
Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Qwens Wan2.1 ist ein Open-Source-Modell zur Videogenerierung, das sowohl leistungsstark als auch zugänglich ist, da es auf Consumer-GPUs laufen kann.
Mit seiner großartigen Leistung konkurriert Wan2.1 mit Open-Source-Modellen wie HunyuanVideo und SkyReels und kommerziellen Lösungen wie Sora und Runway.
In diesem Artikel erfährst du, was Wan2.1 ist, was die wichtigsten Funktionen sind und wie es funktioniert. Außerdem zeige ich dir, wie du darauf zugreifen kannst und wie du damit Videos aus verschiedenen Eingabeaufforderungen erstellst, um seine Fähigkeiten in Aktion zu zeigen.
Wan 2.1 ist ein fortschrittliches Modell zur Videogenerierung, das von Qwen entwickelt wurde. Es gehört zu einer Familie von groß angelegten Videogrundlagenmodellen, d.h. es kann hochwertige Videos aus verschiedenen Arten von Eingaben erstellen, in diesem Fall aus Textbeschreibungen und Bildern.
Wan 2.1 kombiniert leistungsstarke Videoerstellung mit Barrierefreiheit. Im Gegensatz zu vielen anderen KI-Videomodellen, für die teure Hardware erforderlich ist, kann es auf Consumer-GPUs laufen, was es praktischer macht. Außerdem ist es Open Source.
Es basiert auf der Diffusionstransformator-Technologie, einem Ansatz, der es ermöglicht, glatte, realistische Videos mit beeindruckender Bewegungsqualität zu erzeugen. Wan 2.1 führt außerdem einen einzigartigen Video Variational Autoencoder (VAE) ein, der dazu beiträgt, dass das Video auch bei höheren Auflösungen wie 1080p konsistent und detailreich bleibt.
Hier sind seine wichtigsten Merkmale:
Wan 2.1 übertrifft sowohl Open-Source- als auch kommerzielle KI-Videomodelle in mehreren Benchmarks, d.h. es produziert realistischere, qualitativ hochwertigere Videos als viele Alternativen.
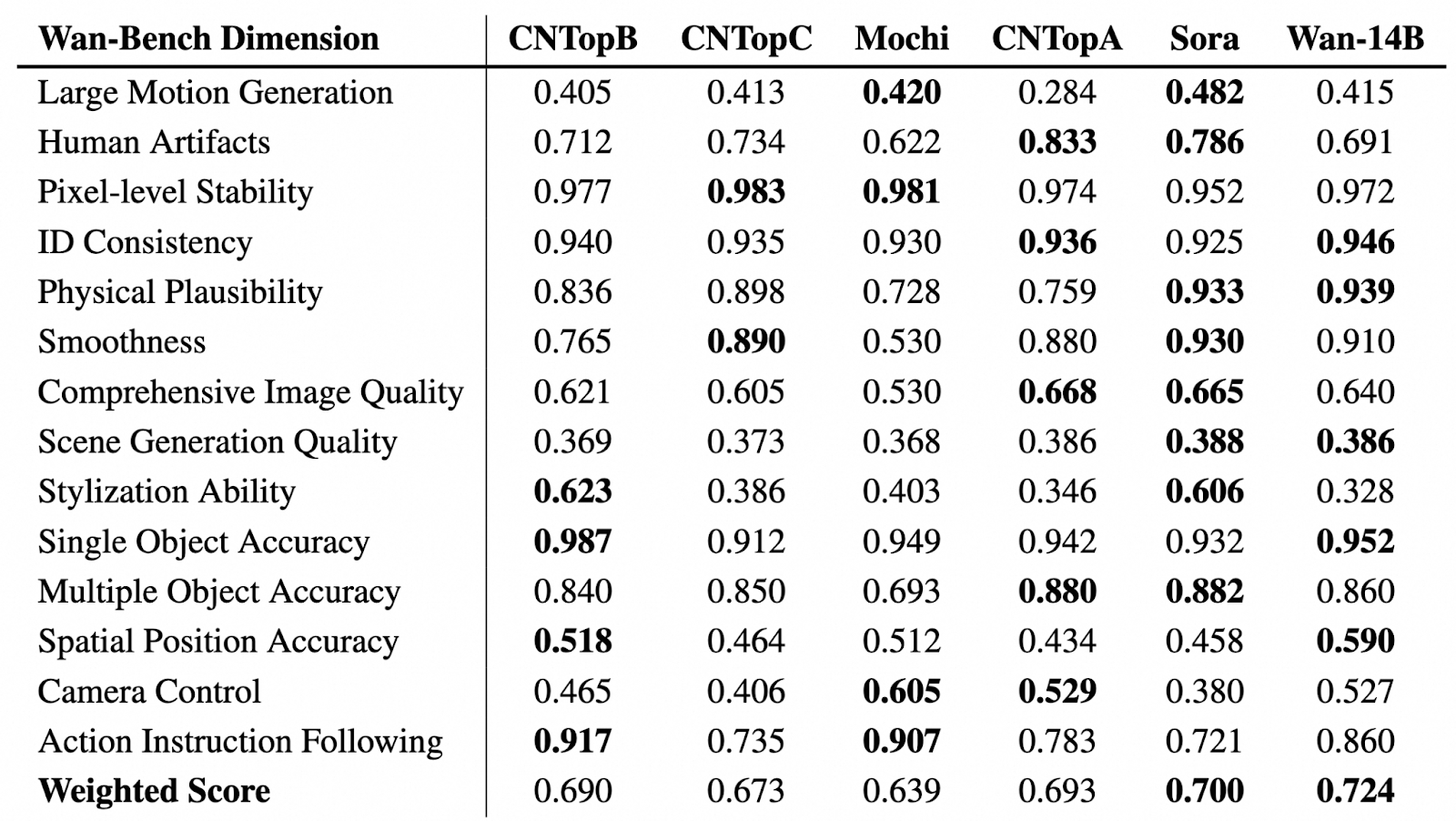
Quelle: GitHub (Wan-Video/Wan2.1)
In der obigen Tabelle sehen wir eine vergleichende Bewertung der Videogenerierungsmodelle über verschiedene Wan-Bench-Dimensionen hinweg, wobei ihre Leistung in Bezug auf Schlüsselaspekte wie Bewegungsgenerierung, visuelle Stabilität, Objektgenauigkeit und Befolgung von Anweisungen bewertet wird. Das leistungsstärkste Modell in jeder Kategorie ist fett hervorgehoben.
Wan-14B erreicht die höchste gewichtete Gesamtpunktzahl (0,724) und beweist damit seine starken Fähigkeiten bei mehreren Benchmarks.
Im Vergleich zu den meisten High-End-KI-Videomodellen, die teure Hardware benötigen, benötigt das T2V-1.3B-Modell von Wan 2.1 nur 8,19 GB VRAM. Das bedeutet, dass du mit einer normalen GPU, wie einer RTX 4090, in wenigen Minuten Videos erstellen kannst, ohne einen Supercomputer zu benötigen.
Mit Wan kannst du mehr als nur Text-to-Video (T2V) machen. Es bietet fortschrittliche Funktionen zur Verbesserung der Videoerstellung und -anpassung, darunter:
Außerdem unterstützt Wan Image-to-Video (I2V), sodass du Standbilder in animierte Videos umwandeln kannst. Du kannst optionale Textaufforderungen hinzufügen, um mehr Kontrolle über die Videoerstellung zu haben, und das erste und das letzte Bild festlegen, um den Aufbau und den Fluss des Videos zu gestalten.
Wan 2.1 ist das erste KI-Videomodell, das lesbaren Text in Videos sowohl auf Englisch als auch auf Chinesisch erzeugen kann. Diese Funktion eignet sich hervorragend zum Erstellen von Untertiteln, animiertem Text und grafischen Einblendungen in Videoinhalten.
Wan 2.1 verwendet einen fortschrittlichen Video Variational Auto Encoder (Wan-VAE), der es ermöglicht:
Es gibt mehrere Möglichkeiten, damit anzufangen - du kannst es entweder online ausprobieren oder es lokal auf deinem Computer ausführen.
Wenn du mit Wan 2.1 experimentieren willst, ohne etwas zu installieren, kannst du es über
1. Hugging Face Raum: Du kannst das Modell direkt in einer Weboberfläche ausführen.
2. WanVideo Website: Hier kannst du mehr tun, als nur Videos zu erstellen. Auf der offiziellen Website kannst du auch Bilder erstellen und eine Sammlung von Videos und Bildern anderer Nutzerinnen und Nutzer zusammen mit den von ihnen verwendeten Prompts entdecken.
Diese Optionen ermöglichen es dir, das Modell schnell zu testen, ohne dich um die Einrichtung oder die Hardware zu kümmern.
Wenn du die volle Kontrolle und Anpassungsmöglichkeiten haben möchtest, kannst du Wan 2.1 auf deinem eigenen Rechner installieren. Wir gehen Schritt für Schritt vor, wie du das machst:
Lade zuerst den Wan 2.1 Code von GitHub herunter:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1Vergewissere dich, dass du Python und PyTorch (Version 2.4.0 oder höher) installiert hast, und installiere dann die erforderlichen Bibliotheken:
pip install -r requirements.txtDu musst die vortrainierten Modelldateien von Hugging Face herunterladen (weitere Informationen findest du hier) oder ModelScope (mehr Infos dazu hier).Es gibt verschiedene Modelle, die du herunterladen kannst:
|
Modelle |
Download Link |
Anmerkungen |
|
T2V-14B |
Unterstützt sowohl 480P als auch 720P |
|
|
I2V-14B-720P |
Unterstützt 720P |
|
|
I2V-14B-480P |
Unterstützt 480P |
|
|
T2V-1.3B |
Unterstützt 480P |
Das 1.3B-Modell kann Videos in 720P-Auflösung erstellen, aber da es für diese Qualität weniger Übung hatte, können die Ergebnisse weniger stabil sein als bei 480P. Für die beste Leistung wird eine Auflösung von 480P empfohlen.
Wan 2.1 ermöglicht es dir, Videos aus Textbeschreibungen zu erstellen, indem du zwei Modellversionen verwendest:
Wenn du nur schnell ein Video erstellen willst, kannst du die folgenden Befehle verwenden, bei denen die Prompt-Erweiterung nicht aktiviert ist.
Für das T2V-14B-Modell (höherwertiges, größeres Modell):
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights."Für das T2V-1.3B-Modell (kleiner, läuft auf leistungsschwächeren GPUs):
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "A futuristic city with flying cars and neon lights."Wenn deinem Computer der Speicher ausgeht (OOM-Fehler), kannst du --offload_model True und --t5_cpu verwenden, um die Speichernutzung zu reduzieren.
Wenn du mehrere Grafikprozessoren hast, kannst du die Videoerzeugung mit diesem Befehl beschleunigen:
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "A futuristic city with flying cars and neon lights.`Dadurch kann die Arbeitslast auf mehrere GPUs aufgeteilt werden, was den Prozess beschleunigt.
Wan 2.1 kann deinen Prompt automatisch verbessern, sodass du das Video detaillierter und visuell ansprechender gestalten kannst.
Es gibt zwei Möglichkeiten, die Aufforderung zu erweitern:
Um Dashscope API zu verwenden:
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'dashscope'Um dein eigenes lokales Modell zu verwenden:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'local_qwen'Wenn du die Diffusers-Bibliothek von Hugging Face verwenden möchtest, anstatt rohe Skripte auszuführen, kannst du ein Video mit Python erstellen:
import torch
from diffusers.utils import export_to_video
from diffusers import AutoencoderKLWan, WanPipeline
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
# Available models: Wan-AI/Wan2.1-T2V-14B-Diffusers, Wan-AI/Wan2.1-T2V-1.3B-Diffusers
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
# Load the autoencoder for video generation
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
# Define the scheduler for controlling video motion flow
flow_shift = 5.0 # 5.0 for 720P, 3.0 for 480P
scheduler = UniPCMultistepScheduler(
prediction_type='flow_prediction',
use_flow_sigmas=True,
num_train_timesteps=1000,
flow_shift=flow_shift
)
# Load the video generation pipeline with the model
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
pipe.scheduler = scheduler
pipe.to("cuda")
# New prompt
prompt = "A futuristic city at sunset, filled with flying cars and neon lights. The buildings have a sleek, cyberpunk design, and people walk on glowing sidewalks. The scene is full of vibrant colors, reflections, and dynamic movement."
# New negative prompt
negative_prompt = "Dull colors, grainy texture, washed-out details, static frames, incorrect lighting, unnatural shadows, distorted faces, artifacts, low-resolution elements, flickering, blurry motion, repetitive patterns, unrealistic reflections, overly simplistic backgrounds, three legged people, walking backwards."
# Generate the video frames
output = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=720,
width=1280,
num_frames=81,
guidance_scale=5.0,
).frames[0]
# Export the generated frames as a video
export_to_video(output, "output.mp4", fps=16)Das Skript beginnt mit dem Laden des Modells Wan2.1-T2V-14B-Diffusers, das zum Erstellen von Videos verwendet wird. Außerdem wird ein VAE (Autoencoder) geladen, der bei der Verarbeitung und Verbesserung der Videobilder hilft. Um zu steuern, wie flüssig Bewegungen im Video erscheinen, verwendet das Skript einen Scheduler (UniPCMultistepScheduler). Die Einstellung flow_shift regelt, wie Bewegungen verarbeitet werden, wobei 5.0 besser für eine höhere Auflösung (720P) und 3.0 für eine niedrigere Auflösung (480P) ist.
Als Nächstes richtet das Skript die Videogenerierungspipeline (WanPipeline) ein und wendet den Scheduler an, um sanftere Übergänge zwischen den Bildern zu gewährleisten. Die Aufforderung beschreibt eine futuristische Stadt mit fliegenden Autos und leuchtenden Neonlichtern, während die negative Aufforderung hilft, unerwünschte Effekte wie verschwommene Details, verwaschene Farben und flackernde Rahmen zu entfernen.
Das Modell erstellt dann 81 Bilder, was etwa 5 Sekunden Video bei 16 Bildern pro Sekunde (FPS) ergibt. Die guidance_scale ist auf 5.0 eingestellt, was dem Modell hilft, der Aufforderung zu folgen, aber auch etwas Kreativität zulässt. Sobald das Video erstellt ist, werden die Bilder kombiniert und als "output.mp4" mit 16 FPS gespeichert.
Der negative Prompt spielt eine wichtige Rolle bei der Verbesserung des fertigen Videos, indem er dem Modell sagt, was es vermeiden soll. Sie hilft, Dinge wie schlechte Bildqualität, seltsame Verzerrungen oder alles, was das Video unrealistisch aussehen lassen könnte, zu beseitigen. In diesem Fall sorgt sie dafür, dass die futuristische Szene sauber, scharf und visuell ansprechend aussieht.
Wenn du eine interaktive Weboberfläche zum Erstellen von Videos bevorzugst, anstatt Code zu verwenden, kannst du Wan 2.1 mit Gradio ausführen:
Für Dashscope Prompt Extension:
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14BFür die lokale Prompt-Durchwahl:
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14BÄhnlich wie bei Text-zu-Video wird auch Bild-zu-Video in Prozesse mit und ohne den Schritt der Prompt-Erweiterung unterteilt. Für weitere Details zur Implementierung kannst du die offizielle GitHub. Du kannst auch in ihren Discord-Kanal beitreten, um über Wan2.1 zu diskutieren, deine Kreationen mit anderen zu teilen, Neuigkeiten über neue Funktionen und Entwicklungen zu erfahren und die offiziellen Website um die erstellten Beispiele zu erkunden.
Wan 2.1 nutzt fortschrittliche KI-Techniken, um hochwertige, realistische Videos zu erstellen. Sie folgt einem diffusionsbasierten Ansatz und integriert Transformatoren um sicherzustellen, dass die Bewegungen über alle Frames hinweg gleichmäßig, konsistent und detailliert sind.
Wan 2.1 verwendet eine Technik namens Diffusionsmodelle, die in zwei Schritten funktionieren:
Es ist wie beim Entwickeln eines Fotos in der Dunkelkammer - das Bild ist anfangs unscharf und körnig, wird aber mit jedem Bearbeitungsschritt klarer.
Wan 2.1 verbessert diesen Ansatz durch den Einsatz eines Diffusionstransformators (DiT), der dazu beiträgt, scharfe Details und flüssige Bewegungen zu erhalten, während er mehrere Videobilder erzeugt.
Quelle: GitHub (Wan-Video/Wan2.1)
Dieses Diagramm zeigt, wie Wan 2.1 Videobilder mit einem Diffusionsmodell erzeugt, das mit einem Diffusionstransformator (DiT) erweitert wurde. Der Prozess beginnt mit einer Eingabebeschreibung (z. B. "Ein Panda hält einen Karton hoch, auf dem 'Wan2.1' steht"). Dieser Text wird von UMT5 verarbeitet, einem Sprachmodell, das dem System hilft, die Aufforderung zu verstehen und zu verfeinern.
Gleichzeitig wird ein verrauschtes Ausgangsbild als Startpunkt eingeführt. Der Wan-Encoder verarbeitet dann diese Eingaben und kodiert sie in eine Form, die das Modell verarbeiten kann. N x DiT Blöcke verfeinern das Bild iterativ.
Das Diffusionsmodell entfernt nach und nach das Rauschen aus den Frames und nutzt die Cross-Attention, um die Ausgabe mit dem vorgegebenen Prompt abzugleichen. Der Zeitschritt (t) gibt die progressiven Schritte bei der Entrauschung an und stellt sicher, dass sich das Video im Laufe der Zeit gleichmäßig entwickelt.
Nach mehreren Verfeinerungsschritten rekonstruiert der Wan-Decoder die endgültigen Videobilder aus den verarbeiteten Daten. Die Ausgabe ist eine Reihe von Einzelbildern, die sich an der ursprünglichen Eingabebeschreibung orientieren und dabei scharfe Details, flüssige Bewegungen und Konsistenz beibehalten.
Wan 2.1 enthält Wan-VAE, ein leistungsstarkes Komprimierungswerkzeug, das das Modell unterstützt:
Das ist so, wie wenn du Dateien für Videos zippst: Es komprimiert und speichert wichtige Details und rekonstruiert sie dann bei der Erstellung des Videos genau.
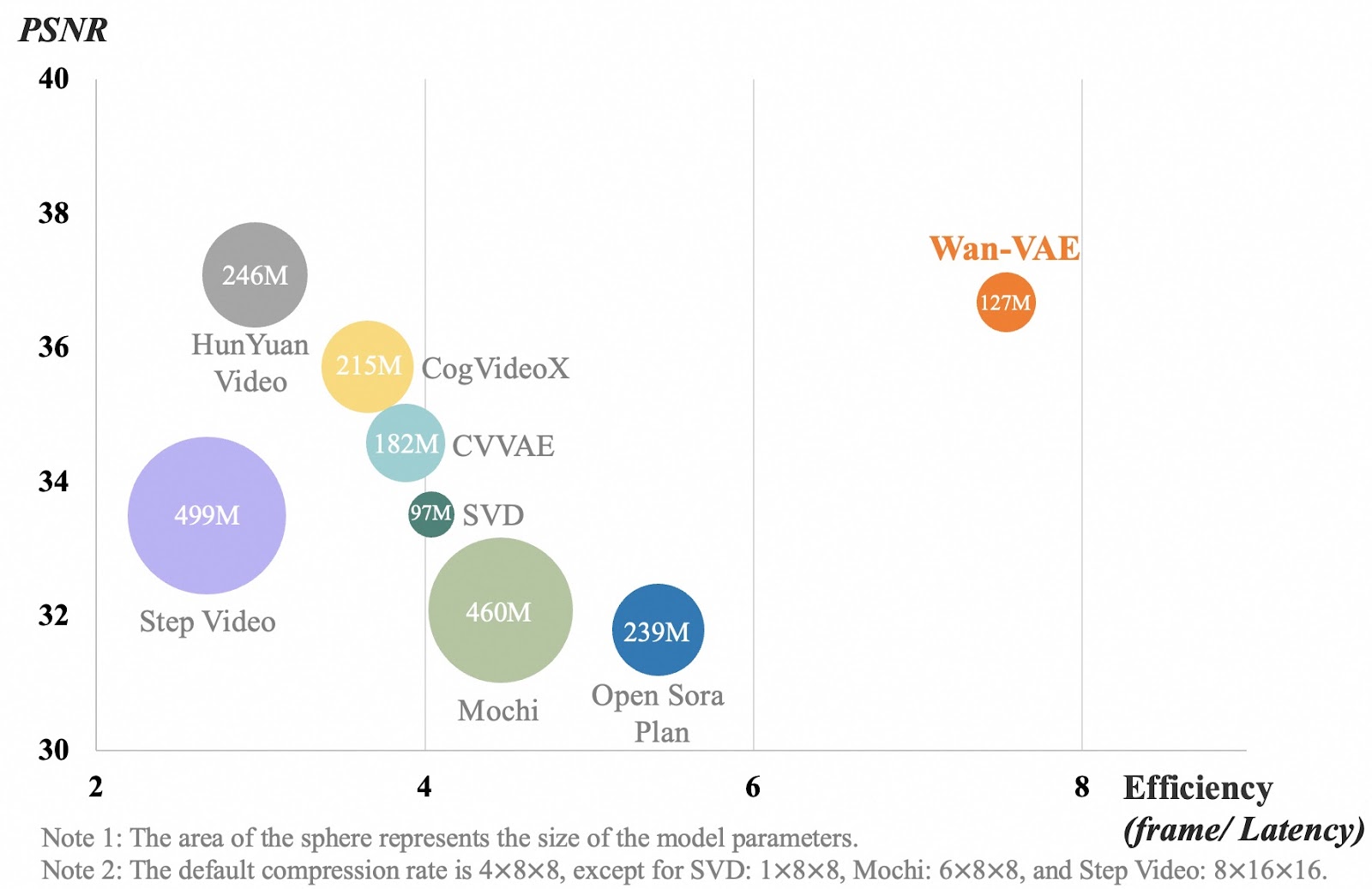
Quelle: GitHub (Wan-Video/Wan2.1)
Die Tabelle vergleicht verschiedene Videokompressionsmodelle anhand der Videoqualität (PSNR) und der Effizienz (wie schnell sie Bilder verarbeiten). Jede Blase steht für ein Modell, und ihre Größe zeigt an, wie groß das Modell ist. Die x-Achse misst, wie effizient ein Modell Videobilder verarbeitet. Eine höhere Zahl bedeutet, dass das Modell schneller arbeitet. Die y-Achse zeigt die Videoqualität an, wobei eine höhere Zahl für klarere, detailliertere Videos steht.
Wan-VAE, in orange dargestellt, schneidet besser ab als andere Modelle, indem es hohe Videoqualität mit schneller Verarbeitung verbindet und dabei relativ klein bleibt (127M Parameter). Andere Modelle, wie Step Video und Mochi, sind viel größer, verarbeiten aber die Bilder nicht so effizient. Das bedeutet, dass Wan-VAE lange Videos in hoher Qualität erstellen kann, ohne dass die Details scharf und die Bewegungen ruckelfrei bleiben, ohne dabei langsamer zu werden.
Wan 2.1 ist ein vielseitiges Modell zur Erzeugung von KI-Videos, das in vielen Branchen eingesetzt werden kann. In diesem Abschnitt werde ich einige Beispiele für verschiedene Anwendungsfälle ausprobieren.
Wan 2.1 kann dir helfen, einzigartige Videoinhalte zu erstellen, ohne teure Ausrüstung oder lange Bearbeitungszeiten. Stellen wir uns also vor, dass ich ein Lifestyle-Influencer bin und einen Inhalt über einen gemütlichen Tag in meinem Leben erstellen möchte. Ichwerde die folgende Aufforderung verwenden, um einen Clip für mein Video zu erstellen:
Eine Zeitraffer-Animation eines gemütlichen Cafés von morgens bis abends, die zeigt, wie Leute kommen und gehen, wie der Kaffee gebrüht wird und wie sich der Sonnenuntergang in den Fenstern spiegelt.
Weil ich es so realistisch wie möglich machen wollte, habe ich auch den Inspirationsmodus benutzt. Das ist das Ergebnis, das ich erhalten habe:
Als das Video erstellt wurde, war ich auf den ersten Blick sehr beeindruckt. Aber als ich genauer hinsah, wurden mir ein paar Dinge klar. Zuerst verschwindet jemand im Hintergrund. Außerdem ist dies kein Zeitraffer, und es wird kein Kaffee gebrüht. Obwohl das Video also ziemlich realistisch aussieht, gibt es die Aufforderung nicht genau wieder.
Nun stell dir vor, du bist ein Spieleentwickler. Du kannst Wan 2.1 verwenden, um realistische Zwischensequenzen, Hintergrundanimationen oder Konzeptzeichnungen für deine Projekte zu erstellen. Wenn du zum Beispiel bereits ein Charakterkonzept hast und das Kreativteam einige Entwürfe zur Verfügung gestellt hat, kannst du sie mit der Bild-zu-Video-Funktion von Wan zum Leben erwecken.
Mit Wan 2.1 kannst du nicht nur Charaktere animieren, sondern auch dynamische Umgebungen erstellen, wie z. B. wechselnde Wettereffekte, belebte Städte oder mystische Landschaften, ohne dass du jedes Bild manuell animieren musst.
Mit der Steuerung des Seitenverhältnisses kannst du außerdem sicherstellen, dass deine Animationen perfekt in verschiedene Spielszenen passen, z. B. in Widescreen-Kinofilme (16:9), mobilfreundliche vertikale Aufnahmen (9:16) oder quadratische Kompositionen (1:1) für Social-Media-Teaser.
Mit den Soundeffekten kannst du sogar Hintergrundgeräusche erzeugen, wie das Rascheln von Blättern, das Summen einer futuristischen Stadt oder Kampfgeräusche.
Lass uns etwas ausprobieren!Ich habe diesen Entwurf eines mittelalterlichen Ritters mit DALL-E erstellt:

Mit Wan habe ich die folgende Eingabeaufforderung mit GPT-4o-mini eingegeben:
Ein mittelalterlicher Ritter steht in heldenhafter Haltung und hält mit beiden Händen ein großes Schwert in der Hand. Sein Umhang weht im Wind, während er das Schlachtfeld überblickt. Der Ritter dreht langsam seinen Kopf und scannt den Horizont mit entschlossenem Blick. Die Animation hat einen filmischen Stil.Aber dann habe ich auf "Erweiterte Eingabeaufforderung" geklickt und das ist, was ich bekommen habe:
Cinematic Medieval Knight: Ein tapferer Ritter in voller Rüstung steht entschlossen da und hält mit beiden Händen ein mächtiges Breitschwert in der Hand. Sein Visierhelm und seine Schulterpanzer glänzen in der Sonne, während ein edles Wappen seinen Brustpanzer ziert. Eine Schärpe umschließt seine Taille und sichert sein Ensemble. Sein karmesinroter Mantel weht dramatisch im Wind, was seine imposante Präsenz noch verstärkt. Mit stählernem Blick schwenkt er den Kopf und überblickt das weite, sandige Schlachtfeld. Die Szene entfaltet sich auf pergamentartigem, strukturiertem Papier, das an ein altes Manuskript erinnert. Dies ist eine großartige Ganzkörperaufnahme, die den Ritter in einer triumphalen Pose zeigt, die an das epische Mittelalterkino erinnert.
Ich habe den Inspirationsmodus ausgeschaltet, aber die Soundeffekte aktiviert. Hier ist das Ergebnis:
Nicht schlecht! Obwohl ich zugeben muss, dass ich eher eine filmische Version des Entwurfs erwartet habe als eine Animation des Entwurfs selbst. Aber vielleicht hätte ich in der Aufforderung deutlicher sein können. Die Musik ist interessant, und ich denke, sie passt gut zur Animation!
Wenn du ein Vermarkter bist, kannst du Wan 2.1 nutzen, um Werbevideos für Marken, Produkte und Dienstleistungen zu erstellen oder sogar Logos zu animieren.
Stell dir vor, du hast ein Eiscremegeschäft und möchtest dein Logo animieren, um es am Ende deiner Werbung oder deiner Werbevideos einzubauen.Um diese Idee zu testen, habe ich dieses Bild noch einmal mit DALL-E erstellt:

Dann habe ich diese Aufforderung benutzt: Der Eisbär frisst das Eis. Das ist das Ergebnis der Bild-zu-Video-Generierung:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
