Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
vLLM (Virtual Large Language Model) é uma biblioteca projetada para hospedar modelos de linguagem grandes (LLMs). Ele oferece um ambiente otimizado para lidar com tarefas de processamento de idiomas em grande escala.
Há vários motivos pelos quais você pode querer sediar seu próprio LLM. A hospedagem de um modelo localmente ou em uma plataforma de nuvem nos dá controle sobre a privacidade dos dados, a possível personalização do modelo para atender melhor às nossas necessidades específicas e pode ser mais barata, dependendo do aplicativo.
Além disso, o vLLM é compatível com a API OpenAI. Essa compatibilidade significa que, se tivermos um código existente que faça interface com a infraestrutura da OpenAI, poderemos substituí-lo por nosso próprio LLM hospedado usando o vLLM sem precisar modificar a base de código existente.
Neste artigo, orientarei você nas etapas de configuração do vLLM. Começaremos demonstrando como executá-lo em nosso computador usando o Dockeruma ferramenta popular de conteinerização que simplifica o processo de execução de aplicativos de forma consistente em vários ambientes. Em seguida, aprenderemos como implantar o vLLM no Google Cloud, fornecendo uma solução dimensionável para hospedar esses modelos e garantir que eles estejam prontos para lidar com tarefas maiores ou volumes de tráfego mais altos.
O vLLM simplifica a execução de LLMs com uma configuração eficiente otimizada para uma plataforma CUDA, o que normalmente significa usar GPUs NVIDIA para aceleração. No entanto, se quisermos executar o modelo em uma CPU, poderemos usar a imagem do Docker que o vLLM fornece especificamente para o uso da CPU. Essa flexibilidade nos permite hospedar modelos mesmo se não tivermos acesso a um ambiente habilitado para CUDA. Para hospedar o vLLM em uma plataforma CUDA, consulte o seu guia de início rápido.
Como a maioria de nós não tem acesso a GPUs de ponta, vamos nos concentrar na configuração do vLLM para ser executado em uma CPU. Isso garante que ainda possamos fazer experiências com LLMs usando os recursos que temos.
Para simplificar o processo, usaremos o Docker, que é uma ferramenta popular que nos permite empacotar aplicativos e suas dependências em contêineres. Pense em um contêiner como uma unidade leve e portátil que inclui tudo o que é necessário para executar um software específico. Ao usar o Docker, não precisamos nos preocupar em instalar manualmente o vLLM ou lidar com possíveis problemas de compatibilidade em nosso sistema.
O vLLM oferece uma imagem do Docker pronta para uso, projetada especificamente para a execução da CPU. Essa imagem contém todos os componentes necessários para executar o vLLM, permitindo que você se concentre em usar o modelo em vez de se preocupar com as complexidades de sua configuração. Isso significa que podemos começar a executar nossos LLMs de forma rápida e eficiente em uma CPU.
Primeiro, precisamos criar uma imagem do Docker que nos permitirá executar o vLLM em nosso computador. O repositório repositório vLLM fornece Dockerfiles com todas as instruções necessárias para criar uma imagem que possa executar o vLLM em uma CPU.
Dockerfile.cpu para CPUs comuns.Dockerfile.arm para CPUs ARM, como as dos Macs modernos.Como tenho um Mac com um processador M2, usarei o arquivo .arm. Para criar a imagem, primeiro clonamos ou baixamos o repositório e, em seguida, executamos este comando dentro dele:
docker build -f Dockerfile.arm -t vllm-cpu --shm-size=4g .Aqui está um resumo rápido do que esse comando faz:
docker build: Esse comando cria uma imagem do Docker a partir de um Dockerfile.-f Dockerfile.arm: Especifica o Dockerfile a ser usado.-t vllm-cpu: Marca a imagem como vllm-cpu para facilitar a referência (poderia ter outro nome).--shm-size=4g: Aloca 4 gigabytes de memória compartilhada, o que ajuda a melhorar o desempenho.A vLLM usa o Hugging Face, uma plataforma que facilita o gerenciamento de modelos, para agilizar o processo de hospedagem de modelos. Veja como você pode começar:
meta-llama/Llama-3.2-1B-Instruct, pois é um modelo menor adequado para testes iniciais. Na página do modelo, pode haver uma opção para solicitar acesso. Siga as instruções fornecidas para obter acesso.Com a nossa imagem do Docker criada e o token Hugging Face pronto, agora podemos executar o modelo vLLM usando o seguinte comando:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16Vamos desvendar esse comando:
docker run: Esse comando executa um contêiner com base na imagem do Docker especificada.-it: Executa o contêiner interativamente com acesso ao terminal.--rm: Remove automaticamente o contêiner quando ele é interrompido.-p 8000:8000: Mapeia a porta 8000 do contêiner para a porta 8000 em nosso computador, tornando o serviço disponível localmente.--env "HUGGING_FACE_HUB_TOKEN=": Define o token do Hugging Face como uma variável de ambiente, permitindo que o vLLM se conecte à API do Hugging Face. Substitua <replace_with_hf_token> pelo token real que criamos.vllm-cpu: Especifica o nome da imagem do Docker que criamos anteriormente.--model meta-llama/Llama-3.2-1B-Instruct: Indica o modelo a ser executado.--dtype float16: Use o tipo de dados float16 porque o modelo exige isso ao ser executado na CPU.Quando você executar esse comando, o servidor demorará um pouco para ficar pronto, pois precisará fazer o download do LLM. Ele estará pronto quando virmos algo assim no terminal:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)Um dos excelentes recursos do vLLM é sua compatibilidade com a API OpenAI. Isso significa que, se tivermos um código existente projetado para interagir com a infraestrutura da OpenAI, poderemos usar facilmente esse mesmo código para nos comunicarmos com um modelo hospedado via vLLM.
Essa compatibilidade permite uma transição suave sem modificar nossa base de código existente. Portanto, quando configuramos o vLLM, fica fácil continuar usando nossas ferramentas e comandos familiares para interagir com o LLM, tornando o processo de integração eficiente e fácil de usar.
Aqui está um exemplo de como enviar uma mensagem ao nosso servidor local em execução no Docker:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
]
)
print(completion.choices[0].message.content)Observe que usamos a chave de API "EMPTY" acima. Essa é a chave padrão. Poderíamos exigir uma chave para acessar o modelo, especificando-a com o parâmetro --api-key. Por exemplo:
docker run -it --rm -p 8000:8000 \
--env "HUGGING_FACE_HUB_TOKEN=<replace_with_hf_token>" \
vllm-cpu --model meta-llama/Llama-3.2-1B-Instruct \
--dtype float16 --api-key supersecretkeyEntão, nesse caso, precisamos substituir a chave na parte superior do código:
openai_api_key = "supersecretkey"A hospedagem de um LLM no Google Cloud usando o vLLM pode oferecer uma solução para a implantação de LLMs. Vamos detalhar as etapas mencionadas e expandi-las para maior clareza.
Primeiro, precisamos acessar o Google Cloud Console. Você pode fazer isso navegando até o Google Cloud Console em seu navegador da Web. Se ainda não tivermos uma conta do Google, precisaremos criar uma para usar os serviços do Google Cloud.
No Console do Google Cloud, localize o menu suspenso do projeto na parte superior da tela e selecione "Novo projeto".

Digite vllm-demo como o nome do projeto, para facilitar a identificação posterior.
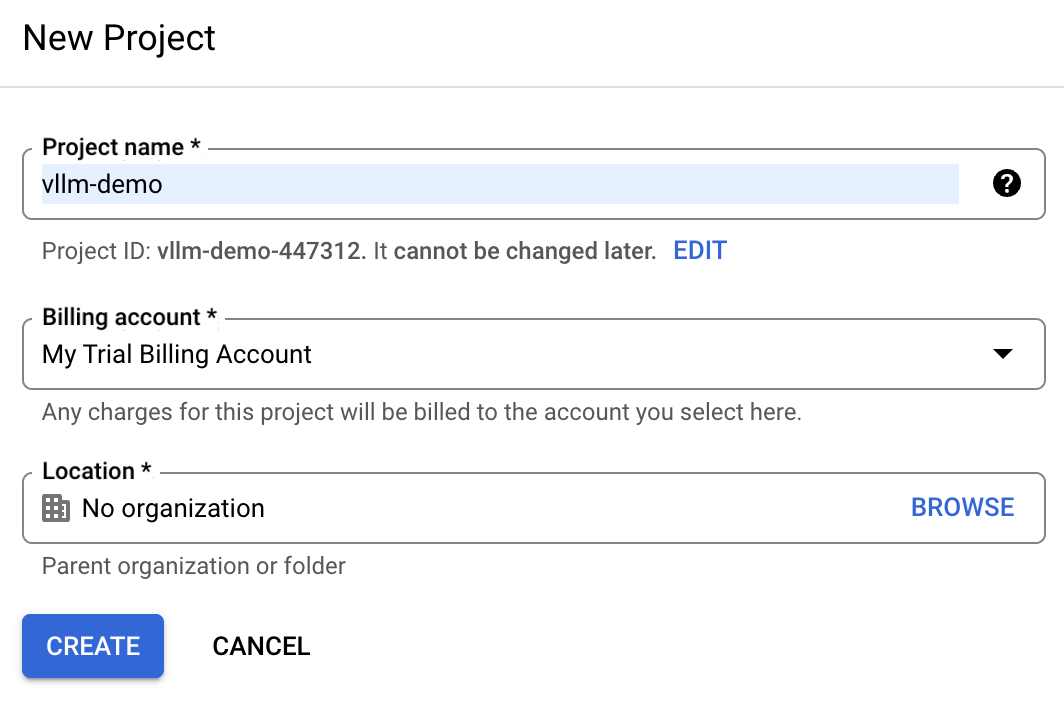
Se você já tiver uma conta de nuvem do Google, a conta de cobrança de avaliação poderá não estar disponível. Nesse caso, precisamos criar uma nova conta de cobrança. Para fazer isso, navegue até a seção "Billing" (Faturamento) e siga as etapas para selecionar uma conta de faturamento existente ou criar uma nova.
O Artifact Registry é um serviço que nos permite armazenar e gerenciar imagens de contêineres. Nós o usamos para armazenar a imagem do Docker que usaremos para executar o vLLM.
No Console da nuvem, pesquise por "artefato" para abrir o Registro de artefatos.
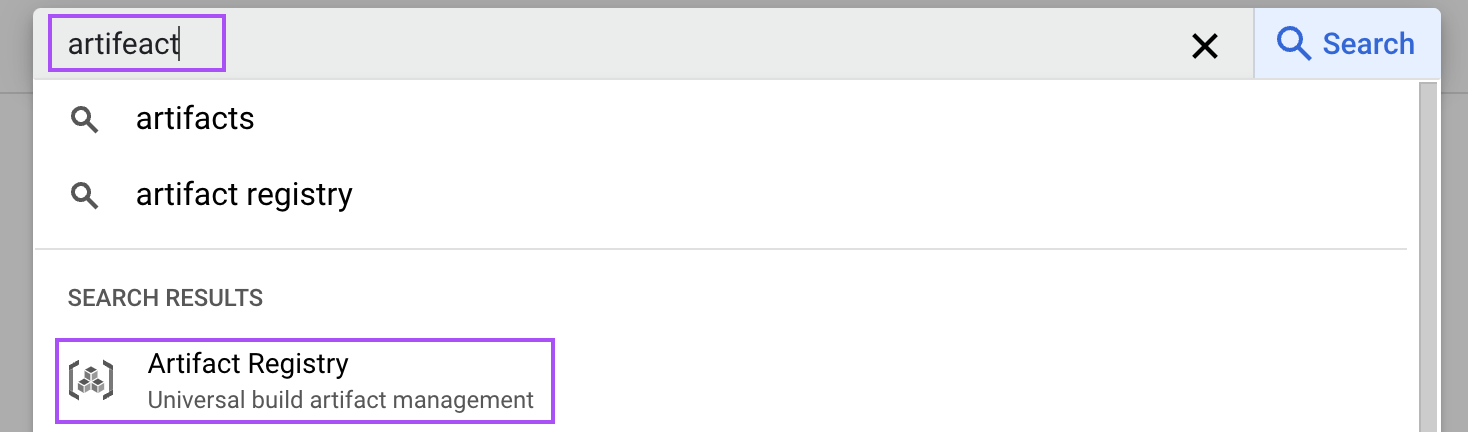
Em seguida, habilite-o para o nosso projeto. Esta etapa é necessária para armazenar a imagem do Docker da nossa configuração vLLM.

Agora, precisamos criar um repositório de artefatos para armazenar nossas imagens de contêineres. Navegue até o Registro de artefatos e clique em "Criar repositório".

Nomeie o repositório como vllm-cpu e escolha "Docker" como o formato. Especifique o local como us-central1 para otimizar o desempenho com base em nossos requisitos de implementação. O restante da configuração pode ser deixado com os valores padrão.

Assim como fizemos em nossa máquina local, precisamos criar a imagem do Docker e, em seguida, carregá-la (push) em nosso repositório vllm-cpu do Google Cloud. Faremos isso usando o shell de nuvem localizado no canto superior direito.
 .
.
Nesse terminal, clone o repositório vLLM do GitHub com o seguinte comando para obter os arquivos necessários:
git clone https://github.com/vllm-project/vllm.gitNavegue até o diretório vLLM clonado usando o terminal.
cd vllmCrie a imagem do Docker com o comando especificado, que usa o Dockerfile fornecido configurado para uso da CPU:
docker build \
-t us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latest \
-f Dockerfile.cpu .Depois que a imagem do Docker for criada, envie-a para o nosso repositório de artefatos. Essa ação envolve o upload da imagem para que ela possa ser usada posteriormente pelos serviços do Google Cloud:
docker push us-central1-docker.pkg.dev/vllm-demo/vllm-cpu/vllm-openai:latestO Google Cloud Run permite a implantação de aplicativos em contêineres. Usamos esse serviço para implementar a imagem que acabamos de criar.
Digite "cloud run" na barra de pesquisa e abra o serviço "Cloud Run".

A partir daí, clique no botão "Create Service" (Criar serviço):
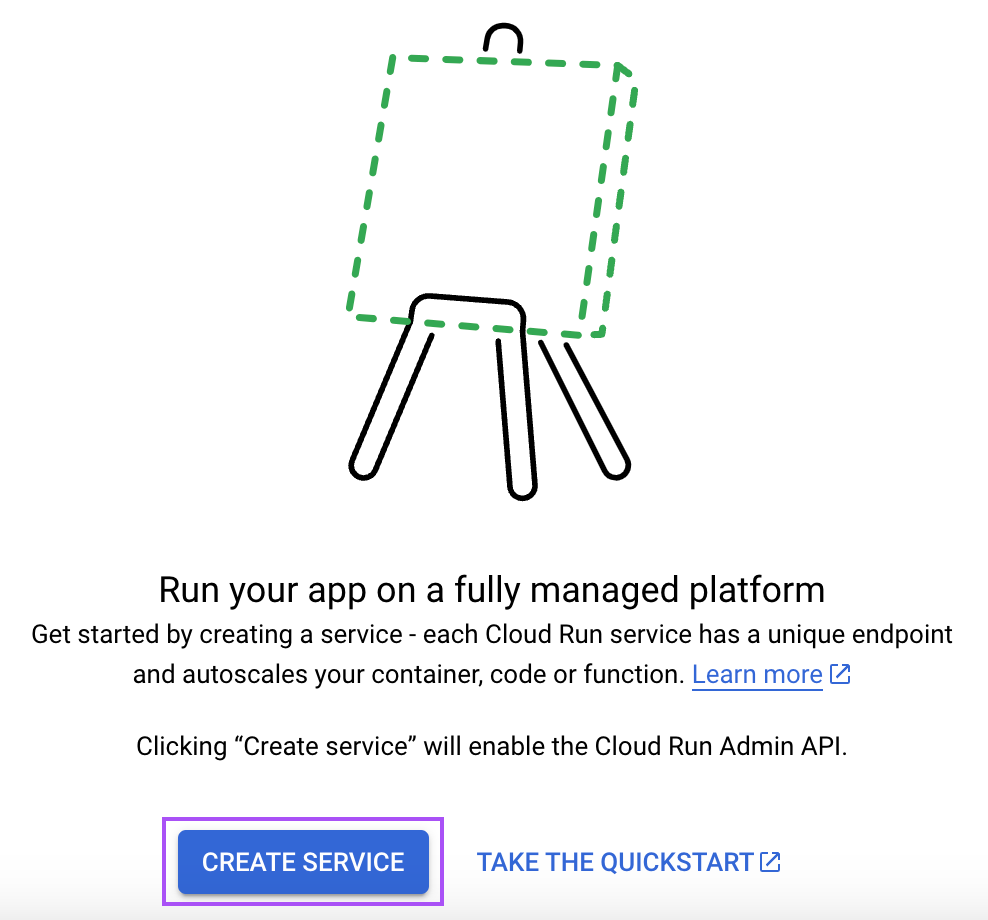
Em seguida, siga estas etapas:
8000, que é usada pelo vLLM.HUGGING_FACE_HUB_TOKEN e cole nosso token aqui. Esse token permite que o vLLM acesse modelos do Hugging Face.--model=meta-llama/Llama-3.2-1B para especificar o modelo desejado.Com toda a configuração definida (as outras opções podem ser deixadas com os valores padrão), clique no botão "Create" (Criar) na parte inferior da página. Aguarde até que o serviço esteja pronto e navegue até a página do serviço. Lá, temos o URL do serviço que podemos usar para nos comunicarmos com o LLM.
Ela deve ter a seguinte aparência:
https://vllm-llama-577126904161.us-central1.run.appPodemos interagir com o LLM usando Python, como fizemos ao executar o modelo localmente. Só precisamos alterar o URL no script:
# Replace with your service URL
openai_api_base = "https://vllm-llama-577126904161.us-central1.run.app/v1"Aviso: Se você estiver seguindo essas etapas, lembre-se de que manter o registro do artefato ativo custará dinheiro. Portanto, lembre-se de desvincular a conta de cobrança depois de seguir este guia, ou você será cobrado em mesmo que ninguém o use.
No momento em que este tutorial foi escrito, o suporte a GPU para o Google Cloud Run estava disponível mediante solicitação. Isso significa que precisamos solicitar especificamente o acesso a esse recurso. Uma vez concedido, a execução do vLLM usando uma GPU aumentará significativamente seu desempenho em comparação com o uso da CPU. Isso é particularmente vantajoso para lidar com modelos de linguagem grandes, pois as GPUs são projetadas para processar tarefas paralelas com mais eficiência.
Se obtivermos acesso ao suporte de GPU, teremos a opção de otimizar nosso fluxo de trabalho. Nesse cenário, não precisamos passar pelo processo de criar nossa própria imagem do Docker. Em vez disso, podemos criar diretamente um serviço utilizando a imagem pré-existente vllm/vllm-openai:latest. Essa imagem é otimizada para funcionar com GPU, o que nos permite implantar nossos modelos de forma rápida e eficaz, sem as etapas de configuração adicionais necessárias para as configurações de CPU.
Depois que o acesso à GPU for aprovado e configurarmos o serviço usando a imagem fornecida, nossa implantação do vLLM poderá aproveitar ao máximo a potência e a velocidade oferecidas pelas GPUs, tornando-a adequada para aplicativos em tempo real e tarefas de processamento de linguagem de alta demanda.
Para aqueles que procuram opções alternativas de hospedagem, plataformas como RunPod oferecem serviços simplificados para a hospedagem de grandes modelos de linguagem. O RunPod, por exemplo, oferece uma configuração sem servidor que simplifica o processo de implementação.
Embora essa opção seja fácil de usar e rápida de configurar, é importante ter em mente que a conveniência geralmente vem com um preço mais alto. Se as restrições orçamentárias forem um fator, talvez queiramos pesar a facilidade de uso em relação aos custos associados a esses serviços.
Neste tutorial, exploramos o processo de configuração e hospedagem do vLLM localmente e no Google Cloud.
Aprendemos a criar e executar imagens do Docker especificamente adaptadas para CPUs, garantindo acessibilidade mesmo sem recursos de GPU de ponta. Além disso, analisamos a implantação do vLLM no Google Cloud, que oferece uma solução dimensionável para lidar com tarefas maiores.
Aprenda IA com estes cursos!
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Bhavishya Pandit
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
