
Programa
Fundamentos do Microsoft Azure (AZ-900)
9 h
O Microsoft Synapse Analytics, que antes era chamado de Azure SQL Data Warehouse, é um serviço de análise integrado que oferece uma plataforma unificada para big data e warehouse.
Ao combinar perfeitamente o warehouse de dados empresariais e a análise de big data, o Synapse permite que os usuários coletem, preparem, gerenciem e forneçam dados para necessidades imediatas de inteligência de negócios e machine learning. Esse serviço incrível dá suporte a várias linguagens, como SQL, Python e Spark, permitindo um monte de recursos de processamento e transformação de dados. Além disso, sua arquitetura sem servidor garante escalabilidade para lidar com qualquer volume de dados, tornando-a uma ferramenta indispensável para os profissionais de dados modernos.
Este guia traz tópicos e perguntas essenciais para te ajudar a se preparar para a entrevista da Synapse. Essas perguntas refletem minha própria experiência entrevistando e trabalhando com profissionais de dados que usam o Synapse, oferecendo uma visão valiosa sobre o que os gerentes de contratação procuram.
Além de ler este guia de entrevista, sugiro que você dê uma olhada na documentação do Microsoft Azure Synapse Analytics para esclarecer dúvidas específicas que possam surgir ao longo do caminho.
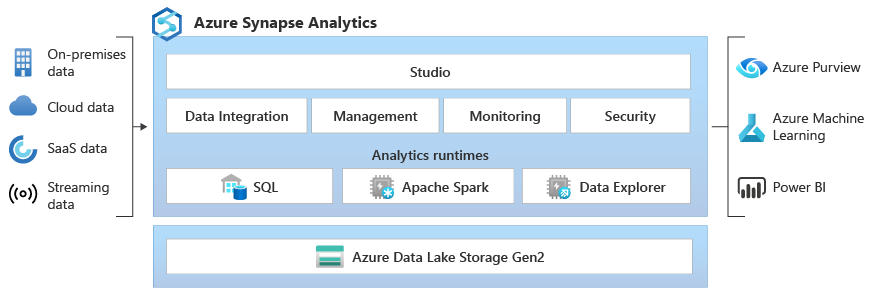
No nível básico, as perguntas vão cobrir o seu conhecimento básico do Synapse, incluindo tarefas como navegar no Synapse Studio, entender seus componentes principais e fazer uma exploração simples de dados. Espere essas perguntas se você tiver pouca experiência com o Synapse ou se o entrevistador estiver avaliando seus conhecimentos básicos.
Se te pedirem pra dar uma visão geral do Synapse, você deve saber descrever o Synapse Analytics e o papel dele no cenário moderno de dados.
O Synapse Analytics é um serviço de análise sem limites que junta warehouse de dados empresariais e análise de big data. As principais características incluem:
A arquitetura principal inclui:
Você pode consultar dados no Synapse usando:
Essas perguntas avaliam o seu entendimento mais profundo do Synapse e sua configuração. Você vai precisar mostrar que sabe lidar com recursos, implementar fluxos de trabalho de processamento de dados e otimizar o desempenho.
Isso se baseia no seu conhecimento básico e precisa que você entenda:
Para criar um pool SQL, vá até o Synapse Studio, selecione o hub “Gerenciar” e, em seguida, “Pools SQL”. Você pode então configurar o nível de desempenho do pool (Unidades de Data Warehouse - DWUs) com base nos requisitos da sua carga de trabalho.
Gerenciar envolve monitorar o desempenho, dimensionar recursos e pausar/retomar o pool conforme necessário.
A Synapse usa o Spark Pools para oferecer o Apache Spark como um serviço. Isso permite que você:
Os pipelines de dados são fluxos de trabalho automatizados para ingestão, transformação e carregamento de dados. No Synapse, você cria usando o hub “Integrar”, que oferece uma interface visual (Azure Data Factory) para projetar e gerenciar pipelines.
Esses pipelines podem se conectar a várias fontes de dados, fazer transformações usando atividades como fluxo de dados ou execução de procedimentos armazenados e carregar dados nos sistemas de destino.
Você pode monitorar os recursos pelo hub “Monitor” no Synapse Studio. Esse hub dá uma visão geral do desempenho do SQL Pool e do Spark Pool, das execuções do pipeline e da saúde geral do sistema. Você também pode usar o Azure Monitor para obter recursos mais detalhados de monitoramento e alerta.
A Synapse Analytics oferece várias opções de armazenamento de dados para atender a diferentes necessidades e cenários, garantindo flexibilidade e eficiência no manuseio de diversos conjuntos de dados. Essas opções incluem:
Espera-se que usuários avançados cuidem da otimização do desempenho, criem fluxos de trabalho complexos e implementem análises sofisticadas e modelos de machine learning. Essas questões são típicas para cargos ou funções sênior na área de dados com um componente DevOps.
Isso se baseia em conhecimentos básicos e intermediários, exigindo experiência prática em:
Indexação correta: Otimize o desempenho do SQL Pool usando índices de armazenamento em coluna agrupados e índices não agrupados apropriados.
Use o Azure DevOps ou o GitHub Actions para automatizar a compilação, o teste e a implantação de soluções Synapse. Isso inclui:
Lidar com análises complexas e garantir operações de dados sem problemas no Synapse Analytics exige uma abordagem multifacetada. Isso envolve testes automatizados, estratégias de implantação e técnicas analíticas avançadas.
Abaixo, você vai encontrar métodos essenciais para atingir esses objetivos de forma eficaz:
Implantar modelos de machine learning no Synapse Analytics envolve várias etapas importantes, desde treinar e registrar os modelos até colocá-los em prática. Aqui está uma abordagem estruturada para implementar com sucesso modelos de machine learning:
Os engenheiros de dados são responsáveis por projetar, construir e manter pipelines de dados, garantir a qualidade dos dados e otimizar o desempenho. Para cargos de engenheiro de dados com foco em Synapse, você deve entender:
Ao projetar pipelines de dados no Synapse Analytics, é preciso pensar em vários componentes importantes para garantir um processamento de dados eficiente e confiável:
No contexto da Synapse Analytics, implementar processos ETL (Extract, Transform, Load) eficazes é essencial para garantir uma gestão e análise de dados eficientes. As seguintes práticas recomendadas são sugeridas para otimizar os processos ETL no Synapse Analytics:
Como engenheiro de dados, a gente enfrenta vários desafios que pedem soluções inovadoras e metodologias robustas. Trabalhar e lidar com dados em tempo real é uma delas. Aqui estão algumas experiências e técnicas que a galera costuma usar:
Garantir a segurança dos dados no Synapse Analytics é super importante pra proteger informações confidenciais e manter a conformidade com as normas regulatórias. Várias estratégias importantes podem ser implementadas para proteger os dados no ambiente Synapse:
Este guia te deu as dicas essenciais para encarar com confiança sua entrevista para a Microsoft Synapse Analytics, seja você engenheiro de dados ou engenheiro de software.
Lembre-se de mostrar não só o seu conhecimento teórico, mas também a sua experiência prática em projetar pipelines de dados, otimizar o desempenho e garantir uma segurança de dados robusta.
Além dos aspectos técnicos, destaque suas habilidades de resolução de problemas e capacidade de aprender continuamente, já que o Synapse Analytics é uma plataforma que está sempre mudando. Mantenha a curiosidade, continue explorando os recursos da Microsoft e mostre sua paixão por usar dados para gerar resultados comerciais impactantes. Boa sorte!
Aprenda Azure com o DataCamp
Programa
Curso
Curso
blog
Chloe Lubin
15 min
blog
Hesam Sheikh Hassani
15 min
blog
Javier Canales Luna
15 min
blog
Zoumana Keita
12 min
blog
Nisha Arya Ahmed
15 min
