
Kurs
KI in der Produktion mit FastAPI bereitstellen
4 Std.
4.5K
Mistral hat kürzlich seine ersten Open-Source-Multimodal-Audiomodelle Voxtral Small und Voxtral Mini vorgestellt, die auf der Mistral 3B-Architektur basieren und speziell für Audioverstehens- und Transkriptionsaufgaben optimiert sind.
In diesem Blog geht's vor allem um den Voxtral Mini 3B, ein kompaktes Open-Source-Modell, das für Echtzeit-Audio-zu-Text-Aufgaben wie Transkription, Zusammenfassung und Q&A entwickelt wurde. Dank seiner effizienten Größe und der Unterstützung für kontextbezogene Schlussfolgerungen ist Voxtral Mini besonders leistungsstark, wenn es mit Inferenz-Frameworks mit hohem Durchsatz wie vLLM kombiniert wird. Damit eignet es sich ideal für die Entwicklung schneller Offline-Audioanwendungen.
In diesem Tutorial zeige ich dir, wie du:
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter„The Median “ schicken , der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
Voxtral ist Mistrals komplett offene Audio-Modellfamilie, die für super Sprachverständnis entwickelt wurde. Voxtral gibt's in zwei Modellgrößen:
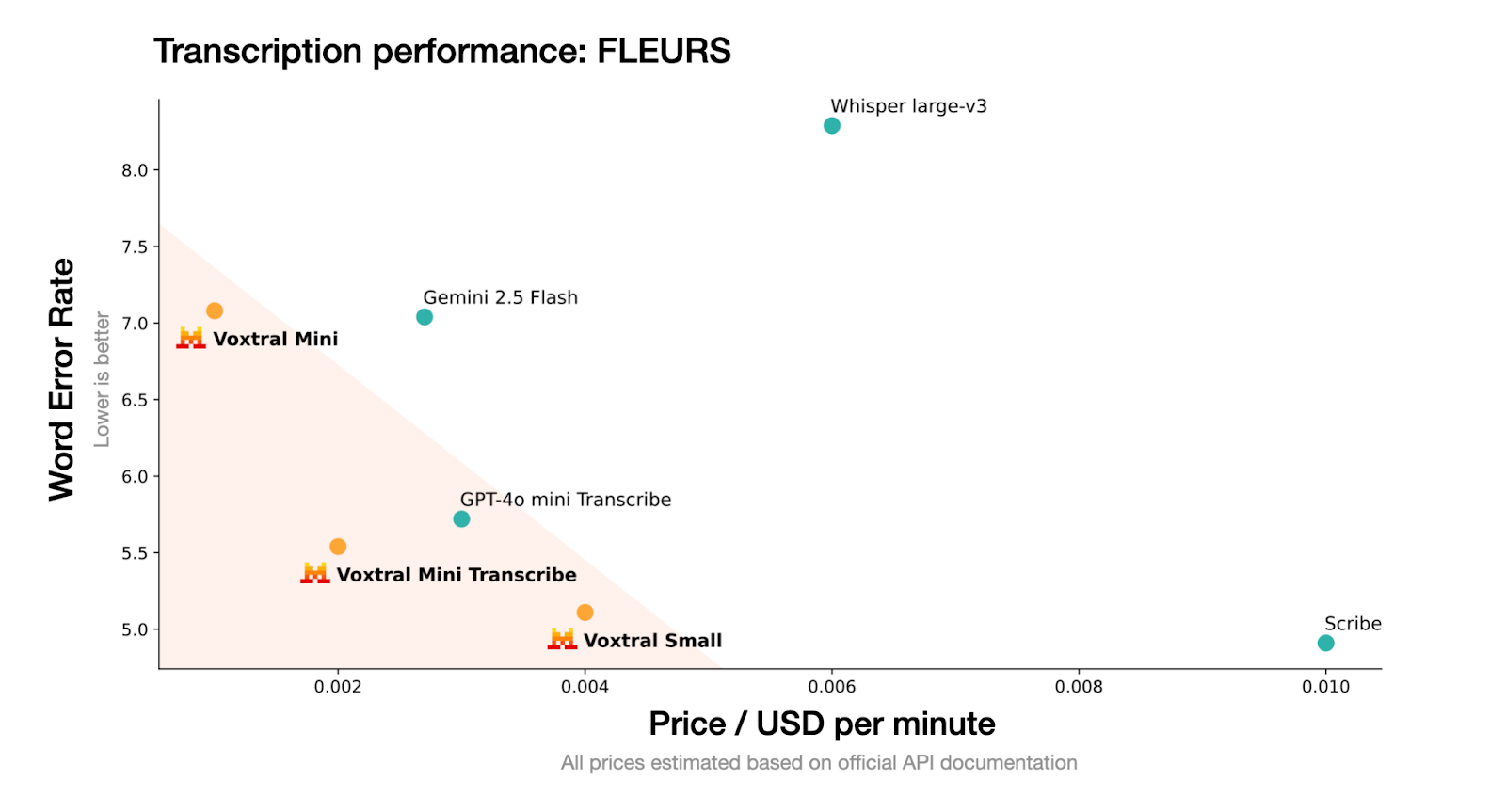
Quelle: Mistral
Voxtral nimmt rohe Audio-Dateien (wie .wav oder .mp3) und kann Transkriptionen und Zusammenfassungen von gesprochenen Inhalten effizient erstellen. Voxtral ist eine kleinere Version, die für schnelle Schlussfolgerungen und den Offline-Einsatz optimiert ist.
Es folgt dem Modellformat von Mistral und ist mit Hochdurchsatz-Inferenz-Frameworks wie vLLM, was es super für Echtzeit-Transkriptionen oder einfache Sprachanwendungen macht.
In diesem Abschnitt zeige ich dir, wie du Voxtral Mini 3B mit vLLM auf einem Colab Pro mit aktivierter T4-GPU nutzen kannst. vLLM wurde wegen seiner hohen Durchsatzrate und niedrigen Latenz ausgewählt, die ideal für Modelle wie Voxtral sind, die schnelle Streaming-Antworten mit Audio-Unterstützung brauchen.
Außerdem werden wir PyNGrok , um den vLLM-Server über einen öffentlichen Endpunkt freizugeben, sodass er für Anwendungen auf deinem lokalen Rechner zugänglich ist.
Fangen wir damit an, die Abhängigkeiten in unserer Colab-Umgebung zu installieren. Führ den folgenden Befehl in der Colab-Zelle aus:
!uv pip install -U transformers accelerate "vllm[audio]" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightlyZuerst installieren wir die benötigten Bibliotheken mit uv, einem schnelleren Python-Paketinstallationsprogramm. Das holt die nächtliche Version von vllm[audio], die experimentelle Unterstützung für Audio-Sprachmodelle wie Voxtral enthält. Wenn du „ uv “ nicht installiert hast, installiere zuerst „ uv “, indem du den folgenden Code ausführst:
!pip install uvAls Nächstes installieren wir das Paket „ mistral-common “, das wichtige Tools für die Interaktion mit Voxtral und anderen Modellen der Mistral-Familie enthält. Dieses Paket enthält Tokenizer, die mit offiziellen Implementierungen abgestimmt sind, sowie eine Pydantic-basierte Validierung für Nachrichtenstrukturen.
!pip install mistral-common --upgrade
!python -c "import mistral_common; print(mistral_common.__version__)"Das mistral-common-Paket hat Hilfsmodule für Voxtral und andere Modelle aus der Mistral-Familie. Es enthält Tokenizer, typisierte Nachrichten im Pydantic-Format und Audio-Hilfsfunktionen. Dieser Schritt sorgt dafür, dass alles mit der internen Verarbeitung von Audioeingaben und strukturierten Nachrichten bei Voxtral klappt.
Jetzt haben wir die grundlegenden Mistral-Abhängigkeiten fertig. Als Nächstes richten wir vLLM ein, indem wir es in sein Haupt-Repository klonen.
Wir klonen das offizielle vLLM-GitHub-Repository, das uns Zugriff auf integrierte Audiobeispiele gibt und als Basis für die Offline- oder gehostete Inferenz dient.
!git clone https://github.com/vllm-project/vllm && cd vllmLass uns kurz checken, ob alles richtig eingerichtet ist.
!python vllm/examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtralIch hab das Offline-Beispiel „ audio_language.py ” ausprobiert, das mit dem Voxtral-Modell die Audio-Sprach-Inferenz an zwei vordefinierten Beispielen durchführt und checkt, ob die Audiodekodierung und -generierung richtig funktionieren.
Nachdem vLLM jetzt eingerichtet ist, konfigurieren wir PyNGrok so, dass der vLLM-Server auf Colab über eine öffentlich zugängliche Internetadresse erreichbar ist.
Als Nächstes installieren wir PyNGrok in der Colab-Umgebung und setzen den Authentifizierungstoken mit dem zuvor kopierten NGROK-Token. Wenn du an einem Prototyp arbeitest, kannst du das Token hier direkt weitergeben.
!pip install pyngrok -q
from pyngrok import ngrok
ngrok.set_auth_token("NGROK_TOKEN")Das ist der wichtigste Schritt, wo wir das Voxtral Mini 3B-Modell über vLLM starten.
!vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --max-model-len 4864Der Code-Schnipsel hat ein paar wichtige Flags:
--tokenizer_mode mistral: Hier wird der Mistral-spezifische Tokenizer für eine genaue Tokenisierung verwendet.--config_format mistral und --load_format mistral: Diese Flags sorgen dafür, dass sowohl die Modellkonfiguration als auch die Gewichte im benutzerdefinierten Format von Mistral geladen werden, sodass die Kompatibilität erhalten bleibt.--max-model-len 4864: Diese Option legt die maximale Länge des Eingabekontexts auf 4864 Tokens fest.Hinweis: Lass diese Zelle laufen, weil das ein aktiver Modellserver ist.
Sobald dein vLLM-Server läuft, gib den folgenden Code Zeile für Zeile in einem Python-Terminal ein:
from pyngrok import ngrok
ngrok.set_auth_token(NGROK_TOKEN)
public_url = ngrok.connect(8000)
print("Public endpoint:", public_url)Der obige Code macht das Modell über eine temporäre öffentliche URL wie die folgende im Internet verfügbar:
https://80xxxxxxxxxx.ngrok-free.appSpeicher diese URL, die im lokalen „ config.py ” gebraucht wird, um eine Verbindung zum Remote-Modell herzustellen. Wenn der Lauf fertig ist, beende die Verbindung mit:
ngrok.kill()In diesem Abschnitt erstellen wir eine Streamlit-Benutzeroberfläche, die Folgendes kann:
Bevor wir die App erstellen, legen wir alle benötigten Abhängigkeiten in einer Datei namens „ requirements.txt “ fest. Das sorgt für einheitliche Umgebungen bei lokalen Läufen oder Colab-Notebooks.
streamlit>=1.28.0
openai>=1.0.0
mistral-common>=0.0.12
huggingface-hub>=0.19.0
pyngrok>=6.0.0
requests>=2.28.0
pydub>=0.25.1 Hier ist, warum wir jedes davon brauchen:
AudioChunk “ und „ TextChunk “.Damit die Konfiguration übersichtlich und portabel bleibt, speichern wir API-Details als Umgebungsvariablen. Du kannst sie in einer Datei namens „ .env ” festlegen:
VOXTRAL_API_KEY=dummy-key
VOXTRAL_API_BASE=NGROK_TOKEN/v1
VOXTRAL_MODEL_NAME=mistralai/Voxtral-Mini-3B-2507VOXTRAL_API_BASE sollte auf deine laufende vLLM-Instanz zeigen, die localhost (http://localhost:8000) oder ein öffentlicher ngrok-Endpunkt sein kann, der so aussieht: https://80xxxxxxxxxx.ngrok-free.app.
Hinweis: Vergewissere dich, dass du „ /v1 “ am Ende der API-Basis hinzufügst, damit es mit OpenAI funktioniert.
Damit deine App modular, einfach anpassbar und produktionsbereit ist, legen wir eine zentrale Konfigurationsklasse in „ config.py “ fest. Diese Datei regelt die Modelleinstellungen, den API-Zugriff, die unterstützten Audioformate, Sprachen und UI-Einstellungen.
Bevor wir die Konfigurationsklasse definieren, laden wir alle Umgebungsvariablen, die in einer Datei namens „ .env “ gespeichert sind. So bleiben sensible Infos vom Code getrennt.
import os
from typing import Optional
from pathlib import Path
# Load environment variables from .env file
env_file = Path(".env")
if env_file.exists():
with open(env_file, 'r') as f:
for line in f:
if line.strip() and not line.startswith('#'):
key, value = line.strip().split('=', 1)
os.environ[key] = valueDieser Ausschnitt checkt, ob eine Datei namens „ .env ” im Stammverzeichnis vorhanden ist. Wenn es gefunden wird, liest es Schlüssel-Wert-Paare und legt sie als Umgebungsvariablen fest. Auf diese Werte kann jetzt über „ os.getenv() “ zugegriffen werden, sodass Geheimnisse nicht fest in die App eingebaut werden.
Jetzt packen wir alle Einstellungen in eine übersichtliche Klasse „ Config “, damit man sie leicht finden und wiederverwenden kann.
class Config:
# API Configuration
VOXTRAL_API_KEY: str = os.getenv("VOXTRAL_API_KEY", "EMPTY")
VOXTRAL_API_BASE: str = os.getenv("VOXTRAL_API_BASE", "http://localhost:8000/v1")
# Model Configuration
MODEL_NAME: str = os.getenv("VOXTRAL_MODEL_NAME", "voxtral-mini-3b-2507")
# Default Parameters
DEFAULT_TEMPERATURE: float = 0.2
DEFAULT_TOP_P: float = 0.95
# Audio Configuration
MAX_AUDIO_SIZE_MB: int = 100
SUPPORTED_AUDIO_FORMATS: list = ['mp3', 'wav', 'm4a', 'flac', 'ogg']
SUPPORTED_LANGUAGES: list = [
"English", "Spanish", "French", "German", "Italian", "Portuguese",
"Russian", "Chinese", "Japanese", "Korean", "Arabic", "Hindi"
]
# UI Configuration
STREAMLIT_THEME: dict = {
"primaryColor": "#1f77b4",
"backgroundColor": "#ffffff",
"secondaryBackgroundColor": "#f0f2f6",
"textColor": "#262730",
"font": "sans serif"
}
@classmethod
def get_api_config(cls) -> dict:
return {
"api_key": cls.VOXTRAL_API_KEY,
"base_url": cls.VOXTRAL_API_BASE,
"model_name": cls.MODEL_NAME
}
@classmethod
def validate_config(cls) -> bool:
if not cls.VOXTRAL_API_BASE:
return False
return True
@classmethod
def get_language_code(cls, language_name: str) -> Optional[str]:
language_mapping = {
"English": "en",
"Spanish": "es",
"French": "fr",
"German": "de",
"Italian": "it",
"Portuguese": "pt",
"Russian": "ru",
"Chinese": "zh",
"Japanese": "ja",
"Korean": "ko",
"Arabic": "ar",
"Hindi": "hi"
}
return language_mapping.get(language_name) Zusammen fungiert diese Klasse „ Config ” als zentrale Steuerungszentrale für deine Voxtral-basierte App. Egal, ob du Modellparameter konfigurierst, Audioformate verwaltest oder das App-Design anpasst – diese Einrichtung sorgt für eine klare Abstraktion, Wiederverwendbarkeit des Codes und einfache Wartung.
Der Kurs beinhaltet:
get_api_config() Methode: Diese Methode sammelt alle API-Zugangsdaten an einem Ort. Egal, wo deine App das Voxtral-Modell aufruft, kannst du einfach Config.get_api_config() ausführen, um alles Nötige auf einmal abzurufen.validate_config() Methode: Bevor du mit der Inferenz startest, kannst du mit dieser Methode checken, ob wichtige Konfigurationswerte (wie die Basis-URL) richtig eingestellt sind. Wenn nicht, kannst du das Problem frühzeitig erkennen und den Benutzer darauf aufmerksam machen.get_language_code() Methode: Mit dieser Methode kannst du ganz einfach mehrsprachige Fragen und Antworten machen, indem du benutzerfreundliche Sprachnamen aus der Benutzeroberfläche (z. B. „Französisch“) mit standardisierten ISO-Sprachcodes (z. B. „fr“) verknüpfst. Wenn eine nicht unterstützte Sprache übergeben wird, wird sicher None zurückgegeben.Schauen wir uns mal die einzelnen Schritte an, die die App-Oberfläche und die Logik aufbauen.
In diesem Schritt starten wir das Streamlit-Frontend, laden Abhängigkeiten und richten den CSS-Stil ein. Das ist die optische und funktionale Basis der App.
import streamlit as st
import tempfile
import os
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage
from mistral_common.audio import Audio
from openai import OpenAI
import time
from config import Config
# Page configuration
st.set_page_config(
page_title="Voxtral Audio Assistant",
page_icon="🎵",
layout="wide",
initial_sidebar_state="expanded"
)
# Custom CSS
st.markdown("""
<style>
.main-header {
font-weight: bold;
text-align: center;
}
.section-header {
font-weight: bold;
}
.info-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.success-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #28a745;
}
.chat-message {
border-radius: 0.5rem;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)Im obigen Python- und CSS-Code:
mistral_common “ von Voxtral.Als Nächstes stellen wir sicher, dass die App bei jedem Neustart gleich läuft, indem wir Sitzungsvariablen und den Client initialisieren.
def init_session_state():
defaults = {
'transcription': "",
'summary': "",
'chat_history': [],
'audio_file_path': None
}
for key, default_value in defaults.items():
if key not in st.session_state:
st.session_state[key] = default_value
def initialize_client():
config = Config.get_api_config()
client = OpenAI(
api_key=config["api_key"],
base_url=config["base_url"],
)
# Test connection
try:
models = client.models.list()
return client
except Exception as e:
st.error(f"Failed to connect to Voxtral API: {str(e)}")
st.info("Make sure your ngrok tunnel is running in Google Colab")
return NoneDieser Code-Schnipsel richtet den internen Status der App ein und kümmert sich um die Verbindung zum Voxtral-API-Server. Es umfasst zwei wichtige Teile:
Dieser Schritt kümmert sich um die Hauptlogik beim Vorbereiten der Audiodatei und beim Erstellen einer Transkription mit Voxtral Mini 3B.
def file_to_chunk(file_path: str) -> AudioChunk:
audio = Audio.from_file(file_path, strict=False)
return AudioChunk.from_audio(audio)
def transcribe_audio(client, audio_file_path):
try:
with open(audio_file_path, "rb") as f:
response = client.audio.transcriptions.create(
file=f,
model=Config.MODEL_NAME,
response_format="text",
stream=True
)
transcription = ""
progress_bar = st.progress(0)
status_text = st.empty()
# Collect all chunks first to get total count
chunks = list(response)
total_chunks = len(chunks)
for i, chunk in enumerate(chunks):
delta = chunk.choices[0].get("delta", {}).get("content")
if delta:
transcription += delta
progress = min((i + 1) / max(total_chunks, 1), 1.0)
progress_bar.progress(progress)
status_text.text(f"Transcribing... {len(transcription)} characters")
progress_bar.empty()
status_text.empty()
return transcription
except Exception as e:
st.error(f"Error during transcription: {str(e)}")
return NoneHier gibt's zwei wichtige Funktionen:
AudioChunk ”-Format um, das die Eingabevoraussetzung für die API von Voxtral ist.stream=True) und decodieren ihn Stück für Stück. Ein Fortschrittsbalken wird dynamisch aktualisiert, sobald Tokens empfangen werden, und gibt den Benutzern Echtzeit-Feedback zum Fortschritt der Transkription.Dieser Schritt sendet die Audioeingabe zusammen mit einer Textanweisung an das Voxtral-Modell, das eine kurze, strukturierte Zusammenfassung des Audioinhalts zurückgibt.
def generate_summary(client, audio_file_path):
try:
audio_chunk = file_to_chunk(audio_file_path)
text_chunk = TextChunk(text="Please provide a comprehensive summary of this audio content, highlighting the key points and main themes discussed.")
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error generating summary: {str(e)}")
return NoneDer obige Code nutzt ein paar wichtige Methoden und Funktionen, um aus dem hochgeladenen Audio eine Zusammenfassung zu erstellen:
audio_chunk: Zuerst wandeln wir die hochgeladene Audiodatei in ein „ AudioChunk ” für die Audioverarbeitung von Voxtral um.text_chunk: Dann wird das Modell über einen Textbefehl aufgefordert, den Inhalt klar und verständlich zusammenzufassen.UserMessage: Das hier kombiniert die „ audio_chunk ” und „ text_chunk ” zu einer einzigen multimodalen Nachricht in einem OpenAI-kompatiblen Format. Response.choices[0].message.content: Dieses Objekt holt den eigentlichen Zusammenfassungstext aus der Antwort des Modells raus.Jetzt haben wir die Zusammenfassung. Lass uns den Nutzern ermöglichen, Fragen in natürlicher Sprache zu den hochgeladenen Audioinhalten zu stellen. Hier kommen die multimodalen Funktionen von Voxtral zum Einsatz, indem Audio mit Textanweisungen kombiniert werden, um kontextbezogene Antworten zu generieren.
Die folgende Funktion unterstützt auch mehrsprachige Antworten, indem sie die Eingabeaufforderung je nach gewählter Sprache dynamisch anpasst.
def ask_question(client, audio_file_path, question, language="English"):
try:
audio_chunk = file_to_chunk(audio_file_path)
if language != "English":
question = f"Please answer the following question in {language}: {question}"
text_chunk = TextChunk(text=question)
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error asking question: {str(e)}")
return NoneHier ist eine kurze Zusammenfassung dessen, was hier passiert:
ask_question() “ können Nutzer Fragen zu den hochgeladenen Audiodateien stellen.file_to_chunk() ” in ein „ AudioChunk ” umgewandelt, das die Audiodaten im Format vorbereitet, das die multimodale API von Voxtral braucht.TextChunk “ gepackt, und sowohl der Ton als auch der Text werden in ein multimodales „ UserMessage “ gepackt.Die Seitenleiste ist wie ein Bedienfeld, wo du die Sitzungseinstellungen verwalten, die Sprache auswählen, die Verbindung zur Voxtral-API testen und das Antwortverhalten des Modells mit intuitiven Schiebereglern anpassen kannst.
def render_sidebar():
with st.sidebar:
st.markdown('<h3 class="section-header">Configuration</h3>', unsafe_allow_html=True)
# Connection status
st.markdown('<h4>Connection Status</h4>', unsafe_allow_html=True)
if st.button("Test Connection"):
client = initialize_client()
if client:
st.success("Connected to Voxtral API")
else:
st.error("Connection failed")
# Language selection
selected_language = st.selectbox("Select language for Q&A:", Config.SUPPORTED_LANGUAGES)
# Model configuration
st.markdown('<h4>Model Settings</h4>', unsafe_allow_html=True)
temperature = st.slider("Temperature", 0.0, 1.0, Config.DEFAULT_TEMPERATURE, 0.1)
top_p = st.slider("Top P", 0.0, 1.0, Config.DEFAULT_TOP_P, 0.05)
if st.button("Clear Session"):
for key in ['transcription', 'summary', 'chat_history', 'audio_file_path']:
st.session_state[key] = "" if key in ['transcription', 'summary'] else [] if key == 'chat_history' else None
st.rerun()
return selected_language, temperature, top_pHier ist eine Erklärung des Codes oben:
st.sidebar ” öffnet eine ausklappbare Seitenleiste, in der wir die Konfigurationstools für die App speichern.initialize_client() “, die versucht, eine Verbindung zur Voxtral-API herzustellen, und den Erfolg oder Misserfolg über Streamlit-Warnmeldungen meldet.temperature: Das hält die Kreativität im Zaum. Die niedrigeren Werte machen die Antworten deterministischer, während die höheren Werte sie vielfältiger machen.top_p: Dieser Parameter steuert die Kernsampling, was dabei hilft, die Generierung auf die wahrscheinlichsten Tokens zu beschränken.Hier kannst du Audiodateien (z. B. .mp3, .wav usw.) hochladen, die vorübergehend gespeichert werden. Nach dem Hochladen können die Nutzer wählen, ob sie die Audioaufnahme transkribieren oder eine Zusammenfassung erstellen möchten.
def render_audio_processing():
st.markdown('<h3 class="section-header">Audio Upload & Processing</h3>', unsafe_allow_html=True)
uploaded_file = st.file_uploader(
"Choose an audio file",
type=Config.SUPPORTED_AUDIO_FORMATS,
help="Upload an audio file to transcribe and analyze"
)
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
st.session_state.audio_file_path = tmp_file.name
st.success(f"File uploaded: {uploaded_file.name}")
# Initialize client
client = initialize_client()
col1, col2 = st.columns(2)
with col1:
if st.button("Generate Summary", type="primary"):
with st.spinner("Generating summary..."):
summary = generate_summary(client, st.session_state.audio_file_path)
if summary:
st.session_state.summary = summary
with col2:
if st.button("Transcribe Audio", type="secondary"):
with st.spinner("Transcribing audio..."):
transcription = transcribe_audio(client, st.session_state.audio_file_path)
if transcription:
st.session_state.transcription = transcription
if st.session_state.summary:
st.markdown('<h4>Summary</h4>', unsafe_allow_html=True)
st.markdown(f'<div class="success-box">{st.session_state.summary}</div>', unsafe_allow_html=True)
if st.session_state.transcription:
st.markdown('<h4>Audio Transcription</h4>', unsafe_allow_html=True)
st.text_area("Transcription", st.session_state.transcription, height=200, label_visibility="collapsed")Wir brauchen eine modulare Struktur, damit Audio-Dateien einfach hochgeladen, verarbeitet und die Ergebnisse über verschiedene Benutzerinteraktionen hinweg gespeichert werden können. So hab ich's gemacht:
Config.SUPPORTED_AUDIO_FORMATS definiert sind. Sobald eine Datei hochgeladen ist, wird sie in eine temporäre Datei geschrieben und unter st.session_state.audio_file_path gespeichert.st.session_state.summary “ gespeichert.st.session_state.transcription “ gespeichert.Mit diesem Schritt können Nutzer Fragen zu den hochgeladenen Audiodateien in mehreren Sprachen stellen (z. B. Englisch, Hindi, Spanisch). Die gewählte Sprache wird benutzt, um die Antwort des Modells zu formatieren, und jedes Frage-Antwort-Paar wird in einem sitzungsgesteuerten Gesprächsverlauf gespeichert und in Chat-Blasen angezeigt.
def render_qa_section(selected_language):
st.markdown('<h3 class="section-header">Multilingual Q&A</h3>', unsafe_allow_html=True)
if st.session_state.audio_file_path:
st.markdown(f'<div class="info-box">Selected language: <strong>{selected_language}</strong></div>', unsafe_allow_html=True)
question = st.text_input(
f"Ask a question about the audio (in {selected_language}):",
placeholder="e.g., What is the main topic discussed?"
)
if st.button("Ask Question", type="primary") and question:
client = initialize_client()
with st.spinner("Processing your question..."):
answer = ask_question(client, st.session_state.audio_file_path, question, selected_language)
if answer:
# Chat history
st.session_state.chat_history.append({
"question": question,
"answer": answer,
"language": selected_language,
"timestamp": time.strftime("%H:%M:%S")
})
st.success("Question answered!")
else:
st.error("Failed to get answer. Please try again.")
if st.session_state.chat_history:
st.markdown('<h4>Conversation History</h4>', unsafe_allow_html=True)
for chat in reversed(st.session_state.chat_history):
st.markdown(f'<div class="chat-message user-message"><strong>Question:</strong> {chat["question"]}</div>', unsafe_allow_html=True)
st.markdown(f'<div class="chat-message assistant-message"><strong>Answer:</strong> {chat["answer"]}</div>', unsafe_allow_html=True)
st.markdown("---")
else:
st.markdown('<div class="info-box">Please upload an audio file to start asking questions.</div>', unsafe_allow_html=True)Hier ist eine Erklärung, was im obigen Code-Schnipsel passiert:
Ask Question Taste „ “: In einem Textfeld kannst du eine Frage in der gewählten Sprache eingeben und dann auf„ “ klicken. Frage stellen Button. Einmal draufgeklickt:st.session_state.chat_history ” mit einem Zeitstempel.In diesem letzten Schritt werden alle vorher definierten Teile zusammengefügt, wie das Initialisieren des Sitzungsstatus, das Rendern der Seitenleiste, das Verarbeiten von Audio-Uploads, die Transkription, Zusammenfassungen und Q&A in einem zweispaltigen Layout.
Sobald der Server läuft und alle Abhängigkeiten installiert sind, stellt dieser Schritt sicher, dass die App über Streamlit an den Browser gesendet wird und für die Interaktion bereit ist.
def main():
st.markdown('<h1 class="main-header">🎵 Voxtral Audio Assistant</h1>', unsafe_allow_html=True)
# Initialize session state
init_session_state()
# Render sidebar and get configuration
selected_language, temperature, top_p = render_sidebar()
col1, col2 = st.columns([1, 1])
with col1:
render_audio_processing()
with col2:
render_qa_section(selected_language)
st.markdown("---")
st.markdown("""
<div style="text-align: center;">
<p>Powered by <strong>Voxtral Mini 3B</strong> | Built with Streamlit</p>
<p>Supports multiple languages for audio analysis and Q&A</p>
</div>
""", unsafe_allow_html=True)
if __name__ == "__main__":
main() Die Funktion „ main() ” ist der Einstiegspunkt für die App. Es kümmert sich um das Layout, koordiniert das Rendering und stellt sicher, dass alle Sitzungsvariablen und UI-Komponenten richtig initialisiert werden. Hier ist eine kurze Zusammenfassung der oben beschriebenen Funktionen:
init_session_state(): Diese Funktion bereitet Standardwerte wie „ transcription “, „ summary “ und „ chat_history “ vor, um den App-Status über Interaktionen hinweg beizubehalten.render_sidebar(): Es lädt Konfigurations-Widgets wie die Sprachauswahl, den Verbindungstest und die Modellparameter.render_audio_processing(): Mit dieser Funktion können Nutzer Audiodateien hochladen und bearbeiten, um sie zu transkribieren und zusammenzufassen.render_qa_section(): Endlich kannst du jetzt auch mehrsprachige Fragen zu hochgeladenen Audiodateien beantworten.Wenn alles fertig ist, starte die App mit:
pip install -r requirements.txtStell sicher, dass sie über die URL erreichbar ist, die du in „ VOXTRAL_API_BASE “ in deiner Datei „ config.py “ angegeben hast. Sobald alle Abhängigkeiten installiert sind, starte die Streamlit-Anwendung, indem du den folgenden Befehl im Terminal ausführst:
streamlit run app.pyDein Browser öffnet die Oberfläche automatisch. Die App ist jetzt voll funktionsfähig mit Audio-Upload, Echtzeit-Transkription, Zusammenfassungen und mehrsprachigen Fragen und Antworten, unterstützt von Voxtral Mini 3B.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
