
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Transformatoren wurden zuerst entwickelt, um das Problem der Sequenztransduktion oder der neuronalen maschinellen Übersetzung zu lösen, d.h. sie sind dazu gedacht, jede Aufgabe zu lösen, die eine Eingabesequenz in eine Ausgabesequenz umwandelt. Deshalb werden sie "Transformers" genannt.
Aber fangen wir von vorne an.
Ein Transformationsmodell ist ein neuronales Netzwerk, das den Kontext von aufeinanderfolgenden Daten lernt und daraus neue Daten generiert.
Um es einfach auszudrücken:
Ein Transformer ist eine Art Modell der künstlichen Intelligenz, das lernt, menschenähnlichen Text zu verstehen und zu erzeugen, indem es Muster in großen Mengen von Textdaten analysiert.
Transformatoren sind ein aktuelles NLP-Modell und gelten als Weiterentwicklung der Encoder-Decoder-Architektur. Während sich die Encoder-Decoder-Architektur jedoch hauptsächlich auf rekurrente neuronale Netze (RNNs) stützt, um sequentielle Informationen zu extrahieren, fehlt Transformers diese Rekurrentität völlig.
Wie machen sie es also?
Sie sind speziell darauf ausgerichtet, Kontext und Bedeutung zu verstehen, indem sie die Beziehung zwischen verschiedenen Elementen analysieren, und sie verlassen sich dabei fast ausschließlich auf eine mathematische Technik, die Aufmerksamkeit genannt wird.

Bild des Autors.
Transformationsmodelle sind eine der jüngsten und einflussreichsten Entwicklungen im Bereich des maschinellen Lernens und gehen auf ein Forschungspapier von Google aus dem Jahr 2017 zurück. Das erste Transformer-Modell wurde in dem einflussreichen Papier "Attention is All You Need" erläutert.
Dieses bahnbrechende Konzept war nicht nur ein theoretischer Fortschritt, sondern wurde auch praktisch umgesetzt, vor allem im TensorFlow-Paket Tensor2Tensor. Außerdem hat die Harvard-NLP-Gruppe einen Beitrag zu diesem aufkeimenden Feld geleistet, indem sie einen kommentierten Leitfaden zu dem Papier angeboten hat, der durch eine PyTorch-Implementierung ergänzt wurde. In unserem separaten Tutorial erfährst du mehr darüber, wie du einen Transformer von Grund auf implementierst.
Ihre Einführung hat zu einem erheblichen Aufschwung in diesem Bereich geführt, der oft als Transformer AI bezeichnet wird. Dieses revolutionäre Modell legte den Grundstein für spätere Durchbrüche auf dem Gebiet der großen Sprachmodelle, darunter auch BERT. Im Jahr 2018 wurden diese Entwicklungen bereits als Wendepunkt im NLP gefeiert.
Im Jahr 2020 kündigten die Forscher von OpenAI das GPT-3 an . Innerhalb weniger Wochen zeigte sich die Vielseitigkeit von GPT-3, als Menschen damit Gedichte, Programme, Lieder, Webseiten und vieles mehr erstellten und damit die Fantasie von Nutzern auf der ganzen Welt anregten.
In einem Papier aus dem Jahr 2021 bezeichneten Stanford-Wissenschaftler diese Innovationen treffend als Gründungsmodelle und unterstrichen damit ihre grundlegende Rolle bei der Umgestaltung der KI. Ihre Arbeit zeigt, wie Transformatorenmodelle nicht nur das Feld revolutioniert haben, sondern auch die Grenzen des Machbaren in der künstlichen Intelligenz verschoben haben und eine neue Ära der Möglichkeiten einläuten.
"Wir befinden uns in einer Zeit, in der uns einfache Methoden wie neuronale Netze eine Explosion neuer Möglichkeiten bieten", sagtAshish Vaswani, ein Unternehmer und ehemaliger leitender Forscher bei Google
Zum Zeitpunkt der Einführung des Transformer-Modells waren RNNs der bevorzugte Ansatz für den Umgang mit sequentiellen Daten, die durch eine bestimmte Reihenfolge in der Eingabe gekennzeichnet sind.
RNNs funktionieren ähnlich wie ein neuronales Feed-Forward-Netzwerk, verarbeiten die Eingaben jedoch sequentiell, ein Element nach dem anderen.
Die Transformatoren wurden von der Encoder-Decoder-Architektur inspiriert, die man in RNNs findet. Statt auf Rekursion basiert das Transformer-Modell jedoch vollständig auf dem Aufmerksamkeitsmechanismus.
Neben der Verbesserung der RNN-Leistung haben Transformers eine neue Architektur zur Lösung vieler anderer Aufgaben wie Textzusammenfassung, Bildunterschriften und Spracherkennung geschaffen.
Was sind also die Hauptprobleme von RNNs? Für NLP-Aufgaben sind sie vor allem aus zwei Gründen ziemlich uneffektiv:
Der Wechsel von rekurrenten neuronalen Netzen (RNNs) wie LSTM zu Transformers in der NLP wird von diesen beiden Hauptproblemen und der Fähigkeit von Transformers, beide zu bewerten, angetrieben, indem sie die Verbesserungen des Aufmerksamkeitsmechanismus nutzen:
So wurden Transformers zu einer natürlichen Verbesserung von RNNs.
Als Nächstes wollen wir uns ansehen, wie Transformatoren funktionieren.
Ursprünglich für die Sequenztransduktion oder neuronale Maschinenübersetzung entwickelt, zeichnen sich Transformatoren durch die Umwandlung von Eingangssequenzen in Ausgangssequenzen aus. Es ist das erste Transduktionsmodell, das sich vollständig auf die Selbstaufmerksamkeit verlässt, um Repräsentationen der Ein- und Ausgabe zu berechnen, ohne sequenzorientierte RNNs oder Faltung zu verwenden. Das Hauptmerkmal der Transformers-Architektur ist, dass sie das Encoder-Decoder-Modell beibehält.
Wenn wir einen Transformer für die Sprachübersetzung als eine einfache Blackbox betrachten, würde er einen Satz in einer Sprache, z.B. Englisch, als Eingabe nehmen und seine Übersetzung in Englisch ausgeben.

Bild des Autors.
Wenn wir ein wenig abtauchen, stellen wir fest, dass diese Blackbox aus zwei Hauptteilen besteht:
Bild des Autors. Globale Struktur von Encoder-Decoder.
Allerdings sind sowohl der Encoder als auch der Decoder eigentlich ein Stapel mit mehreren Schichten (jeweils die gleiche Anzahl). Alle Encoder weisen dieselbe Struktur auf, und die Eingaben gehen in jeden von ihnen ein und werden an den nächsten weitergegeben. Alle Dekoder haben die gleiche Struktur und erhalten den Input vom letzten Enkoder und dem vorherigen Dekoder.
Die ursprüngliche Architektur bestand aus 6 Encodern und 6 Decodern, aber wir können so viele Schichten replizieren, wie wir wollen. Gehen wir also von jeweils N Schichten aus.
Bild des Autors. Globale Struktur von Encoder-Decoder. Mehrere Schichten.
Nachdem wir nun eine allgemeine Vorstellung von der Gesamtarchitektur des Transformators haben, wollen wir uns auf die beiden Encoder und Decoder konzentrieren, um ihren Arbeitsablauf besser zu verstehen:
Der Encoder ist eine grundlegende Komponente der Transformer-Architektur. Die Hauptaufgabe des Encoders ist es, die eingegebenen Token in kontextualisierte Darstellungen umzuwandeln. Im Gegensatz zu früheren Modellen, die Token unabhängig voneinander verarbeiteten, erfasst der Transformer-Encoder den Kontext jedes Tokens in Bezug auf die gesamte Sequenz.
Seine Struktur setzt sich wie folgt zusammen:
Bild des Autors. Globale Struktur von Encodern.
Zerlegen wir also den Arbeitsablauf in seine grundlegendsten Schritte:
Die Einbettung erfolgt nur im untersten Encoder. Der Kodierer beginnt mit der Umwandlung der eingegebenen Token - Wörter oder Teilwörter - in Vektoren unter Verwendung von Einbettungsschichten. Diese Einbettungen erfassen die semantische Bedeutung der Token und wandeln sie in numerische Vektoren um.
Alle Kodierer erhalten eine Liste von Vektoren mit einer Größe von 512 (feste Größe). Im unteren Encoder wären das die Worteinbettungen, aber in anderen Encodern wäre es die Ausgabe des Encoders, der direkt darunter liegt.
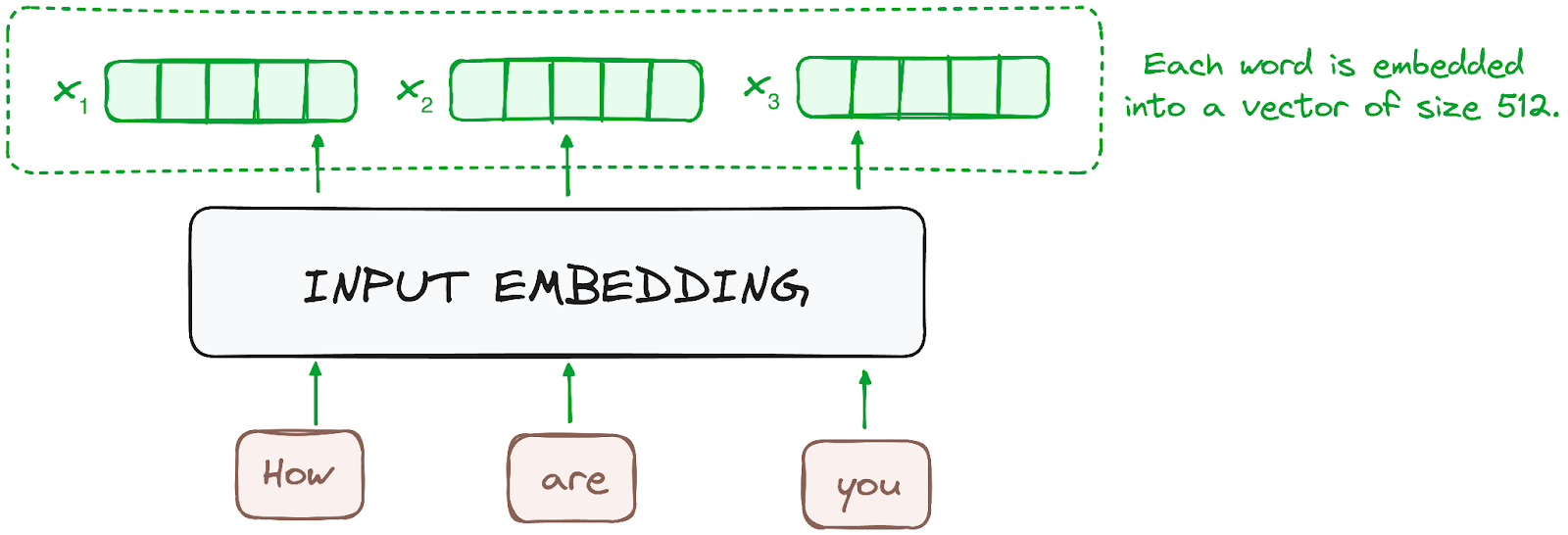
Bild des Autors. Der Arbeitsablauf des Encoders. Einbettung des Inputs.
Da Transformers nicht über einen Rekursionsmechanismus wie RNNs verfügen, verwenden sie Positionskodierungen, die zu den Eingabeeinbettungen hinzugefügt werden, um Informationen über die Position jedes Tokens in der Sequenz zu liefern. So können sie die Position der einzelnen Wörter im Satz verstehen.
Die Forscherinnen und Forscher schlugen vor, eine Kombination aus verschiedenen Sinus- und Kosinusfunktionen zu verwenden, um Positionsvektoren zu erstellen, die es ermöglichen, diesen Positionskodierer für Sätze beliebiger Länge zu verwenden.
Bei diesem Ansatz wird jede Dimension durch eindeutige Frequenzen und Offsets der Welle repräsentiert, wobei die Werte von -1 bis 1 reichen, was effektiv jede Position darstellt.
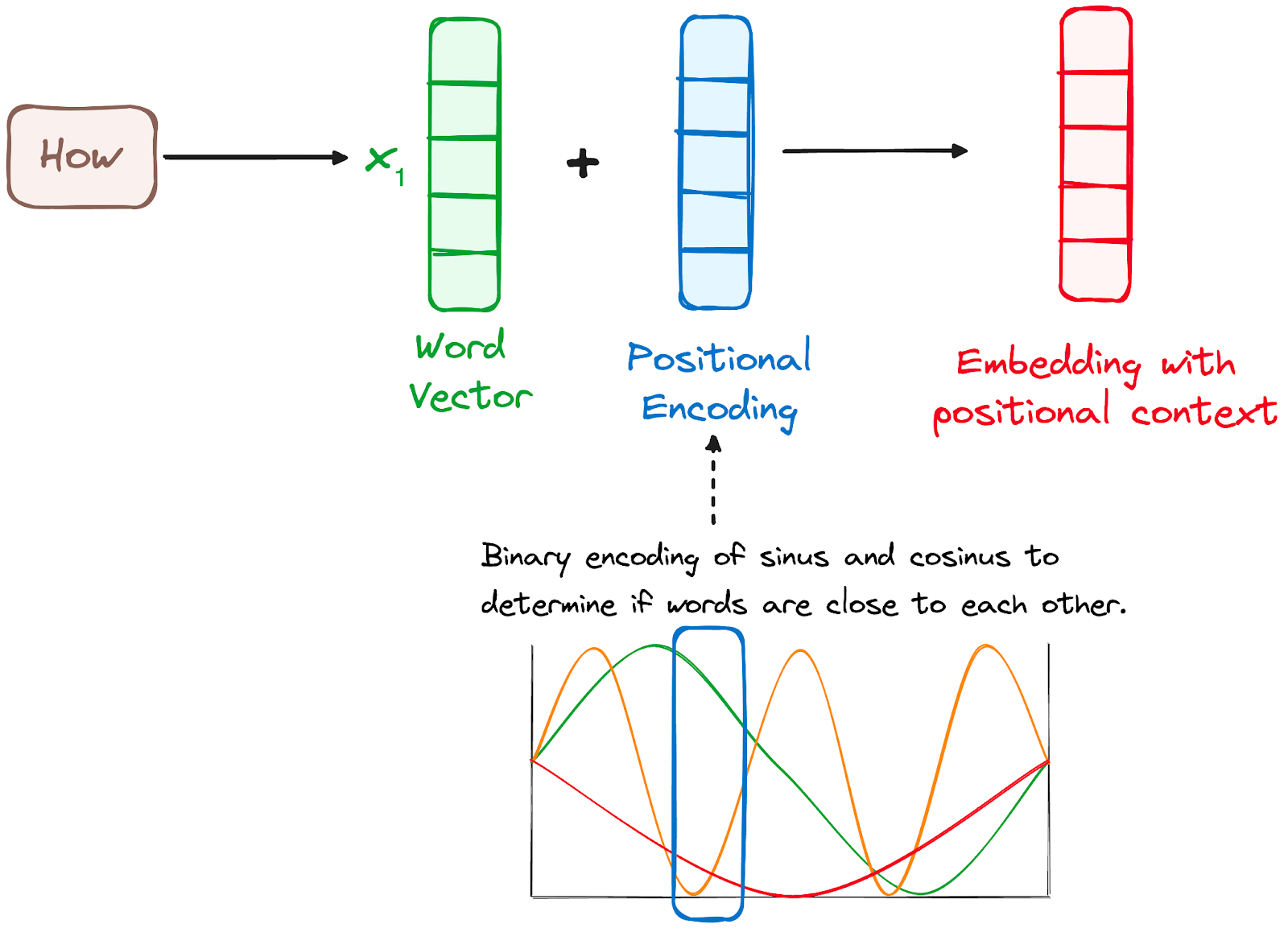
Bild des Autors. Der Arbeitsablauf des Encoders. Positionelle Kodierung.
Der Transformer-Encoder besteht aus einem Stapel identischer Schichten (6 im ursprünglichen Transformer-Modell).
Die Encoderschicht dient dazu, alle Eingabesequenzen in eine kontinuierliche, abstrakte Darstellung umzuwandeln, die die gelernten Informationen aus der gesamten Sequenz kapselt. Diese Schicht besteht aus zwei Untermodulen:
Außerdem werden Restverbindungen um jede Teilschicht herum berücksichtigt, auf die dann eine Schichtnormalisierung folgt.
Bild des Autors. Der Arbeitsablauf des Encoders. Stapel von Encoderschichten
Im Encoder nutzt die mehrköpfige Aufmerksamkeit einen speziellen Aufmerksamkeitsmechanismus, der als Selbstaufmerksamkeit bekannt ist. Dieser Ansatz ermöglicht es den Modellen, jedes Wort in der Eingabe mit anderen Wörtern in Beziehung zu setzen. In einem bestimmten Beispiel könnte das Modell zum Beispiel lernen, das Wort "sind" mit "du" zu verbinden.
Dieser Mechanismus ermöglicht es dem Encoder, sich auf verschiedene Teile der Eingangssequenz zu konzentrieren, während er jedes Token verarbeitet. Es berechnet die Aufmerksamkeitswerte auf der Grundlage von:
Dieses erste Self-Attention-Modul ermöglicht es dem Modell, kontextbezogene Informationen aus der gesamten Sequenz zu erfassen. Anstatt eine einzige Aufmerksamkeitsfunktion auszuführen, werden Abfragen, Schlüssel und Werte h-mal linear projiziert. Für jede dieser projizierten Versionen von Abfragen, Schlüsseln und Werten wird der Aufmerksamkeitsmechanismus parallel ausgeführt, was h-dimensionale Ausgabewerte ergibt.
Die detaillierte Architektur sieht folgendermaßen aus:
Nachdem die Abfrage-, Schlüssel- und Wertvektoren eine lineare Schicht durchlaufen haben, wird eine Punktprodukt-Matrixmultiplikation zwischen den Abfragen und Schlüsseln durchgeführt, wodurch eine Punktematrix entsteht.
Die Punktematrix legt fest, wie stark jedes Wort gegenüber anderen Wörtern betont werden sollte. Daher wird jedem Wort eine Punktzahl im Verhältnis zu anderen Wörtern innerhalb desselben Zeitschritts zugewiesen. Eine höhere Punktzahl bedeutet mehr Konzentration.
Dieser Prozess ordnet die Abfragen effektiv den entsprechenden Schlüsseln zu.
Bild des Autors. Der Arbeitsablauf des Encoders. Aufmerksamkeitsmechanismus - Matrixmultiplikation.
Die Punktzahlen werden dann durch die Quadratwurzel aus der Dimension der Abfrage- und Schlüsselvektoren geteilt und skaliert. Dieser Schritt wird durchgeführt, um stabilere Gradienten zu gewährleisten, da die Multiplikation der Werte zu übermäßig großen Auswirkungen führen kann.
Bild des Autors. Der Arbeitsablauf des Encoders. Senkung der Aufmerksamkeitswerte.
Anschließend wird eine Softmax-Funktion auf die angepassten Punktzahlen angewendet, um die Aufmerksamkeitsgewichte zu erhalten. Daraus ergeben sich Wahrscheinlichkeitswerte zwischen 0 und 1. Die Softmax-Funktion hebt höhere Werte hervor, während sie niedrigere Werte abschwächt. Dadurch kann das Modell besser bestimmen, welche Wörter mehr Aufmerksamkeit erhalten sollten.
Bild des Autors. Der Arbeitsablauf des Encoders. Softmax angepasste Noten.
Der folgende Schritt des Aufmerksamkeitsmechanismus besteht darin, dass die aus der Softmax-Funktion abgeleiteten Gewichte mit dem Wertevektor multipliziert werden, was zu einem Ausgangsvektor führt.
Bei diesem Verfahren bleiben nur die Wörter erhalten, die eine hohe Softmax-Bewertung aufweisen. Schließlich wird dieser Ausgangsvektor zur weiteren Verarbeitung in eine lineare Schicht eingespeist.
Bild des Autors. Der Arbeitsablauf des Encoders. Kombiniere die Softmax-Ergebnisse mit dem Wertevektor.
Und endlich bekommen wir den Output des Attention-Mechanismus!
Du fragst dich vielleicht, warum es "Multi-Head Attention" genannt wird?
Erinnere dich daran, dass wir unsere Abfragen, Schlüssel und Werte h-mal brechen, bevor der ganze Prozess beginnt. Dieser Prozess, der als Selbstaufmerksamkeit bekannt ist, findet in jeder dieser kleineren Stufen oder "Köpfe" separat statt. Jeder Kopf arbeitet unabhängig und zaubert einen Ausgangsvektor.
Dieses Ensemble durchläuft eine letzte lineare Schicht, die wie ein Filter wirkt und die gemeinsame Leistung verfeinert. Das Schöne daran ist, dass jeder Kopf auf unterschiedliche Weise lernt und so das Gebermodell mit einem robusten und vielseitigen Verständnis bereichert.
Auf jede Unterschicht in einer Encoderschicht folgt ein Normalisierungsschritt. Außerdem wird die Ausgabe jeder Teilschicht zu ihrer Eingabe hinzugefügt (Restverbindung), um das Problem des verschwindenden Gradienten zu entschärfen und tiefere Modelle zu ermöglichen. Dieser Prozess wird auch nach dem Feed-Forward Neural Network wiederholt.
Bild des Autors. Der Arbeitsablauf des Encoders. Normalisierung und Restverbindung nach Multi-Head Attention.
Die Reise des normalisierten Restoutputs geht weiter, indem er durch ein punktuelles Feedforward-Netzwerk navigiert, eine entscheidende Phase für die weitere Verfeinerung.
Stell dir dieses Netzwerk als ein Duo von linearen Schichten vor, zwischen denen eine ReLU-Aktivierung als Brücke fungiert. Nach der Verarbeitung nimmt die Ausgabe den bekannten Weg: Sie läuft in einer Schleife zurück und verschmilzt mit der Eingabe des punktuellen Feedforward-Netzwerks.
Auf dieses Wiedersehen folgt eine weitere Runde der Normalisierung, um sicherzustellen, dass alles gut eingestellt und für die nächsten Schritte synchronisiert ist.
Bild des Autors. Der Arbeitsablauf des Encoders. Feed-Forward Neural Network Teilschicht.
Die Ausgabe der letzten Kodierschicht ist eine Reihe von Vektoren, die die Eingangssequenz mit einem umfassenden Kontextverständnis darstellen. Dieser Ausgang wird dann als Eingang für den Decoder in einem Transformer-Modell verwendet.
Diese sorgfältige Kodierung ebnet den Weg für den Dekoder, damit er beim Dekodieren auf die richtigen Wörter im Input achtet.
Stell dir vor, du baust einen Turm, in dem du N Geberschichten aufstapeln kannst. Jede Schicht in diesem Stapel bekommt die Chance, verschiedene Facetten der Aufmerksamkeit zu erforschen und zu lernen, ähnlich wie Schichten von Wissen. Das erweitert nicht nur das Verständnis, sondern könnte auch die Vorhersagefähigkeiten des Umspannwerks erheblich verbessern.
Die Aufgabe des Decoders besteht darin, Textfolgen zu erstellen. Genau wie der Encoder ist auch der Decoder mit einer ähnlichen Anzahl von Unterschichten ausgestattet. Es verfügt über zwei mehrköpfige Aufmerksamkeitsschichten, eine punktuelle Feedforward-Schicht und beinhaltet sowohl Restverbindungen als auch eine Schichtnormalisierung nach jeder Teilschicht.
Bild des Autors. Globale Struktur von Encodern.
Diese Komponenten funktionieren ähnlich wie die Schichten des Encoders, allerdings mit einem Unterschied: Jede mehrköpfige Aufmerksamkeitsschicht im Decoder hat ihre eigene Aufgabe.
Der letzte Schritt des Decoders besteht aus einer linearen Schicht, die als Klassifikator dient und mit einer Softmax-Funktion ausgestattet ist, um die Wahrscheinlichkeiten der verschiedenen Wörter zu berechnen.
Der Transformer-Decoder ist so aufgebaut, dass er diese Ausgabe erzeugt, indem er die kodierten Informationen Schritt für Schritt dekodiert.
Es ist wichtig zu wissen, dass der Decoder autoregressiv arbeitet und seinen Prozess mit einem Start-Token beginnt. Es verwendet eine Liste von zuvor erzeugten Ausgaben als Eingaben, zusammen mit den Ausgaben des Encoders, die reich an Aufmerksamkeitsinformationen der ursprünglichen Eingabe sind.
Dieser sequentielle Tanz der Dekodierung wird fortgesetzt, bis der Dekoder einen entscheidenden Moment erreicht: die Erzeugung eines Tokens, das das Ende der Erstellung seiner Ausgabe signalisiert.
An der Startlinie des Decoders spiegelt der Prozess den des Encoders wider. Hier durchläuft der Input zunächst eine Einbettungsschicht
Nach der Einbettung durchläuft die Eingabe, genau wie der Decoder, die Schicht der Positionskodierung. Diese Sequenz ist so konzipiert, dass sie Positionseinbettungen erzeugt.
Diese Positionseinbettungen werden dann in die erste Multi-Head-Attention-Schicht des Decoders geleitet, wo die für die Eingabe des Decoders spezifischen Attention Scores sorgfältig berechnet werden.
Der Decoder besteht aus einem Stapel identischer Schichten (6 im ursprünglichen Transformer-Modell). Jede Schicht besteht aus drei Hauptunterkomponenten:
Dies ähnelt dem Selbstbeobachtungsmechanismus des Encoders, allerdings mit einem entscheidenden Unterschied: Er verhindert, dass die Positionen auf die nachfolgenden Positionen achten, was bedeutet, dass jedes Wort in der Sequenz nicht von zukünftigen Token beeinflusst wird.
Wenn zum Beispiel die Aufmerksamkeitswerte für das Wort "sind" berechnet werden, ist es wichtig, dass "sind" keinen Blick auf "du" wirft, das ein weiteres Wort in der Sequenz ist.
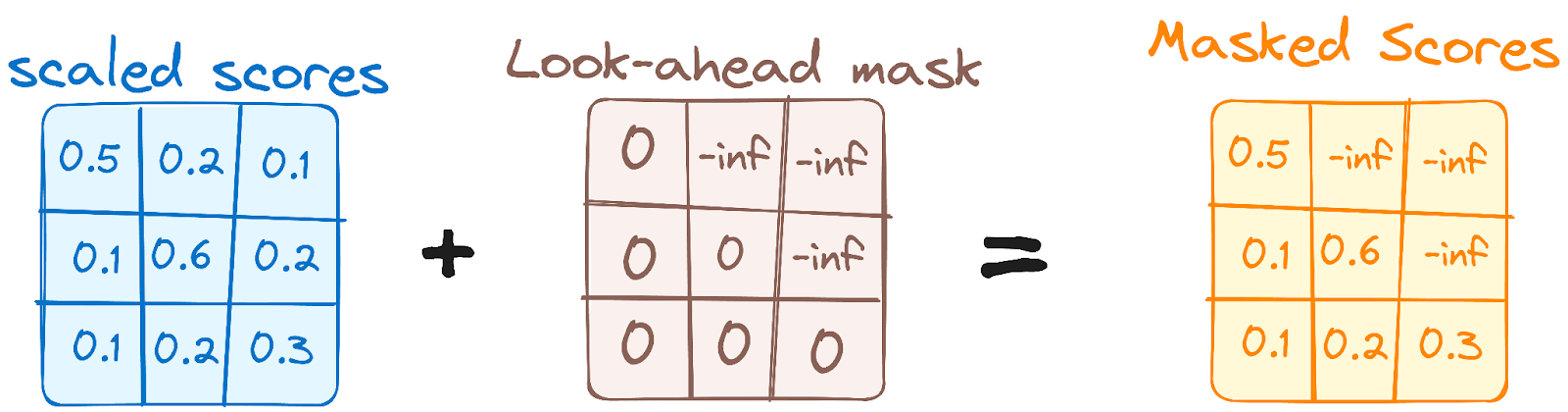
Bild des Autors. Der Arbeitsablauf des Decoders. Die erste mehrköpfige Aufmerksamkeitsmaske.
Diese Maskierung stellt sicher, dass die Vorhersagen für eine bestimmte Position nur von den bekannten Ergebnissen an den Positionen davor abhängen können.
In der zweiten mehrköpfigen Aufmerksamkeitsschicht des Decoders sehen wir ein einzigartiges Zusammenspiel zwischen den Komponenten des Encoders und des Decoders. Hier übernehmen die Ausgaben des Encoders die Rolle von Abfragen und Schlüsseln, während die Ausgaben der ersten mehrköpfigen Aufmerksamkeitsschicht des Decoders als Werte dienen.
Auf diese Weise wird die Eingabe des Encoders mit der des Decoders abgeglichen und der Decoder kann die wichtigsten Teile der Eingabe des Encoders erkennen und hervorheben.
Anschließend wird der Output dieser zweiten Schicht der mehrköpfigen Aufmerksamkeit durch eine punktuelle Feedforward-Schicht verfeinert, wodurch die Verarbeitung weiter verbessert wird.
Bild des Autors. Der Arbeitsablauf des Decoders. Encoder-Decoder Achtung.
In dieser Teilschicht kommen die Abfragen von der vorherigen Decoderschicht und die Schlüssel und Werte von der Ausgabe des Encoders. So kann jede Position im Decoder alle Positionen in der Eingangssequenz besuchen und die Informationen des Encoders mit den Informationen des Decoders kombinieren.
Ähnlich wie beim Encoder enthält jede Decoderschicht ein vollständig verbundenes Feedforward-Netzwerk, das auf jede Position separat und identisch angewendet wird.
Die Reise der Daten durch das Transformatormodell gipfelt in ihrer Passage durch eine letzte lineare Schicht, die als Klassifikator fungiert.
Die Größe dieses Klassifikators entspricht der Gesamtzahl der beteiligten Klassen (Anzahl der im Vokabular enthaltenen Wörter). In einem Szenario mit 1000 verschiedenen Klassen, die 1000 verschiedene Wörter repräsentieren, ist die Ausgabe des Klassifikators beispielsweise ein Array mit 1000 Elementen.
Dieser Output wird dann einer Softmax-Schicht zugeführt, die ihn in eine Reihe von Wahrscheinlichkeitswerten umwandelt, die jeweils zwischen 0 und 1 liegen. Der höchste dieser Wahrscheinlichkeitswerte ist der Schlüssel, sein entsprechender Index zeigt direkt auf das Wort, das das Modell als nächstes in der Reihenfolge vorhersagt.
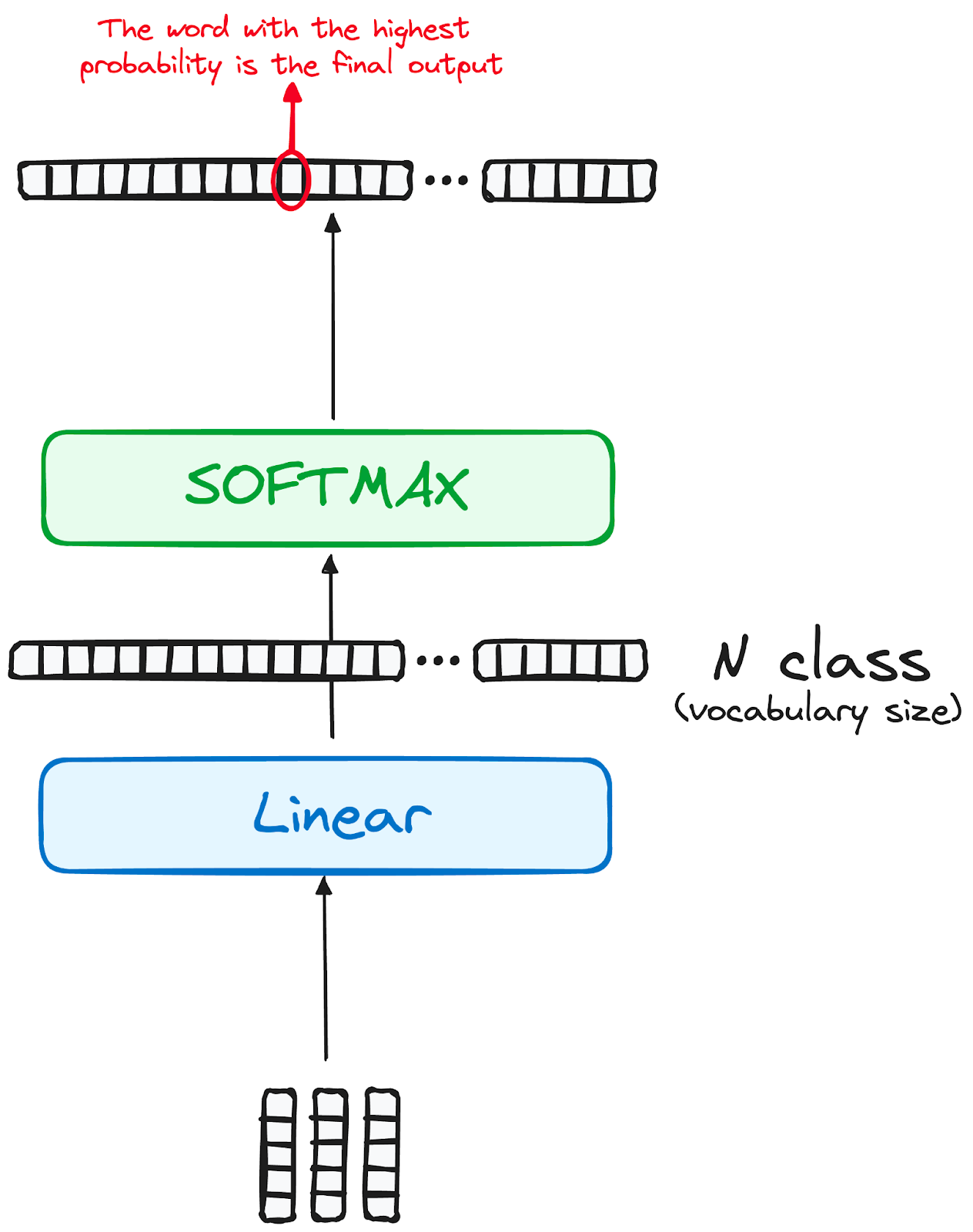
Bild des Autors. Der Arbeitsablauf des Decoders. Der endgültige Ausgang des Transformators.
Auf jede Teilschicht (maskierte Selbstaufmerksamkeit, Encoder-Decoder-Aufmerksamkeit, Feed-Forward-Netz) folgt ein Normalisierungsschritt, und jede beinhaltet auch eine Restverbindung um sie herum.
Die Ausgabe der letzten Schicht wird in eine vorhergesagte Sequenz umgewandelt, normalerweise durch eine lineare Schicht, gefolgt von einer Softmax, um Wahrscheinlichkeiten über das Vokabular zu generieren.
Der Decoder nimmt in seinem Arbeitsablauf die frisch erzeugte Ausgabe in seine wachsende Liste von Eingängen auf und fährt dann mit dem Dekodierungsprozess fort. Dieser Zyklus wiederholt sich, bis das Modell ein bestimmtes Token vorhersagt, das die Fertigstellung signalisiert.
Das Token, das mit der höchsten Wahrscheinlichkeit vorhergesagt wird, wird als abschließende Klasse zugewiesen, die oft durch das End-Token repräsentiert wird.
Bedenke auch hier, dass der Decoder nicht auf eine einzige Ebene beschränkt ist. Es kann aus N Schichten bestehen, die jeweils auf den vom Encoder und den vorhergehenden Schichten erhaltenen Input aufbauen. Dank dieses mehrschichtigen Aufbaus kann das Modell seinen Fokus diversifizieren und unterschiedliche Aufmerksamkeitsmuster in den einzelnen Köpfen extrahieren.
Ein solcher mehrschichtiger Ansatz kann die Vorhersagefähigkeit des Modells erheblich verbessern, da es ein differenzierteres Verständnis für verschiedene Aufmerksamkeitskombinationen entwickelt.
Und die endgültige Architektur sieht in etwa so aus (aus dem Originalbeitrag)
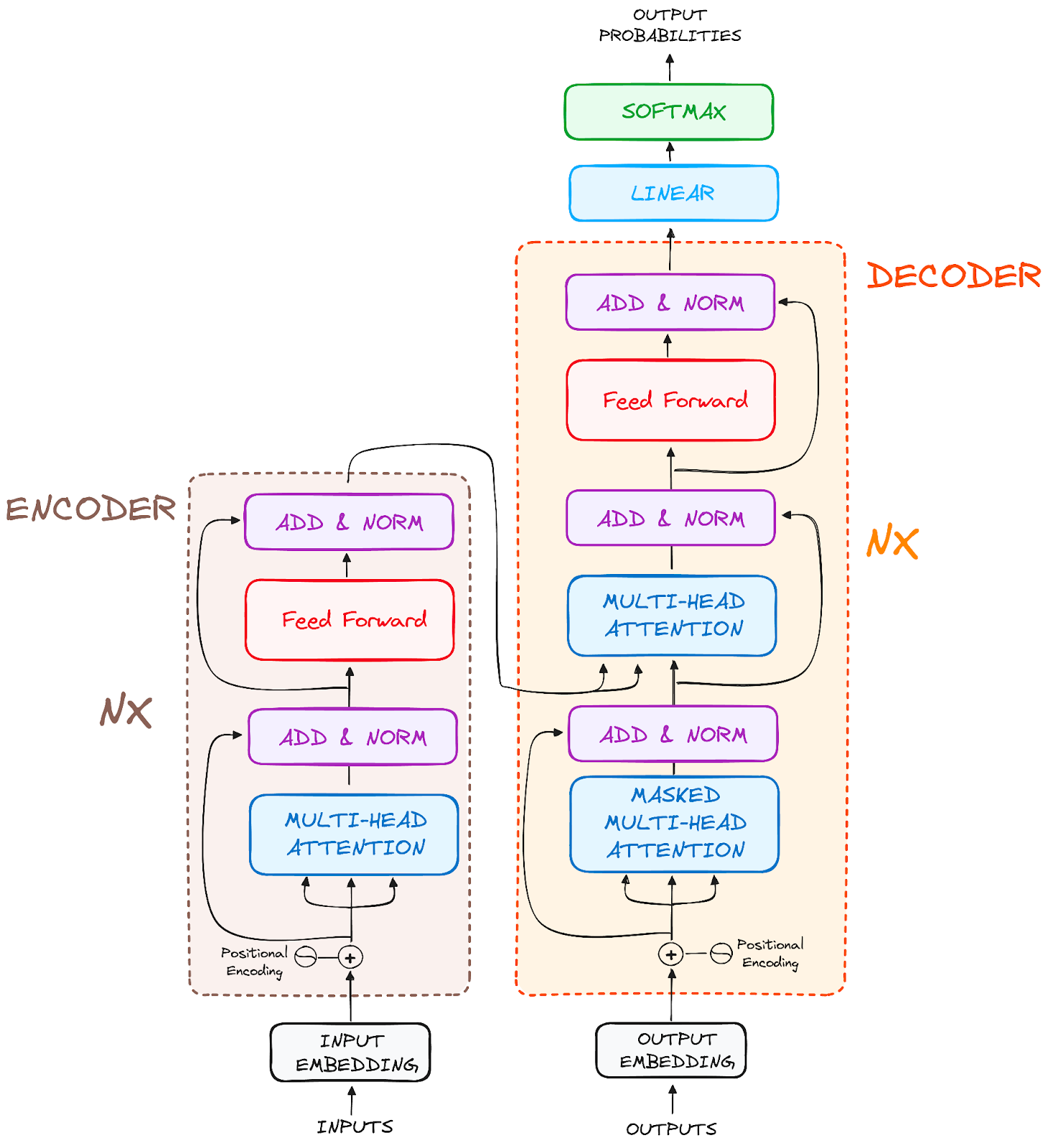
Bild des Autors. Die ursprüngliche Struktur von Transformers.
Um diese Architektur besser zu verstehen, empfehle ich dir, einen Transformer von Grund auf neu zu erstellen, indem du dieses Tutorial befolgst.
Die 2018 von Google veröffentlichte Version von BERT, einem Open-Source-Framework für die Verarbeitung natürlicher Sprache, revolutionierte NLP mit seinem einzigartigen bidirektionalen Training, das es dem Modell ermöglicht, kontextbezogene Vorhersagen darüber zu treffen, wie das nächste Wort lauten sollte.
Durch das Verstehen des Kontextes von allen Seiten eines Wortes übertraf BERT frühere Modelle bei Aufgaben wie dem Beantworten von Fragen und dem Verstehen mehrdeutiger Sprache. Sein Kern verwendet Transformatoren, die jedes Ausgangs- und Eingangselement dynamisch verbinden.
BERT, das zuvor auf Wikipedia trainiert wurde, schnitt bei verschiedenen NLP-Aufgaben hervorragend ab, was Google dazu veranlasste, es für natürlichere Suchanfragen in seine Suchmaschine zu integrieren. Diese Innovation löste einen Wettlauf um die Entwicklung fortschrittlicher Sprachmodelle aus und hat die Fähigkeit des Fachs, komplexe Sprache zu verstehen, erheblich verbessert.
Mehr über BERT erfährst du in unserem separaten Artikel, in dem das BERT-Modell vorgestellt wird.
LaMDA (Language Model for Dialogue Applications) ist ein von Google entwickeltes Transformer-basiertes Modell, das speziell für Konversationsaufgaben konzipiert ist und auf der Google I/O Keynote 2021 vorgestellt wurde. Sie wurden entwickelt, um natürlichere und kontextbezogene Antworten zu generieren und so die Benutzerinteraktion in verschiedenen Anwendungen zu verbessern.
Das Design von LaMDA ermöglicht es, eine Vielzahl von Themen und Nutzerintentionen zu verstehen und darauf zu reagieren. Das macht es ideal für Anwendungen in Chatbots, virtuellen Assistenten und anderen interaktiven KI-Systemen, bei denen eine dynamische Konversation entscheidend ist.
Dieser Fokus auf das Verstehen und Beantworten von Gesprächen macht LaMDA zu einem bedeutenden Fortschritt auf dem Gebiet der natürlichen Sprachverarbeitung und der KI-gesteuerten Kommunikation.
Wenn du daran interessiert bist, die LaMDA-Modelle besser zu verstehen, kannst du dir den Artikel über LaMDA ansehen.
GPT und ChatGPT, entwickelt von OpenAI, sind fortschrittliche generative Modelle, die für ihre Fähigkeit bekannt sind, kohärente und kontextbezogene Texte zu produzieren. GPT-1 war das erste Modell, das im Juni 2018 eingeführt wurde, und GPT-3, eines der wirkungsvollsten Modelle, wurde zwei Jahre später im Jahr 2020 eingeführt.
Diese Modelle sind für eine Vielzahl von Aufgaben geeignet, z. B. für die Erstellung von Inhalten, Konversation, Sprachübersetzung und vieles mehr. Die Architektur von GPT ermöglicht es, Texte zu generieren, die der menschlichen Schrift sehr ähnlich sind. Das macht es nützlich für Anwendungen wie kreatives Schreiben, Kundensupport und sogar Hilfe bei der Programmierung. ChatGPT, eine für Konversationskontexte optimierte Variante, zeichnet sich durch die Erzeugung von menschenähnlichen Dialogen aus, was seine Anwendung in Chatbots und virtuellen Assistenten verbessert.
Die Landschaft der Gründungsmodelle, insbesondere der Transformatormodelle, erweitert sich rasant. In einer Studie wurden mehr als 50 bedeutende Transformatorenmodelle identifiziert, während die Stanford-Gruppe 30 von ihnen bewertete und damit dem rasanten Wachstum des Bereichs Rechnung trug. NLP Cloud, ein innovatives Startup im Rahmen von NVIDIAs Inception-Programm, setzt rund 25 große Sprachmodelle kommerziell für verschiedene Branchen wie Fluggesellschaften und Apotheken ein.
Es gibt einen zunehmenden Trend, diese Modelle als Open Source zu veröffentlichen, wobei Plattformen wie der Model Hub von Hugging Face eine Vorreiterrolle spielen. Darüber hinaus wurden zahlreiche Transformer-basierte Modelle entwickelt, die jeweils auf unterschiedliche NLP-Aufgaben spezialisiert sind und die Vielseitigkeit und Effizienz des Modells in verschiedenen Anwendungen unter Beweis stellen.
In einem separaten Artikel erfährst du mehr über alle existierenden Foundation-Modelle, was sie sind und welche am häufigsten verwendet werden.
Das Benchmarking und die Bewertung der Leistung von Transformer-Modellen im NLP beinhaltet einen systematischen Ansatz zur Beurteilung ihrer Effektivität und Effizienz.
Je nach Art der Aufgabe gibt es verschiedene Möglichkeiten und Ressourcen, dies zu tun:
Bei maschinellen Übersetzungsaufgaben kannst du auf Standarddatensätze wie den WMT (Workshop on Machine Translation) zurückgreifen, bei dem MÜ-Systeme mit einer Vielzahl von Sprachpaaren konfrontiert werden, von denen jedes seine eigenen Herausforderungen bietet.
Metriken wie BLEU, METEOR, TER und chrF dienen als Navigationsinstrumente, die uns zu Genauigkeit und Geläufigkeit führen.
Darüber hinaus gewährleisten Tests in verschiedenen Bereichen wie Nachrichten, Literatur und technischen Texten die Anpassungsfähigkeit und Vielseitigkeit eines MÜ-Systems und machen es zu einem echten Polyglotten in der digitalen Welt.
Um QA-Modelle zu bewerten, verwenden wir spezielle Sammlungen von Fragen und Antworten, wie SQuAD (Stanford Question Answering Dataset), Natural Questions oder TriviaQA.
Jedes ist wie ein anderes Spiel mit seinen eigenen Regeln. Bei SQuAD geht es zum Beispiel darum, Antworten in einem vorgegebenen Text zu finden, während andere eher wie ein Quizspiel mit Fragen von überall her sind.
Um zu sehen, wie gut diese Programme abschneiden, verwenden wir Werte wie Precision, Recall, F1 und manchmal sogar exakte Übereinstimmungswerte.
Wenn wir uns mit Natural Language Inference (NLI) beschäftigen, verwenden wir spezielle Datensätze wie SNLI (Stanford Natural Language Inference), MultiNLI und ANLI.
Diese sind wie große Bibliotheken mit Sprachvariationen und kniffligen Fällen, die uns helfen zu sehen, wie gut unsere Computer verschiedene Arten von Sätzen verstehen. Wir prüfen vor allem, wie genau die Computer verstehen, ob Aussagen übereinstimmen, sich widersprechen oder nicht zusammenhängen.
Es ist auch wichtig zu wissen, wie der Computer knifflige sprachliche Dinge herausfindet, z. B. wenn sich ein Wort auf etwas bezieht, das bereits erwähnt wurde, oder wie er "nicht", "alle" und "einige" versteht.
In der Welt der neuronalen Netze werden zwei prominente Strukturen meist mit Transformatoren verglichen. Jede von ihnen bietet unterschiedliche Vorteile und Herausforderungen, die auf bestimmte Arten der Datenverarbeitung zugeschnitten sind. RNNs, die in diesem Artikel bereits mehrfach erwähnt wurden, und Convulational Layers.
Rekurrente Schichten, ein Eckpfeiler der rekurrenten neuronalen Netze (RNNs), eignen sich hervorragend für die Verarbeitung sequentieller Daten. Die Stärke dieser Architektur liegt in ihrer Fähigkeit, sequenzielle Operationen durchzuführen, die für Aufgaben wie Sprachverarbeitung oder Zeitreihenanalyse entscheidend sind. In einer rekurrenten Schicht wird die Ausgabe eines vorherigen Schritts als Eingabe für den nächsten Schritt in das Netz zurückgeführt. Dieser Schleifenmechanismus ermöglicht es dem Netzwerk, sich an frühere Informationen zu erinnern, was wichtig ist, um den Kontext in einer Sequenz zu verstehen.
Wie wir bereits erörtert haben, hat diese sequentielle Verarbeitung jedoch zwei wesentliche Auswirkungen:
Transformatormodelle unterscheiden sich deutlich von Architekturen, die rekurrente Schichten verwenden, da ihnen die Rekursivität fehlt. Wie wir bereits gesehen haben, bewertet die Aufmerksamkeitsschicht des Transformers beide Probleme, was sie zur natürlichen Weiterentwicklung von RNNs für NLP-Anwendungen macht.
Convolutional Layers, die Bausteine der Convolutional Neural Networks (CNNs), sind dagegen für ihre Effizienz bei der Verarbeitung räumlicher Daten wie Bildern bekannt.
Diese Schichten verwenden Kernel (Filter), die die Eingabedaten durchsuchen, um Merkmale zu extrahieren. Die Breite dieser Kerne kann angepasst werden, so dass sich das Netz je nach Aufgabe auf kleine oder große Merkmale konzentrieren kann.
Convolutional Layers sind zwar außergewöhnlich gut darin, räumliche Hierarchien und Muster in Daten zu erfassen, aber bei langfristigen Abhängigkeiten haben sie Probleme. Sie berücksichtigen keine sequentiellen Informationen und sind daher weniger geeignet für Aufgaben, bei denen es darauf ankommt, die Reihenfolge oder den Kontext einer Sequenz zu verstehen.
Aus diesem Grund sind CNNs und Transformers auf unterschiedliche Datentypen und Aufgaben zugeschnitten. CNNs dominieren im Bereich des Computersehens aufgrund ihrer Effizienz bei der Verarbeitung räumlicher Informationen, während Transformers aufgrund ihrer Fähigkeit, weitreichende Abhängigkeiten zu verstehen, die erste Wahl für komplexe sequenzielle Aufgaben sind, insbesondere im Bereich NLP.
Zusammenfassend lässt sich sagen, dass Transformers einen monumentalen Durchbruch auf dem Gebiet der künstlichen Intelligenz (NLP) darstellen.
Indem sie sequenzielle Daten durch ihren einzigartigen Mechanismus der Selbstaufmerksamkeit effektiv verwalten, haben diese Modelle die traditionellen RNNs übertroffen. Ihre Fähigkeit, lange Sequenzen effizienter zu verarbeiten und die Datenverarbeitung zu parallelisieren, beschleunigt das Training erheblich.
Pioniermodelle wie der BERT von Google und die GPT-Serie von OpenAI sind Beispiele für die transformative Wirkung von Transformers bei der Verbesserung von Suchmaschinen und der Generierung von menschenähnlichen Texten.
Dadurch sind sie für das moderne maschinelle Lernen unentbehrlich geworden. Sie treiben die Grenzen der KI voran und eröffnen neue Wege des technologischen Fortschritts.
Wenn du dich in Transformers und ihre Verwendung vertiefen willst, ist unser Artikel über Transformers und das umarmende Gesicht ein perfekter Anfang! In unserer ausführlichen Anleitung erfährst du, wie du einen Transformer mit PyTorch bauen kannst.
Erfahre mehr über Transformatoren und LLMs!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna

