
Curso
Colocando IA em Produção com FastAPI
4 h
4.5K
A Mistral lançou recentemente seus primeiros modelos de áudio multimodal de código aberto, o Voxtral Small e o Voxtral Mini, que são baseados na arquitetura Mistral 3B e foram otimizados especialmente para tarefas de compreensão e transcrição de áudio.
Neste blog, vou focar no Voxtral Mini 3B, um modelo compacto e de código aberto feito pra tarefas de áudio pra texto em tempo real, tipo transcrição, resumo e perguntas e respostas. Com seu tamanho eficiente e suporte para raciocínio de contexto longo, o Voxtral Mini é super poderoso quando usado com estruturas de inferência de alto rendimento, como o vLLM, o que o torna ideal para criar aplicativos de áudio rápidos e offline.
Neste tutorial, vou te mostrar como:
A gente mantém nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito às sextas-feiras, que traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
Voxtral é a família de modelos de áudio totalmente open source da Mistral, feita pra entender super bem o que a gente fala. O Voxtral está disponível em dois tamanhos:
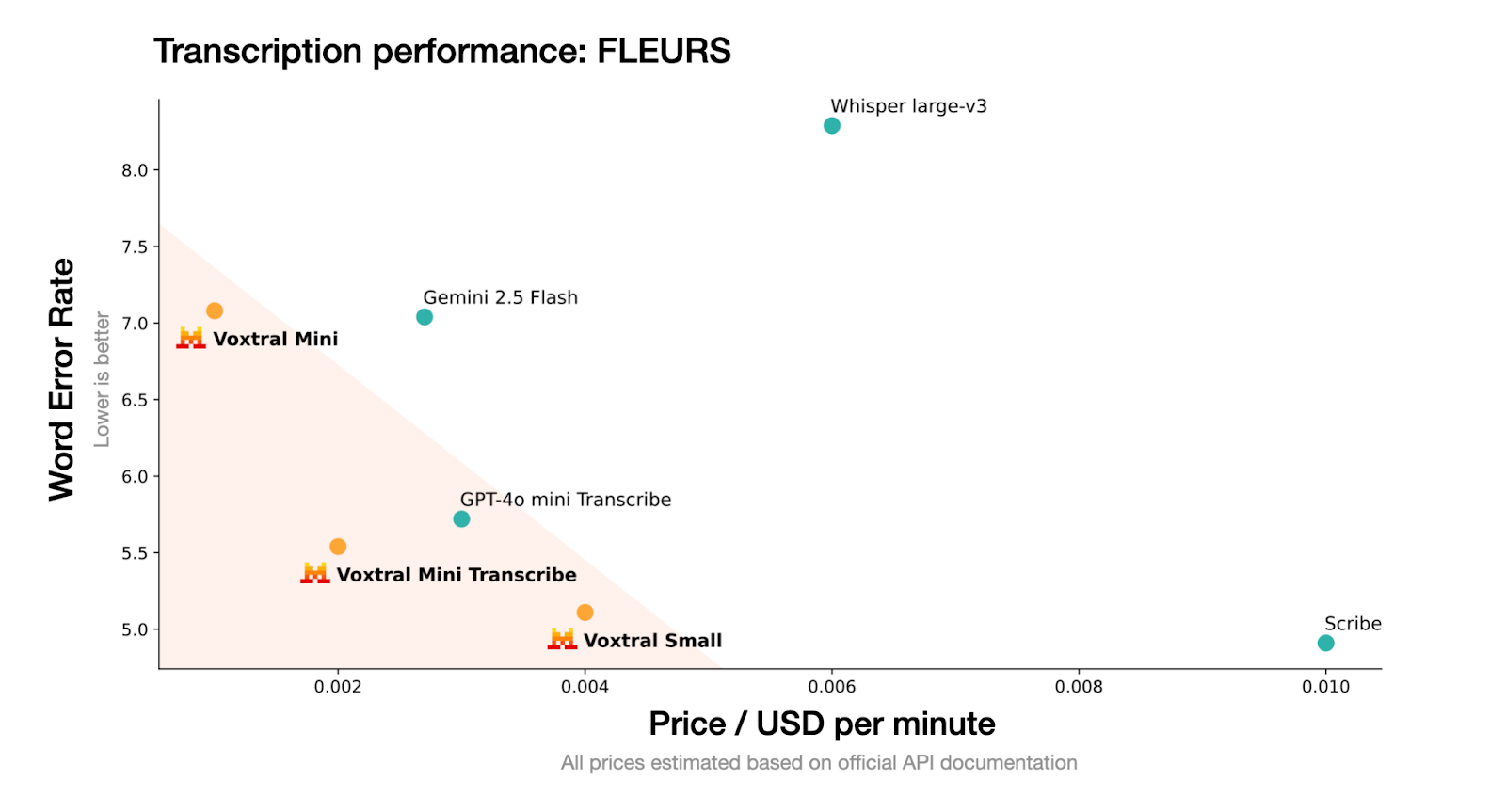
Fonte: Mistral
O Voxtral aceita áudio bruto (como .wav ou .mp3) e foi treinado pra gerar transcrições e resumos de conteúdo falado de um jeito eficiente. O Voxtral é uma versão menor, otimizada pra inferência rápida e implantação offline.
Segue o formato do modelo Mistral e é compatível com estruturas de inferência de alto rendimento, como vLLM, o que o torna uma excelente escolha para transcrição em tempo real ou aplicações de voz leves.
Nesta seção, vou te mostrar como usar o Voxtral Mini 3B com o vLLM em um Colab Pro com GPU T4 ativada. O vLLM foi escolhido por causa da alta capacidade de processamento e baixa latência, que são ideais para modelos como o Voxtral, que precisam de respostas rápidas de streaming com suporte para áudio.
Além disso, vamos usar o PyNGrok para expor o servidor vLLM por meio de um endpoint público, tornando-o acessível para aplicativos em execução na sua máquina local.
Vamos começar instalando as dependências no nosso ambiente Colab. Execute o seguinte comando na célula Colab:
!uv pip install -U transformers accelerate "vllm[audio]" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightlyComeçamos instalando as bibliotecas necessárias usando o uv, um instalador de pacotes Python mais rápido. Isso pega a versão noturna do vllm[audio], que tem suporte experimental para modelos de linguagem de áudio como o Voxtral. Se você não tem o uv instalado no seu ambiente, primeiro instale o uv executando o seguinte código:
!pip install uvDepois, a gente instala o pacote mistral-common, que tem os utilitários essenciais pra interagir com o Voxtral e outros modelos da família Mistral. Esse pacote inclui tokenizadores alinhados com implementações oficiais e validação baseada em Pydantic para estruturas de mensagens.
!pip install mistral-common --upgrade
!python -c "import mistral_common; print(mistral_common.__version__)"O pacote mistral-common tem módulos úteis para o Voxtral e outros modelos da família Mistral. Inclui tokenizadores, mensagens digitadas nos formatos Pydantic e funções auxiliares de áudio. Essa etapa garante que tudo funcione bem com o jeito que o Voxtral lida com entradas de áudio e mensagens estruturadas.
Agora que já temos as dependências básicas do Mistral prontas, vamos configurar o vLLM clonando o repositório principal dele.
Clonamos o repositório GitHub oficial do vLLM, que nos dá acesso a exemplos de áudio integrados e serve como base para iniciar a inferência offline ou hospedada.
!git clone https://github.com/vllm-project/vllm && cd vllmVamos fazer uma checada rápida pra garantir que a nossa configuração tá certa.
!python vllm/examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtralEu rodei o exemplo offline audio_language.py, que faz a inferência do idioma do áudio em duas amostras pré-definidas usando o modelo Voxtral e confirma se a decodificação e a geração do áudio estão funcionando direitinho.
Com o vLLM já configurado, vamos configurar o PyNGrok para expor o servidor vLLM no Colab através de um endereço de internet acessível ao público.
Depois, a gente instala o PyNGrok no ambiente colab e configura o token de autenticação usando o token NGROK que a gente copiou antes. Se você estiver trabalhando em um protótipo, pode passar o token diretamente aqui.
!pip install pyngrok -q
from pyngrok import ngrok
ngrok.set_auth_token("NGROK_TOKEN")Essa é a etapa principal, onde a gente lança o modelo Voxtral Mini 3B usando o vLLM.
!vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --max-model-len 4864O trecho de código tem várias coisas importantes:
--tokenizer_mode mistral: Isso usa o tokenizador específico do Mistral para uma tokenização precisa.--config_format mistral e --load_format mistral: Essas flags garantem que tanto a configuração do modelo quanto os pesos sejam carregados no formato personalizado do Mistral, mantendo a compatibilidade.--max-model-len 4864: Essa bandeira define o comprimento máximo do contexto de entrada para 4864 tokens.Observação: Mantenha essa célula funcionando, pois este é um servidor modelo ativo.
Depois que o servidor vLLM estiver funcionando, execute o seguinte código linha por linha em um terminal Python:
from pyngrok import ngrok
ngrok.set_auth_token(NGROK_TOKEN)
public_url = ngrok.connect(8000)
print("Public endpoint:", public_url)O código acima vai deixar o modelo disponível na internet em um URL público temporário tipo:
https://80xxxxxxxxxx.ngrok-free.appSalve este URL, que vai ser usado no config.py local para se conectar ao modelo remoto. Depois que a execução terminar, encerre a conexão executando:
ngrok.kill()Nesta seção, vamos criar uma interface Streamlit que:
Antes de criar o aplicativo, a gente define todas as dependências necessárias em um arquivo chamado “ requirements.txt ”. Isso garante ambientes consistentes em execuções locais ou notebooks Colab.
streamlit>=1.28.0
openai>=1.0.0
mistral-common>=0.0.12
huggingface-hub>=0.19.0
pyngrok>=6.0.0
requests>=2.28.0
pydub>=0.25.1 Eis porque precisamos de cada um deles:
AudioChunk e TextChunk.Para manter a configuração limpa e portátil, a gente guarda os detalhes da API como variáveis de ambiente. Você pode definir isso dentro de um arquivo .env:
VOXTRAL_API_KEY=dummy-key
VOXTRAL_API_BASE=NGROK_TOKEN/v1
VOXTRAL_MODEL_NAME=mistralai/Voxtral-Mini-3B-2507VOXTRAL_API_BASE deve apontar para a sua instância vLLM em execução, que pode ser localhost (http://localhost:8000) ou um endpoint público ngrok semelhante a https://80xxxxxxxxxx.ngrok-free.app.
Observação: Certifique-se de adicionar /v1 no final da base da API para compatibilidade com OpenAI.
Para deixar seu aplicativo modular, fácil de ajustar e pronto para produção, vamos definir uma classe de configuração central em config.py. Esse arquivo controla as configurações do modelo, o acesso à API, os formatos de áudio compatíveis, os idiomas e as preferências da interface do usuário.
Antes de definir a classe config, carregamos todas as variáveis de ambiente salvas em um arquivo .env. Isso mantém as informações confidenciais separadas do código.
import os
from typing import Optional
from pathlib import Path
# Load environment variables from .env file
env_file = Path(".env")
if env_file.exists():
with open(env_file, 'r') as f:
for line in f:
if line.strip() and not line.startswith('#'):
key, value = line.strip().split('=', 1)
os.environ[key] = valueEsse trecho de código verifica se existe um arquivo .env no diretório raiz. Se achar, ele lê os pares chave-valor e define como variáveis de ambiente. Agora dá pra acessar esses valores usando os.getenv(), garantindo que os segredos não fiquem gravados no app.
Agora, vamos juntar todas as configurações numa classe Config bem organizada, pra facilitar o acesso e reutilização.
class Config:
# API Configuration
VOXTRAL_API_KEY: str = os.getenv("VOXTRAL_API_KEY", "EMPTY")
VOXTRAL_API_BASE: str = os.getenv("VOXTRAL_API_BASE", "http://localhost:8000/v1")
# Model Configuration
MODEL_NAME: str = os.getenv("VOXTRAL_MODEL_NAME", "voxtral-mini-3b-2507")
# Default Parameters
DEFAULT_TEMPERATURE: float = 0.2
DEFAULT_TOP_P: float = 0.95
# Audio Configuration
MAX_AUDIO_SIZE_MB: int = 100
SUPPORTED_AUDIO_FORMATS: list = ['mp3', 'wav', 'm4a', 'flac', 'ogg']
SUPPORTED_LANGUAGES: list = [
"English", "Spanish", "French", "German", "Italian", "Portuguese",
"Russian", "Chinese", "Japanese", "Korean", "Arabic", "Hindi"
]
# UI Configuration
STREAMLIT_THEME: dict = {
"primaryColor": "#1f77b4",
"backgroundColor": "#ffffff",
"secondaryBackgroundColor": "#f0f2f6",
"textColor": "#262730",
"font": "sans serif"
}
@classmethod
def get_api_config(cls) -> dict:
return {
"api_key": cls.VOXTRAL_API_KEY,
"base_url": cls.VOXTRAL_API_BASE,
"model_name": cls.MODEL_NAME
}
@classmethod
def validate_config(cls) -> bool:
if not cls.VOXTRAL_API_BASE:
return False
return True
@classmethod
def get_language_code(cls, language_name: str) -> Optional[str]:
language_mapping = {
"English": "en",
"Spanish": "es",
"French": "fr",
"German": "de",
"Italian": "it",
"Portuguese": "pt",
"Russian": "ru",
"Chinese": "zh",
"Japanese": "ja",
"Korean": "ko",
"Arabic": "ar",
"Hindi": "hi"
}
return language_mapping.get(language_name) Juntos, essa classe Config funciona como o centro de controle centralizado para o seu aplicativo com tecnologia Voxtral. Se você está configurando parâmetros do modelo, gerenciando formatos de áudio ou definindo o tema do aplicativo, essa configuração garante uma abstração clara, reutilização do código e facilidade de manutenção.
A aula inclui:
get_api_config() método: Esse método centraliza todas as credenciais relacionadas à API. Sempre que seu aplicativo fizer uma chamada para o modelo Voxtral, você pode simplesmente usar Config.get_api_config() para pegar tudo o que precisa de uma vez só.validate_config() método: Antes de começar a inferência, esse método permite que você verifique se os valores de configuração essenciais (como a URL base) estão definidos corretamente. Se não, você pode pegar o problema logo e avisar o usuário.get_language_code() método: Esse método permite perguntas e respostas em vários idiomas sem complicações, mapeando nomes de idiomas fáceis de entender da interface do usuário (por exemplo, “francês”) para códigos de idioma ISO padronizados (por exemplo, “fr”). Se um idioma não suportado for passado, ele retorna None com segurança.Vamos ver cada subetapa que forma a interface e a lógica do aplicativo.
Nesta etapa, a gente inicializa o front-end do Streamlit, carrega as dependências e configura o estilo CSS. Isso é a base visual e funcional do aplicativo.
import streamlit as st
import tempfile
import os
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage
from mistral_common.audio import Audio
from openai import OpenAI
import time
from config import Config
# Page configuration
st.set_page_config(
page_title="Voxtral Audio Assistant",
page_icon="🎵",
layout="wide",
initial_sidebar_state="expanded"
)
# Custom CSS
st.markdown("""
<style>
.main-header {
font-weight: bold;
text-align: center;
}
.section-header {
font-weight: bold;
}
.info-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.success-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #28a745;
}
.chat-message {
border-radius: 0.5rem;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)No código Python e CSS acima:
mistral_common da Voxtral.Depois, a gente garante que o app funcione direitinho sempre que for recarregado, inicializando as variáveis de sessão e o cliente.
def init_session_state():
defaults = {
'transcription': "",
'summary': "",
'chat_history': [],
'audio_file_path': None
}
for key, default_value in defaults.items():
if key not in st.session_state:
st.session_state[key] = default_value
def initialize_client():
config = Config.get_api_config()
client = OpenAI(
api_key=config["api_key"],
base_url=config["base_url"],
)
# Test connection
try:
models = client.models.list()
return client
except Exception as e:
st.error(f"Failed to connect to Voxtral API: {str(e)}")
st.info("Make sure your ngrok tunnel is running in Google Colab")
return NoneEsse trecho de código configura o estado interno do aplicativo e cuida da conexão com o servidor da API Voxtral. Tem dois pontos principais:
Esta etapa trata da lógica central da preparação do arquivo de áudio e da geração de uma transcrição usando o Voxtral Mini 3B.
def file_to_chunk(file_path: str) -> AudioChunk:
audio = Audio.from_file(file_path, strict=False)
return AudioChunk.from_audio(audio)
def transcribe_audio(client, audio_file_path):
try:
with open(audio_file_path, "rb") as f:
response = client.audio.transcriptions.create(
file=f,
model=Config.MODEL_NAME,
response_format="text",
stream=True
)
transcription = ""
progress_bar = st.progress(0)
status_text = st.empty()
# Collect all chunks first to get total count
chunks = list(response)
total_chunks = len(chunks)
for i, chunk in enumerate(chunks):
delta = chunk.choices[0].get("delta", {}).get("content")
if delta:
transcription += delta
progress = min((i + 1) / max(total_chunks, 1), 1.0)
progress_bar.progress(progress)
status_text.text(f"Transcribing... {len(transcription)} characters")
progress_bar.empty()
status_text.empty()
return transcription
except Exception as e:
st.error(f"Error during transcription: {str(e)}")
return NoneTem duas funções principais aqui:
AudioChunk ”, que é o formato que a API do Voxtral precisa.stream=True) e decodifica pedaço por pedaço. Uma barra de progresso atualiza automaticamente conforme os tokens são recebidos, dando aos usuários um feedback em tempo real sobre o andamento da transcrição.Essa etapa manda a entrada de áudio junto com um aviso em texto pro modelo Voxtral, que devolve um resumo curto e estruturado do conteúdo do áudio.
def generate_summary(client, audio_file_path):
try:
audio_chunk = file_to_chunk(audio_file_path)
text_chunk = TextChunk(text="Please provide a comprehensive summary of this audio content, highlighting the key points and main themes discussed.")
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error generating summary: {str(e)}")
return NoneO código acima usa vários métodos e funções importantes para gerar um resumo a partir do áudio enviado:
audio_chunk: Primeiro, a gente transforma o arquivo de áudio que você mandou num arquivo AudioChunk pra poder processar o áudio com o Voxtral.text_chunk: Depois, usa-se um prompt de texto pra dizer pro modelo resumir o conteúdo de um jeito claro e completo.UserMessage: Isso junta o audio_chunk e o text_chunk numa mensagem multimodal só, num formato compatível com o OpenAI. Response.choices[0].message.content: Esse objeto pega o texto resumido real da resposta do modelo.Agora, temos o resumo. Vamos permitir que os usuários façam perguntas em linguagem natural sobre o conteúdo de áudio enviado. Isso usa os recursos multimodais do Voxtral, combinando áudio com prompts de texto para gerar respostas que entendem o contexto.
A função a seguir também dá suporte a respostas em vários idiomas, mudando o prompt de forma dinâmica com base no idioma escolhido.
def ask_question(client, audio_file_path, question, language="English"):
try:
audio_chunk = file_to_chunk(audio_file_path)
if language != "English":
question = f"Please answer the following question in {language}: {question}"
text_chunk = TextChunk(text=question)
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error asking question: {str(e)}")
return NoneAqui vai um resumo do que tá rolando por aqui:
ask_question() ” permite que os usuários façam qualquer pergunta sobre o áudio enviado.AudioChunk ) usando a função reutilizável file_to_chunk(), que prepara o áudio no formato que a API multimodal do Voxtral espera.TextChunk, e tanto o áudio quanto o texto são agrupados em um objeto multimodal UserMessage.A barra lateral funciona como um painel de controle, permitindo que os usuários gerenciem as configurações da sessão, escolham o idioma de saída, testem a conexão com a API do Voxtral e personalizem o comportamento de resposta do modelo por meio de controles deslizantes intuitivos.
def render_sidebar():
with st.sidebar:
st.markdown('<h3 class="section-header">Configuration</h3>', unsafe_allow_html=True)
# Connection status
st.markdown('<h4>Connection Status</h4>', unsafe_allow_html=True)
if st.button("Test Connection"):
client = initialize_client()
if client:
st.success("Connected to Voxtral API")
else:
st.error("Connection failed")
# Language selection
selected_language = st.selectbox("Select language for Q&A:", Config.SUPPORTED_LANGUAGES)
# Model configuration
st.markdown('<h4>Model Settings</h4>', unsafe_allow_html=True)
temperature = st.slider("Temperature", 0.0, 1.0, Config.DEFAULT_TEMPERATURE, 0.1)
top_p = st.slider("Top P", 0.0, 1.0, Config.DEFAULT_TOP_P, 0.05)
if st.button("Clear Session"):
for key in ['transcription', 'summary', 'chat_history', 'audio_file_path']:
st.session_state[key] = "" if key in ['transcription', 'summary'] else [] if key == 'chat_history' else None
st.rerun()
return selected_language, temperature, top_pAqui está uma explicação do código acima:
st.sidebar ” abre uma barra lateral que dá pra fechar, onde a gente guarda as ferramentas de configuração do app.initialize_client() ”, que tenta se conectar à API do Voxtral e mostra se deu certo ou não usando alertas do Streamlit.temperature: Isso controla a criatividade. Os valores mais baixos tornam as respostas mais determinísticas, enquanto os mais altos as tornam mais variadas.top_p: Esse parâmetro controla a amostragem do núcleo, o que ajuda a restringir a geração aos tokens mais prováveis.Esta seção permite que os usuários enviem arquivos de áudio (como .mp3, .wav, etc.), que são salvos temporariamente. Depois de fazer o upload, os usuários podem escolher entre transcrever o áudio ou gerar um resumo de alto nível.
def render_audio_processing():
st.markdown('<h3 class="section-header">Audio Upload & Processing</h3>', unsafe_allow_html=True)
uploaded_file = st.file_uploader(
"Choose an audio file",
type=Config.SUPPORTED_AUDIO_FORMATS,
help="Upload an audio file to transcribe and analyze"
)
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
st.session_state.audio_file_path = tmp_file.name
st.success(f"File uploaded: {uploaded_file.name}")
# Initialize client
client = initialize_client()
col1, col2 = st.columns(2)
with col1:
if st.button("Generate Summary", type="primary"):
with st.spinner("Generating summary..."):
summary = generate_summary(client, st.session_state.audio_file_path)
if summary:
st.session_state.summary = summary
with col2:
if st.button("Transcribe Audio", type="secondary"):
with st.spinner("Transcribing audio..."):
transcription = transcribe_audio(client, st.session_state.audio_file_path)
if transcription:
st.session_state.transcription = transcription
if st.session_state.summary:
st.markdown('<h4>Summary</h4>', unsafe_allow_html=True)
st.markdown(f'<div class="success-box">{st.session_state.summary}</div>', unsafe_allow_html=True)
if st.session_state.transcription:
st.markdown('<h4>Audio Transcription</h4>', unsafe_allow_html=True)
st.text_area("Transcription", st.session_state.transcription, height=200, label_visibility="collapsed")Precisamos de uma estrutura modular pra facilitar o upload de áudio, o processamento e o armazenamento dos resultados das interações dos usuários. Olha só como eu fiz:
Config.SUPPORTED_AUDIO_FORMATS. Depois que um arquivo é enviado, ele é gravado em um arquivo temporário e salvo em st.session_state.audio_file_path.st.session_state.summary.st.session_state.transcription.Essa etapa permite que os usuários façam perguntas sobre o áudio enviado em vários idiomas (por exemplo, inglês, hindi, espanhol). O idioma escolhido é usado pra formatar a resposta do modelo, e cada par de pergunta e resposta é guardado num histórico de conversas gerenciado pela sessão e mostrado usando balões de chat.
def render_qa_section(selected_language):
st.markdown('<h3 class="section-header">Multilingual Q&A</h3>', unsafe_allow_html=True)
if st.session_state.audio_file_path:
st.markdown(f'<div class="info-box">Selected language: <strong>{selected_language}</strong></div>', unsafe_allow_html=True)
question = st.text_input(
f"Ask a question about the audio (in {selected_language}):",
placeholder="e.g., What is the main topic discussed?"
)
if st.button("Ask Question", type="primary") and question:
client = initialize_client()
with st.spinner("Processing your question..."):
answer = ask_question(client, st.session_state.audio_file_path, question, selected_language)
if answer:
# Chat history
st.session_state.chat_history.append({
"question": question,
"answer": answer,
"language": selected_language,
"timestamp": time.strftime("%H:%M:%S")
})
st.success("Question answered!")
else:
st.error("Failed to get answer. Please try again.")
if st.session_state.chat_history:
st.markdown('<h4>Conversation History</h4>', unsafe_allow_html=True)
for chat in reversed(st.session_state.chat_history):
st.markdown(f'<div class="chat-message user-message"><strong>Question:</strong> {chat["question"]}</div>', unsafe_allow_html=True)
st.markdown(f'<div class="chat-message assistant-message"><strong>Answer:</strong> {chat["answer"]}</div>', unsafe_allow_html=True)
st.markdown("---")
else:
st.markdown('<div class="info-box">Please upload an audio file to start asking questions.</div>', unsafe_allow_html=True)Aqui tá um resumo do que tá rolando no trecho de código acima:
Ask Question botão: Um campo de entrada de texto permite que os usuários digitem uma pergunta no idioma escolhido e cliquem no botão“ ” (Pergunte ao especialista) ou “ ” (Envie a pergunta). Uma vez, cliquei nele:st.session_state.chat_history com um carimbo de data/hora.Essa última etapa junta todos os componentes que a gente definiu antes, como inicializar o estado da sessão, renderizar a barra lateral, cuidar dos uploads de áudio, transcrição, resumos e perguntas e respostas usando um layout de duas colunas.
Depois que o servidor estiver funcionando e todas as dependências estiverem instaladas, essa etapa garante que o aplicativo seja servido ao navegador via Streamlit e esteja pronto para interação.
def main():
st.markdown('<h1 class="main-header">🎵 Voxtral Audio Assistant</h1>', unsafe_allow_html=True)
# Initialize session state
init_session_state()
# Render sidebar and get configuration
selected_language, temperature, top_p = render_sidebar()
col1, col2 = st.columns([1, 1])
with col1:
render_audio_processing()
with col2:
render_qa_section(selected_language)
st.markdown("---")
st.markdown("""
<div style="text-align: center;">
<p>Powered by <strong>Voxtral Mini 3B</strong> | Built with Streamlit</p>
<p>Supports multiple languages for audio analysis and Q&A</p>
</div>
""", unsafe_allow_html=True)
if __name__ == "__main__":
main() A função “ main() ” é tipo o ponto de partida do app. Ele controla o layout, coordena a renderização e garante que todas as variáveis da sessão e componentes da interface do usuário sejam inicializados corretamente. Aqui está um resumo do que as funções definidas acima descrevem:
init_session_state(): Essa função prepara valores padrão como transcription, summary e chat_history para manter o estado do aplicativo durante as interações.render_sidebar(): Carrega widgets de configuração, incluindo seletor de idioma, teste de conexão e parâmetros do modelo.render_audio_processing(): Essa função permite que os usuários enviem e processem arquivos de áudio para transcrição e geração de resumos.render_qa_section(): Por fim, essa função permite responder perguntas em vários idiomas em áudios que você carregar.Quando tudo estiver pronto, execute o aplicativo usando:
pip install -r requirements.txtDá uma olhada se tá acessível pelo URL que tá em VOXTRAL_API_BASE dentro do seu config.py. Depois que todas as dependências estiverem instaladas, execute o aplicativo Streamlit digitando o seguinte comando no terminal:
streamlit run app.pyO seu navegador vai abrir a interface automaticamente. O app agora tá funcionando direitinho com upload de áudio, transcrição em tempo real, resumos e perguntas e respostas em vários idiomas, tudo com a ajuda do Voxtral Mini 3B.
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita


