
Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
Wan2.1 de Qwen est un modèle de génération vidéo open-source conçu pour être à la fois puissant et accessible, puisqu'il peut fonctionner sur des GPU grand public.
Grâce à ses excellentes performances, Wan2.1 rivalise avec des modèles open-source tels que HunyuanVideo et SkyReels, ainsi qu'avec des solutions commerciales telles que Sora et Runway.
Dans cet article, je vais vous expliquer ce qu'est Wan2.1, ses principales caractéristiques et son fonctionnement. De plus, je vous expliquerai comment y accéder et l'utiliser pour générer des vidéos à partir de diverses invites, en mettant en évidence ses capacités en action.
Wan 2.1 est un modèle de génération vidéo avancé développé par Qwen. Il appartient à une famille de modèles de fondation vidéo à grande échelle, ce qui signifie qu'il peut créer des vidéos de haute qualité à partir de différents types d'entrées, en l'occurrence des descriptions textuelles et des images.
Wan 2.1 associe la génération de vidéos puissantes à l'accessibilité. Il peut fonctionner sur des GPU grand public, contrairement à de nombreux autres modèles vidéo d'IA qui nécessitent un matériel coûteux, ce qui le rend plus pratique. De plus, il s'agit d'un logiciel libre.
Il repose sur la technologie du transformateur de diffusion, une approche qui lui permet de générer des vidéos fluides et réalistes avec une qualité de mouvement impressionnante. Wan 2.1 introduit également un autoencodeur variationnel vidéo (VAE) unique en son genre, qui permet de préserver la cohérence et les détails des vidéos, même à des résolutions plus élevées telles que 1080p.
Voici ses principales caractéristiques :
Wan 2.1 surpasse les modèles vidéo IA commerciaux et open-source sur de nombreux critères de référence, ce qui signifie qu'il produit des vidéos plus réalistes et de meilleure qualité que de nombreuses autres solutions.
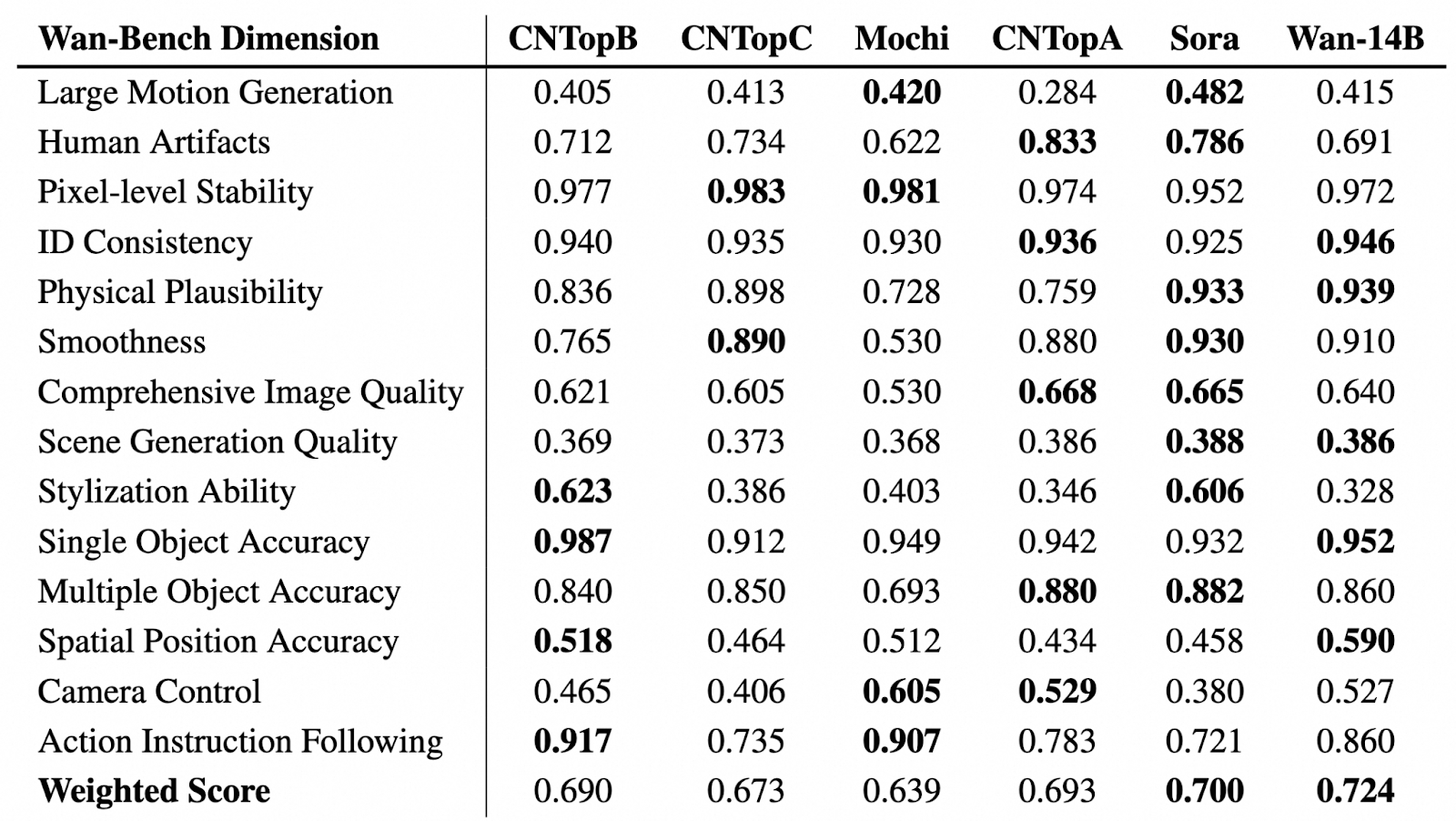
Source : GitHub (Wan-Video/Wan2.1)
Dans le tableau ci-dessus, nous pouvons voir une évaluation comparative des modèles de génération vidéo à travers différentes dimensions de Wan-Bench, évaluant leurs performances dans des aspects clés tels que la génération de mouvement, la stabilité visuelle, la précision des objets et le suivi des instructions. Le modèle le plus performant dans chaque catégorie est mis en évidence en gras.
Wan-14B obtient la note globale pondérée la plus élevée (0,724), ce qui témoigne de ses solides capacités au regard de plusieurs critères de référence.
Comparé à la plupart des modèles vidéo d'IA haut de gamme qui nécessitent un matériel coûteux, le modèle T2V-1.3B de Wan 2.1 n'a besoin que de 8,19 Go de VRAM. Cela signifie que vous pouvez générer des vidéos à l'aide d'un GPU ordinaire, comme une RTX 4090, en quelques minutes seulement, sans avoir besoin d'un supercalculateur.
Avec Wan, vous pouvez faire plus que du Text-to-Video (T2V). Il offre des fonctions avancées pour améliorer la génération et la personnalisation des vidéos, notamment :
En outre, Wan prend en charge la conversion d'images en vidéos (I2V), ce qui vous permet de transformer des images fixes en vidéos animées. Vous pouvez ajouter des invites de texte facultatives pour mieux contrôler la génération de la vidéo et définir la première et la dernière image pour façonner la composition et le flux de la vidéo.
Wan 2.1 est le premier modèle vidéo d'IA capable de générer un texte lisible à l'intérieur des vidéos en anglais et en chinois. Cette fonction est idéale pour créer des sous-titres, du texte animé et des superpositions graphiques dans un contenu vidéo.
Wan 2.1 utilise un encodeur vidéo variationnel avancé (Wan-VAE) qui lui permet de.. :
Il y a plusieurs façons de commencer : vous pouvez l'essayer en ligne ou l'exécuter localement sur votre ordinateur.
Si vous souhaitez expérimenter Wan 2.1 sans rien installer, vous pouvez y accéder via :
1. Espace Hugging Face: Vous pouvez exécuter le modèle directement dans une interface web.
2. Site web WanVideo: Ici, vous pouvez faire plus que générer des vidéos. Le site officiel vous permet également de créer des images et d'explorer une collection de vidéos et d'images générées par d'autres utilisateurs, ainsi que les invites qu'ils ont utilisées.
Ces options vous permettent de tester rapidement le modèle sans vous soucier de la configuration ou du matériel.
Si vous souhaitez un contrôle total et une personnalisation, vous pouvez installer Wan 2.1 sur votre propre machine. Voyons étape par étape comment procéder :
Tout d'abord, téléchargez le code de Wan 2.1 sur GitHub :
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1Assurez-vous que Python et PyTorch (version 2.4.0 ou ultérieure) sont installés, puis installez les bibliothèques requises :
pip install -r requirements.txtVous devez télécharger les fichiers de modèles pré-entraînés à partir de Hugging Face (voir plus d'informations ici) ou ModelScope (voir plus d'informations ici).Il existe différents modèles que vous pouvez télécharger :
|
Modèles |
Télécharger le lien |
Notes |
|
T2V-14B |
Prend en charge les formats 480P et 720P |
|
|
I2V-14B-720P |
Prise en charge de 720P |
|
|
I2V-14B-480P |
Prise en charge de 480P |
|
|
T2V-1.3B |
Prise en charge de 480P |
Le modèle 1.3B peut générer des vidéos en résolution 720P, mais comme il a été moins entraîné à cette qualité, les résultats peuvent être moins stables qu'en 480P. Pour de meilleures performances, la résolution 480P est recommandée.
Wan 2.1 vous permet de générer des vidéos à partir de descriptions textuelles en utilisant deux versions de modèles :
Si vous souhaitez simplement générer une vidéo rapidement, vous pouvez utiliser les commandes suivantes, pour lesquelles l'amélioration de l'invite n'est pas activée.
Pour le modèle Modèle T2V-14B (meilleure qualité, modèle plus grand) :
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights."Pour le modèle modèle T2V-1.3B (plus petit, fonctionne avec des GPU bas de gamme) :
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "A futuristic city with flying cars and neon lights."Si votre ordinateur manque de mémoire (erreur OOM), vous pouvez utiliser --offload_model True et --t5_cpu pour réduire l'utilisation de la mémoire.
Si vous disposez de plusieurs GPU, vous pouvez accélérer la génération de vidéos en exécutant cette commande :
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "A futuristic city with flying cars and neon lights.`Cela permet de répartir la charge de travail sur plusieurs GPU, ce qui accélère le processus.
Wan 2.1 peut améliorer automatiquement votre message d'accueil, ce qui vous permet de rendre la vidéo plus détaillée et plus attrayante sur le plan visuel.
Il y a deux façons de prolonger l'invite :
Pour utiliser l'API Dashscope :
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'dashscope'Pour utiliser votre propre modèle local :
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'local_qwen'Si vous souhaitez utiliser la bibliothèque de diffuseurs de Hugging Face au lieu d'exécuter des scripts bruts, vous pouvez générer une vidéo avec Python :
import torch
from diffusers.utils import export_to_video
from diffusers import AutoencoderKLWan, WanPipeline
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
# Available models: Wan-AI/Wan2.1-T2V-14B-Diffusers, Wan-AI/Wan2.1-T2V-1.3B-Diffusers
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
# Load the autoencoder for video generation
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
# Define the scheduler for controlling video motion flow
flow_shift = 5.0 # 5.0 for 720P, 3.0 for 480P
scheduler = UniPCMultistepScheduler(
prediction_type='flow_prediction',
use_flow_sigmas=True,
num_train_timesteps=1000,
flow_shift=flow_shift
)
# Load the video generation pipeline with the model
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
pipe.scheduler = scheduler
pipe.to("cuda")
# New prompt
prompt = "A futuristic city at sunset, filled with flying cars and neon lights. The buildings have a sleek, cyberpunk design, and people walk on glowing sidewalks. The scene is full of vibrant colors, reflections, and dynamic movement."
# New negative prompt
negative_prompt = "Dull colors, grainy texture, washed-out details, static frames, incorrect lighting, unnatural shadows, distorted faces, artifacts, low-resolution elements, flickering, blurry motion, repetitive patterns, unrealistic reflections, overly simplistic backgrounds, three legged people, walking backwards."
# Generate the video frames
output = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=720,
width=1280,
num_frames=81,
guidance_scale=5.0,
).frames[0]
# Export the generated frames as a video
export_to_video(output, "output.mp4", fps=16)Le script commence par charger le modèle Wan2.1-T2V-14B-Diffusers, qui est utilisé pour créer des vidéos. Il charge également un VAE (Autoencoder), qui permet de traiter et d'améliorer les images vidéo. Pour contrôler la fluidité des mouvements dans la vidéo, le script utilise un planificateur (UniPCMultistepScheduler). Le paramètre flow_shift permet de régler la façon dont les mouvements sont traités, 5.0 étant préférable pour une résolution plus élevée (720P) et 3.0 pour une résolution plus faible (480P).
Ensuite, le script met en place le pipeline de génération vidéo (WanPipeline) et applique le planificateur pour assurer des transitions plus fluides entre les images. L'invite décrit une ville futuriste avec des voitures volantes et des néons lumineux, tandis que l'invite négative permet d'éliminer les effets indésirables, tels que les détails flous, les couleurs délavées et les images vacillantes.
Le modèle crée ensuite 81 images, ce qui donne environ 5 secondes de vidéo à 16 images par seconde (FPS). Le site guidance_scale est réglé sur 5.0, ce qui permet au modèle de suivre le message tout en laissant une certaine place à la créativité. Une fois la vidéo générée, les images sont combinées et enregistrées sous "output.mp4" à 16 FPS.
Le message négatif joue un rôle important dans l'amélioration de la vidéo finale en indiquant au modèle ce qu'il doit éviter. Il permet de se débarrasser d'éléments tels qu'une mauvaise qualité d'image, des distorsions étranges ou tout ce qui pourrait donner à la vidéo un aspect irréaliste. Dans ce cas, il garantit que la scène futuriste est propre, nette et visuellement attrayante.
Si vous préférez une interface web interactive pour générer des vidéos plutôt que d'utiliser du code, vous pouvez exécuter Wan 2.1 avec Gradio :
Pour l'extension de l'invite Dashscope :
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14BPour l'extension de l'invite locale :
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14BComme pour la conversion texte-vidéo, la conversion image-vidéo est également divisée en processus avec et sans l'étape d'extension de l'invite. Pour plus de détails sur l'implémentation, vous pouvez visiter le site officiel GitHub. Vous pouvez également rejoindre leur canal Discord pour discuter de Wan2.1, partager vos créations, obtenir des mises à jour sur les nouvelles fonctionnalités et les développements, et visiter le site officiel pour découvrir les exemples générés.
Wan 2.1 utilise des techniques d'intelligence artificielle avancées pour générer des vidéos réalistes de haute qualité. Il suit une approche basée sur la diffusion et intègre transformateurs pour s'assurer que les mouvements sont fluides, cohérents et détaillés d'une image à l'autre.
Wan 2.1 utilise une technique appelée modèles de diffusion, qui fonctionne en deux étapes :
C'est un peu comme le développement d'une photo dans une chambre noire : l'image est d'abord floue et granuleuse, mais elle devient plus claire à chaque étape du traitement.
Wan 2.1 améliore cette approche en utilisant un transformateur de diffusion (DiT), qui permet de conserver des détails précis et des mouvements fluides tout en générant plusieurs images vidéo.
Source : GitHub (Wan-Video/Wan2.1)
Ce diagramme montre comment Wan 2.1 génère des images vidéo à l'aide d'un modèle de diffusion amélioré par un transformateur de diffusion (DiT). Le processus commence par une description d'entrée (par exemple, "Un panda brandit un carton portant l'inscription 'Wan2.1'"). Ce texte est traité par UMT5, un modèle linguistique qui aide le système à comprendre et à affiner l'invite.
Simultanément, une image bruyante initiale est introduite comme point de départ. Le Wan-Encoder traite ensuite ces entrées, les encodant sous une forme que le modèle peut manipuler. Les blocs N x DiT affinent l'image de manière itérative.
Le modèle de diffusion élimine progressivement le bruit des images, en utilisant l'attention croisée pour aligner la sortie sur l'invite fournie. Le pas de temps (t) indique les étapes progressives du débruitage, garantissant une évolution régulière de la vidéo dans le temps.
Après plusieurs étapes d'affinage, le décodeur Wan reconstruit les images vidéo finales à partir des données traitées. La sortie est une série d'images qui s'alignent sur la description originale de l'entrée, en conservant des détails précis, des mouvements fluides et une certaine cohérence.
Wan 2.1 propose Wan-VAE, un puissant outil de compression qui aide le modèle :
C'est comme lorsque vous zippez des fichiers pour des vidéos : Il compresse et stocke les détails clés, puis les reconstitue avec précision lors de la génération de la vidéo.
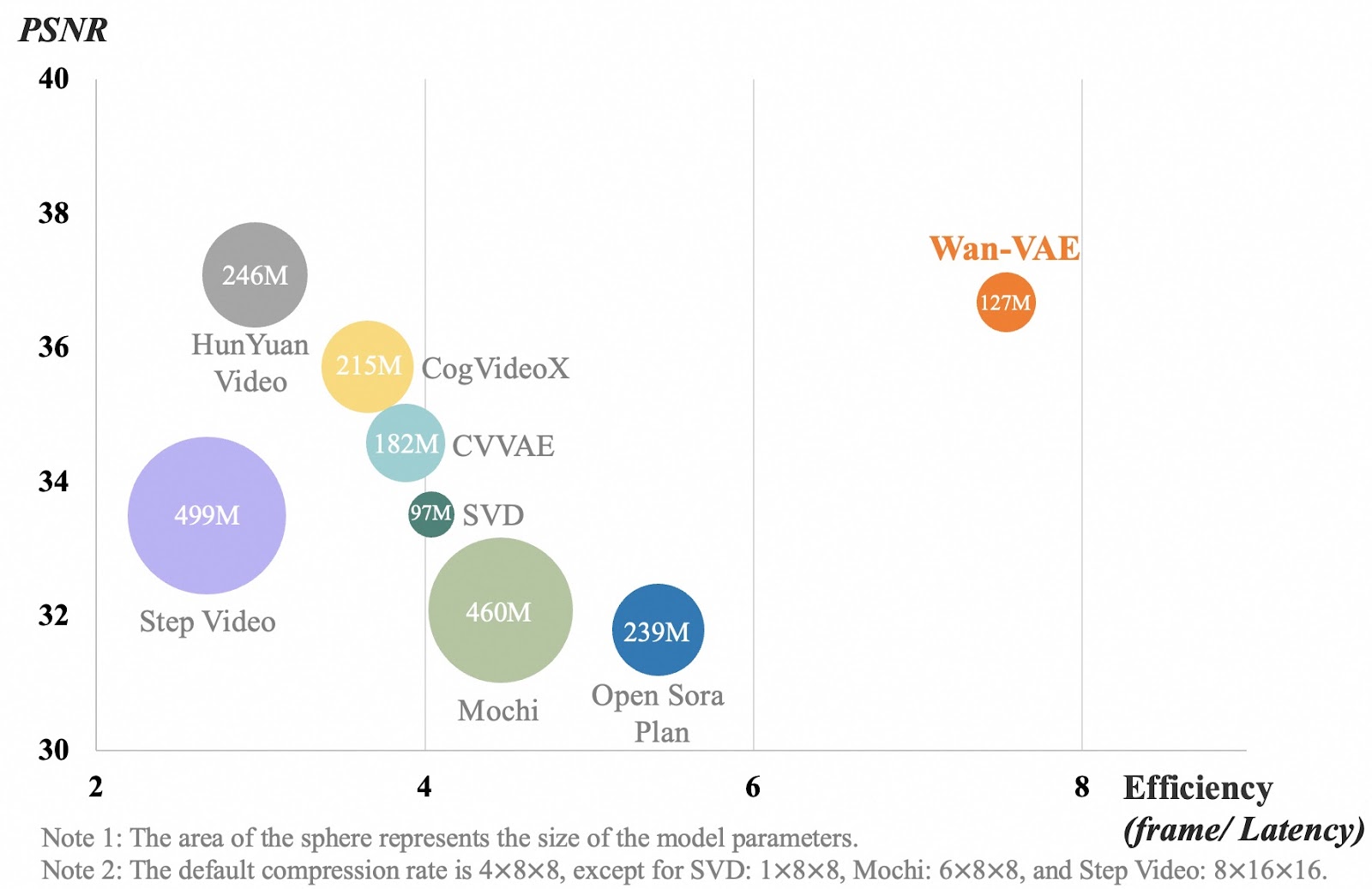
Source : GitHub (Wan-Video/Wan2.1)
Le tableau compare différents modèles de compression vidéo sur la base de la qualité vidéo (PSNR) et de l'efficacité (vitesse de traitement des images). Chaque bulle représente un modèle, et sa taille indique la taille du modèle. L'axe des abscisses mesure l'efficacité avec laquelle un modèle traite les images vidéo. Un chiffre plus élevé signifie que le modèle fonctionne plus rapidement. L'axe des ordonnées indique la qualité de la vidéo, un chiffre plus élevé signifiant des vidéos plus claires et plus détaillées.
Le modèle Wan-VAE, représenté en orange, obtient de meilleurs résultats que les autres modèles en conciliant une qualité vidéo élevée et un traitement rapide, tout en restant relativement petit (127 millions de paramètres). D'autres modèles, comme Step Video et Mochi, sont beaucoup plus grands mais ne traitent pas les images aussi efficacement. Cela signifie que Wan-VAE peut générer des vidéos longues et de haute qualité tout en conservant la netteté des détails et la fluidité des mouvements, sans ralentissement.
Wan 2.1 est un modèle polyvalent de génération de vidéos d'IA qui peut être utilisé dans de nombreux secteurs. Dans cette section, j'essaierai quelques exemples pour différents cas d'utilisation.
Wan 2.1 peut vous aider à générer un contenu vidéo unique sans équipement coûteux ni longues heures de montage. Imaginons que je sois un influenceur lifestyle et que je veuille créer du contenu autour d'une journée agréable de ma vie. Jevais utiliser l'invite suivante pour créer un clip pour ma vidéo :
Une animation time-lapse d'un café confortable du matin au soir, montrant les allées et venues des gens, la préparation du café et le coucher de soleil se reflétant sur les vitres.
Comme je voulais qu'il soit le plus réaliste possible, j'ai également utilisé le mode inspiration. Voici le résultat que j'ai obtenu :
Lorsque la vidéo a été générée, j'ai été très impressionné à première vue. Mais en y regardant de plus près, je me suis rendu compte de deux choses. Tout d'abord, quelqu'un disparaît à l'arrière-plan. En outre, il ne s'agit pas d'un time-lapse et aucun café n'est en train d'être préparé. Ainsi, même si la vidéo semble assez réaliste, elle ne reflète pas fidèlement le message.
Imaginez maintenant que vous êtes un développeur de jeux. Vous pouvez utiliser Wan 2.1 pour générer des scènes réalistes, des animations d'arrière-plan ou des illustrations conceptuelles pour vos projets. Par exemple, si vous avez déjà un concept de personnage et que l'équipe créative vous a fourni quelques dessins, vous pouvez lui donner vie grâce à la fonction de conversion d'images en vidéos de Wan.
Au-delà de l'animation de personnages, Wan 2.1 permet également de créer des environnements dynamiques, tels que des effets météorologiques changeants, des paysages urbains animés ou des paysages mystiques, sans qu'il soit nécessaire d'animer chaque image manuellement.
De plus, grâce au contrôle du rapport hauteur/largeur, vous pouvez vous assurer que vos animations s'intègrent parfaitement dans différentes scènes de jeu, telles que les cinématiques sur grand écran (16:9), les plans verticaux adaptés aux mobiles (9:16) ou les compositions carrées (1:1) pour les teasers sur les médias sociaux.
Vous pouvez même utiliser la fonction d'effets sonores pour créer une ambiance de fond, comme le bruissement des feuilles, le bourdonnement d'une ville futuriste ou l'ambiance sonore d'une bataille.
Essayons quelque chose !J'ai généré cette ébauche de chevalier médiéval avec DALL-E :

En utilisant Wan, j'ai saisi l'invite suivante en utilisant GPT-4o-mini :
Un chevalier médiéval se tient dans une position héroïque, tenant une grande épée à deux mains. Sa cape flotte au vent tandis qu'il arpente le champ de bataille. Le chevalier tourne lentement la tête, scrutant l'horizon d'un air déterminé. L'animation a un style cinématographique.Mais ensuite, j'ai cliqué sur Enhanced Prompt, et voici ce que j'ai obtenu :
Chevalier médiéval cinématographique : Un preux chevalier se tient résolument debout, vêtu d'une armure complète, tenant à deux mains une redoutable épée. Son casque à visière et ses pauldrons d'épaule brillent sous le soleil, tandis qu'un écusson noble orne son plastron. Une écharpe enserre sa taille, sécurisant ainsi son ensemble. Sa cape cramoisie se déploie de façon spectaculaire dans la brise, ajoutant à sa présence imposante. D'un regard d'acier, il pivote la tête, observant le vaste champ de bataille sablonneux. La scène se déroule sur un papier texturé semblable à du parchemin, évoquant un manuscrit ancien. Il s'agit d'un plan grandiose de tout le corps, qui capture le chevalier dans une pose triomphante, rappelant le cinéma épique médiéval.
J'ai désactivé le mode Inspiration mais j'ai activé les effets sonores. Voici le résultat :
Pas mal ! Même si je dois admettre que je m'attendais à une version plus cinématographique de l'avant-projet plutôt qu'à une animation de l'avant-projet lui-même. Mais j'aurais peut-être pu être plus clair dans l'invitation. La musique est intéressante, et je pense qu'elle s'accorde bien avec l'animation !
Si vous êtes un spécialiste du marketing, vous pouvez utiliser Wan 2.1 pour créer des vidéos promotionnelles pour des marques, des produits et des services, ou même pour animer des logos.
Imaginez que vous ayez un commerce de glaces, et que vous souhaitiez animer votre logo afin de le placer à la fin de vos publicités ou de vos vidéos promotionnelles.Pour tester cette idée, j'ai à nouveau généré cette image avec DALL-E :

Ensuite, j'ai utilisé ce message : L'ours polaire mange la glace. C'est le résultat de la génération image-vidéo :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours