
Curso
Implementación de IA en producción con FastAPI
4 h
4.5K
Mistral ha lanzado recientemente sus primeros modelos de audio multimodal de código abierto, Voxtral Small y Voxtral Mini, basados en la arquitectura Mistral 3B y optimizados específicamente para tareas de comprensión y transcripción de audio.
En este blog me centraré en Voxtral Mini 3B, un modelo compacto y de código abierto diseñado para tareas de audio a texto en tiempo real, como transcripción, resumen y preguntas y respuestas. Con su tamaño eficiente y su compatibilidad con el razonamiento de contexto largo, Voxtral Mini es especialmente potente cuando se combina con marcos de inferencia de alto rendimiento como vLLM, lo que lo hace ideal para crear aplicaciones de audio rápidas y sin conexión.
En este tutorial, te explicaré cómo:
Mantenemos a nuestros lectores al día sobre las últimas novedades en IA mediante el envío de The Median, nuestro boletín informativo gratuito de los viernes que resume las noticias más importantes de la semana. Suscríbete y mantente al día en solo unos minutos a la semana:
Voxtral es la familia de modelos de audio totalmente de código abierto de Mistral, diseñada para una comprensión del habla potente. Voxtral está disponible en dos tamaños:
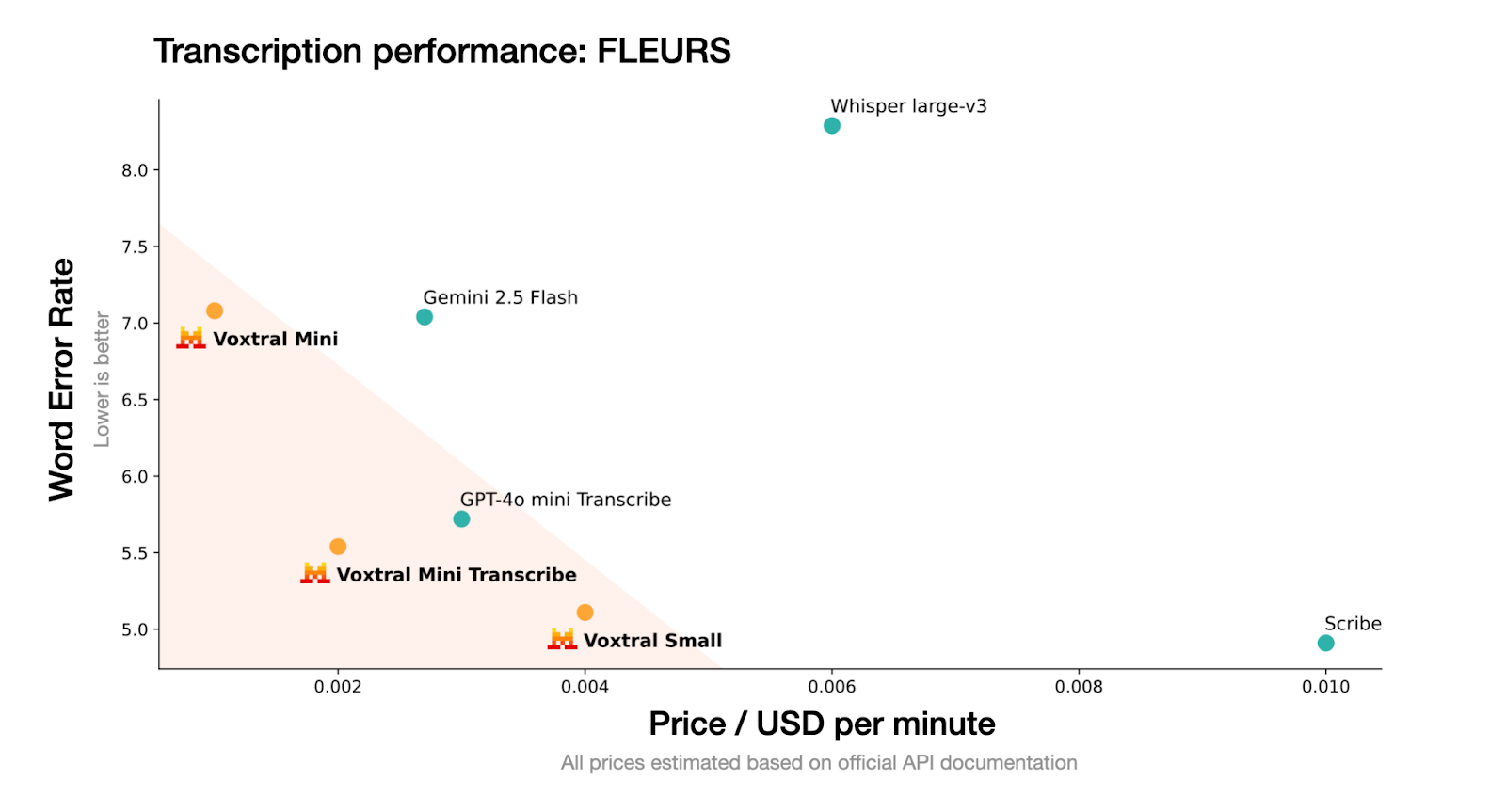
Fuente: Mistral
Voxtral acepta entradas de audio sin procesar (como .wav o .mp3) y está entrenado para generar transcripciones y resúmenes de contenido hablado de manera eficiente. Voxtral es una variante más pequeña optimizada para una inferencia rápida y una implementación fuera de línea.
Sigue el formato modelo de Mistral y es compatible con marcos de inferencia de alto rendimiento como vLLM, lo que lo convierte en una excelente opción para la transcripción en tiempo real o aplicaciones de voz ligeras.
En esta sección, te explicaré cómo utilizar Voxtral Mini 3B con vLLM en Colab Pro con GPU T4 habilitada. Se ha elegido vLLM por su alto rendimiento y su baja latencia, características ideales para modelos como Voxtral, que requieren respuestas rápidas en streaming con soporte de audio.
Además, utilizaremos PyNGrok para exponer el servidor vLLM a través de un punto final público, haciéndolo accesible a las aplicaciones que se ejecutan en tu máquina local.
Comencemos por instalar las dependencias en nuestro entorno Colab. Ejecuta el siguiente comando en la celda Colab:
!uv pip install -U transformers accelerate "vllm[audio]" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightlyComenzamos instalando las bibliotecas necesarias utilizando uv, un instalador de paquetes Python más rápido. Esto descarga la versión nocturna de vllm[audio], que incluye soporte experimental para modelos de lenguaje de audio como Voxtral. Si no tienes instalado uv en tu entorno, primero instala uv ejecutando el siguiente código:
!pip install uvA continuación, instalamos el paquete mistral-common, que proporciona las utilidades esenciales necesarias para interactuar con Voxtral y otros modelos de la familia Mistral. Este paquete incluye tokenizadores alineados con implementaciones oficiales y validación basada en Pydantic para estructuras de mensajes.
!pip install mistral-common --upgrade
!python -c "import mistral_common; print(mistral_common.__version__)"El paquete mistral-common contiene módulos de utilidad para Voxtral y otros modelos de la familia Mistral. Incluye tokenizadores, mensajes tipificados en formatos Pydantic y funciones auxiliares de audio. Este paso garantiza la compatibilidad con el manejo interno de Voxtral de las entradas de audio y los mensajes estructurados.
Ahora que ya tenemos listas las dependencias básicas de Mistral, a continuación configuraremos vLLM clonándolo en su repositorio principal.
Clonamos el repositorio oficial de vLLM en GitHub, lo que nos da acceso a ejemplos de audio integrados y sirve como base para lanzar inferencias sin conexión o alojadas.
!git clone https://github.com/vllm-project/vllm && cd vllmHagamos una rápida comprobación para asegurarnos de que la configuración es correcta.
!python vllm/examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtralEjecuté el ejemplo sin conexión « audio_language.py », que realiza una inferencia del idioma del audio en dos muestras predefinidas utilizando el modelo Voxtral y confirma si la decodificación y la generación de audio funcionan correctamente.
Ahora que ya has configurado vLLM, vamos a configurar PyNGrok para exponer el servidor vLLM en Colab a través de una dirección de Internet de acceso público.
A continuación, instalamos PyNGrok en el entorno colab y configuramos el token de autenticación utilizando el token NGROK que copiamos anteriormente. Si estás trabajando en un prototipo, puedes pasar el token directamente aquí.
!pip install pyngrok -q
from pyngrok import ngrok
ngrok.set_auth_token("NGROK_TOKEN")Este es el paso clave, en el que lanzamos el modelo Voxtral Mini 3B a través de vLLM.
!vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --max-model-len 4864El fragmento de código incluye varios indicadores importantes:
--tokenizer_mode mistral: Utiliza el tokenizador específico de Mistral para una tokenización precisa.--config_format mistral y --load_format mistral: Estas banderas garantizan que tanto la configuración del modelo como los pesos se carguen en el formato personalizado de Mistral, manteniendo la compatibilidad.--max-model-len 4864: Esta bandera establece la longitud máxima del contexto de entrada en 4864 tokens.Nota: Mantén esta celda en funcionamiento, ya que se trata de un servidor modelo activo.
Una vez que tu servidor vLLM esté en funcionamiento, ejecuta el siguiente código línea por línea en un terminal Python:
from pyngrok import ngrok
ngrok.set_auth_token(NGROK_TOKEN)
public_url = ngrok.connect(8000)
print("Public endpoint:", public_url)El código anterior expondrá el modelo a Internet en una URL pública temporal como:
https://80xxxxxxxxxx.ngrok-free.appGuarda esta URL, que se utilizará en el config.py local para conectarte al modelo remoto. Una vez completada la ejecución, finaliza la conexión ejecutando:
ngrok.kill()En esta sección, crearemos una interfaz de usuario Streamlit que:
Antes de crear la aplicación, definimos todas las dependencias necesarias en un archivo requirements.txt. Esto garantiza entornos coherentes en las ejecuciones locales o en los cuadernos Colab.
streamlit>=1.28.0
openai>=1.0.0
mistral-common>=0.0.12
huggingface-hub>=0.19.0
pyngrok>=6.0.0
requests>=2.28.0
pydub>=0.25.1 He aquí por qué necesitamos cada uno de ellos:
AudioChunk y TextChunk.Para mantener la configuración limpia y portátil, almacenamos los detalles de la API como variables de entorno. Puedes definirlos dentro de un archivo .env:
VOXTRAL_API_KEY=dummy-key
VOXTRAL_API_BASE=NGROK_TOKEN/v1
VOXTRAL_MODEL_NAME=mistralai/Voxtral-Mini-3B-2507VOXTRAL_API_BASE debe apuntar a tu instancia vLLM en ejecución, que puede ser localhost (http://localhost:8000) o un punto final público ngrok que tenga un aspecto similar a https://80xxxxxxxxxx.ngrok-free.app.
Nota: Asegúrate de añadir /v1 al final de la base API para garantizar la compatibilidad con OpenAI.
Para que tu aplicación sea modular, fácilmente ajustable y esté lista para su producción, definiremos una clase de configuración central en config.py. Este archivo controlará la configuración del modelo, el acceso a la API, los formatos de audio compatibles, los idiomas y las preferencias de la interfaz de usuario.
Antes de definir la clase config, cargamos cualquier variable de entorno guardada en un archivo .env. Esto mantiene la información confidencial separada del código.
import os
from typing import Optional
from pathlib import Path
# Load environment variables from .env file
env_file = Path(".env")
if env_file.exists():
with open(env_file, 'r') as f:
for line in f:
if line.strip() and not line.startswith('#'):
key, value = line.strip().split('=', 1)
os.environ[key] = valueEste fragmento comprueba si existe un archivo .env en el directorio raíz. Si se encuentra, lee los pares clave-valor y los establece como variables de entorno. Ahora se puede acceder a estos valores utilizando os.getenv(), lo que garantiza que los secretos no queden codificados en la aplicación.
Ahora, agrupamos todos los ajustes en una clase limpia llamada « Config » para facilitar el acceso y la reutilización.
class Config:
# API Configuration
VOXTRAL_API_KEY: str = os.getenv("VOXTRAL_API_KEY", "EMPTY")
VOXTRAL_API_BASE: str = os.getenv("VOXTRAL_API_BASE", "http://localhost:8000/v1")
# Model Configuration
MODEL_NAME: str = os.getenv("VOXTRAL_MODEL_NAME", "voxtral-mini-3b-2507")
# Default Parameters
DEFAULT_TEMPERATURE: float = 0.2
DEFAULT_TOP_P: float = 0.95
# Audio Configuration
MAX_AUDIO_SIZE_MB: int = 100
SUPPORTED_AUDIO_FORMATS: list = ['mp3', 'wav', 'm4a', 'flac', 'ogg']
SUPPORTED_LANGUAGES: list = [
"English", "Spanish", "French", "German", "Italian", "Portuguese",
"Russian", "Chinese", "Japanese", "Korean", "Arabic", "Hindi"
]
# UI Configuration
STREAMLIT_THEME: dict = {
"primaryColor": "#1f77b4",
"backgroundColor": "#ffffff",
"secondaryBackgroundColor": "#f0f2f6",
"textColor": "#262730",
"font": "sans serif"
}
@classmethod
def get_api_config(cls) -> dict:
return {
"api_key": cls.VOXTRAL_API_KEY,
"base_url": cls.VOXTRAL_API_BASE,
"model_name": cls.MODEL_NAME
}
@classmethod
def validate_config(cls) -> bool:
if not cls.VOXTRAL_API_BASE:
return False
return True
@classmethod
def get_language_code(cls, language_name: str) -> Optional[str]:
language_mapping = {
"English": "en",
"Spanish": "es",
"French": "fr",
"German": "de",
"Italian": "it",
"Portuguese": "pt",
"Russian": "ru",
"Chinese": "zh",
"Japanese": "ja",
"Korean": "ko",
"Arabic": "ar",
"Hindi": "hi"
}
return language_mapping.get(language_name) En conjunto, esta clase Config actúa como centro de control centralizado para tu aplicación con tecnología Voxtral. Ya sea que estés configurando los parámetros del modelo, gestionando formatos de audio o estableciendo el tema de la aplicación, esta configuración garantiza una abstracción limpia, la reutilización del código y la facilidad de mantenimiento.
La clase incluye:
get_api_config() método: Este método centraliza todas las credenciales relacionadas con la API. Siempre que tu aplicación realice una llamada al modelo Voxtral, solo tendrás que ejecutar Config.get_api_config() para recuperar todo lo necesario de una sola vez.validate_config() método: Antes de iniciar la inferencia, este método te permite validar que los valores de configuración esenciales (como la URL base) estén definidos correctamente. Si no es así, podrás detectar el problema a tiempo y avisar al usuario.get_language_code() método: Este método permite realizar preguntas y respuestas multilingües sin problemas, al asignar nombres de idiomas fáciles de usar desde la interfaz de usuario (por ejemplo, «francés») a códigos de idioma ISO estandarizados (por ejemplo, «fr»). Si se pasa un idioma no compatible, devuelve None de forma segura.Repasemos cada uno de los pasos que conforman la interfaz y la lógica de la aplicación.
En este paso, inicializamos la interfaz de Streamlit, cargamos las dependencias y configuramos el estilo CSS. Esto constituye la base visual y funcional de la aplicación.
import streamlit as st
import tempfile
import os
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage
from mistral_common.audio import Audio
from openai import OpenAI
import time
from config import Config
# Page configuration
st.set_page_config(
page_title="Voxtral Audio Assistant",
page_icon="🎵",
layout="wide",
initial_sidebar_state="expanded"
)
# Custom CSS
st.markdown("""
<style>
.main-header {
font-weight: bold;
text-align: center;
}
.section-header {
font-weight: bold;
}
.info-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.success-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #28a745;
}
.chat-message {
border-radius: 0.5rem;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)En el código Python y CSS anterior:
mistral_common de Voxtral.A continuación, nos aseguramos de que la aplicación se comporte de forma coherente al recargarse inicializando las variables de sesión y el cliente.
def init_session_state():
defaults = {
'transcription': "",
'summary': "",
'chat_history': [],
'audio_file_path': None
}
for key, default_value in defaults.items():
if key not in st.session_state:
st.session_state[key] = default_value
def initialize_client():
config = Config.get_api_config()
client = OpenAI(
api_key=config["api_key"],
base_url=config["base_url"],
)
# Test connection
try:
models = client.models.list()
return client
except Exception as e:
st.error(f"Failed to connect to Voxtral API: {str(e)}")
st.info("Make sure your ngrok tunnel is running in Google Colab")
return NoneEste fragmento de código configura el estado interno de la aplicación y gestiona la conexión con el servidor API de Voxtral. Incluye dos componentes clave:
Este paso se encarga de la lógica básica de preparar el archivo de audio y generar una transcripción utilizando Voxtral Mini 3B.
def file_to_chunk(file_path: str) -> AudioChunk:
audio = Audio.from_file(file_path, strict=False)
return AudioChunk.from_audio(audio)
def transcribe_audio(client, audio_file_path):
try:
with open(audio_file_path, "rb") as f:
response = client.audio.transcriptions.create(
file=f,
model=Config.MODEL_NAME,
response_format="text",
stream=True
)
transcription = ""
progress_bar = st.progress(0)
status_text = st.empty()
# Collect all chunks first to get total count
chunks = list(response)
total_chunks = len(chunks)
for i, chunk in enumerate(chunks):
delta = chunk.choices[0].get("delta", {}).get("content")
if delta:
transcription += delta
progress = min((i + 1) / max(total_chunks, 1), 1.0)
progress_bar.progress(progress)
status_text.text(f"Transcribing... {len(transcription)} characters")
progress_bar.empty()
status_text.empty()
return transcription
except Exception as e:
st.error(f"Error during transcription: {str(e)}")
return NoneAquí hay dos funciones clave:
AudioChunk », que es el formato de entrada requerido por la API de Voxtral.stream=True) y lo decodificamos por fragmentos. Una barra de progreso se actualiza dinámicamente a medida que se reciben los tokens, lo que proporciona a los usuarios información en tiempo real sobre el progreso de la transcripción.Este paso envía la entrada de audio junto con una indicación textual al modelo Voxtral, que devuelve un resumen conciso y estructurado del contenido de audio.
def generate_summary(client, audio_file_path):
try:
audio_chunk = file_to_chunk(audio_file_path)
text_chunk = TextChunk(text="Please provide a comprehensive summary of this audio content, highlighting the key points and main themes discussed.")
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error generating summary: {str(e)}")
return NoneEl código anterior utiliza varios métodos y funciones clave para generar un resumen a partir del audio cargado:
audio_chunk: En primer lugar, convertimos el archivo de audio cargado en un archivo « AudioChunk » para el procesamiento de audio de Voxtral.text_chunk: A continuación, se utiliza un mensaje de texto para indicar al modelo que resuma el contenido de forma clara y completa.UserMessage: Esto combina audio_chunk y text_chunk en un único mensaje multimodal en un formato compatible con OpenAI. Response.choices[0].message.content: Este objeto extrae el texto resumido real de la respuesta del modelo.Ahora ya tenemos el resumen. Permitamos a los usuarios formular preguntas en lenguaje natural sobre el contenido de audio subido. Utiliza las capacidades multimodales de Voxtral combinando audio con indicaciones de texto para generar respuestas contextuales.
La siguiente función también admite respuestas multilingües modificando dinámicamente el mensaje en función del idioma seleccionado.
def ask_question(client, audio_file_path, question, language="English"):
try:
audio_chunk = file_to_chunk(audio_file_path)
if language != "English":
question = f"Please answer the following question in {language}: {question}"
text_chunk = TextChunk(text=question)
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error asking question: {str(e)}")
return NoneAquí tienes un resumen de lo que está pasando:
ask_question() » (Pregunta sobre el audio) permite a los usuarios hacer cualquier pregunta sobre el audio subido.AudioChunk ) utilizando la función reutilizable « file_to_chunk() », que prepara el audio en el formato esperado por la API multimodal de Voxtral.TextChunk, y tanto el audio como el texto se agrupan en un elemento multimodal UserMessage.La barra lateral funciona como un panel de control, permitiéndoles gestionar la configuración de la sesión, seleccionar el idioma de salida, probar la conexión con la API de Voxtral y personalizar el comportamiento de respuesta del modelo mediante intuitivos controles deslizantes.
def render_sidebar():
with st.sidebar:
st.markdown('<h3 class="section-header">Configuration</h3>', unsafe_allow_html=True)
# Connection status
st.markdown('<h4>Connection Status</h4>', unsafe_allow_html=True)
if st.button("Test Connection"):
client = initialize_client()
if client:
st.success("Connected to Voxtral API")
else:
st.error("Connection failed")
# Language selection
selected_language = st.selectbox("Select language for Q&A:", Config.SUPPORTED_LANGUAGES)
# Model configuration
st.markdown('<h4>Model Settings</h4>', unsafe_allow_html=True)
temperature = st.slider("Temperature", 0.0, 1.0, Config.DEFAULT_TEMPERATURE, 0.1)
top_p = st.slider("Top P", 0.0, 1.0, Config.DEFAULT_TOP_P, 0.05)
if st.button("Clear Session"):
for key in ['transcription', 'summary', 'chat_history', 'audio_file_path']:
st.session_state[key] = "" if key in ['transcription', 'summary'] else [] if key == 'chat_history' else None
st.rerun()
return selected_language, temperature, top_pA continuación se muestra un desglose del código anterior:
st.sidebar » abre una barra lateral plegable donde se almacenan las herramientas de configuración de la aplicación.initialize_client() », que intenta conectarse a la API de Voxtral e informa del éxito o el fracaso mediante alertas de Streamlit.temperature: Esto controla la creatividad. Los valores más bajos hacen que las respuestas sean más deterministas, mientras que los más altos las hacen más diversas.top_p: Este parámetro controla el muestreo del núcleo, lo que ayuda a restringir la generación a los tokens más probables.Esta sección permite a los usuarios cargar archivos de audio (como .mp3, .wav, etc.), que se guardan temporalmente. Una vez subido, los usuarios pueden elegir entre transcribir el audio o generar un resumen de alto nivel.
def render_audio_processing():
st.markdown('<h3 class="section-header">Audio Upload & Processing</h3>', unsafe_allow_html=True)
uploaded_file = st.file_uploader(
"Choose an audio file",
type=Config.SUPPORTED_AUDIO_FORMATS,
help="Upload an audio file to transcribe and analyze"
)
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
st.session_state.audio_file_path = tmp_file.name
st.success(f"File uploaded: {uploaded_file.name}")
# Initialize client
client = initialize_client()
col1, col2 = st.columns(2)
with col1:
if st.button("Generate Summary", type="primary"):
with st.spinner("Generating summary..."):
summary = generate_summary(client, st.session_state.audio_file_path)
if summary:
st.session_state.summary = summary
with col2:
if st.button("Transcribe Audio", type="secondary"):
with st.spinner("Transcribing audio..."):
transcription = transcribe_audio(client, st.session_state.audio_file_path)
if transcription:
st.session_state.transcription = transcription
if st.session_state.summary:
st.markdown('<h4>Summary</h4>', unsafe_allow_html=True)
st.markdown(f'<div class="success-box">{st.session_state.summary}</div>', unsafe_allow_html=True)
if st.session_state.transcription:
st.markdown('<h4>Audio Transcription</h4>', unsafe_allow_html=True)
st.text_area("Transcription", st.session_state.transcription, height=200, label_visibility="collapsed")Necesitamos una estructura modular que facilite la carga de archivos de audio, su procesamiento y el almacenamiento permanente de los resultados de las interacciones de los usuarios. Así es como lo hice:
Config.SUPPORTED_AUDIO_FORMATS. Una vez que se carga un archivo, se escribe en un archivo temporal y se guarda en st.session_state.audio_file_path.st.session_state.summary.st.session_state.transcription.Este paso permite a los usuarios hacer preguntas sobre el audio subido en varios idiomas (por ejemplo, inglés, hindi, español). El idioma seleccionado se utiliza para dar formato a la respuesta del modelo, y cada par de preguntas y respuestas se almacena en un historial de conversaciones gestionado por sesiones y se muestra mediante bocadillos de chat.
def render_qa_section(selected_language):
st.markdown('<h3 class="section-header">Multilingual Q&A</h3>', unsafe_allow_html=True)
if st.session_state.audio_file_path:
st.markdown(f'<div class="info-box">Selected language: <strong>{selected_language}</strong></div>', unsafe_allow_html=True)
question = st.text_input(
f"Ask a question about the audio (in {selected_language}):",
placeholder="e.g., What is the main topic discussed?"
)
if st.button("Ask Question", type="primary") and question:
client = initialize_client()
with st.spinner("Processing your question..."):
answer = ask_question(client, st.session_state.audio_file_path, question, selected_language)
if answer:
# Chat history
st.session_state.chat_history.append({
"question": question,
"answer": answer,
"language": selected_language,
"timestamp": time.strftime("%H:%M:%S")
})
st.success("Question answered!")
else:
st.error("Failed to get answer. Please try again.")
if st.session_state.chat_history:
st.markdown('<h4>Conversation History</h4>', unsafe_allow_html=True)
for chat in reversed(st.session_state.chat_history):
st.markdown(f'<div class="chat-message user-message"><strong>Question:</strong> {chat["question"]}</div>', unsafe_allow_html=True)
st.markdown(f'<div class="chat-message assistant-message"><strong>Answer:</strong> {chat["answer"]}</div>', unsafe_allow_html=True)
st.markdown("---")
else:
st.markdown('<div class="info-box">Please upload an audio file to start asking questions.</div>', unsafe_allow_html=True)A continuación se detalla lo que ocurre en el fragmento de código anterior:
Ask Question botón « » (Añadir a la lista de reproducción): Un campo de entrada de texto permite a los usuarios escribir una pregunta en el idioma seleccionado y hacer clic en el botón« » (Pregunta en inglés) o « » (Pregunta en español). Una vez, haz clic en él:st.session_state.chat_history con una marca de tiempo.Este último paso reúne todos los componentes definidos anteriormente, incluyendo la inicialización del estado de la sesión, la representación de la barra lateral, la gestión de las cargas de audio, la transcripción, los resúmenes y las preguntas y respuestas utilizando un diseño de dos columnas.
Una vez que el servidor está en funcionamiento y todas las dependencias están instaladas, este paso garantiza que la aplicación se envíe al navegador a través de Streamlit y esté lista para interactuar.
def main():
st.markdown('<h1 class="main-header">🎵 Voxtral Audio Assistant</h1>', unsafe_allow_html=True)
# Initialize session state
init_session_state()
# Render sidebar and get configuration
selected_language, temperature, top_p = render_sidebar()
col1, col2 = st.columns([1, 1])
with col1:
render_audio_processing()
with col2:
render_qa_section(selected_language)
st.markdown("---")
st.markdown("""
<div style="text-align: center;">
<p>Powered by <strong>Voxtral Mini 3B</strong> | Built with Streamlit</p>
<p>Supports multiple languages for audio analysis and Q&A</p>
</div>
""", unsafe_allow_html=True)
if __name__ == "__main__":
main() La función main() actúa como punto de entrada para la aplicación. Controla el diseño, coordina la representación y garantiza que todas las variables de sesión y los componentes de la interfaz de usuario se inicialicen correctamente. A continuación se ofrece un resumen de lo que describen las funciones definidas anteriormente:
init_session_state(): Esta función prepara valores predeterminados como transcription, summary y chat_history para mantener el estado de la aplicación entre interacciones.render_sidebar(): Carga los widgets de configuración, incluyendo el selector de idioma, la prueba de conexión y los parámetros del modelo.render_audio_processing(): Esta función permite a los usuarios cargar y procesar archivos de audio para su transcripción y generación de resúmenes.render_qa_section(): Por último, esta función permite responder preguntas en varios idiomas sobre el audio subido.Una vez que todo esté listo, ejecuta la aplicación utilizando:
pip install -r requirements.txtAsegúrate de que se puede acceder a él a través de la URL especificada en VOXTRAL_API_BASE dentro de tu config.py. Una vez instaladas todas las dependencias, ejecuta la aplicación Streamlit ejecutando el siguiente comando en la terminal:
streamlit run app.pyTu navegador abrirá la interfaz automáticamente. La aplicación ya es totalmente funcional con carga de audio, transcripción en tiempo real, resúmenes y preguntas y respuestas multilingües, gracias a la tecnología de Voxtral Mini 3B.
¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan




