
programa
Microsoft Azure Fundamentals (AZ-900)
9 h
Microsoft Synapse Analytics, anteriormente conocido como Azure SQL Data Warehouse, es un servicio de análisis integrado que ofrece una plataforma unificada para big data y almacenamiento de datos.
Al combinar a la perfección el almacenamiento de datos empresariales y el análisis de macrodatos, Synapse permite a los usuarios ingestar, preparar, gestionar y servir datos para satisfacer las necesidades inmediatas de inteligencia empresarial y machine learning. Este potente servicio es compatible con múltiples lenguajes, como SQL, Python y Spark, lo que permite una amplia gama de capacidades de procesamiento y transformación de datos. Además, su arquitectura sin servidor garantiza la escalabilidad necesaria para gestionar cualquier volumen de datos, lo que lo convierte en una herramienta indispensable para los profesionales de datos modernos.
Esta guía proporciona temas y preguntas esenciales para ayudarte a prepararte para tu entrevista con Synapse. Estas preguntas reflejan mi propia experiencia entrevistando y trabajando con profesionales de datos que utilizan Synapse, y proporcionan una valiosa información sobre lo que buscan los responsables de contratación.
Además de seguir esta guía de entrevista, te sugiero que consultes la documentación de Microsoft Azure Synapse Analytics si tienes alguna pregunta específica durante el proceso.
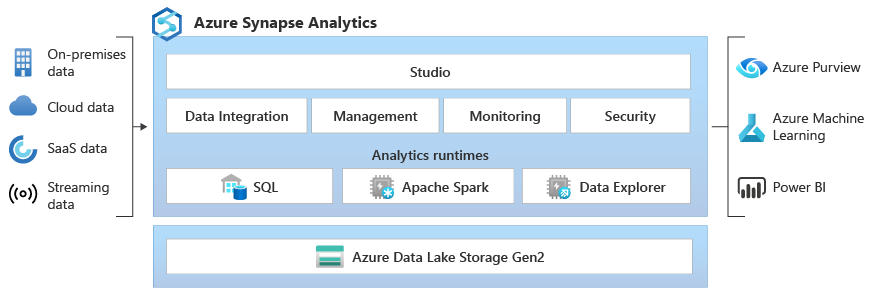
En el nivel básico, las preguntas abarcarán tus conocimientos fundamentales sobre Synapse, incluyendo tareas como navegar por Synapse Studio, comprender sus componentes básicos y realizar exploraciones de datos sencillas. Prepárate para estas preguntas si tienes poca experiencia con Synapse o si el entrevistador está evaluando tus conocimientos básicos.
Si te piden que des una visión general de alto nivel sobre Synapse, deberías ser capaz de describir Synapse Analytics y su función en un panorama de datos moderno.
Synapse Analytics es un servicio de análisis sin límites que combina el almacenamiento de datos empresariales y el análisis de macrodatos. Las características principales incluyen:
La arquitectura central incluye:
Puedes consultar datos en Synapse utilizando:
Estas preguntas evalúan tu comprensión profunda de Synapse y su configuración. Deberás demostrar tu capacidad para gestionar recursos, implementar flujos de trabajo de procesamiento de datos y optimizar el rendimiento.
Esto se basa en tus conocimientos básicos y requiere comprender:
Para crear un grupo SQL, accede a Synapse Studio, selecciona el centro «Administrar» y, a continuación, «Grupos SQL». A continuación, puedes configurar el nivel de rendimiento del grupo (unidades de almacén de datos, DWU) en función de los requisitos de tu carga de trabajo.
La gestión implica supervisar el rendimiento, escalar los recursos y pausar/reanudar el grupo según sea necesario.
Synapse utiliza Spark Pools para proporcionar Apache Spark como servicio. Esto te permite:
Las canalizaciones de datos son flujos de trabajo automatizados para la ingesta, transformación y carga de datos. En Synapse, tú los creas utilizando el centro «Integrate», que proporciona una interfaz visual (Azure Data Factory) para diseñar y administrar canalizaciones.
Estas canalizaciones pueden conectarse a diversas fuentes de datos, realizar transformaciones mediante actividades como el flujo de datos o la ejecución de procedimientos almacenados, y cargar datos en los sistemas de destino.
Puedes supervisar los recursos a través del centro «Monitor» en Synapse Studio. Este centro proporciona información sobre el rendimiento de SQL Pool y Spark Pool, las ejecuciones de canalizaciones y el estado general del sistema. También puedes utilizar Azure Monitor para obtener funciones de supervisión y alertas más detalladas.
Synapse Analytics ofrece una variedad de opciones de almacenamiento de datos que se adaptan a diferentes necesidades y situaciones, lo que garantiza flexibilidad y eficiencia en el manejo de diversos conjuntos de datos. Estas opciones incluyen:
Se espera que los usuarios avanzados se encarguen de la optimización del rendimiento, creen flujos de trabajo complejos e implementen modelos sofisticados de análisis y machine learning. Estas preguntas son típicas para puestos de alto nivel relacionados con los datos o funciones con un componente de DevOps.
Esto se basa en conocimientos básicos e intermedios, y requiere experiencia práctica en:
Indexación adecuada: Optimiza el rendimiento del grupo SQL mediante índices de almacenamiento en columnas agrupados e índices no agrupados adecuados.
Utiliza Azure DevOps o GitHub Actions para automatizar la compilación, las pruebas y la implementación de soluciones Synapse. Esto incluye:
Para gestionar análisis complejos y garantizar operaciones de datos fluidas dentro de Synapse Analytics, es necesario adoptar un enfoque multifacético. Esto implica pruebas automatizadas, estrategias de implementación y técnicas analíticas avanzadas.
A continuación, encontrarás métodos esenciales para alcanzar estos objetivos de manera eficaz:
La implementación de modelos de machine learning en Synapse Analytics implica varios pasos clave, desde el entrenamiento y el registro de los modelos hasta su implementación para su uso práctico. A continuación, se presenta un enfoque estructurado para implementar con éxito modelos de machine learning:
Los ingenieros de datos son responsables de diseñar, crear y mantener canales de datos, garantizar la calidad de los datos y optimizar el rendimiento. Para los puestos de ingeniero de datos centrados en Synapse, debes comprender:
Al diseñar canalizaciones de datos en Synapse Analytics, hay que tener en cuenta varios componentes clave para garantizar un procesamiento de datos eficiente y fiable:
En el contexto de Synapse Analytics, la implementación de procesos ETL (extraer, transformar, cargar) eficaces es fundamental para garantizar una gestión y un análisis eficientes de los datos. Se recomiendan las siguientes prácticas recomendadas para optimizar los procesos ETL en Synapse Analytics:
Como ingeniero de datos, uno se enfrenta a numerosos retos que requieren soluciones innovadoras y metodologías sólidas. Trabajar y manejar datos en tiempo real es uno de ellos. A continuación, se describen algunas experiencias y técnicas que se emplean habitualmente:
Garantizar la seguridad de los datos en Synapse Analytics es fundamental para proteger la información confidencial y mantener el cumplimiento de las normas reglamentarias. Se pueden implementar varias estrategias clave para proteger los datos dentro del entorno Synapse:
Esta guía te ha proporcionado información clave para afrontar con confianza tu entrevista para Microsoft Synapse Analytics, tanto si eres ingeniero de datos como ingeniero de software.
Recuerda destacar no solo tus conocimientos teóricos, sino también tu experiencia práctica en el diseño de canales de datos, la optimización del rendimiento y la garantía de una seguridad de datos sólida.
Más allá de los aspectos técnicos, destaca tus habilidades para resolver problemas y tu capacidad para aprender continuamente, ya que Synapse Analytics es una plataforma en rápida evolución. Mantén tu curiosidad, sigue explorando los recursos de Microsoft y demuestra tu pasión por aprovechar los datos para impulsar resultados empresariales impactantes. ¡Buena suerte!
Aprende Azure con DataCamp
programa
Curso
Curso
blog
Josep Ferrer
15 min
blog
Gus Frazer
14 min
blog
Nisha Arya Ahmed
15 min
blog
Zoumana Keita
12 min
Tutorial
Moez Ali