
Lernpfad
Microsoft Azure Grundlagen (AZ-900)
9 Std.
Microsoft Synapse Analytics, früher bekannt als Azure SQL Data Warehouse, ist ein integrierter Analysedienst, der eine einheitliche Plattform für Big Data und Data Warehousing bietet.
Durch die nahtlose Verbindung von Unternehmensdatenbanken und Big-Data-Analysen können Nutzer mit Synapse Daten sammeln, aufbereiten, verwalten und bereitstellen, um sofortige Business-Intelligence- und Machine-Learning-Anforderungen zu erfüllen. Dieser leistungsstarke Dienst unterstützt mehrere Sprachen wie SQL, Python und Spark und bietet so eine breite Palette an Datenverarbeitungs- und -transformationsfunktionen. Außerdem sorgt die serverlose Architektur dafür, dass es mit jedem Datenvolumen klarkommt, was es zu einem unverzichtbaren Tool für moderne Datenexperten macht.
Dieser Leitfaden enthält wichtige Themen und Fragen, die dir bei der Vorbereitung auf dein Synapse-Vorstellungsgespräch helfen sollen. Diese Fragen zeigen meine eigenen Erfahrungen aus Interviews und der Zusammenarbeit mit Datenprofis, die Synapse nutzen, und geben einen guten Einblick in das, worauf Personalverantwortliche achten.
Ich schlage vor, dass du neben der Arbeit mit diesem Interviewleitfaden auch mal in der Microsoft Azure Synapse Analytics-Dokumentation stöberst, falls du unterwegs Fragen hast.
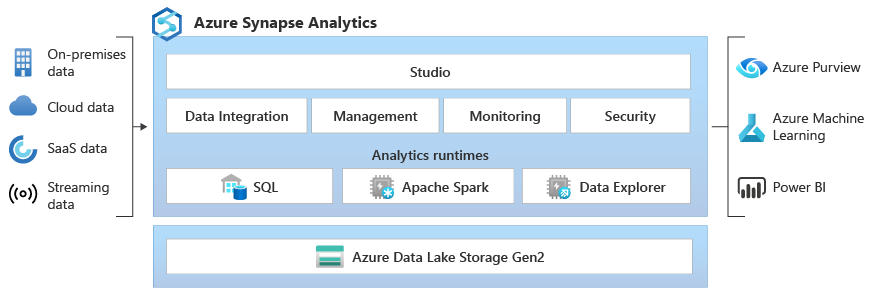
Auf der Grundstufe geht's um dein Basiswissen über Synapse, zum Beispiel wie man sich im Synapse Studio zurechtfindet, was die wichtigsten Teile sind und wie man einfache Datenauswertungen macht. Rechne mit diesen Fragen, wenn du nur wenig Erfahrung mit Synapse hast oder wenn der Interviewer dein grundlegendes Verständnis checken will.
Wenn du gebeten wirst, einen Überblick über Synapse zu geben, solltest du Synapse Analytics und seine Rolle in einer modernen Datenlandschaft beschreiben können.
Synapse Analytics ist ein super vielseitiger Analysedienst, der Unternehmensdatenlagerung und Big-Data-Analysen zusammenbringt. Die wichtigsten Funktionen sind:
Die Kernarchitektur umfasst:
Du kannst Daten in Synapse mit folgendem Befehl abfragen:
Diese Fragen zeigen, wie gut du Synapse und seine Konfiguration verstehst. Du musst zeigen, dass du Ressourcen verwalten, Datenverarbeitungsabläufe umsetzen und die Leistung optimieren kannst.
Das baut auf deinen Grundkenntnissen auf und du solltest Folgendes verstehen:
Um einen SQL-Pool zu erstellen, gehst du zu Synapse Studio, wählst den Hub „Verwalten” und dann „SQL-Pools”. Du kannst dann die Leistungsstufe des Pools (Data Warehouse Units – DWUs) nach deinen Anforderungen an die Arbeitslast einstellen.
Verwalten heißt, die Leistung im Auge zu behalten, Ressourcen anzupassen und den Pool bei Bedarf anzuhalten oder wieder zu starten.
Synapse nutzt Spark Pools, um Apache Spark als Dienst anzubieten. Damit kannst du:
Datenpipelines sind automatisierte Abläufe für die Erfassung, Umwandlung und das Laden von Daten. In Synapse machst du das über den Hub „Integrate“, der eine visuelle Oberfläche (Azure Data Factory) zum Entwerfen und Verwalten von Pipelines bietet.
Diese Pipelines können mit verschiedenen Datenquellen verbunden werden, Transformationen mithilfe von Aktivitäten wie Datenfluss oder der Ausführung gespeicherter Prozeduren durchführen und Daten in Zielsysteme laden.
Du kannst Ressourcen über den Hub „Monitor“ in Synapse Studio überwachen. Dieser Hub gibt dir einen Einblick in die Leistung von SQL Pool und Spark Pool, die Ausführung von Pipelines und den allgemeinen Systemzustand. Du kannst auch Azure Monitor für detailliertere Überwachungs- und Warnfunktionen nutzen.
Synapse Analytics hat verschiedene Optionen für die Datenspeicherung, die zu unterschiedlichen Bedürfnissen und Situationen passen. So ist alles flexibel und effizient, wenn es um verschiedene Datensätze geht. Zu diesen Optionen gehören:
Von fortgeschrittenen Benutzern wird erwartet, dass sie die Leistungsoptimierung übernehmen, komplexe Arbeitsabläufe erstellen und anspruchsvolle Analyse- und Machine-Learning-Modelle umsetzen. Diese Fragen sind typisch für leitende Positionen im Datenbereich oder Jobs mit DevOps-Aufgaben.
Das baut auf Grund- und Mittelstufenkennis auf und braucht praktische Erfahrung in:
Richtige Indizierung: Mach die SQL-Pool-Leistung besser, indem du Clustered-Columnstore-Indizes und passende Non-Clustered-Indizes benutzt.
Nutze Azure DevOps oder GitHub Actions, um das Erstellen, Testen und Bereitstellen von Synapse-Lösungen zu automatisieren. Das umfasst:
Um komplexe Analysen zu machen und einen reibungslosen Datenbetrieb in Synapse Analytics zu haben, braucht man einen vielseitigen Ansatz. Dazu gehören automatisierte Tests, Bereitstellungsstrategien und fortgeschrittene Analysetechniken.
Hier findest du wichtige Methoden, um diese Ziele effektiv zu erreichen:
Das Einrichten von Machine-Learning-Modellen in Synapse Analytics hat ein paar wichtige Schritte, vom Trainieren und Registrieren der Modelle bis hin zu ihrer Einrichtung für den praktischen Einsatz. Hier ist ein strukturierter Ansatz für die erfolgreiche Implementierung von Machine-Learning-Modellen:
Dateningenieure kümmern sich darum, Datenpipelines zu entwerfen, aufzubauen und zu pflegen, die Datenqualität sicherzustellen und die Leistung zu optimieren. Für Stellen als Dateningenieur mit Schwerpunkt auf Synapse solltest du Folgendes verstehen:
Beim Entwerfen von Datenpipelines in Synapse Analytics musst du ein paar wichtige Sachen beachten, damit die Daten effizient und zuverlässig verarbeitet werden:
Bei Synapse Analytics ist es echt wichtig, gute ETL-Prozesse (Extrahieren, Transformieren, Laden) einzurichten, um Datenmanagement und -analyse effizient zu machen. Die folgenden bewährten Methoden sind empfehlenswert, um ETL-Prozesse in Synapse Analytics zu optimieren:
Als Dateningenieur hat man mit vielen Herausforderungen zu tun, die coole Lösungen und starke Methoden brauchen. Eins davon ist die Arbeit mit und der Umgang mit Echtzeitdaten. Hier sind ein paar Erfahrungen und Techniken, die oft benutzt werden:
Die Datensicherheit in Synapse Analytics ist super wichtig, um sensible Infos zu schützen und die gesetzlichen Standards einzuhalten. Es gibt ein paar wichtige Strategien, die man anwenden kann, um Daten in der Synapse-Umgebung zu schützen:
Dieser Leitfaden hat dir wichtige Infos gegeben, damit du dein Vorstellungsgespräch bei Microsoft Synapse Analytics locker meistern kannst, egal ob du Dateningenieur oder Softwareentwickler bist.
Denk dran, nicht nur dein theoretisches Wissen zu zeigen, sondern auch deine praktische Erfahrung beim Entwerfen von Datenpipelines, beim Optimieren der Leistung und beim Sicherstellen einer robusten Datensicherheit.
Zeig nicht nur deine technischen Fähigkeiten, sondern auch, dass du Probleme lösen kannst und immer dazulernst, weil Synapse Analytics eine Plattform ist, die sich schnell weiterentwickelt. Bleib neugierig, schau dir weiter die Ressourcen von Microsoft an und zeig, wie sehr du dich dafür begeisterst, Daten zu nutzen, um beeindruckende Geschäftsergebnisse zu erzielen. Viel Glück!
Lerne Azure mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Matt Crabtree