
Cours
Déployer l’IA en production avec FastAPI
4 h
4.5K
Mistral a récemment lancé ses premiers modèles audio multimodaux open source, Voxtral Small et Voxtral Mini, basés sur l'architecture Mistral 3B et spécialement optimisés pour les tâches de compréhension et de transcription audio.
Dans cet article, je me concentrerai sur le Voxtral Mini 3B, un modèle compact et open source conçu pour les tâches audio-texte en temps réel telles que la transcription, la synthèse et les questions-réponses. Grâce à sa taille compacte et à sa prise en charge du raisonnement dans un contexte étendu, Voxtral Mini est particulièrement performant lorsqu'il est associé à des frameworks d'inférence à haut débit tels que vLLM, ce qui le rend idéal pour créer des applications audio hors ligne rapides.
Dans ce tutoriel, je vais vous expliquer comment :
Nous tenons nos lecteurs informés des dernières actualités en matière d'IA grâce à The Median, notre newsletter hebdomadaire gratuite qui résume les articles les plus importants de la semaine. Abonnez-vous et restez informé en quelques minutes par semaine :
Voxtral est la famille de modèles audio entièrement open source de Mistral, conçue pour une compréhension vocale performante. Voxtral est disponible en deux tailles :
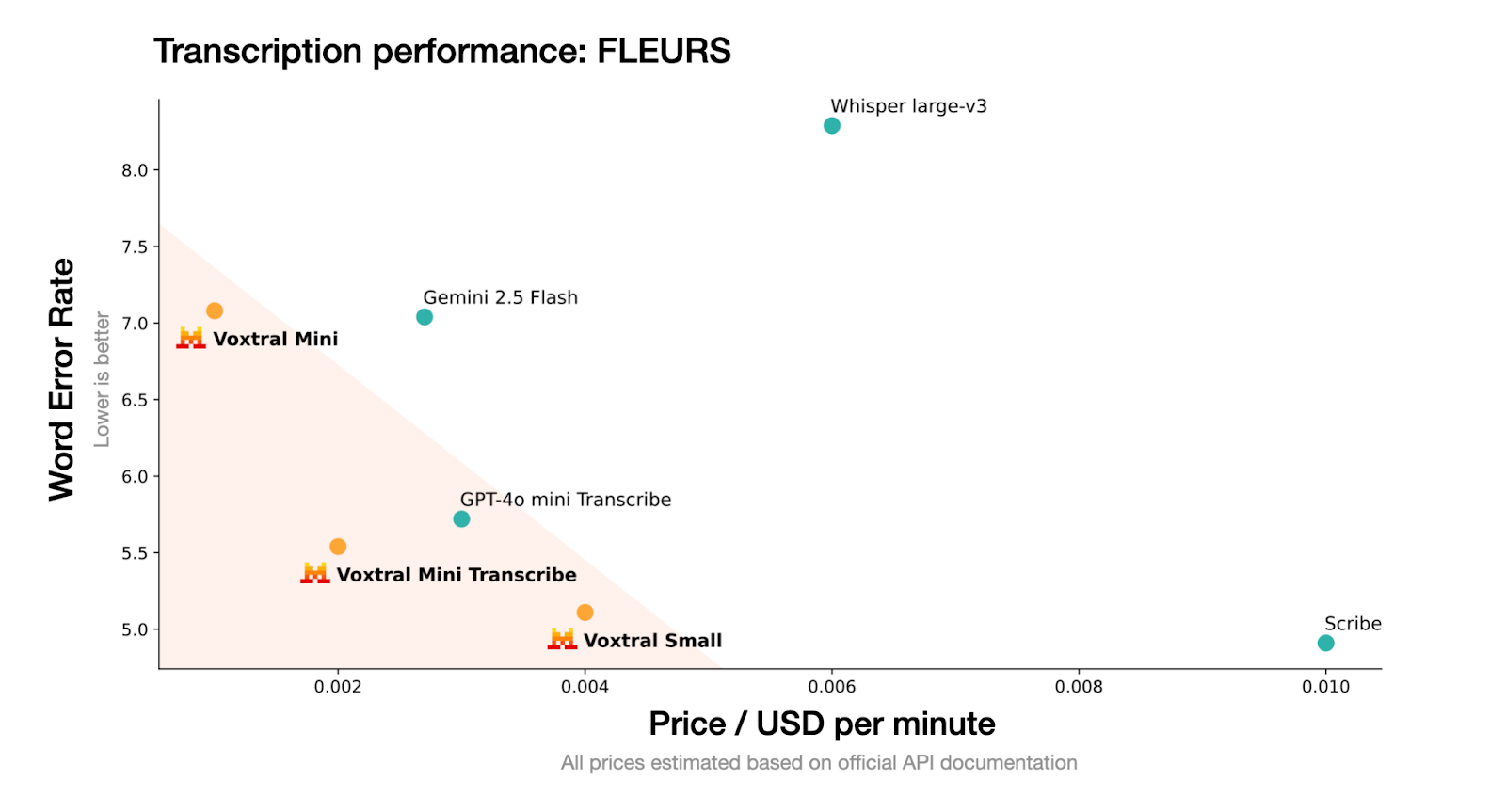
Source : Mistral
Voxtral accepte les fichiers audio bruts (tels que .wav ou .mp3) et est conçu pour générer efficacement des transcriptions et des résumés à partir de contenus vocaux. Voxtral est une variante plus petite optimisée pour une inférence rapide et un déploiement hors ligne.
Il suit le format modèle de Mistral et est compatible avec les frameworks d'inférence à haut débit tels que vLLM, ce qui en fait un excellent choix pour la transcription en temps réel ou les applications vocales légères.
Dans cette section, je vais vous expliquer comment utiliser Voxtral Mini 3B avec vLLM sur Colab Pro avec GPU T4 activé. vLLM a été sélectionné pour ses capacités de traitement à haut débit et à faible latence, idéales pour les modèles tels que Voxtral qui nécessitent des réponses rapides en streaming avec prise en charge audio.
De plus, nous utiliserons PyNGrok pour exposer le serveur vLLM via un point de terminaison public, le rendant ainsi accessible aux applications exécutées sur votre machine locale.
Commençons par installer les dépendances dans notre environnement Colab. Veuillez exécuter la commande suivante dans la cellule Colab :
!uv pip install -U transformers accelerate "vllm[audio]" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightlyNous commençons par installer les bibliothèques requises à l'aide de uv, un programme d'installation de paquets Python plus rapide. Cela télécharge la version nocturne d'vllm[audio], qui inclut une prise en charge expérimentale des modèles audio-linguistiques tels que Voxtral. Si vous n'avez pas installé uv dans votre environnement, veuillez d'abord installer uv en exécutant le code suivant :
!pip install uvEnsuite, nous installons le paquet mistral-common, qui fournit les utilitaires essentiels requis pour interagir avec Voxtral et d'autres modèles de la famille Mistral. Ce package comprend des tokeniseurs alignés sur les implémentations officielles et une validation basée sur Pydantic pour les structures de messages.
!pip install mistral-common --upgrade
!python -c "import mistral_common; print(mistral_common.__version__)"Le paquet mistral-common contient des modules utilitaires pour Voxtral et d'autres modèles de la famille Mistral. Il comprend des tokeniseurs, des messages typés au format Pydantic et des fonctions d'aide audio. Cette étape garantit la compatibilité avec le traitement interne des entrées audio et des messages structurés par Voxtral.
Maintenant que les dépendances de base de Mistral sont prêtes, nous allons configurer vLLM en le clonant dans son référentiel principal.
Nous clonons le référentiel GitHub officiel vLLM, qui nous donne accès à des exemples audio intégrés et sert de base pour lancer l'inférence hors ligne ou hébergée.
!git clone https://github.com/vllm-project/vllm && cd vllmVérifions rapidement que notre configuration est correcte.
!python vllm/examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtralJ'ai exécuté l'exemple hors ligne audio_language.py, qui effectue une inférence audio-linguistique sur deux échantillons prédéfinis à l'aide du modèle Voxtral et vérifie si le décodage et la génération audio fonctionnent correctement.
Maintenant que vLLM est configuré, configurons PyNGrok pour exposer le serveur vLLM sur Colab via une adresse Internet accessible au public.
Ensuite, nous installons PyNGrok dans l'environnement colab et configurons le jeton d'authentification à l'aide du jeton NGROK que nous avons copié précédemment. Si vous travaillez sur un prototype, vous pouvez transmettre le jeton directement ici.
!pip install pyngrok -q
from pyngrok import ngrok
ngrok.set_auth_token("NGROK_TOKEN")Il s'agit de l'étape clé, au cours de laquelle nous lançons le modèle Voxtral Mini 3B via vLLM.
!vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --max-model-len 4864L'extrait de code comprend plusieurs indicateurs importants :
--tokenizer_mode mistral: Ceci utilise le tokenizer spécifique à Mistral pour une tokenisation précise.--config_format mistral et --load_format mistral: Ces indicateurs garantissent que la configuration du modèle et les poids sont chargés dans le format personnalisé de Mistral, ce qui assure la compatibilité.--max-model-len 4864: Ce drapeau définit la longueur maximale du contexte d'entrée à 4864 jetons.Remarque : Veuillez maintenir cette cellule en fonctionnement, car il s'agit d'un serveur modèle actif.
Une fois que votre serveur vLLM est opérationnel, exécutez le code suivant ligne par ligne dans un terminal Python :
from pyngrok import ngrok
ngrok.set_auth_token(NGROK_TOKEN)
public_url = ngrok.connect(8000)
print("Public endpoint:", public_url)Le code ci-dessus exposera le modèle sur Internet à une URL publique temporaire telle que :
https://80xxxxxxxxxx.ngrok-free.appVeuillez enregistrer cette URL, qui sera utilisée dans l'config.py locale pour se connecter au modèle distant. Une fois l'exécution terminée, veuillez mettre fin à la connexion en exécutant :
ngrok.kill()Dans cette section, nous allons créer une interface utilisateur Streamlit qui :
Avant de créer l'application, nous définissons toutes les dépendances requises dans un fichier requirements.txt. Cela garantit la cohérence des environnements entre les exécutions locales et les notebooks Colab.
streamlit>=1.28.0
openai>=1.0.0
mistral-common>=0.0.12
huggingface-hub>=0.19.0
pyngrok>=6.0.0
requests>=2.28.0
pydub>=0.25.1 Voici pourquoi nous avons besoin de chacun :
AudioChunk et TextChunk.Afin de garantir la clarté et la portabilité de la configuration, nous stockons les détails de l'API sous forme de variables d'environnement. Vous pouvez les définir dans un fichier .env:
VOXTRAL_API_KEY=dummy-key
VOXTRAL_API_BASE=NGROK_TOKEN/v1
VOXTRAL_MODEL_NAME=mistralai/Voxtral-Mini-3B-2507VOXTRAL_API_BASE doit pointer vers votre instance vLLM en cours d'exécution, qui peut être localhost (http://localhost:8000) ou un point de terminaison public ngrok qui ressemble à https://80xxxxxxxxxx.ngrok-free.app.
Remarque : Veuillez vous assurer d'ajouter /v1 à la fin de la base API pour garantir la compatibilité avec OpenAI.
Afin de rendre votre application modulaire, facilement ajustable et prête pour la production, nous définirons une classe de configuration centrale dans config.py. Ce fichier contrôle les paramètres du modèle, l'accès à l'API, les formats audio pris en charge, les langues et les préférences de l'interface utilisateur.
Avant de définir la classe config, nous chargeons toutes les variables d'environnement enregistrées dans un fichier .env. Cela permet de séparer les informations sensibles du code.
import os
from typing import Optional
from pathlib import Path
# Load environment variables from .env file
env_file = Path(".env")
if env_file.exists():
with open(env_file, 'r') as f:
for line in f:
if line.strip() and not line.startswith('#'):
key, value = line.strip().split('=', 1)
os.environ[key] = valueCet extrait de code vérifie si un fichier .env existe dans le répertoire racine. Si elles sont trouvées, il lit les paires clé-valeur et les définit comme variables d'environnement. Ces valeurs sont désormais accessibles via os.getenv(), ce qui garantit que les secrets ne sont pas codés en dur dans l'application.
À présent, nous regroupons tous les paramètres dans une classe d'Config s claire pour faciliter l'accès et la réutilisation.
class Config:
# API Configuration
VOXTRAL_API_KEY: str = os.getenv("VOXTRAL_API_KEY", "EMPTY")
VOXTRAL_API_BASE: str = os.getenv("VOXTRAL_API_BASE", "http://localhost:8000/v1")
# Model Configuration
MODEL_NAME: str = os.getenv("VOXTRAL_MODEL_NAME", "voxtral-mini-3b-2507")
# Default Parameters
DEFAULT_TEMPERATURE: float = 0.2
DEFAULT_TOP_P: float = 0.95
# Audio Configuration
MAX_AUDIO_SIZE_MB: int = 100
SUPPORTED_AUDIO_FORMATS: list = ['mp3', 'wav', 'm4a', 'flac', 'ogg']
SUPPORTED_LANGUAGES: list = [
"English", "Spanish", "French", "German", "Italian", "Portuguese",
"Russian", "Chinese", "Japanese", "Korean", "Arabic", "Hindi"
]
# UI Configuration
STREAMLIT_THEME: dict = {
"primaryColor": "#1f77b4",
"backgroundColor": "#ffffff",
"secondaryBackgroundColor": "#f0f2f6",
"textColor": "#262730",
"font": "sans serif"
}
@classmethod
def get_api_config(cls) -> dict:
return {
"api_key": cls.VOXTRAL_API_KEY,
"base_url": cls.VOXTRAL_API_BASE,
"model_name": cls.MODEL_NAME
}
@classmethod
def validate_config(cls) -> bool:
if not cls.VOXTRAL_API_BASE:
return False
return True
@classmethod
def get_language_code(cls, language_name: str) -> Optional[str]:
language_mapping = {
"English": "en",
"Spanish": "es",
"French": "fr",
"German": "de",
"Italian": "it",
"Portuguese": "pt",
"Russian": "ru",
"Chinese": "zh",
"Japanese": "ja",
"Korean": "ko",
"Arabic": "ar",
"Hindi": "hi"
}
return language_mapping.get(language_name) Ensemble, cette classe d'Config s agit comme le centre de contrôle centralisé de votre application optimisée par Voxtral. Que vous configuriez les paramètres du modèle, gériez les formats audio ou définissiez le thème de l'application, cette configuration garantit une abstraction claire, la réutilisabilité du code et la facilité de maintenance.
Le cours comprend :
get_api_config() méthode : Cette méthode centralise toutes les informations d'identification liées à l'API. Chaque fois que votre application appelle le modèle Voxtral, il vous suffit d'utiliser Config.get_api_config() pour récupérer toutes les informations nécessaires en une seule fois.validate_config() méthode : Avant de commencer l'inférence, cette méthode vous permet de vérifier que les valeurs de configuration essentielles (telles que l'URL de base) sont correctement définies. Si ce n'est pas le cas, vous pouvez détecter le problème rapidement et en informer l'utilisateur.get_language_code() méthode : Cette méthode permet une gestion multilingue fluide des questions-réponses en associant des noms de langues conviviaux issus de l'interface utilisateur (par exemple, « Français ») à des codes de langue ISO standardisés (par exemple, « fr »). Si une langue non prise en charge est transmise, la fonction renvoie None en toute sécurité.Examinons chaque sous-étape qui compose l'interface et la logique de l'application.
Dans cette étape, nous initialisons l'interface utilisateur Streamlit, chargeons les dépendances et configurons le style CSS. Cela constitue la base visuelle et fonctionnelle de l'application.
import streamlit as st
import tempfile
import os
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage
from mistral_common.audio import Audio
from openai import OpenAI
import time
from config import Config
# Page configuration
st.set_page_config(
page_title="Voxtral Audio Assistant",
page_icon="🎵",
layout="wide",
initial_sidebar_state="expanded"
)
# Custom CSS
st.markdown("""
<style>
.main-header {
font-weight: bold;
text-align: center;
}
.section-header {
font-weight: bold;
}
.info-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.success-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #28a745;
}
.chat-message {
border-radius: 0.5rem;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)Dans le code Python et CSS ci-dessus :
mistral_common.Ensuite, nous nous assurons que l'application se comporte de manière cohérente à chaque rechargement en initialisant les variables de session et le client.
def init_session_state():
defaults = {
'transcription': "",
'summary': "",
'chat_history': [],
'audio_file_path': None
}
for key, default_value in defaults.items():
if key not in st.session_state:
st.session_state[key] = default_value
def initialize_client():
config = Config.get_api_config()
client = OpenAI(
api_key=config["api_key"],
base_url=config["base_url"],
)
# Test connection
try:
models = client.models.list()
return client
except Exception as e:
st.error(f"Failed to connect to Voxtral API: {str(e)}")
st.info("Make sure your ngrok tunnel is running in Google Colab")
return NoneCet extrait de code configure l'état interne de l'application et gère la connexion au serveur API Voxtral. Il comprend deux éléments clés :
Cette étape gère la logique principale de préparation du fichier audio et de génération d'une transcription à l'aide de Voxtral Mini 3B.
def file_to_chunk(file_path: str) -> AudioChunk:
audio = Audio.from_file(file_path, strict=False)
return AudioChunk.from_audio(audio)
def transcribe_audio(client, audio_file_path):
try:
with open(audio_file_path, "rb") as f:
response = client.audio.transcriptions.create(
file=f,
model=Config.MODEL_NAME,
response_format="text",
stream=True
)
transcription = ""
progress_bar = st.progress(0)
status_text = st.empty()
# Collect all chunks first to get total count
chunks = list(response)
total_chunks = len(chunks)
for i, chunk in enumerate(chunks):
delta = chunk.choices[0].get("delta", {}).get("content")
if delta:
transcription += delta
progress = min((i + 1) / max(total_chunks, 1), 1.0)
progress_bar.progress(progress)
status_text.text(f"Transcribing... {len(transcription)} characters")
progress_bar.empty()
status_text.empty()
return transcription
except Exception as e:
st.error(f"Error during transcription: {str(e)}")
return NoneIl existe deux fonctions principales ici :
AudioChunk », qui est le format requis par l'API de Voxtral.stream=True) et le décodons morceau par morceau. Une barre de progression se met à jour dynamiquement à mesure que les jetons sont reçus, offrant aux utilisateurs un retour en temps réel sur l'avancement de la transcription.Cette étape envoie l'entrée audio ainsi qu'une invite textuelle au modèle Voxtral, qui renvoie un résumé concis et structuré du contenu audio.
def generate_summary(client, audio_file_path):
try:
audio_chunk = file_to_chunk(audio_file_path)
text_chunk = TextChunk(text="Please provide a comprehensive summary of this audio content, highlighting the key points and main themes discussed.")
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error generating summary: {str(e)}")
return NoneLe code ci-dessus utilise plusieurs méthodes et fonctions clés pour générer un résumé à partir de l'audio téléchargé :
audio_chunk: AudioChunk Tout d'abord, nous convertissons le fichier audio téléchargé en un format compatible avec le traitement audio de Voxtral.text_chunk: Ensuite, une invite textuelle est utilisée pour demander au modèle de résumer le contenu de manière claire et complète.UserMessage: Ceci combine les formats audio_chunk et text_chunk en un seul message multimodal dans un format compatible avec OpenAI. Response.choices[0].message.content: Cet objet extrait le texte récapitulatif réel de la réponse du modèle.Nous avons maintenant le résumé. Permettons aux utilisateurs de poser des questions en langage naturel sur le contenu audio téléchargé. Cette fonctionnalité exploite les capacités multimodales de Voxtral en combinant l'audio et des invites textuelles afin de générer des réponses adaptées au contexte.
La fonction suivante prend également en charge les réponses multilingues en modifiant dynamiquement l'invite en fonction de la langue sélectionnée.
def ask_question(client, audio_file_path, question, language="English"):
try:
audio_chunk = file_to_chunk(audio_file_path)
if language != "English":
question = f"Please answer the following question in {language}: {question}"
text_chunk = TextChunk(text=question)
user_msg = UserMessage(content=[audio_chunk, text_chunk]).to_openai()
response = client.chat.completions.create(
model=Config.MODEL_NAME,
messages=[user_msg],
temperature=Config.DEFAULT_TEMPERATURE,
top_p=Config.DEFAULT_TOP_P,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"Error asking question: {str(e)}")
return NoneVoici un aperçu de ce qui se passe ici :
ask_question() » (Demander une explication) permet aux utilisateurs de poser toute question concernant l'audio téléchargé.AudioChunk Le processus commence par la conversion du fichier téléchargé en une instance multimodale à l'aide de la fonction réutilisable ` file_to_chunk() `, qui prépare l'audio dans le format attendu par l'API multimodale de Voxtral.TextChunk », et l'audio et le texte sont regroupés dans un élément multimodal « UserMessage ».La barre latérale sert de panneau de contrôle, permettant aux utilisateurs de gérer les paramètres de session, de sélectionner la langue de sortie, de tester la connexion à l'API Voxtral et de personnaliser le comportement de réponse du modèle à l'aide de curseurs intuitifs.
def render_sidebar():
with st.sidebar:
st.markdown('<h3 class="section-header">Configuration</h3>', unsafe_allow_html=True)
# Connection status
st.markdown('<h4>Connection Status</h4>', unsafe_allow_html=True)
if st.button("Test Connection"):
client = initialize_client()
if client:
st.success("Connected to Voxtral API")
else:
st.error("Connection failed")
# Language selection
selected_language = st.selectbox("Select language for Q&A:", Config.SUPPORTED_LANGUAGES)
# Model configuration
st.markdown('<h4>Model Settings</h4>', unsafe_allow_html=True)
temperature = st.slider("Temperature", 0.0, 1.0, Config.DEFAULT_TEMPERATURE, 0.1)
top_p = st.slider("Top P", 0.0, 1.0, Config.DEFAULT_TOP_P, 0.05)
if st.button("Clear Session"):
for key in ['transcription', 'summary', 'chat_history', 'audio_file_path']:
st.session_state[key] = "" if key in ['transcription', 'summary'] else [] if key == 'chat_history' else None
st.rerun()
return selected_language, temperature, top_pVoici une analyse du code ci-dessus :
st.sidebar » ouvre une barre latérale repliable dans laquelle sont stockés les outils de configuration de l'application.initialize_client(), qui tente de se connecter à l'API Voxtral et signale la réussite ou l'échec de la connexion à l'aide d'alertes Streamlit.temperature: Cela contrôle la créativité. Les valeurs plus faibles rendent les réponses plus déterministes, tandis que les valeurs plus élevées les rendent plus variées.top_p: Ce paramètre contrôle l'échantillonnage du noyau, ce qui permet de limiter la génération aux jetons les plus probables.Cette section permet aux utilisateurs de télécharger des fichiers audio (tels que .mp3, .wav, etc.), qui sont enregistrés temporairement. Une fois le fichier audio téléchargé, les utilisateurs peuvent choisir de le transcrire ou de générer un résumé de haut niveau.
def render_audio_processing():
st.markdown('<h3 class="section-header">Audio Upload & Processing</h3>', unsafe_allow_html=True)
uploaded_file = st.file_uploader(
"Choose an audio file",
type=Config.SUPPORTED_AUDIO_FORMATS,
help="Upload an audio file to transcribe and analyze"
)
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
st.session_state.audio_file_path = tmp_file.name
st.success(f"File uploaded: {uploaded_file.name}")
# Initialize client
client = initialize_client()
col1, col2 = st.columns(2)
with col1:
if st.button("Generate Summary", type="primary"):
with st.spinner("Generating summary..."):
summary = generate_summary(client, st.session_state.audio_file_path)
if summary:
st.session_state.summary = summary
with col2:
if st.button("Transcribe Audio", type="secondary"):
with st.spinner("Transcribing audio..."):
transcription = transcribe_audio(client, st.session_state.audio_file_path)
if transcription:
st.session_state.transcription = transcription
if st.session_state.summary:
st.markdown('<h4>Summary</h4>', unsafe_allow_html=True)
st.markdown(f'<div class="success-box">{st.session_state.summary}</div>', unsafe_allow_html=True)
if st.session_state.transcription:
st.markdown('<h4>Audio Transcription</h4>', unsafe_allow_html=True)
st.text_area("Transcription", st.session_state.transcription, height=200, label_visibility="collapsed")Nous avons besoin d'une structure modulaire pour faciliter le téléchargement audio, le traitement et le stockage permanent des résultats tout au long des interactions avec les utilisateurs. Voici comment j'ai procédé :
Config.SUPPORTED_AUDIO_FORMATS. Une fois qu'un fichier est téléchargé, il est enregistré dans un fichier temporaire et sauvegardé dans st.session_state.audio_file_path.st.session_state.summary.st.session_state.transcription ».Cette étape permet aux utilisateurs de poser des questions sur l'audio téléchargé dans plusieurs langues (par exemple, anglais, hindi, espagnol). La langue sélectionnée est utilisée pour formater la réponse du modèle, et chaque paire question-réponse est stockée dans un historique de conversation géré par session et affichée à l'aide de bulles de discussion.
def render_qa_section(selected_language):
st.markdown('<h3 class="section-header">Multilingual Q&A</h3>', unsafe_allow_html=True)
if st.session_state.audio_file_path:
st.markdown(f'<div class="info-box">Selected language: <strong>{selected_language}</strong></div>', unsafe_allow_html=True)
question = st.text_input(
f"Ask a question about the audio (in {selected_language}):",
placeholder="e.g., What is the main topic discussed?"
)
if st.button("Ask Question", type="primary") and question:
client = initialize_client()
with st.spinner("Processing your question..."):
answer = ask_question(client, st.session_state.audio_file_path, question, selected_language)
if answer:
# Chat history
st.session_state.chat_history.append({
"question": question,
"answer": answer,
"language": selected_language,
"timestamp": time.strftime("%H:%M:%S")
})
st.success("Question answered!")
else:
st.error("Failed to get answer. Please try again.")
if st.session_state.chat_history:
st.markdown('<h4>Conversation History</h4>', unsafe_allow_html=True)
for chat in reversed(st.session_state.chat_history):
st.markdown(f'<div class="chat-message user-message"><strong>Question:</strong> {chat["question"]}</div>', unsafe_allow_html=True)
st.markdown(f'<div class="chat-message assistant-message"><strong>Answer:</strong> {chat["answer"]}</div>', unsafe_allow_html=True)
st.markdown("---")
else:
st.markdown('<div class="info-box">Please upload an audio file to start asking questions.</div>', unsafe_allow_html=True)Voici une analyse détaillée du code ci-dessus :
Ask Question s sur le bouton: Un champ de saisie de texte permet aux utilisateurs de saisir une question dans la langue sélectionnée, puis de cliquer sur le bouton « » (Poser la question) ou « » (Poser la question). Une fois, cliquez dessus :st.session_state.chat_history avec un horodatage.Cette dernière étape rassemble tous les composants précédemment définis, notamment l'initialisation de l'état de la session, l'affichage de la barre latérale, la gestion des téléchargements audio, la transcription, les résumés et les questions-réponses à l'aide d'une mise en page à deux colonnes.
Une fois que le serveur est opérationnel et que toutes les dépendances sont installées, cette étape garantit que l'application est fournie au navigateur via Streamlit et qu'elle est prête à être utilisée.
def main():
st.markdown('<h1 class="main-header">🎵 Voxtral Audio Assistant</h1>', unsafe_allow_html=True)
# Initialize session state
init_session_state()
# Render sidebar and get configuration
selected_language, temperature, top_p = render_sidebar()
col1, col2 = st.columns([1, 1])
with col1:
render_audio_processing()
with col2:
render_qa_section(selected_language)
st.markdown("---")
st.markdown("""
<div style="text-align: center;">
<p>Powered by <strong>Voxtral Mini 3B</strong> | Built with Streamlit</p>
<p>Supports multiple languages for audio analysis and Q&A</p>
</div>
""", unsafe_allow_html=True)
if __name__ == "__main__":
main() La fonction « main() » sert de point d'entrée pour l'application. Il contrôle la mise en page, coordonne le rendu et garantit que toutes les variables de session et tous les composants de l'interface utilisateur sont correctement initialisés. Voici un résumé de ce que décrivent les fonctions définies ci-dessus :
init_session_state(): Cette fonction prépare des valeurs par défaut telles que transcription, summary et chat_history afin de conserver l'état de l'application entre les interactions.render_sidebar(): Il charge les widgets de configuration, notamment le sélecteur de langue, le test de connexion et les paramètres du modèle.render_audio_processing(): Cette fonctionnalité permet aux utilisateurs de télécharger et de traiter des fichiers audio afin de les transcrire et d'en générer un résumé.render_qa_section(): Enfin, cette fonctionnalité permet de répondre à des questions en plusieurs langues sur les fichiers audio téléchargés.Une fois que tout est prêt, exécutez l'application à l'aide de :
pip install -r requirements.txtVeuillez vous assurer qu'il est accessible via l'URL spécifiée dans VOXTRAL_API_BASE à l'intérieur de votre config.py. Une fois toutes les dépendances installées, exécutez l'application Streamlit en exécutant la commande suivante dans le terminal :
streamlit run app.pyVotre navigateur ouvrira automatiquement l'interface. L'application est désormais entièrement fonctionnelle avec le téléchargement audio, la transcription en temps réel, les résumés et les questions-réponses multilingues, grâce à la technologie Voxtral Mini 3B.
Apprenez l'IA grâce à ces cours !
Cours
Cours
Cours