Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
vLLM (Virtual Large Language Model) est une bibliothèque conçue pour héberger de grands modèles de langage (LLM). Il offre un environnement optimisé pour traiter des tâches de traitement linguistique à grande échelle.
Il y a plusieurs raisons pour lesquelles nous pourrions vouloir accueillir notre propre LLM. L'hébergement d'un modèle localement ou sur une plateforme cloud nous permet de contrôler la confidentialité des données, la personnalisation potentielle du modèle pour mieux répondre à nos besoins spécifiques, et cela peut être moins cher en fonction de l'application.
En outre, vLLM est compatible avec l'API OpenAI API. Cette compatibilité signifie que si nous disposons d'un code existant qui s'interface avec l'infrastructure d'OpenAI, nous pouvons le remplacer par notre propre LLM hébergé en utilisant vLLM sans avoir à modifier la base de code existante.
Dans cet article, je vous guiderai à travers les étapes de la mise en place de vLLM. Nous allons commencer par montrer comment l'exécuter sur notre ordinateur en utilisant Dockerun outil populaire de conteneurisation qui simplifie le processus d'exécution d'applications de manière cohérente dans tous les environnements. Ensuite, nous apprendrons à déployer vLLM sur Google Cloud, ce qui constitue une solution évolutive pour héberger ces modèles et s'assurer qu'ils sont prêts à gérer des tâches plus importantes ou des volumes de trafic plus élevés.
vLLM simplifie l'exécution des LLM avec une configuration efficace optimisée pour une plateforme CUDA, ce qui signifie généralement l'utilisation de GPU NVIDIA pour l'accélération. Cependant, si nous voulons exécuter le modèle sur un processeur, nous pouvons utiliser l'image Docker que vLLM fournit spécifiquement pour l'utilisation du processeur. Cette flexibilité nous permet d'héberger des modèles même si nous n'avons pas accès à un environnement CUDA. Pour héberger vLLM sur une plateforme CUDA, reportez-vous à leur guide de démarrage rapide.
Comme la plupart d'entre nous n'ont pas accès à des GPU haut de gamme, nous nous concentrerons sur la configuration de vLLM pour qu'il fonctionne sur un CPU. Cela nous permet de continuer à expérimenter les LLM en utilisant les ressources dont nous disposons.
Pour simplifier le processus, nous utiliserons Docker, un outil populaire qui permet d'empaqueter les applications et leurs dépendances dans des conteneurs. Considérez un conteneur comme une unité légère et portable qui comprend tout ce qui est nécessaire pour faire fonctionner un logiciel spécifique. En utilisant Docker, nous n'avons pas à nous préoccuper de l'installation manuelle de vLLM ou des problèmes de compatibilité potentiels sur notre système.
vLLM propose une image Docker prête à l'emploi, conçue spécifiquement pour l'exécution de l'unité centrale. Cette image contient tous les composants nécessaires à l'exécution de vLLM, ce qui nous permet de nous concentrer sur l'utilisation du modèle plutôt que sur la complexité de sa mise en place. Cela signifie que nous pouvons commencer à exécuter nos LLM rapidement et efficacement sur un processeur.
Tout d'abord, nous devons créer une image Docker qui nous permettra d'exécuter vLLM sur notre ordinateur. Le référentiel vLLM dépôt vLLM fournit des Dockerfiles avec toutes les instructions nécessaires pour construire une image qui peut exécuter vLLM sur un CPU.
Dockerfile.cpu pour les unités centrales ordinaires.Dockerfile.arm pour les processeurs ARM tels que ceux des Mac modernes.Comme j'ai un Mac avec un processeur M2, j'utiliserai le fichier .arm. Pour construire l'image, nous devons d'abord cloner ou télécharger le dépôt, puis exécuter cette commande à l'intérieur de celui-ci :
docker build -f Dockerfile.arm -t vllm-cpu --shm-size=4g .Voici une brève description des fonctions de cette commande :
docker build: Cette commande crée une image Docker à partir d'un fichier Docker.-f Dockerfile.arm: Spécifie le fichier Docker à utiliser.-t vllm-cpu: Marquez l'image comme vllm-cpu pour faciliter la référence (il aurait pu s'agir d'un autre nom).--shm-size=4g: Alloue 4 gigaoctets de mémoire partagée, ce qui permet d'améliorer les performances.vLLM utilise Hugging Face, une plateforme qui facilite la gestion des modèles, pour rationaliser le processus d'hébergement des modèles. Voici comment nous pouvons commencer :
meta-llama/Llama-3.2-1B-Instruct, car il s'agit d'un modèle plus petit adapté aux premiers essais. Sur la page du modèle, il peut y avoir une option pour demander l'accès. Suivez les instructions fournies pour obtenir l'accès.Avec notre image Docker construite et le jeton Hugging Face prêt, nous pouvons maintenant exécuter le modèle vLLM à l'aide de la commande suivante :
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16Décortiquons cette commande :
docker run: Cette commande lance un conteneur basé sur l'image Docker spécifiée.-it: Exécute le conteneur de manière interactive avec un accès terminal.--rm: Retire automatiquement le conteneur lorsqu'il est arrêté.-p 8000:8000: Associe le port 8000 du conteneur au port 8000 de notre machine, rendant ainsi le service disponible localement.--env "HUGGING_FACE_HUB_TOKEN=": Définit le jeton Hugging Face comme une variable d'environnement, permettant à vLLM de se connecter à l'API Hugging Face. Remplacez <replace_with_hf_token> par le jeton que nous avons créé.vllm-cpu: Spécifie le nom de l'image Docker que nous avons construite précédemment.--model meta-llama/Llama-3.2-1B-Instruct: Indique le modèle à exécuter.--dtype float16: Utilisez le type de données float16 car le modèle l'exige lorsqu'il est exécuté sur l'unité centrale.Lorsque nous lançons cette commande, le serveur mettra un certain temps à être prêt car il doit télécharger le LLM. Il sera prêt lorsque nous verrons quelque chose de ce genre dans le terminal :
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)L'une des grandes caractéristiques de vLLM est sa compatibilité avec l'API OpenAI. Cela signifie que si nous disposons d'un code existant conçu pour interagir avec l'infrastructure d'OpenAI, nous pouvons facilement utiliser ce même code pour communiquer avec un modèle hébergé via vLLM.
Cette compatibilité permet une transition en douceur sans modifier notre base de code existante. Ainsi, lorsque nous configurons vLLM, il devient simple de continuer à utiliser nos outils et commandes familiers pour interagir avec le LLM, ce qui rend le processus d'intégration efficace et convivial.
Voici un exemple d'envoi d'un message à notre serveur local fonctionnant sur Docker :
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
]
)
print(completion.choices[0].message.content)Notez que nous avons utilisé la clé API "EMPTY" ci-dessus. Il s'agit de la clé par défaut. Nous pourrions exiger une clé pour accéder au modèle en la spécifiant avec le paramètre --api-key. Par exemple :
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16 --api-key supersecretkeyEnsuite, dans ce cas, nous devons remplacer la clé en haut du code :
openai_api_key = "supersecretkey"L'hébergement d'un LLM sur Google Cloud à l'aide de vLLM peut constituer une solution pour le déploiement des LLM. Décomposons les étapes mentionnées et développons-les pour plus de clarté.
Tout d'abord, nous devons accéder à la console du cloud de Google. Nous pouvons le faire en naviguant vers Google Cloud Console dans notre navigateur web. Si nous n'avons pas encore de compte Google, nous devons en créer un pour utiliser les services Google Cloud.
Dans la Google Cloud Console, localisez le menu déroulant du projet en haut de l'écran et sélectionnez " Nouveau projet. "

Saisissez vllm-demo comme nom de projet, afin de pouvoir l'identifier plus facilement par la suite.
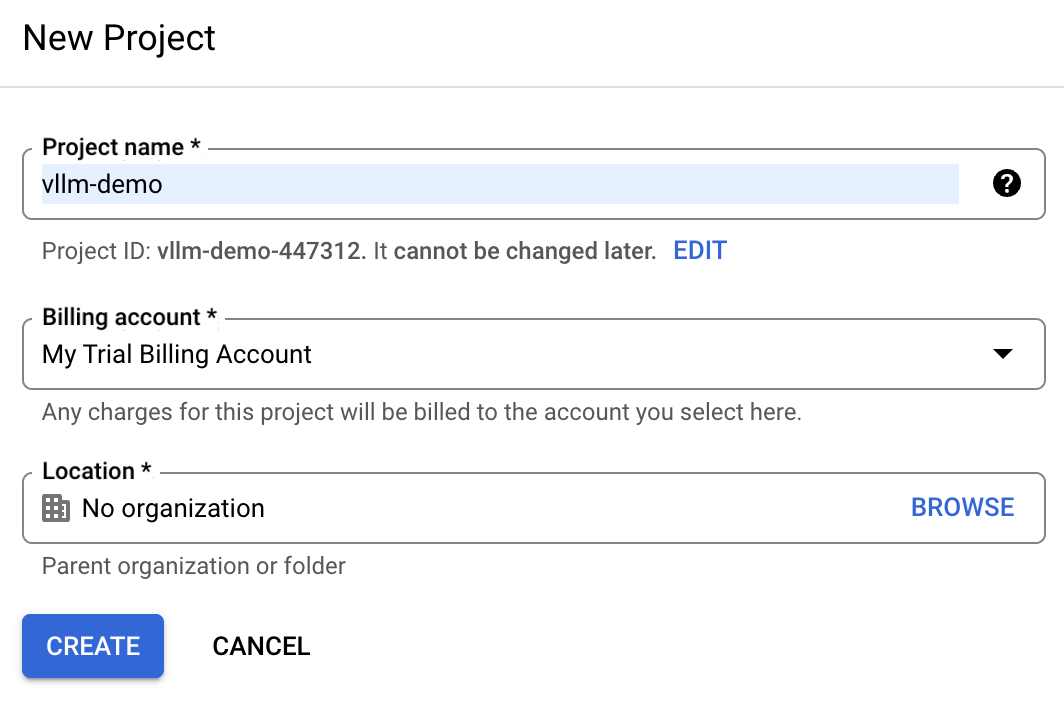
Si nous disposons déjà d'un compte Google cloud, il se peut que le compte de facturation d'essai ne soit pas disponible. Dans ce cas, nous devons créer un nouveau compte de facturation. Pour ce faire, accédez à la section "Facturation" et suivez les étapes pour sélectionner un compte de facturation existant ou en créer un nouveau.
Le registre d'artefacts est un service qui nous permet de stocker et de gérer des images de conteneurs. Nous l'utilisons pour stocker l'image Docker que nous utiliserons pour exécuter vLLM.
Dans la console cloud, recherchez "artefact" pour ouvrir le registre des artefacts.
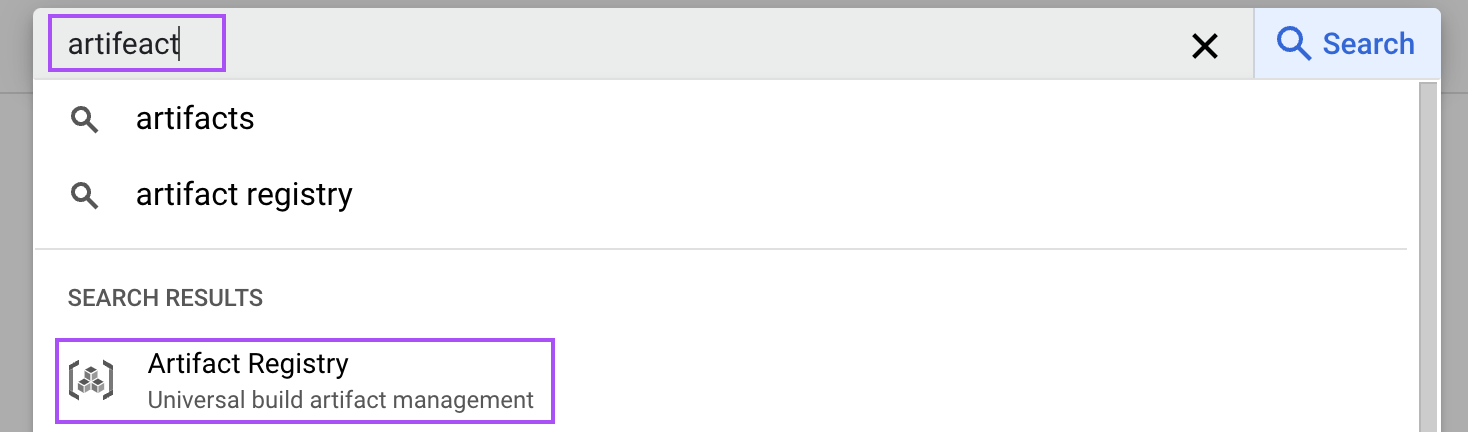
Ensuite, activez-le pour notre projet. Cette étape est nécessaire pour stocker l'image Docker de notre configuration vLLM.

Nous devons maintenant créer un référentiel d'artefacts pour stocker nos images de conteneurs. Naviguez jusqu'au registre des artefacts et cliquez sur "Créer un référentiel".

Nommez le dépôt vllm-cpu et choisissez "Docker" comme format. Spécifiez l'emplacement comme us-central1 pour optimiser les performances en fonction de nos exigences de déploiement. Le reste de la configuration peut être laissé avec les valeurs par défaut.

Tout comme nous l'avons fait pour notre machine locale, nous devons construire l'image Docker, puis la télécharger (push) vers notre référentiel vllm-cpu Google Cloud. Pour ce faire, nous utiliserons le shell cloud situé dans le coin supérieur droit.
 .
.
Dans ce terminal, clonez le dépôt GitHub vLLM avec la commande suivante pour récupérer les fichiers nécessaires :
git clone https://github.com/vllm-project/vllm.gitNaviguez vers le répertoire vLLM cloné à l'aide du terminal.
cd vllmConstruire l'image Docker avec la commande spécifiée, qui utilise le fichier Dockerfile fourni configuré pour l'utilisation du processeur :
docker build \
-t us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latest \
-f Dockerfile.cpu .Une fois que l'image Docker est construite, poussez-la dans notre dépôt d'artefacts. Cette action consiste à télécharger l'image afin qu'elle puisse être utilisée ultérieurement par les services Google Cloud :
docker push us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latestGoogle Cloud Run permet le déploiement d'applications conteneurisées. Nous utilisons ce service pour déployer l'image que nous venons de construire.
Tapez "cloud run" dans la barre de recherche et ouvrez le service "Cloud Run".

Cliquez ensuite sur le bouton "Créer un service" :
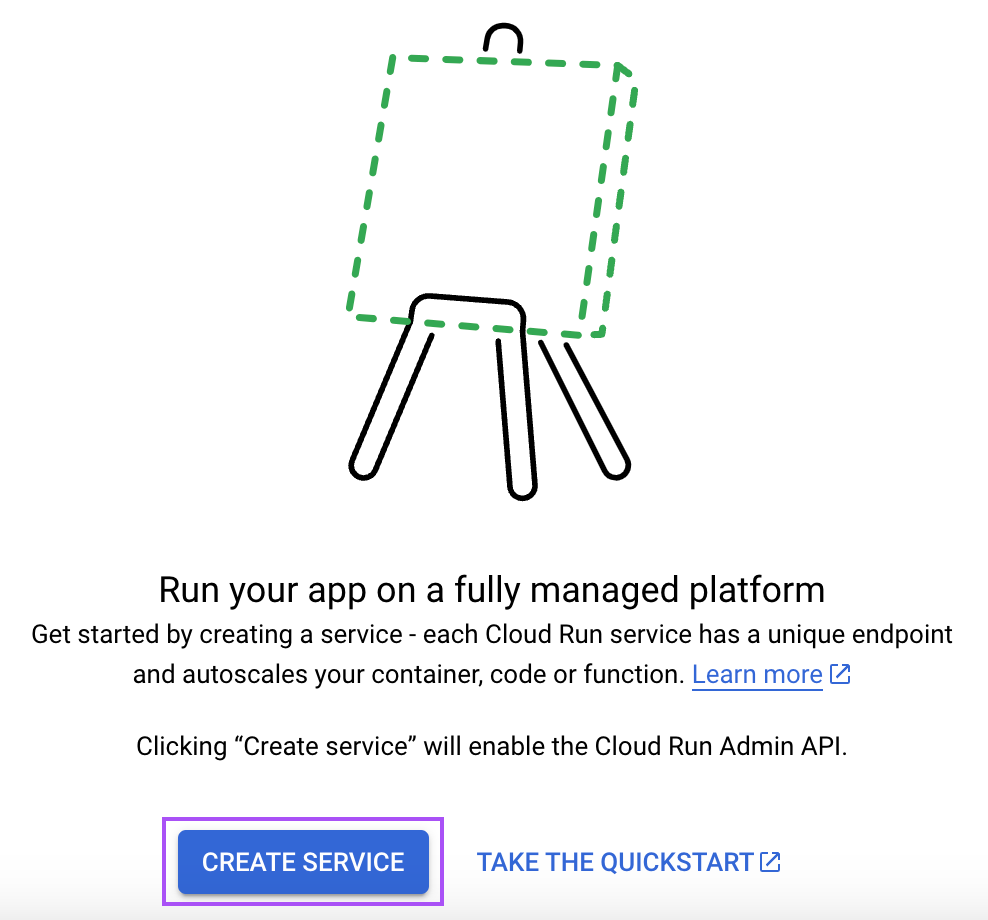
Suivez ensuite les étapes suivantes :
8000, qui est utilisé par vLLM.HUGGING_FACE_HUB_TOKEN et collez-y notre jeton. Ce jeton permet à vLLM d'accéder aux modèles de Hugging Face.--model=meta-llama/Llama-3.2-1B pour spécifier le modèle désiré.Une fois toutes les configurations définies (les autres options peuvent être laissées avec les valeurs par défaut), cliquez sur le bouton "Créer" au bas de la page. Attendez que le service soit prêt et accédez à la page de ce service. Nous y trouvons l'URL du service que nous pouvons utiliser pour communiquer avec le LLM.
Il devrait ressembler à ceci :
https://vllm-llama-577126904161.us-central1.run.appNous pouvons interagir avec le LLM en utilisant Python comme nous l'avons fait lorsque nous avons exécuté le modèle localement. Il suffit de modifier l'URL du script :
# Replace with your service URL
openai_api_base = "https://vllm-llama-577126904161.us-central1.run.app/v1"Avertissement : Si vous suivez ces étapes, n'oubliez pas que le fait de conserver le registre des artefacts en direct vous coûtera de l'argent. N'oubliez donc pas de dissocier le compte de facturation après avoir suivi ce guide, sinon vous serez facturé même si personne ne l'utilise.
Au moment de la rédaction de ce tutoriel, la prise en charge du GPU pour Google Cloud Run est disponible sur demande. Cela signifie que nous devons demander spécifiquement l'accès à cette fonctionnalité. Une fois qu'il a été accordé, l'exécution du vLLM à l'aide d'un GPU augmentera de manière significative ses performances par rapport à l'utilisation du CPU. Cela est particulièrement utile pour traiter les modèles linguistiques de grande taille, car les GPU sont conçus pour traiter les tâches parallèles plus efficacement.
Si nous obtenons l'accès au support GPU, nous avons la possibilité de rationaliser notre flux de travail. Dans ce scénario, nous n'avons pas besoin de passer par le processus de construction de notre propre image Docker. Au lieu de cela, nous pouvons directement créer un service utilisant l'image préexistante vllm/vllm-openai:latest. Cette image est optimisée pour fonctionner avec le GPU, ce qui nous permet de déployer nos modèles rapidement et efficacement sans les étapes de configuration supplémentaires requises pour les configurations CPU.
Une fois l'accès au GPU approuvé et le service configuré à l'aide de l'image fournie, notre déploiement vLLM peut tirer pleinement parti de la puissance et de la vitesse offertes par les GPU, ce qui le rend bien adapté aux applications en temps réel et aux tâches de traitement linguistique à forte demande.
Pour ceux qui recherchent d'autres options d'hébergement, des plateformes comme RunPod offrent des services rationalisés pour l'hébergement de grands modèles linguistiques. RunPod, par exemple, fournit une configuration sans serveur qui simplifie le processus de déploiement.
Bien que cette option soit conviviale et rapide à mettre en place, il est important de garder à l'esprit que la commodité a souvent un prix plus élevé. Si les contraintes budgétaires sont un facteur, nous pourrions vouloir mettre en balance la facilité d'utilisation et les coûts associés à ces services.
Dans ce tutoriel, nous avons exploré le processus de configuration et d'hébergement de vLLM à la fois localement et sur Google Cloud.
Nous avons appris à construire et à exécuter des images Docker spécifiquement adaptées aux CPU, garantissant l'accessibilité même sans ressources GPU haut de gamme. En outre, nous avons envisagé de déployer vLLM sur Google Cloud, qui offre une solution évolutive pour traiter des tâches plus importantes.
Apprenez l'IA avec ces cours !
Cours
Cours