Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.2K
vLLM (Virtual Large Language Model) es una biblioteca diseñada para alojar grandes modelos lingüísticos (LLM). Ofrece un entorno optimizado para manejar tareas de procesamiento lingüístico a gran escala.
Hay varias razones por las que podríamos querer organizar nuestro propio LLM. Alojar un modelo localmente o en una plataforma en la nube nos da control sobre la privacidad de los datos, una posible personalización del modelo para que se adapte mejor a nuestras necesidades específicas, y puede ser más barato dependiendo de la aplicación.
Además, vLLM es compatible con la API de OpenAI. Esta compatibilidad significa que si tenemos código existente que interactúa con la infraestructura de OpenAI, podemos sustituirlo por nuestro propio LLM alojado utilizando vLLM sin tener que modificar la base de código existente.
En este artículo, te guiaré a través de los pasos para configurar vLLM. Empezaremos demostrando cómo ejecutarlo en nuestro ordenador utilizando Dockeruna popular herramienta de contenedorización que simplifica el proceso de ejecutar aplicaciones de forma coherente en distintos entornos. A continuación, aprenderemos a desplegar vLLM en Google Cloud, proporcionando una solución escalable para alojar estos modelos y garantizar que están preparados para gestionar tareas de mayor envergadura o mayores volúmenes de tráfico.
vLLM simplifica la ejecución de LLMs con una configuración eficiente optimizada para una plataforma CUDA, lo que normalmente significa utilizar GPUs NVIDIA para la aceleración. Sin embargo, si queremos ejecutar el modelo en una CPU, podemos utilizar la imagen Docker que vLLM proporciona específicamente para el uso de la CPU. Esta flexibilidad nos permite alojar modelos aunque no tengamos acceso a un entorno compatible con CUDA. Para alojar vLLM en una plataforma CUDA, consulta su guía de inicio rápido.
Como la mayoría de nosotros no tenemos acceso a GPUs de gama alta, nos centraremos en configurar vLLM para que se ejecute en una CPU. Esto garantiza que podamos seguir experimentando con los LLM utilizando los recursos de que disponemos.
Para simplificar el proceso, utilizaremos Docker, que es una popular herramienta que nos permite empaquetar aplicaciones y sus dependencias en contenedores. Piensa en un contenedor como una unidad ligera y portátil que incluye todo lo necesario para ejecutar un software específico. Al utilizar Docker, no tenemos que preocuparnos de instalar manualmente vLLM ni de lidiar con posibles problemas de compatibilidad en nuestro sistema.
vLLM ofrece una imagen Docker lista para usar, diseñada específicamente para la ejecución en CPU. Esta imagen contiene todos los componentes necesarios para ejecutar vLLM, lo que nos permite centrarnos en utilizar el modelo en lugar de en las complejidades de su configuración. Esto significa que podemos empezar a ejecutar nuestros LLM rápida y eficazmente en una CPU.
En primer lugar, tenemos que crear una imagen Docker que nos permita ejecutar vLLM en nuestro ordenador. La página repositorio vLLM proporciona Dockerfiles con todas las instrucciones necesarias para construir una imagen que pueda ejecutar vLLM en una CPU.
Dockerfile.cpu para CPU normales.Dockerfile.arm para CPU ARM como las de los Mac modernos.Como tengo un Mac con un procesador M2, utilizaré el archivo .arm. Para construir la imagen, primero clonamos o descargamos el repositorio y luego ejecutamos este comando desde dentro de él:
docker build -f Dockerfile.arm -t vllm-cpu --shm-size=4g .Aquí tienes un rápido desglose de lo que hace este comando:
docker build: Este comando crea una imagen Docker a partir de un archivo Dockerfile.-f Dockerfile.arm: Especifica el Dockerfile a utilizar.-t vllm-cpu: Etiqueta la imagen como vllm-cpu para facilitar la referencia (podría haber sido otro nombre).--shm-size=4g: Asigna 4 gigabytes de memoria compartida, lo que ayuda a mejorar el rendimiento.vLLM utiliza Hugging Face, una plataforma que facilita la gestión de modelos, para agilizar el proceso de alojamiento de modelos. Así es como podemos empezar:
meta-llama/Llama-3.2-1B-Instruct, ya que es un modelo más pequeño adecuado para las pruebas iniciales. En la página del modelo, puede haber una opción para solicitar el acceso. Sigue las instrucciones que te den para acceder.Con nuestra imagen Docker construida y el token Cara de Abrazo listo, ahora podemos ejecutar el modelo vLLM utilizando el siguiente comando:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16Vamos a desgranar este comando:
docker run: Este comando ejecuta un contenedor basado en la imagen Docker especificada.-it: Ejecuta el contenedor de forma interactiva con acceso al terminal.--rm: Elimina automáticamente el contenedor cuando se detiene.-p 8000:8000: Asigna el puerto 8000 del contenedor al puerto 8000 de nuestra máquina, haciendo que el servicio esté disponible localmente.--env "HUGGING_FACE_HUB_TOKEN=": Establece el token de Hugging Face como variable de entorno, permitiendo a vLLM conectarse a la API de Hugging Face. Sustituye <reemplazar_con_hf_token> por el token real que hemos creado.vllm-cpu: Especifica el nombre de la imagen Docker que construimos anteriormente.--model meta-llama/Llama-3.2-1B-Instruct: Indica qué modelo ejecutar.--dtype float16: Utiliza el tipo de datos float16 porque el modelo lo requiere cuando se ejecuta en CPU.Cuando ejecutemos este comando, el servidor tardará un rato en estar listo, ya que necesita descargar el LLM. Estará listo cuando veamos algo así en el terminal:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)Una de las grandes características de vLLM es su compatibilidad con la API OpenAI. Esto significa que si tenemos código existente diseñado para interactuar con la infraestructura de OpenAI, podemos utilizar fácilmente ese mismo código para comunicarnos con un modelo alojado mediante vLLM.
Esta compatibilidad permite una transición suave sin modificar nuestra base de código existente. Así, cuando configuramos vLLM, resulta sencillo seguir utilizando nuestras herramientas y comandos familiares para interactuar con el LLM, lo que hace que el proceso de integración sea eficaz y fácil de usar.
He aquí un ejemplo de cómo enviar un mensaje a nuestro servidor local que se ejecuta en Docker:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
]
)
print(completion.choices[0].message.content)Ten en cuenta que antes hemos utilizado la clave API "VACÍA". Esta es la clave por defecto. Podríamos exigir una clave para acceder al modelo especificándola con el parámetro --api-key. Por ejemplo:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16 --api-key supersecretkeyEntonces, en este caso, tenemos que sustituir la clave en la parte superior del código:
openai_api_key = "supersecretkey"Alojar un LLM en Google Cloud utilizando vLLM puede proporcionar una solución para desplegar LLMs. Vamos a desglosar los pasos mencionados y a ampliarlos para una mayor claridad.
En primer lugar, tenemos que acceder a la Consola de Google Cloud. Podemos hacerlo navegando a Google Cloud Console en nuestro navegador web. Si aún no tenemos una cuenta de Google, tenemos que crear una para utilizar los servicios de Google Cloud.
En Google Cloud Console, localiza el menú desplegable de proyectos en la parte superior de la pantalla y selecciona "Nuevo proyecto".

Introduce vllm-demo como nombre del proyecto, para facilitar su identificación posterior.
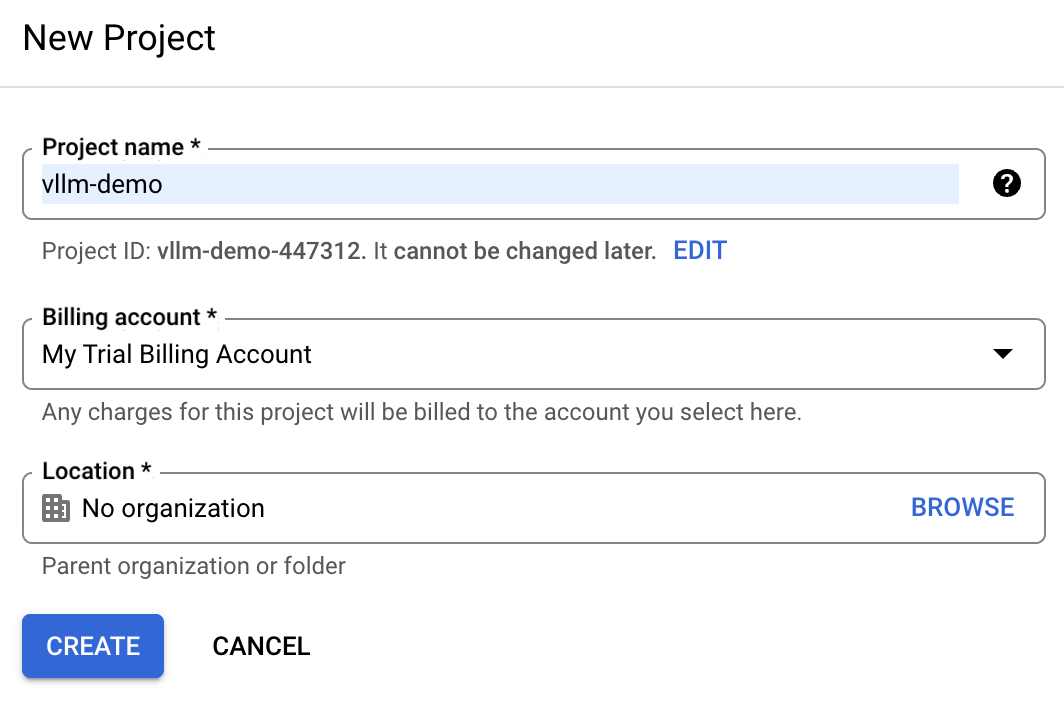
Si ya tenemos una cuenta en la nube de Google, es posible que la cuenta de facturación de prueba no esté disponible. En este caso, tenemos que crear una nueva cuenta de facturación. Para ello, ve a la sección "Facturación" y sigue los pasos para seleccionar una cuenta de facturación existente o crear una nueva.
El Registro de Artefactos es un servicio que nos permite almacenar y gestionar imágenes de contenedores. Lo utilizamos para almacenar la imagen Docker que utilizaremos para ejecutar vLLM.
En la Consola de la Nube, busca "artefacto" para abrir el Registro de Artefactos.
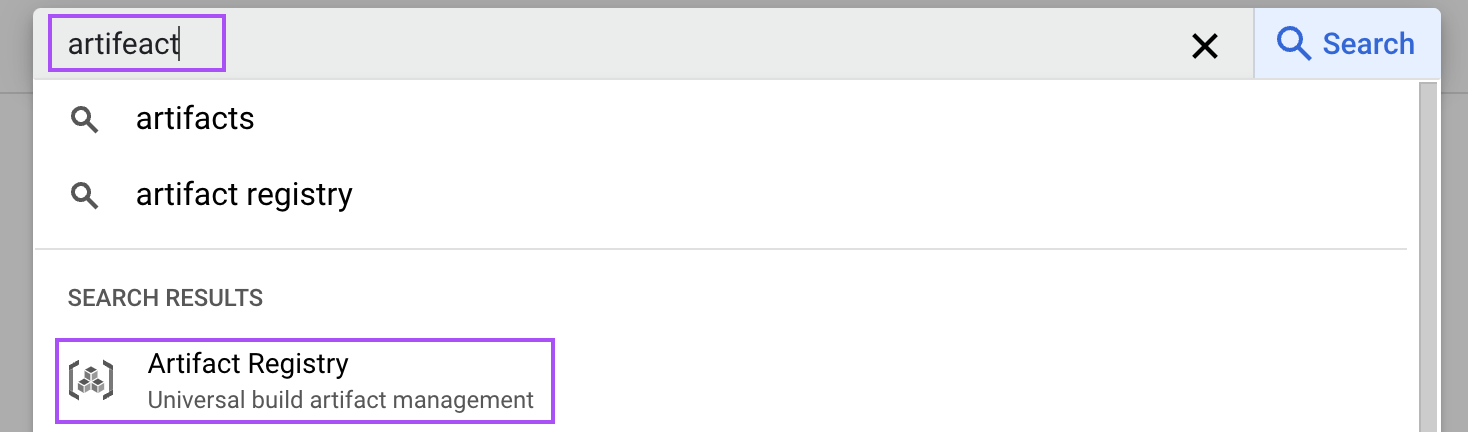
Después, habilítalo para nuestro proyecto. Este paso es necesario para almacenar la imagen Docker de nuestra configuración vLLM.

Ahora, necesitamos crear un repositorio de artefactos para almacenar nuestras imágenes de contenedor. Navega hasta el Registro de Artefactos y haz clic en "Crear Repositorio".

Nombra el repositorio vllm-cpu y elige "Docker" como formato. Especifica la ubicación como us-central1 para optimizar el rendimiento en función de nuestros requisitos de implantación. El resto de la configuración se puede dejar con los valores por defecto.

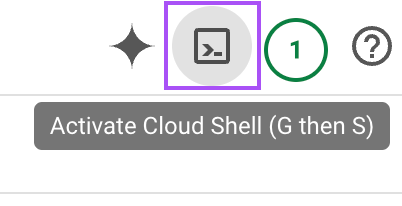
Al igual que hicimos para nuestra máquina local, tenemos que construir la imagen Docker y luego subirla (push) a nuestro repositorio vllm-cpu de Google Cloud. Lo haremos utilizando el caparazón de la nube situado en la esquina superior derecha.
 .
.
En ese terminal, clona el repositorio GitHub de vLLM con el siguiente comando para obtener los archivos necesarios:
git clone https://github.com/vllm-project/vllm.gitNavega hasta el directorio vLLM clonado utilizando el terminal.
cd vllmConstruye la imagen Docker con el comando especificado, que utiliza el Dockerfile proporcionado configurado para el uso de la CPU:
docker build \
-t us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latest \
-f Dockerfile.cpu .Una vez creada la imagen Docker, envíala a nuestro repositorio de artefactos. Esta acción consiste en subir la imagen para que pueda ser utilizada posteriormente por los servicios de Google Cloud:
docker push us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latestGoogle Cloud Run permite el despliegue de aplicaciones en contenedores. Utilizamos este servicio para desplegar la imagen que acabamos de construir.
Escribe "Cloud Run" en la barra de búsqueda y abre el servicio "Cloud Run".

Desde ahí, haz clic en el botón "Crear servicio":
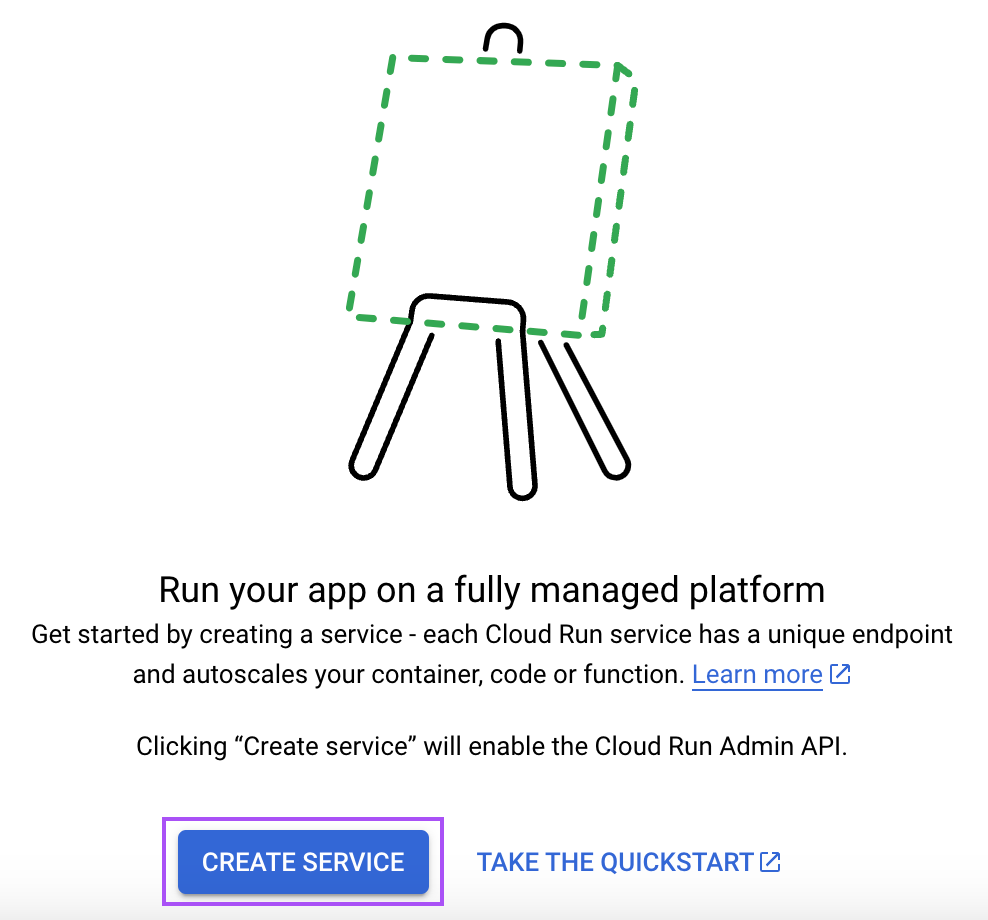
A continuación, sigue estos pasos:
8000, que es el que utiliza vLLM.HUGGING_FACE_HUB_TOKEN y pega aquí nuestro token. Este token permite a vLLM acceder a los modelos de Cara Abrazada.--model=meta-llama/Llama-3.2-1B para especificar el modelo deseado.Con toda la configuración establecida (las demás opciones pueden dejarse con los valores por defecto), pulsa el botón "Crear" en la parte inferior de la página. Espera a que el servicio esté listo y navega hasta la página de ese servicio. Ahí tenemos la URL del servicio que podemos utilizar para comunicarnos con el LLM.
Debería tener este aspecto:
https://vllm-llama-577126904161.us-central1.run.appPodemos interactuar con el LLM utilizando Python como hicimos al ejecutar el modelo localmente. Sólo tenemos que cambiar la URL en el script:
# Replace with your service URL
openai_api_base = "https://vllm-llama-577126904161.us-central1.run.app/v1"Advertencia: Si sigues estos pasos, ten en cuenta que mantener vivo el registro de artefactos te costará dinero. Así que recuerda desvincular la cuenta de facturación después de seguir esta guía, o se te facturará aunque nadie la utilice.
En el momento de escribir este tutorial, el soporte GPU para Google Cloud Run está disponible bajo petición. Esto significa que tenemos que solicitar específicamente el acceso a esta función. Una vez concedido, ejecutar el vLLM utilizando una GPU aumentará significativamente su rendimiento en comparación con el uso de la CPU. Esto es especialmente beneficioso para manejar grandes modelos lingüísticos, ya que las GPU están diseñadas para procesar tareas paralelas de forma más eficiente.
Si obtenemos acceso al soporte de la GPU, tendremos la opción de agilizar nuestro flujo de trabajo. En este escenario, no necesitamos pasar por el proceso de construir nuestra propia imagen Docker. En su lugar, podemos crear directamente un servicio utilizando la imagen preexistente vllm/vllm-openai:latest. Esta imagen está optimizada para funcionar con GPU, lo que nos permite desplegar nuestros modelos de forma rápida y eficaz sin los pasos de configuración adicionales que requieren las configuraciones de CPU.
Una vez aprobado el acceso a la GPU y configurado el servicio utilizando la imagen proporcionada, nuestra implantación de vLLM puede aprovechar al máximo la potencia y velocidad que ofrecen las GPU, lo que la hace muy adecuada para aplicaciones en tiempo real y tareas de procesamiento lingüístico de alta demanda.
Para los que buscan opciones de alojamiento alternativas, plataformas como RunPod ofrecen servicios simplificados para alojar grandes modelos lingüísticos. RunPod, por ejemplo, proporciona una configuración sin servidor que simplifica el proceso de despliegue.
Aunque esta opción es fácil de usar y rápida de configurar, es importante tener en cuenta que la comodidad suele tener un precio más alto. Si las limitaciones presupuestarias son un factor, podríamos sopesar la facilidad de uso frente a los costes asociados a dichos servicios.
En este tutorial, exploramos el proceso de configuración y alojamiento de vLLM tanto localmente como en Google Cloud.
Aprendimos a construir y ejecutar imágenes Docker específicamente adaptadas a CPU, garantizando la accesibilidad incluso sin recursos de GPU de gama alta. Además, estudiamos la posibilidad de desplegar vLLM en Google Cloud, que ofrece una solución escalable para gestionar tareas de mayor envergadura.
Aprende IA con estos cursos
Curso
Curso
blog
Bhavishya Pandit
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer

