
programa
Científico especializado en machine learning en Python
85 h
La reducción de la dimensionalidad es una potente técnica de aprendizaje automático y análisis de datos que consiste en transformar los datos de alta dimensión en un espacio de menor dimensión, conservando tanta información importante como sea posible. Los datos de alta dimensión se refieren a conjuntos de datos con un gran número de características o variables, que pueden plantear retos importantes para los modelos de aprendizaje automático.
En este tutorial, aprenderemos por qué debemos utilizar la reducción de la dimensionalidad, los tipos de técnicas de reducción de la dimensionalidad y cómo aplicar estas técnicas a un sencillo conjunto de datos de imágenes. También visualizaremos los datos en el espacio 2D y compararemos las imágenes en el espacio dimensional inferior.
Si eres nuevo en el aprendizaje automático y quieres dominar los conceptos del aprendizaje automático, realiza el curso Conviértete en un científico del aprendizaje automático en Python y trabaja para convertirte en un científico del aprendizaje automático.
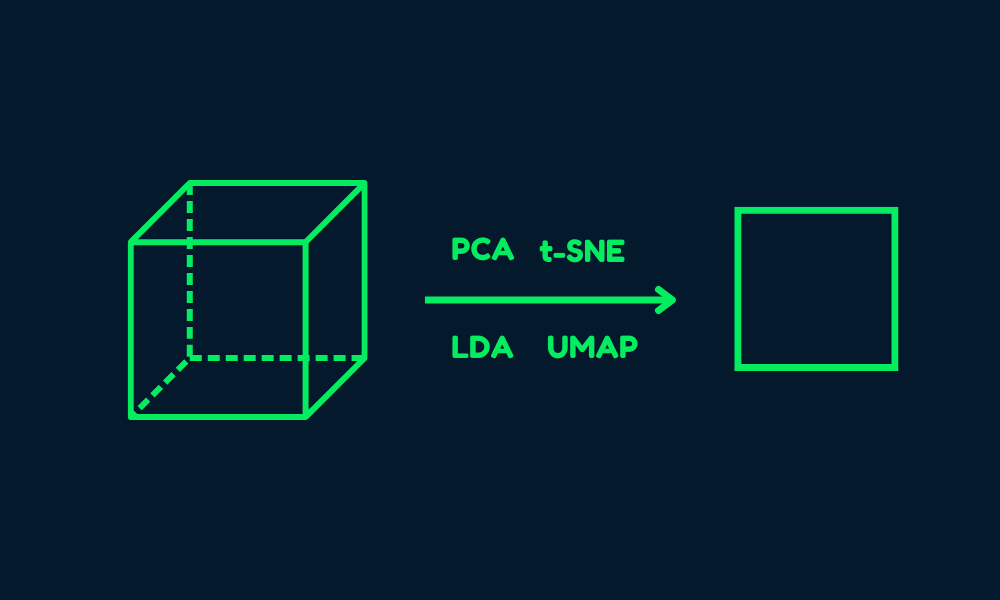
Imagen del autor
Los datos de alta dimensión, aunque ricos en información, a menudo contienen características redundantes o irrelevantes. Esto puede dar lugar a varios problemas:
La reducción de la dimensionalidad aborda estos problemas simplificando los datos y conservando sus características más importantes. Esto no sólo mejora el rendimiento del modelo, sino que también facilita la interpretación y visualización de los datos.
Las técnicas de reducción de la dimensionalidad también pueden clasificarse en función de si suponen una estructura lineal o no lineal en los datos.
Los métodos lineales suponen que los datos se encuentran en un subespacio lineal. Estas técnicas son eficaces desde el punto de vista informático y funcionan bien cuando la estructura de los datos es intrínsecamente lineal.
He aquí algunos ejemplos:
Sigue el Análisis de Componentes Principales (ACP) en Python para aprender a extraer información de los datos sin supervisión utilizando el conjunto de datos Cáncer de Mama y CIFAR-10.
Los métodos no lineales se utilizan cuando los datos se encuentran en una variedad no lineal. Estas técnicas son más adecuadas para captar estructuras complejas en los datos.
He aquí algunos ejemplos:
Las técnicas de reducción de la dimensionalidad pueden clasificarse a grandes rasgos en dos tipos: Selección y extracción de rasgos.
La selección de rasgos consiste en identificar y conservar sólo los rasgos más relevantes del conjunto de datos. Este proceso no transforma los datos, sino que selecciona un subconjunto de las características originales.
Entre los métodos habituales se incluyen:
La extracción de rasgos, también conocida como proyección de rasgos, transforma los datos en un espacio de menor dimensión creando nuevos rasgos que son combinaciones de los originales. Este enfoque es especialmente útil cuando las características originales están muy correlacionadas o son redundantes.
Entre los métodos populares de extracción de rasgos se incluyen:
En esta guía aprenderemos a aplicar técnicas de reducción de la dimensionalidad en Python.
Empezaremos importando los paquetes Python necesarios y cargando el conjunto de datos de dígitos desde sklearn.datasets.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
# Load the digits dataset
digits = load_digits()
X = digits.data # shape (1797, 64)
y = digits.target # labels for digits (0 through 9)
print("Data shape:", X.shape)
print("Labels shape:", y.shape)Este conjunto de datos contiene 1.797 imágenes en escala de grises de dígitos manuscritos (0-9), cada una representada como una imagen de 8x8 (64 píxeles). Los datos se aplanan en un vector de características de 64 dimensiones para cada imagen.
Data shape: (1797, 64)
Labels shape: (1797,)Ahora visualizaremos algunas muestras del conjunto de datos para comprenderlo mejor. Utilizando Matplotlib, mostraremos imágenes que han sido remodeladas a su formato de cuadrícula original de 8x8.
def plot_digits(images, labels, n_rows=2, n_cols=5):
fig, axes = plt.subplots(n_rows, n_cols, figsize=(10, 4))
axes = axes.ravel()
for i in range(n_rows * n_cols):
axes[i].imshow(images[i].reshape(8, 8), cmap='gray')
axes[i].set_title(f"Label: {labels[i]}")
axes[i].axis('off')
plt.tight_layout()
plt.show()
plot_digits(X, y)Como podemos ver, muestra una cuadrícula de imágenes, mostrando cómo se ven los dígitos en escala de grises del 0 al 9.

t-SNE es una popular técnica de reducción de la dimensionalidad para visualizar datos de alta dimensión en 2D o 3D. Es especialmente eficaz para preservar las estructuras locales de los datos.
Lee el blog Introducción al t-SNE: Reducción no lineal de la dimensionalidad y visualización de datos para aprender a visualizar datos de alta dimensión en un espacio de baja dimensión mediante una técnica de reducción no lineal de la dimensionalidad.
Antes de aplicar t-SNE, escalamos los datos utilizando StandardScaler para normalizar los valores de las características.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)A continuación, seleccionamos un subconjunto de 500 muestras para un cálculo más rápido y ejecutamos el algoritmo t-SNE en el subconjunto.
Aquí tienes los argumentos de la función TSNE con su explicación:
n_samples = 500
X_sub = X_scaled[:n_samples]
y_sub = y[:n_samples]
tsne = TSNE(n_components=2,
perplexity=30,
n_iter=1000,
random_state=42)
X_tsne = tsne.fit_transform(X_sub)
print("t-SNE result shape:", X_tsne.shape)La reducción de la dimensionalidad fue un éxito, ya que ahora tenemos 500 muestras, cada una representada en 2 dimensiones.
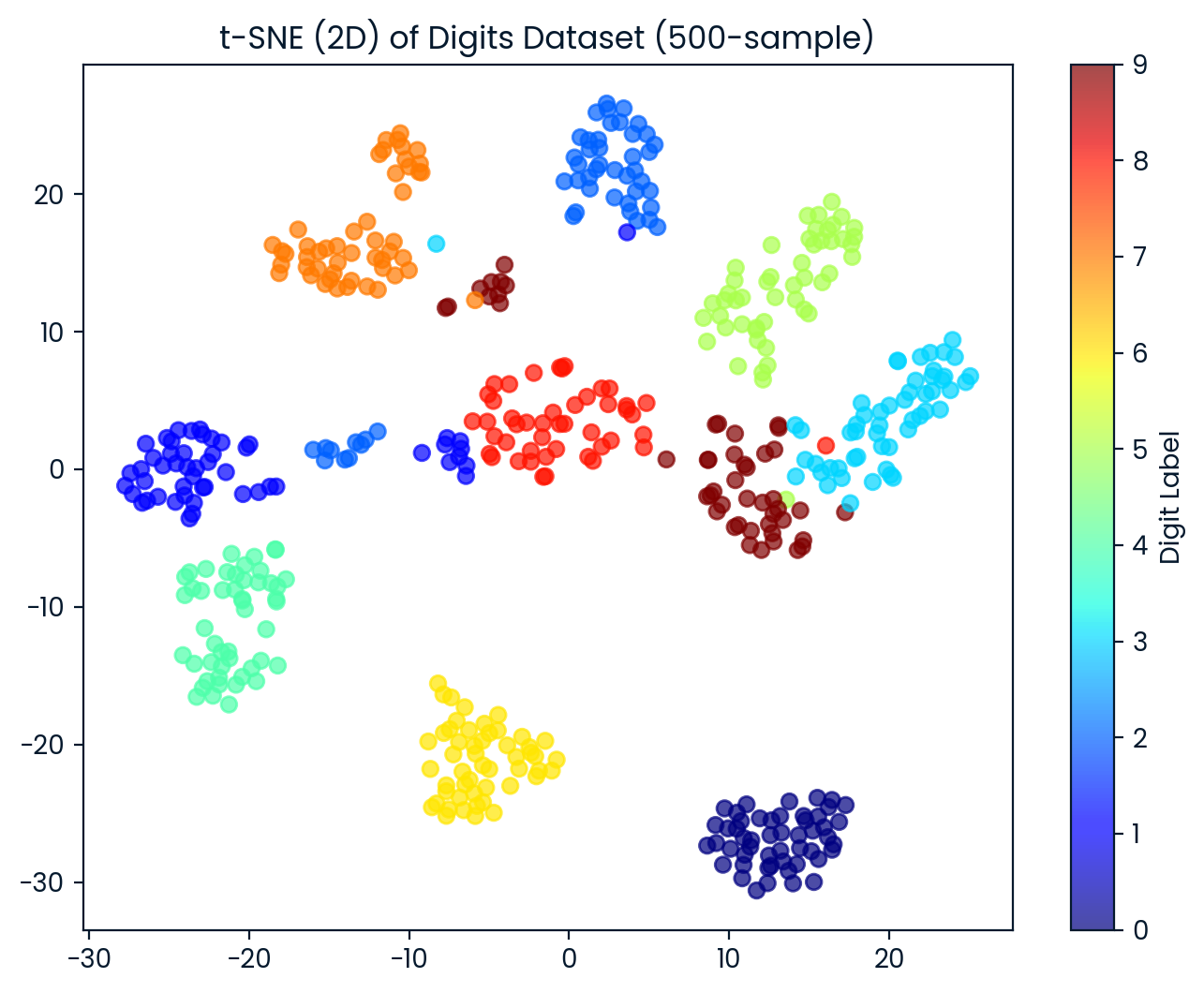
t-SNE result shape: (500, 2)Ahora visualizamos el conjunto de datos 2D t-SNE. Cada punto está coloreado según su etiqueta de dígito, lo que nos permite observar lo bien que el t-SNE separa las distintas clases de dígitos.
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1],
c=y_sub, cmap='jet', alpha=0.7)
plt.colorbar(scatter, label='Digit Label')
plt.title('t-SNE (2D) of Digits Dataset (500-sample)')
plt.show()El t-SNE separó eficazmente los dígitos en 10 grupos distintos, con cierto solapamiento entre grupos.
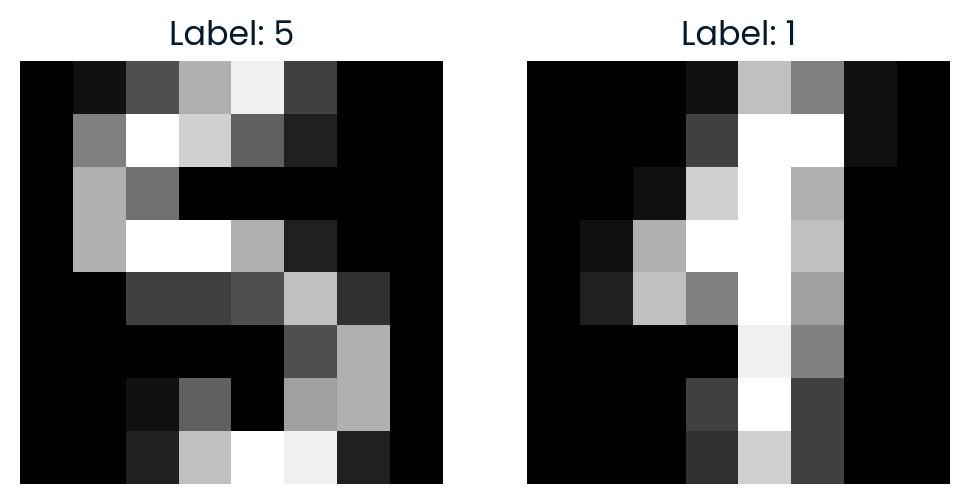
Para explorar más el espacio t-SNE, seleccionamos al azar dos puntos y calculamos la distancia euclídea entre ellos en el espacio t-SNE 2D. También visualizaremos las imágenes para ver lo parecidas que son.
import random
idx1, idx2 = random.sample(range(X_tsne.shape[0]), 2)
point1, point2 = X_tsne[idx1], X_tsne[idx2]
dist_tsne = np.linalg.norm(point1 - point2)
print(f"Comparing images #{idx1} and #{idx2}")
print(f"Distance in t-SNE space: {dist_tsne:.4f}")
print(f"Label of image #{idx1}: {y_sub[idx1]}")
print(f"Label of image #{idx2}: {y_sub[idx2]}")
# Plot the original images
fig, axes = plt.subplots(1, 2, figsize=(6, 3))
axes[0].imshow(X[idx1].reshape(8, 8), cmap='gray')
axes[0].set_title(f"Label: {y_sub[idx1]}")
axes[0].axis('off')
axes[1].imshow(X[idx2].reshape(8, 8), cmap='gray')
axes[1].set_title(f"Label: {y_sub[idx2]}")
axes[1].axis('off')
plt.show()La distancia en el espacio t-SNE refleja lo diferentes que son las dos imágenes en la representación 2D reducida.
Comparing images #291 and #90
Distance in t-SNE space: 35.7666
Label of image #291: 5
Label of image #90: 1
Si tienes problemas para ejecutar el código anterior, comprueba el espacio de trabajo Espacio de trabajo DataLab para obtener más ayuda.
La reducción de la dimensionalidad desempeña un papel crucial en las aplicaciones del mundo real, ya que mejora la eficacia, precisión e interpretabilidad de los modelos de aprendizaje automático, además de permitir una mejor visualización y análisis de conjuntos de datos complejos.
En este tutorial, hemos explorado el concepto de reducción de la dimensionalidad, su finalidad, métodos y tipos. Por último, hemos aprendido a utilizar la técnica t-SNE para transformar los datos de imagen en un espacio de dimensiones inferiores para su visualización y análisis.
Toma la Reducción de la dimensionalidad en Python para comprender el concepto de reducción de la dimensionalidad de tus datos y dominar las técnicas para hacerlo en Python.
Los mejores cursos de DataCamp
programa
programa
Curso
blog
Abid Ali Awan
7 min
blog
Javier Canales Luna
12 min
Tutorial
Abid Ali Awan
Tutorial
Bharath K
Tutorial
Bex Tuychiev



