Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.2K
vLLM (Virtual Large Language Model) ist eine Bibliothek, die entwickelt wurde, um große Sprachmodelle (LLMs) zu hosten. Es bietet eine optimierte Umgebung für die Bearbeitung umfangreicher Sprachverarbeitungsaufgaben.
Es gibt mehrere Gründe, warum wir unseren eigenen LLM ausrichten wollen. Ein Modell lokal oder auf einer Cloud-Plattform zu hosten, gibt uns die Kontrolle über den Datenschutz, die Möglichkeit, das Modell an unsere spezifischen Bedürfnisse anzupassen, und es kann je nach Anwendung günstiger sein.
Außerdem ist vLLM kompatibel mit der OpenAI API. Diese Kompatibilität bedeutet, dass wir bestehenden Code, der eine Schnittstelle zur OpenAI-Infrastruktur hat, durch unseren eigenen gehosteten LLM mit vLLM ersetzen können, ohne die bestehende Codebasis ändern zu müssen.
In diesem Artikel führe ich dich durch die Schritte zur Einrichtung von vLLM. Wir beginnen mit einer Demonstration, wie wir es auf unserem Computer mit Dockerverwenden, einem beliebten Tool für die Containerisierung, das die konsistente Ausführung von Anwendungen in verschiedenen Umgebungen vereinfacht. Dann lernen wir, wie man vLLM in der Google Cloud einsetzt, um eine skalierbare Lösung für das Hosting dieser Modelle bereitzustellen und sicherzustellen, dass sie für größere Aufgaben oder ein höheres Verkehrsaufkommen gerüstet sind.
vLLM vereinfacht die Ausführung von LLMs mit einem effizienten Setup, das für eine CUDA-Plattform optimiert ist, was in der Regel bedeutet, dass NVIDIA-GPUs zur Beschleunigung verwendet werden. Wenn wir das Modell stattdessen auf einer CPU ausführen wollen, können wir das Docker-Image verwenden, das vLLM speziell für die CPU-Nutzung bereitstellt. Diese Flexibilität ermöglicht es uns, Modelle zu hosten, auch wenn wir keinen Zugang zu einer CUDA-fähigen Umgebung haben. Um vLLM auf einer CUDA Plattform zu hosten, lesen Sie die deren Schnellstartanleitung.
Da die meisten von uns keinen Zugang zu High-End-GPUs haben, werden wir uns darauf konzentrieren, vLLM auf einer CPU laufen zu lassen. So ist sichergestellt, dass wir mit den uns zur Verfügung stehenden Ressourcen weiterhin mit LLMs experimentieren können.
Um den Prozess zu vereinfachen, werden wir Docker verwenden, ein beliebtes Tool, mit dem wir Anwendungen und ihre Abhängigkeiten in Container verpacken können. Stell dir einen Container als eine leichte, tragbare Einheit vor, die alles enthält, was zum Ausführen einer bestimmten Software benötigt wird. Durch die Verwendung von Docker müssen wir uns keine Gedanken über die manuelle Installation von vLLM oder mögliche Kompatibilitätsprobleme auf unserem System machen.
vLLM bietet ein gebrauchsfertiges Docker-Image, das speziell für die CPU-Ausführung entwickelt wurde. Dieses Bild enthält alle notwendigen Komponenten, um vLLM auszuführen. So können wir uns auf die Nutzung des Modells konzentrieren, anstatt uns mit der komplexen Einrichtung zu beschäftigen. Das bedeutet, dass wir unsere LLMs schnell und effizient auf einer CPU laufen lassen können.
Zuerst müssen wir ein Docker-Image erstellen, mit dem wir vLLM auf unserem Computer ausführen können. Das vLLM-Repository bietet Dockerfiles mit allen notwendigen Anweisungen, um ein Image zu erstellen, das vLLM auf einer CPU ausführen kann.
Dockerfile.cpu für normale CPUs.Dockerfile.arm für ARM-CPUs wie die in modernen Macs.Da ich einen Mac mit einem M2-Prozessor habe, werde ich die Datei .arm verwenden. Um das Image zu erstellen, klonen oder laden wir zuerst das Repository herunter und führen dann diesen Befehl aus:
docker build -f Dockerfile.arm -t vllm-cpu --shm-size=4g .Hier ist ein kurzer Überblick darüber, was dieser Befehl bewirkt:
docker build: Dieser Befehl erstellt ein Docker-Image aus einer Dockerdatei.-f Dockerfile.arm: Gibt das zu verwendende Dockerfile an.-t vllm-cpu: Kennzeichne das Bild als vllm-cpu, um es leichter zu finden (es hätte auch ein anderer Name sein können).--shm-size=4g: Weist 4 Gigabyte gemeinsamen Speicher zu, was zur Verbesserung der Leistung beiträgt.vLLM nutzt Hugging Face, eine Plattform, die die Verwaltung von Modellen erleichtert, um den Prozess des Modellhostings zu optimieren. Hier ist, wie wir anfangen können:
meta-llama/Llama-3.2-1B-Instruct, da es ein kleineres Modell ist, das sich für erste Tests eignet. Auf der Seite des Modells gibt es möglicherweise eine Option, um Zugang zu beantragen. Befolge alle Anweisungen, um Zugang zu erhalten.Nachdem wir unser Docker-Image erstellt haben und das Hugging Face-Token bereit ist, können wir das vLLM-Modell mit dem folgenden Befehl ausführen:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16Lass uns diesen Befehl auspacken:
docker run: Dieser Befehl führt einen Container aus, der auf dem angegebenen Docker-Image basiert.-it: Führt den Container interaktiv mit Terminalzugriff aus.--rm: Entfernt den Container automatisch, wenn er angehalten wird.-p 8000:8000: Ordnet den Port 8000 des Containers dem Port 8000 auf unserem Rechner zu und macht den Dienst lokal verfügbar.--env "HUGGING_FACE_HUB_TOKEN=": Setzt das Hugging Face-Token als Umgebungsvariable, damit vLLM sich mit der Hugging Face-API verbinden kann. Ersetze <Ersetzen_mit_hf_token> mit dem tatsächlichen Token, den wir erstellt haben.vllm-cpu: Gibt den Namen des Docker-Images an, das wir zuvor erstellt haben.--model meta-llama/Llama-3.2-1B-Instruct: Gibt an, welches Modell ausgeführt werden soll.--dtype float16: Verwende den Datentyp float16, weil das Modell ihn benötigt, wenn es auf der CPU läuft.Wenn wir diesen Befehl ausführen, wird es eine Weile dauern, bis der Server bereit ist, da er die LLM herunterladen muss. Es wird fertig sein, wenn wir so etwas im Terminal sehen:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)Eine der großartigen Eigenschaften von vLLM ist seine Kompatibilität mit der OpenAI API. Das bedeutet, dass wir bestehenden Code, der für die Interaktion mit der OpenAI-Infrastruktur entwickelt wurde, problemlos für die Kommunikation mit einem über vLLM gehosteten Modell verwenden können.
Diese Kompatibilität ermöglicht einen reibungslosen Übergang, ohne unsere bestehende Codebasis zu verändern. Wenn wir also vLLM einrichten, können wir ganz einfach unsere vertrauten Tools und Befehle für die Interaktion mit dem LLM verwenden und so den Integrationsprozess effizient und benutzerfreundlich gestalten.
Hier ist ein Beispiel dafür, wie wir eine Nachricht an unseren lokalen Server auf Docker senden:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
]
)
print(completion.choices[0].message.content)Beachte, dass wir oben den API-Schlüssel "EMPTY" verwendet haben. Dies ist der Standardschlüssel. Wir könnten einen Schlüssel für den Zugriff auf das Modell verlangen, indem wir ihn mit dem Parameter --api-key angeben. Zum Beispiel:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16 --api-key supersecretkeyDann müssen wir in diesem Fall den Schlüssel am Anfang des Codes ersetzen:
openai_api_key = "supersecretkey"Das Hosting eines LLM auf Google Cloud mit vLLM kann eine Lösung für die Bereitstellung von LLMs sein. Lass uns die genannten Schritte aufschlüsseln und zur besseren Verständlichkeit erweitern.
Zuerst müssen wir auf die Google Cloud Console zugreifen. Wir können dies tun, indem wir in unserem Webbrowser zur Google Cloud Console navigieren. Wenn wir noch kein Google-Konto haben, müssen wir eines erstellen, um die Google Cloud-Dienste zu nutzen.
Suche in der Google Cloud Console das Dropdown-Menü "Projekt" am oberen Rand des Bildschirms und wähle "Neues Projekt".

Gib vllm-demo als Projektnamen ein, damit du es später leichter identifizieren kannst.
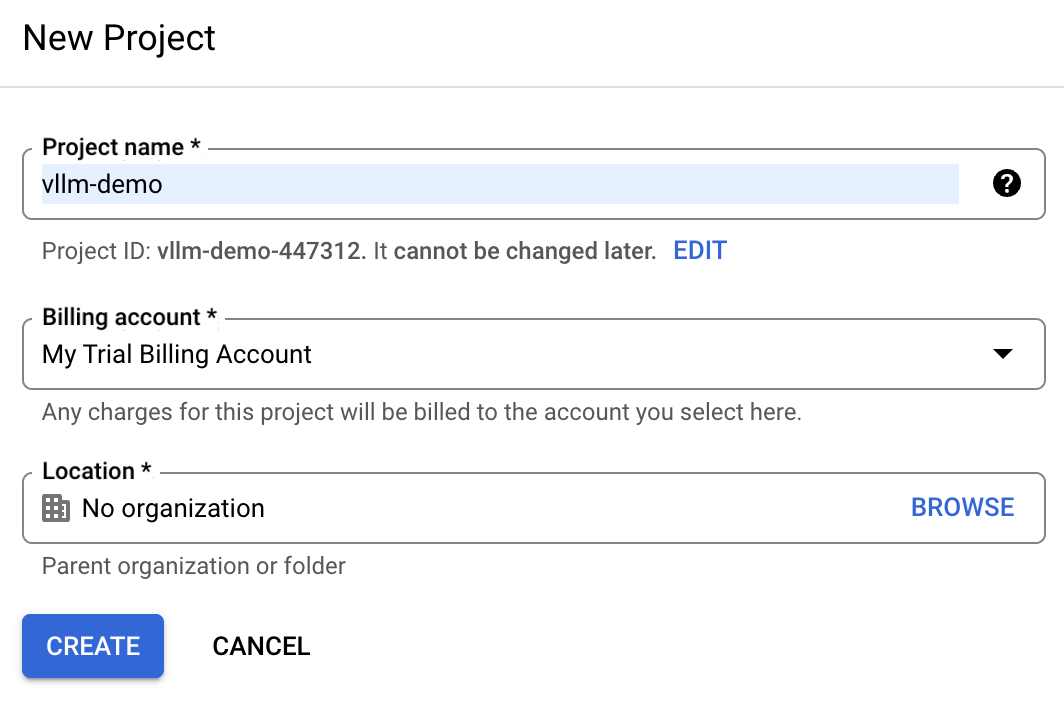
Wenn wir bereits ein Google Cloud-Konto haben, ist das Probeabrechnungskonto möglicherweise nicht verfügbar. In diesem Fall müssen wir ein neues Rechnungskonto anlegen. Navigiere dazu zum Abschnitt "Abrechnung" und folge den Schritten, um entweder ein bestehendes Abrechnungskonto auszuwählen oder ein neues zu erstellen.
Die Artifact Registry ist ein Dienst, mit dem wir Container-Images speichern und verwalten können. Wir verwenden es, um das Docker-Image zu speichern, mit dem wir vLLM ausführen werden.
Suche in der Cloud-Konsole nach "Artefakt", um die Artefaktregistrierung zu öffnen.
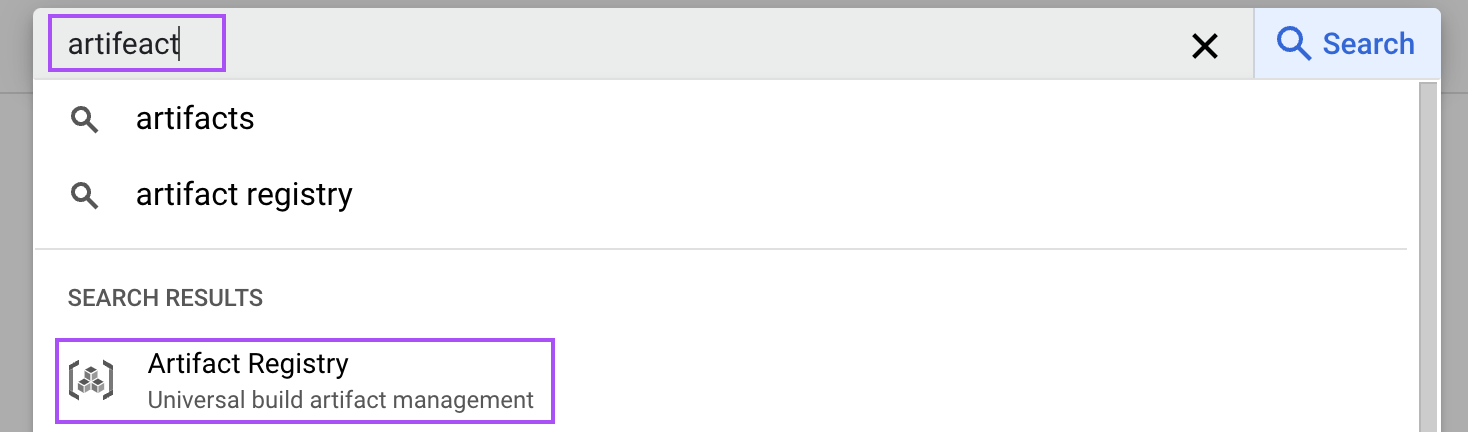
Dann aktiviere sie für unser Projekt. Dieser Schritt ist notwendig, um das Docker-Image unseres vLLM-Setups zu speichern.

Jetzt müssen wir ein Artefakt-Repository erstellen, um unsere Container-Images zu speichern. Navigiere zur Artefaktregistrierung und klicke auf "Repository erstellen".

Benenne das Repository vllm-cpu und wähle "Docker" als Format. Gib den Standort als us-central1 an, um die Leistung auf der Grundlage unserer Einsatzanforderungen zu optimieren. Der Rest der Konfiguration kann mit den Standardwerten belassen werden.

Genau wie bei unserem lokalen Rechner müssen wir das Docker-Image erstellen und es dann in unser vllm-cpu Google Cloud Repository hochladen (push). Dazu verwenden wir die Cloud Shell in der oberen rechten Ecke.
 .
.
In diesem Terminal klonst du das vLLM GitHub Repository mit dem folgenden Befehl, um die benötigten Dateien zu holen:
git clone https://github.com/vllm-project/vllm.gitNavigiere mit dem Terminal zu dem geklonten vLLM-Verzeichnis.
cd vllmErstelle das Docker-Image mit dem angegebenen Befehl, der das bereitgestellte, für die CPU-Auslastung konfigurierte Dockerfile verwendet:
docker build \
-t us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latest \
-f Dockerfile.cpu .Sobald das Docker-Image erstellt ist, schiebst du es in unser Artifact Repository. Bei dieser Aktion wird das Bild hochgeladen, damit es später von den Google Cloud-Diensten verwendet werden kann:
docker push us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latestGoogle Cloud Run ermöglicht die Bereitstellung von containerisierten Anwendungen. Wir nutzen diesen Dienst, um das gerade erstellte Image zu verteilen.
Gib "Cloud Run" in die Suchleiste ein und öffne den Dienst "Cloud Run".

Dort klickst du auf die Schaltfläche "Dienst erstellen":
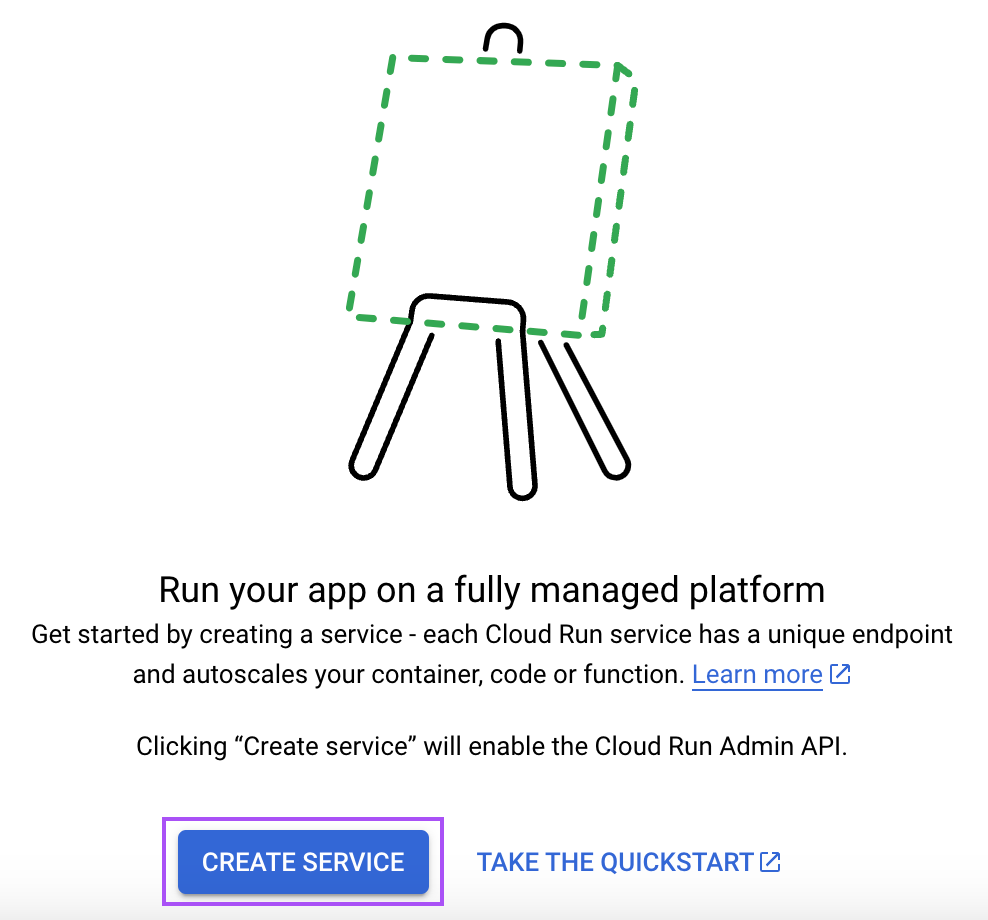
Dann befolge diese Schritte:
8000, der von vLLM verwendet wird.HUGGING_FACE_HUB_TOKEN hinzu und füge unser Token hier ein. Mit diesem Token kann vLLM auf Modelle von Hugging Face zugreifen.--model=meta-llama/Llama-3.2-1B an, um das gewünschte Modell anzugeben.Wenn du alle Einstellungen vorgenommen hast (die anderen Optionen können mit den Standardwerten belassen werden), klicke auf die Schaltfläche "Erstellen" unten auf der Seite. Warte, bis der Dienst bereit ist und navigiere zu dieser Seite. Dort haben wir die Service-URL, die wir für die Kommunikation mit dem LLM verwenden können.
Es sollte in etwa so aussehen:
https://vllm-llama-577126904161.us-central1.run.appWir können mit Python mit dem LLM interagieren, so wie wir es bei der lokalen Ausführung des Modells getan haben. Wir müssen nur die URL im Skript ändern:
# Replace with your service URL
openai_api_base = "https://vllm-llama-577126904161.us-central1.run.app/v1"Warnung: Wenn du diese Schritte befolgst, solltest du daran denken, dass es dich Geld kostet, die Artefaktregistrierung aufrechtzuerhalten. Vergiss also bitte nicht, die Verknüpfung des Abrechnungskontos aufzuheben, nachdem du diese Anleitung befolgt hast, sonst wird dir in Rechnung gestellt, auch wenn niemand es benutzt.
Zum Zeitpunkt der Erstellung dieses Tutorials ist die GPU-Unterstützung für Google Cloud Run auf Anfrage verfügbar. Das bedeutet, dass wir den Zugriff auf diese Funktion ausdrücklich beantragen müssen. Wenn die vLLM mit einem Grafikprozessor ausgeführt wird, erhöht sich die Leistung im Vergleich zur CPU-Nutzung erheblich. Dies ist vor allem bei der Bearbeitung großer Sprachmodelle von Vorteil, da GPUs dafür ausgelegt sind, parallele Aufgaben effizienter zu verarbeiten.
Wenn wir Zugang zur GPU-Unterstützung erhalten, haben wir die Möglichkeit, unseren Arbeitsablauf zu rationalisieren. In diesem Szenario müssen wir nicht unser eigenes Docker-Image erstellen. Stattdessen können wir direkt einen Dienst erstellen, der das bereits existierende Bild vllm/vllm-openai:latest nutzt. Dieses Image ist für die Arbeit mit der GPU optimiert und ermöglicht es uns, unsere Modelle schnell und effektiv einzusetzen, ohne die zusätzlichen Einrichtungsschritte, die für CPU-Konfigurationen erforderlich sind.
Sobald der GPU-Zugriff genehmigt ist und wir den Dienst mit dem bereitgestellten Image eingerichtet haben, kann unsere vLLM-Implementierung die Leistung und Geschwindigkeit der GPUs voll ausschöpfen und eignet sich damit hervorragend für Echtzeitanwendungen und anspruchsvolle Sprachverarbeitungsaufgaben.
Für diejenigen, die nach alternativen Hosting-Optionen suchen, bieten Plattformen wie RunPod bieten optimierte Dienste für das Hosting großer Sprachmodelle. RunPod bietet zum Beispiel eine serverlose Einrichtung das den Einsatzprozess vereinfacht.
Diese Option ist zwar benutzerfreundlich und schnell eingerichtet, aber es ist wichtig zu bedenken, dass der Komfort oft einen höheren Preis hat. Wenn Budgetbeschränkungen eine Rolle spielen, sollten wir die Benutzerfreundlichkeit gegen die Kosten abwägen, die mit solchen Diensten verbunden sind.
In diesem Tutorial haben wir den Prozess der Einrichtung und des Hostings von vLLM sowohl lokal als auch in der Google Cloud untersucht.
Wir haben gelernt, wie man Docker-Images erstellt und ausführt, die speziell auf CPUs zugeschnitten sind und auch ohne High-End-GPU-Ressourcen zugänglich sind. Außerdem haben wir uns überlegt, vLLM in der Google Cloud einzusetzen, die eine skalierbare Lösung für die Bewältigung größerer Aufgaben bietet.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach