Kurs
Python für Fortgeschrittene
4 Std.
1.4M
Der umfangreiche Beitrag von Forschern im Bereich NLP, kurz für Natural Language Processing, hat in den letzten Jahrzehnten zu innovativen Ergebnissen in verschiedenen Bereichen geführt. Im Folgenden findest du einige Beispiele für Natural Language Processing in der Praxis:
In diesem konzeptionellen Blog geht es um Transformers, eines der leistungsstärksten Modelle, die jemals in der natürlichen Sprachverarbeitung entwickelt wurden. Nachdem wir ihre Vorteile im Vergleich zu rekurrenten neuronalen Netzen erklärt haben, werden wir dein Verständnis für Transformers erweitern. Dann werden wir einige reale Fallbeispiele mit Huggingface-Transformatoren durchspielen.
Du kannst auch mehr über den Aufbau von NLP-Anwendungen mit Hugging Face in unserem Code-Along erfahren.
Bevor wir uns mit dem Kernkonzept der Transformatoren befassen, wollen wir kurz verstehen, was wiederkehrende Modelle sind und wo ihre Grenzen liegen.
Rekurrente Netze verwenden die Encoder-Decoder-Architektur und werden vor allem dann eingesetzt, wenn es um Aufgaben geht, bei denen sowohl die Eingaben als auch die Ausgaben Sequenzen in einer bestimmten Reihenfolge sind. Einige der wichtigsten Anwendungen von rekurrenten Netzen sind die maschinelle Übersetzung und die Modellierung von Zeitreihen.
Überlegen wir uns, wie wir den folgenden französischen Satz ins Englische übersetzen können. Die Eingabe, die dem Encoder übermittelt wird, ist der französische Originalsatz, und die übersetzte Ausgabe wird vom Decoder erzeugt.
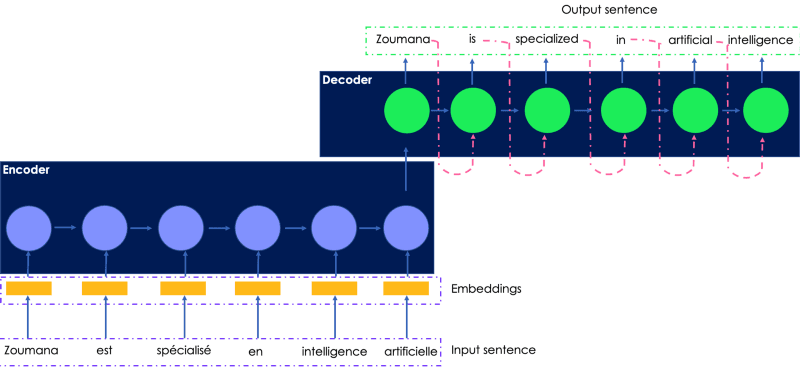
Eine einfache Illustration des rekurrenten Netzwerks für Sprachübersetzung
Wäre es nicht toll, ein Modell zu haben, das die Vorteile von rekurrenten Netzen kombiniert und parallele Berechnungen ermöglicht?
Hier kommen die Transformatoren ins Spiel.
Transformers ist die neue einfache, aber leistungsstarke neuronale Netzwerkarchitektur, die Google Brain 2017 mit der berühmten Forschungsarbeit "Attention is all you need" vorgestellt hat. Es basiert auf dem Mechanismus der Aufmerksamkeit und nicht auf der sequentiellen Berechnung, wie wir sie in rekurrenten Netzen beobachten können.
Ähnlich wie bei rekurrenten Netzen gibt es auch bei Transformatoren zwei Hauptblöcke: Encoder und Decoder, die jeweils über einen Selbstbeobachtungsmechanismus verfügen. Die erste Version der Transformatoren hatte eine RNN- und LSTM-Encoder-Decoder-Architektur, die später in Self-Attention- und Feed-Forward-Netzwerke geändert wurde.
Der folgende Abschnitt gibt einen allgemeinen Überblick über die Hauptbestandteile der einzelnen Transformatorenblöcke.
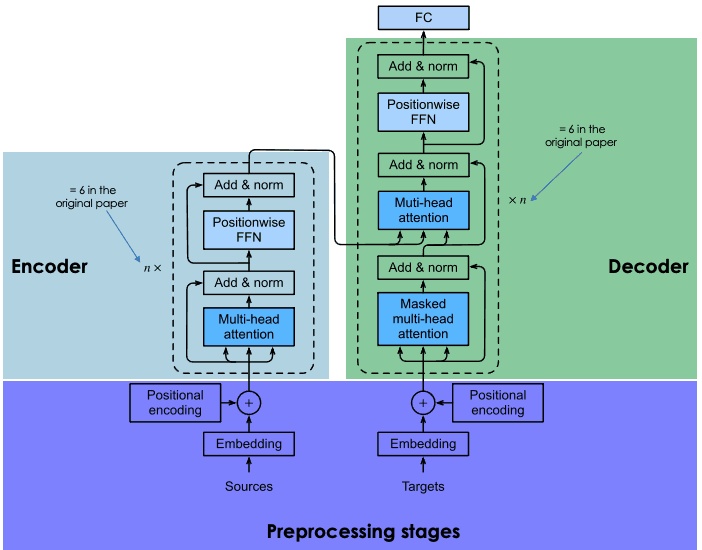
Allgemeine Architektur von Transformatoren (angepasst vom Autor)
Dieser Abschnitt enthält zwei Hauptschritte: (1) die Erzeugung der Einbettungen des Eingabesatzes und (2) die Berechnung des Positionsvektors für jedes Wort im Eingabesatz. Alle Berechnungen werden sowohl für den Ausgangssatz (vor dem Encoder-Block) als auch für den Zielsatz (vor dem Decoder-Block) auf die gleiche Weise durchgeführt.
Bevor wir die Einbettungen der Eingabedaten erzeugen, führen wir zunächst eine Tokenisierung durch und erstellen dann die Einbettung jedes einzelnen Wortes, ohne auf die Beziehung zwischen den Wörtern im Satz zu achten.
Bei der Tokenisierung werden alle Beziehungen, die im Eingabesatz vorhanden sind, verworfen. Die Positionskodierung versucht, den ursprünglichen zyklischen Charakter wiederherzustellen, indem sie für jedes Wort einen Kontextvektor erzeugt.
Am Ende des vorherigen Schritts erhalten wir für jedes Wort zwei Vektoren: (1) die Einbettung und (2) der Kontextvektor. Diese Vektoren werden addiert, um einen einzigen Vektor für jedes Wort zu erstellen, der dann an den Kodierer übermittelt wird.
Wie bereits erwähnt, haben wir jeden Gedanken an eine Beziehung verloren. Das Ziel der Aufmerksamkeitsschicht ist es, die kontextuellen Beziehungen zwischen verschiedenen Wörtern im Eingabesatz zu erfassen. Dieser Schritt führt dazu, dass für jedes Wort ein Aufmerksamkeitsvektor erzeugt wird.
In dieser Phase wird ein neuronales Feed-Forward-Netzwerk auf jeden Aufmerksamkeitsvektor angewandt, um ihn in ein Format umzuwandeln, das von der nächsten Multi-Head-Aufmerksamkeitsschicht im Decoder erwartet wird.
Der Decoder-Block besteht aus drei Hauptschichten: maskierte Multi-Head-Attention, Multi-Head-Attention und ein positionsbezogenes Feedforward-Netzwerk. Die letzten beiden Schichten, die im Encoder gleich sind, haben wir bereits verstanden.
Der Decoder kommt während des Trainings des Netzwerks ins Spiel und erhält zwei Haupteingaben: (1) die Aufmerksamkeitsvektoren des Eingangssatzes, den wir übersetzen wollen, und (2) die übersetzten Zielsätze auf Englisch.
Bei der Generierung des nächsten englischen Wortes darf das Netzwerk alle Wörter aus dem französischen Wort verwenden. Wenn es sich jedoch um ein bestimmtes Wort in der Zielsequenz (englische Übersetzung) handelt, muss das Netzwerk nur auf die vorherigen Wörter zugreifen, da die Bereitstellung der nächsten Wörter dazu führen würde, dass das Netzwerk "schummelt" und keine Anstrengungen unternimmt, um richtig zu lernen. Hier hat die maskierte Mehrkopf-Aufmerksamkeitsebene ihre Vorteile. Es maskiert die nächsten Wörter, indem es sie in Nullen umwandelt, damit sie vom Aufmerksamkeitsnetzwerk nicht verwendet werden können.
Das Ergebnis der maskierten Multi-Head-Attention-Schicht durchläuft die restlichen Schichten, um das nächste Wort vorherzusagen, indem eine Wahrscheinlichkeitsbewertung erstellt wird.
Diese Architektur war aus den folgenden Gründen erfolgreich:
Tiefe neuronale Netze wie Transformatoren von Grund auf zu trainieren, ist keine leichte Aufgabe und kann mit folgenden Herausforderungen verbunden sein:
Der Einsatz von Transfer Learning kann viele Vorteile haben, wie z.B. die Verkürzung der Trainingszeit, die Beschleunigung des Trainingsprozesses für neue Modelle und die Verkürzung der Projektlaufzeit.
Stell dir vor, du baust ein Modell von Grund auf, um Mandingo in Wolof zu übersetzen, beides Sprachen mit geringen Ressourcen. Das Sammeln von Daten zu diesen Sprachen ist kostspielig. Anstatt all diese Herausforderungen zu meistern, kann man bereits trainierte Deep Neural Networks als Ausgangspunkt für das Training des neuen Modells verwenden.
Solche Modelle wurden auf einem riesigen Datenkorpus trainiert, der von einer anderen Person (einer moralischen Person, einer Organisation usw.) zur Verfügung gestellt wurde, und haben sich bei Übersetzungsaufgaben wie Französisch-Englisch als sehr gut erwiesen.
Wenn du neu im Bereich NLP bist, kannst du dir in diesem Kurs Einführung in die natürliche Sprachverarbeitung in Python die grundlegenden Fähigkeiten aneignen, um Probleme aus der Praxis zu lösen.
Aber was meinst du mit Wiederverwendung von tiefen neuronalen Netzen?
Bei der Wiederverwendung des Modells wählst du ein vortrainiertes Modell aus, das deinem Anwendungsfall ähnlich ist, verfeinerst die Daten des Input-Output-Paares deiner Zielaufgabe und trainierst den Kopf des vortrainierten Modells mit deinen Daten neu.
Die Einführung von Transformers hat zur Entwicklung modernster Transfer-Learning-Modelle geführt, wie z. B.:
Hugging Face ist eine KI-Community und Machine Learning-Plattform, die 2016 von Julien Chaumond, Clément Delangue und Thomas Wolf gegründet wurde. Es zielt darauf ab, NLP zu demokratisieren, indem es Data Scientists, KI-Praktikern und Ingenieuren sofortigen Zugang zu über 20.000 vortrainierten Modellen bietet, die auf der hochmodernen Transformer-Architektur basieren. Diese Modelle können angewendet werden auf:
Hugging Face Transformers bietet außerdem fast 2000 Datensätze und mehrschichtige APIs, die es Programmierern ermöglichen, mit Hilfe von 31 Bibliotheken mit diesen Modellen zu interagieren. Die meisten davon sind Deep Learning-Programme, wie Pytorch, Tensorflow, Jax, ONNX, Fastai, Stable-Baseline 3 usw.
Diese Kurse sind eine großartige Einführung in die Verwendung von Pytorch und Tensorflow für den Aufbau von Deep Convolutional Neural Networks. Weitere Bestandteile der Hugging Face Transformers sind die Pipelines.
Die Methode pipeline() hat die folgende Struktur:
from transformers import pipeline
# To use a default model & tokenizer for a given task(e.g. question-answering)
pipeline("<task-name>")
# To use an existing model
pipeline("<task-name>", model="<model_name>")
# To use a custom model/tokenizer
pipeline('<task-name>', model='<model name>',tokenizer='<tokenizer_name>')Jetzt, wo du Transformers und die Hugging Face Plattform besser verstehst, werden wir dich durch die folgenden realen Szenarien führen: Sprachübersetzung, Sequenzklassifizierung mit Zero-Shot-Klassifizierung, Stimmungsanalyse und Beantwortung von Fragen.
Dieser Datensatz ist auf Datacamp's Dataset wird von Facebook angereichert und wurde erstellt, um die Popularität eines Artikels vor seiner Veröffentlichung vorherzusagen. Die Analyse wird auf der Grundlage der Beschreibungsspalte durchgeführt. Um unsere Beispiele zu veranschaulichen, werden wir nur drei Beispiele aus den Daten verwenden.
Im Folgenden findest du eine kurze Beschreibung der Daten. Sie hat 14 Spalten und 1428 Zeilen.
import pandas as pd
# Load the data from the path
data_path = "datacamp_workspace_export_2022-08-08 07_56_40.csv"
news_data = pd.read_csv(data_path, error_bad_lines=False)
# Show data information
news_data.info()
MariamMT ist ein effizientes Framework für maschinelle Übersetzung. Es nutzt die MarianNMT-Engine unter der Haube, die von Microsoft und vielen akademischen Einrichtungen wie der University of Edinburgh und der Adam-Mickiewicz-Universität in Poznań ausschließlich in C++ entwickelt wurde. Dieselbe Engine steckt derzeit hinter dem Microsoft Translator-Dienst.
Die NLP-Gruppe der Universität Helsinki hat mehrere Übersetzungsmodelle für Hugging Face Transformers veröffentlicht, die alle im folgenden Format vorliegen: Helsinki-NLP/opus-mt-{src}-{tgt}, wobei {src} und {tgt} jeweils der Ausgangs- und der Zielsprache entsprechen.
In unserem Fall ist die Ausgangssprache also Englisch (en) und die Zielsprache ist Französisch (fr)
MarianMT ist eines dieser Modelle, das zuvor mit Marian auf parallel gesammelten Daten bei Opus trainiert wurde.
pip install transformers sentencepiece
from transformers import MarianTokenizer, MarianMTModel# Get the name of the model
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Get the tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Instantiate the model
model = MarianMTModel.from_pretrained(model_name)def format_batch_texts(language_code, batch_texts):
formated_bach = [">>{}<< {}".format(language_code, text) for text in
batch_texts]
return formated_bachdef perform_translation(batch_texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts,
return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts# Check the model translation from the original language (English) to French
translated_texts = perform_translation(english_texts, trans_model, trans_model_tkn)
# Create wrapper to properly format the text
from textwrap import TextWrapper
# Wrap text to 80 characters.
wrapper = TextWrapper(width=80)
for text in translated_texts:
print("Original text: \n", text)
print("Translation : \n", text)
print(print(wrapper.fill(text)))
print("")
Das bedeutet, dass du, wenn deine Trainingslabels Wissenschaft, Politik oder Bildung sind, nicht in der Lage sein wirst, das Label für das Gesundheitswesen vorherzusagen, es sei denn, du trainierst dein Modell unter Berücksichtigung dieses Labels und der entsprechenden Eingabedaten neu.
Mit diesem leistungsstarken Ansatz ist es möglich, das Ziel eines Textes in etwa 15 Sprachen vorherzusagen, ohne dass man die möglichen Bezeichnungen gesehen hat. Wir können dieses Modell verwenden, indem wir es einfach aus dem Hub laden.
Hier geht es darum, die Kategorie jeder der vorherigen Beschreibungen zu klassifizieren, egal ob es sich um Technik, Politik, Sicherheit oder Finanzen handelt.
from transformers import pipelinecandidate_labels = ["tech", "politics", "business", "finance"]my_classifier = pipeline("zero-shot-classification",
model='joeddav/xlm-roberta-large-xnli')#For the first description
prediction = my_classifier(english_texts[0], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)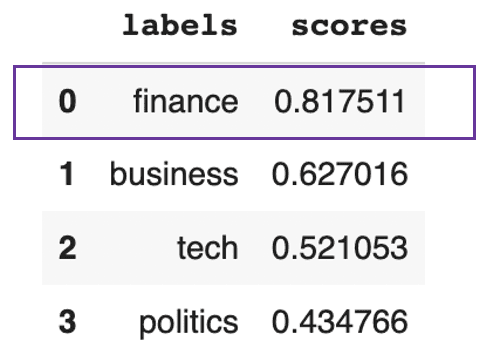
Der Text soll sich hauptsächlich um Finanzen drehen
Dieses Ergebnis zeigt, dass es in dem Text insgesamt zu 81% um Finanzen geht.
Für die letzte Beschreibung erhalten wir das folgende Ergebnis:
#For the last description
prediction = my_classifier(english_texts[-1], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)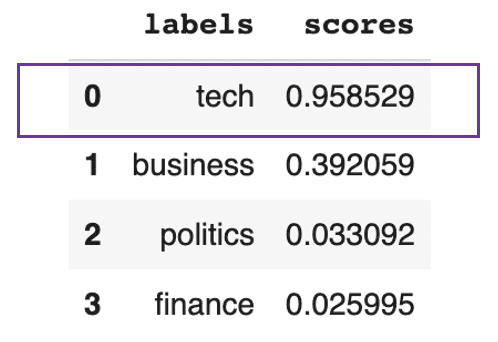
Vorhersage, dass es im Text hauptsächlich um Technik geht
Dieses vorherige Ergebnis zeigt, dass der Text insgesamt zu 95 % technisch ist.
Die meisten Modelle zur Klassifizierung von Gefühlen erfordern ein entsprechendes Training. Das Pipelinemodul Hugging Face macht es einfach, Vorhersagen zur Stimmungsanalyse zu treffen, indem es ein bestimmtes Modell verwendet, das im Hub verfügbar ist.
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)# Run the predictions
distil_bert_model(english_texts[1:])
Das Modell sagte für den ersten Text mit 96%iger Wahrscheinlichkeit eine negative Stimmung voraus, für den zweiten mit 52%iger Wahrscheinlichkeit eine positive.
Wenn du mehr über die Aufgaben der Sentiment-Analyse erfahren möchtest, hilft dir dieser Python-Kurs zur Sentiment-Analyse dabei, deinen eigenen Sentiment-Analyse-Klassifikator mit Python zu erstellen und die Grundlagen von NLP zu verstehen.
Stell dir vor, du hast es mit einem Bericht zu tun, der viel länger ist als der über Apple. Und alles, was dich interessiert, ist das Datum des Ereignisses, das erwähnt wird. Anstatt den ganzen Bericht zu lesen, um die wichtigsten Informationen zu finden, können wir ein Frage-Antwort-Modell von Hugging Face verwenden, das uns die Antwort liefert, die uns interessiert.
Das geht, indem du das Modell mit dem richtigen Kontext (Apples Bericht) und der Frage versiehst, auf die wir eine Antwort finden wollen.
from transformers import AutoModelForQuestionAnswering, AutoTokenizermodel_checkpoint = "deepset/roberta-base-squad2"
task = 'question-answering'
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)QA_input = {
'question': 'when is Apple hosting an event?',
'context': english_texts[-1]
}model_response = QA_model(QA_input)
pd.DataFrame([model_response])
Das Modell antwortete, dass Apples Veranstaltung am 10. September stattfindet, mit einer hohen Wahrscheinlichkeit von 97%.
In diesem Artikel haben wir uns mit der Entwicklung der natürlichen Sprachtechnologie von rekurrenten Netzen zu Transformatoren beschäftigt und wie Hugging Face die Nutzung von NLP durch seine Plattform demokratisiert hat.
Wenn du immer noch zögerst, Transformatoren einzusetzen, ist es unserer Meinung nach an der Zeit, sie auszuprobieren und deinen Geschäftsfällen einen Mehrwert zu verleihen.
Kurse für Python
Kurs
Kurs
Kurs