
Track
AI Business Fundamentals
12 hr
Qwen’s Wan2.1 is an open-source video generation model designed to be both powerful and accessible, as it can run on consumer-grade GPUs.
With its great performance, Wan2.1 competes with open-source models like HunyuanVideo and SkyReels and commercial solutions such as Sora and Runway.
In this article, I’ll explore what Wan2.1 is, its key features and how it works. Plus, I will guide you on how to access it and use it to generate videos from various prompts, showcasing its capabilities in action.
Wan 2.1 is an advanced video generation model developed by Qwen. It belongs to a family of large-scale video foundation models, meaning it can create high-quality videos from different types of inputs, in this case, text descriptions and images.
Wan 2.1 combines powerful video generation with accessibility. It can run on consumer-grade GPUs, unlike many other AI video models that require expensive hardware, which makes it more practical. Plus, it is open source.
It is built on diffusion transformer technology, an approach that allows it to generate smooth, realistic videos with impressive motion quality. Wan 2.1 also introduces a unique Video Variational Autoencoder (VAE), which helps maintain video consistency and detail, even at higher resolutions like 1080p.
Here are its key features:
Wan 2.1 outperforms both open-source and commercial AI video models on multiple benchmarks, meaning it produces more realistic, high-quality videos than many alternatives.
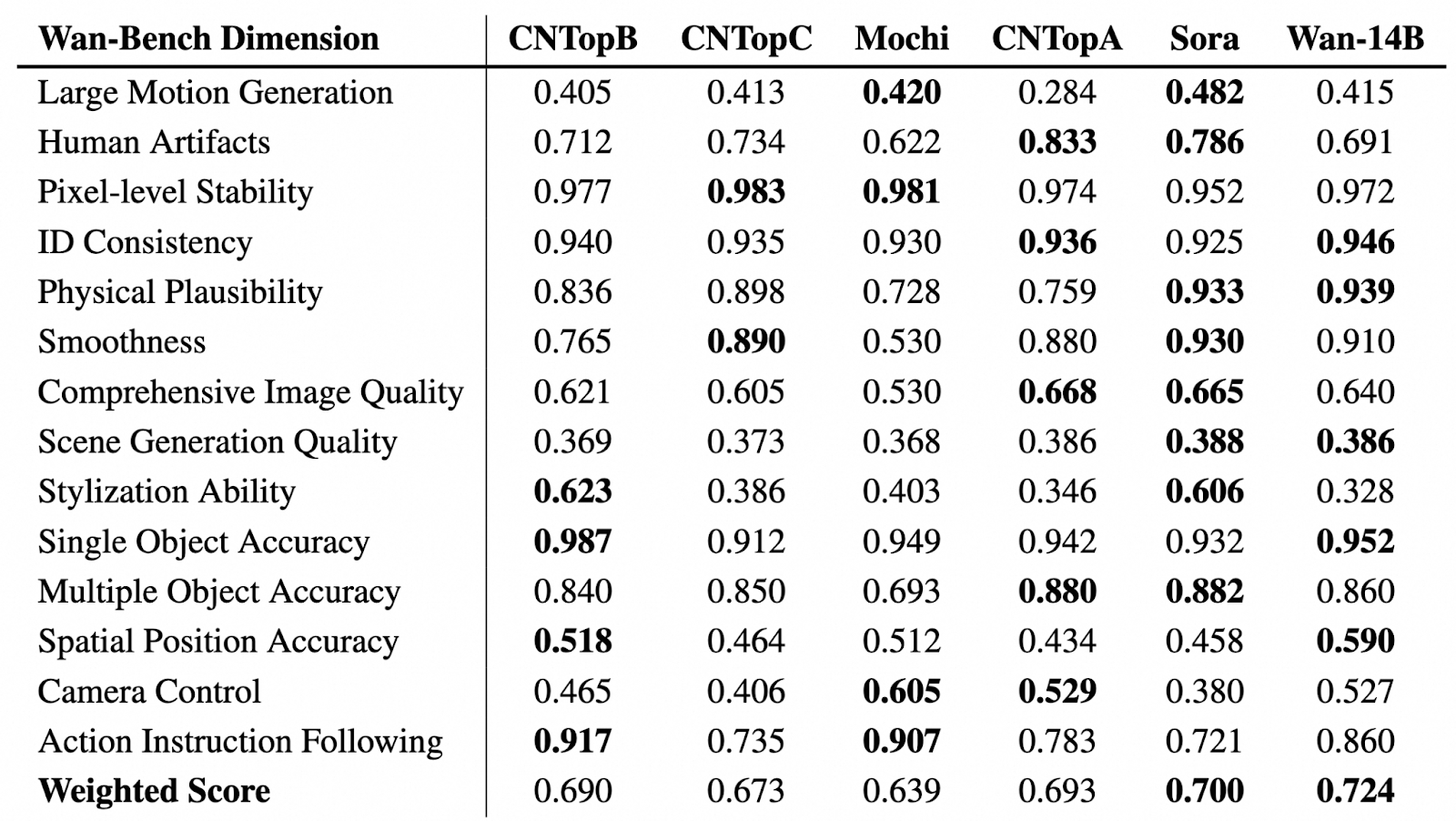
Source: GitHub (Wan-Video/Wan2.1)
In the table above, we can see a comparative evaluation of video generation models across various Wan-Bench dimensions, assessing their performance in key aspects such as motion generation, visual stability, object accuracy, and instruction following. The highest-performing model in each category is highlighted in bold.
Wan-14B achieves the highest overall weighted score (0.724), demonstrating its strong capabilities across multiple benchmarks.
Compared to most high-end AI video models that require expensive hardware, Wan 2.1’s T2V-1.3B model only needs 8.19GB of VRAM. This means you can generate videos using a regular GPU, like an RTX 4090, in just a few minutes without needing a supercomputer.
With Wan, you can do more than just Text-to-Video (T2V). It offers advanced features to improve video generation and customization, including:
Additionally, Wan supports Image-to-Video (I2V) so you can transform still images into animated videos. You can add optional text prompts for greater control over video generation and define the first and last frames to shape the video’s composition and flow.
Wan 2.1 is the first AI video model that can generate readable text inside videos in both English and Chinese. This is great for creating captions, animated text, and graphic overlays within video content.
Wan 2.1 uses an advanced Video Variational Auto Encoder (Wan-VAE) that allows it to:
There are several ways to get started—you can either try it online or run it locally on your computer.
If you want to experiment with Wan 2.1 without installing anything, you can access it through:
1. Hugging Face space: You can run the model directly in a web interface.
2. WanVideo website: Here, you can do more than just generate videos. The official website also lets you create images and explore a collection of videos and images generated by other users, along with the prompts they used.
These options allow you to test the model quickly without worrying about setup or hardware.
If you want full control and customization, you can install Wan 2.1 on your own machine. Let’s go step-by-step on how to do this:
First, download the Wan 2.1 code from GitHub:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1Make sure you have Python and PyTorch (version 2.4.0 or later) installed, then install the required libraries:
pip install -r requirements.txtYou need to download the pre-trained model files from Hugging Face (see more info here) or ModelScope (see more info here).There are different models you can download:
|
Models |
Download Link |
Notes |
|
T2V-14B |
Supports both 480P and 720P |
|
|
I2V-14B-720P |
Supports 720P |
|
|
I2V-14B-480P |
Supports 480P |
|
|
T2V-1.3B |
Supports 480P |
The 1.3B model can generate videos in 720P resolution, but since it has had less training at this quality, the results may be less stable than at 480P. For the best performance, 480P resolution is recommended.
Wan 2.1 allows you to generate videos from text descriptions using two model versions:
If you just want to generate a video quickly, you can use the following commands, where prompt enhancement is not enabled.
For the T2V-14B model (higher quality, bigger model):
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights."For the T2V-1.3B model (smaller, runs on lower-end GPUs):
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "A futuristic city with flying cars and neon lights."If your computer runs out of memory (OOM error), you can use --offload_model True and --t5_cpu to reduce memory usage.
If you have multiple GPUs, you can speed up video generation by running this command:
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "A futuristic city with flying cars and neon lights.`This allows the workload to be split across multiple GPUs, making the process faster.
Wan 2.1 can improve your prompt automatically, so you can make the video more detailed and visually appealing.
There are two ways to extend the prompt:
To use Dashscope API:
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'dashscope'To use your own local model:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "A futuristic city with flying cars and neon lights." --use_prompt_extend --prompt_extend_method 'local_qwen'If you want to use Hugging Face’s Diffusers library instead of running raw scripts, you can generate a video with Python:
import torch
from diffusers.utils import export_to_video
from diffusers import AutoencoderKLWan, WanPipeline
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
# Available models: Wan-AI/Wan2.1-T2V-14B-Diffusers, Wan-AI/Wan2.1-T2V-1.3B-Diffusers
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
# Load the autoencoder for video generation
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
# Define the scheduler for controlling video motion flow
flow_shift = 5.0 # 5.0 for 720P, 3.0 for 480P
scheduler = UniPCMultistepScheduler(
prediction_type='flow_prediction',
use_flow_sigmas=True,
num_train_timesteps=1000,
flow_shift=flow_shift
)
# Load the video generation pipeline with the model
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
pipe.scheduler = scheduler
pipe.to("cuda")
# New prompt
prompt = "A futuristic city at sunset, filled with flying cars and neon lights. The buildings have a sleek, cyberpunk design, and people walk on glowing sidewalks. The scene is full of vibrant colors, reflections, and dynamic movement."
# New negative prompt
negative_prompt = "Dull colors, grainy texture, washed-out details, static frames, incorrect lighting, unnatural shadows, distorted faces, artifacts, low-resolution elements, flickering, blurry motion, repetitive patterns, unrealistic reflections, overly simplistic backgrounds, three legged people, walking backwards."
# Generate the video frames
output = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=720,
width=1280,
num_frames=81,
guidance_scale=5.0,
).frames[0]
# Export the generated frames as a video
export_to_video(output, "output.mp4", fps=16)The script starts by loading the Wan2.1-T2V-14B-Diffusers model, which is used to create videos. It also loads a VAE (Autoencoder), which helps process and improve the video frames. To control how smoothly motion appears in the video, the script uses a scheduler (UniPCMultistepScheduler). The flow_shift setting adjusts how movement is handled, with 5.0 being better for higher resolution (720P) and 3.0 for lower resolution (480P).
Next, the script sets up the video generation pipeline (WanPipeline) and applies the scheduler to ensure smoother transitions between frames. The prompt describes a futuristic city with flying cars and glowing neon lights, while the negative prompt helps remove unwanted effects, such as blurry details, washed-out colors, and flickering frames.
The model then creates 81 frames, which results in about 5 seconds of video at 16 frames per second (FPS). The guidance_scale is set to 5.0, which helps the model follow the prompt while allowing some creativity. Once the video is generated, the frames are combined and saved as "output.mp4" at 16 FPS.
The negative prompt plays an important role in improving the final video by telling the model what to avoid. It helps get rid of things like poor image quality, strange distortions, or anything that might make the video look unrealistic. In this case, it ensures that the futuristic scene looks clean, sharp, and visually appealing.
If you prefer an interactive web interface to generate videos instead of using code, you can run Wan 2.1 with Gradio:
For Dashscope prompt extension:
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14BFor local prompt extension:
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14BSimilar to text-to-video, image-to-video is also divided into processes with and without the prompt extension step. For more details on the implementation, you can visit the official GitHub. You can also join their Discord channel to discuss Wan2.1, share your creations, get updates on new features and developments, and visit the official website to explore generated examples.
Wan 2.1 is built using advanced AI techniques to generate high-quality, realistic videos. It follows a diffusion-based approach and integrates transformers to make sure that the movements are smooth, consistent, and detailed across frames.
Wan 2.1 uses a technique called diffusion models, which work in two steps:
It is kind of like developing a photo in a darkroom—the image starts out blurry and grainy, but it gets clearer with each processing step.
Wan 2.1 improves this approach by using a Diffusion Transformer (DiT), which helps maintain sharp details and smooth motion while generating multiple video frames.
Source: GitHub (Wan-Video/Wan2.1)
This diagram shows how Wan 2.1 generates video frames using a diffusion model enhanced with a Diffusion Transformer (DiT). The process starts with an input description (e.g., "A panda is holding up a cardboard that says 'Wan2.1'"). This text is processed by UMT5, a language model that helps the system understand and refine the prompt.
Simultaneously, an initial noisy image is introduced as the starting point. The Wan-Encoder then processes these inputs, encoding them into a form that the model can manipulate. N x DiT Blocks iteratively refine the image.
The diffusion model progressively removes noise from the frames, using cross-attention to align the output with the provided prompt. The timestep (t) indicates the progressive steps in denoising, ensuring the video develops smoothly over time.
After multiple refinement steps, the Wan-Decoder reconstructs the final video frames from the processed data. The output is a series of frames that align with the original input description, maintaining sharp details, smooth motion, and consistency.
Wan 2.1 features Wan-VAE, a powerful compression tool that helps the model:
It is like when you are zipping files for videos: It compresses and stores key details, then reconstructs them accurately when generating the video.
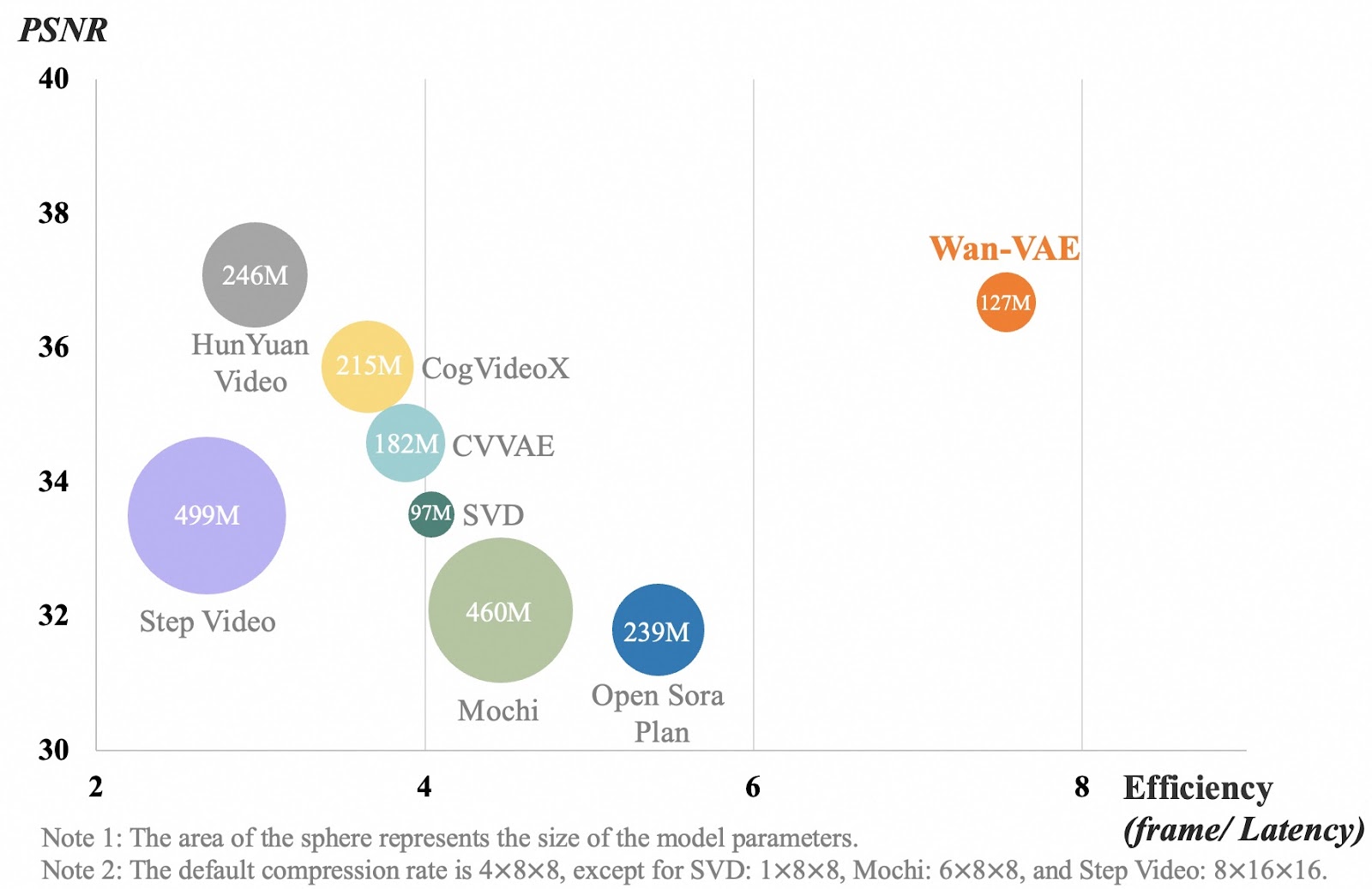
Source: GitHub (Wan-Video/Wan2.1)
The chart compares different video compression models based on video quality (PSNR) and efficiency (how fast they process frames). Each bubble represents a model, and its size shows how big the model is. The x-axis measures how efficiently a model processes video frames. A higher number means the model works faster. The y-axis shows video quality, where a higher number means clearer, more detailed videos.
Wan-VAE, shown in orange, performs better than other models by balancing high video quality with fast processing while staying relatively small (127M parameters). Other models, like Step Video and Mochi, are much larger but don’t process frames as efficiently. This means Wan-VAE can generate long, high-quality videos while keeping details sharp and movement smooth, without slowing down.
Wan 2.1 is a versatile AI video generation model that can be used in many industries. In this section, I will try some examples for different use cases.
Wan 2.1 can help you generate unique video content without expensive equipment or long editing hours. So, let’s imagine that I am a lifestyle influencer and that I want to create some content around a cozy day in my life.I am going to use the following prompt to create a clip for my video:
A time-lapse animation of a cozy café from morning to evening, showing people coming and going, coffee being brewed, and the sunset reflecting on the windows.
Because I wanted it to be as realistic as possible, I also used inspiration mode. This is the result I got:
When the video was generated, at first glance, I was very impressed. But after taking a closer look, I realized a couple of things. First, someone disappears in the background. Additionally, this is not a time-lapse, and no coffee is being brewed. So, even though the video looks quite realistic, it doesn’t accurately reflect the prompt.
Now, imagine you are a game developer. You could use Wan 2.1 to generate realistic cutscenes, background animations, or concept art for your projects. For example, if you already have a character concept and the creative team has provided some designs, you could bring it to life using Wan’s image-to-video feature.
Beyond character animation, Wan 2.1 can also help create dynamic environments, such as shifting weather effects, bustling cityscapes, or mystical landscapes, without needing to animate each frame manually.
Also, with aspect ratio control, you could ensure that your animations fit perfectly into different game scenes, such as widescreen cinematics (16:9), mobile-friendly vertical shots (9:16), or square compositions (1:1) for social media teasers.
You could even use the sound effects feature to generate background ambiance, like the rustling of leaves, the hum of a futuristic city, or battle soundscapes.
Let’s try something!I generated this draft of a medieval knight with DALL-E:

Using Wan, I entered the following prompt using GPT-4o-mini:
A medieval knight stands in a heroic stance, gripping a large sword with both hands. His cape flows in the wind as he surveys the battlefield. The knight slowly turns his head, scanning the horizon with a determined expression. The animation has a cinematic style.But then, I clicked Enhanced Prompt, and this is what I got:
Cinematic Medieval Knight: A gallant knight stands resolute, clad in full plate armor, gripping a formidable broadsword with both hands. His visored helmet and shoulder pauldrons gleam under the sun, while a noble crest adorns his chestplate. A sash cinches his waist, securing his ensemble. His crimson cloak billows dramatically in the breeze, adding to his imposing presence. With a steely gaze, he pivots his head, surveying the vast, sandy battlefield. The scene unfolds on parchment-like textured paper, evoking an ancient manuscript feel. This is a grand, full-body shot, capturing the knight in a triumphant pose, reminiscent of epic medieval cinema.
I toggled off Inspiration Mode but enabled Sound Effects. Here’s the result:
Not bad! Although I must admit, I was expecting a more cinematic version of the draft rather than an animation of the draft itself. But maybe I could have been clearer in the prompt. The music is interesting, and I guess it goes well with the animation!
If you are a marketer, you can use Wan 2.1 to create promotional videos for brands, products, and services or even to animate logos.
Imagine you have an ice cream business, and you want to animate your logo in order to put it at the end of your ads or promo videos.To test this idea, I have once again generated this image with DALL-E:

Then, I used this prompt: The polar bear eats the ice cream. This is the result of image-to-video generation:
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
6 min
blog
Dr Ana Rojo-Echeburúa
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan


