
Cursus
Microsoft Azure Fundamentals (AZ-900)
9 h
Microsoft Synapse Analytics, anciennement connu sous le nom d'Azure SQL Data Warehouse, est un service d'analyse intégré offrant une plateforme unifiée pour le big data et le stockage de données.
En combinant de manière transparente le stockage des données d'entreprise et l'analyse des mégadonnées, Synapse permet aux utilisateurs d'ingérer, de préparer, de gérer et de fournir des données pour répondre aux besoins immédiats en matière de veille économique et d'apprentissage automatique. Ce service performant prend en charge plusieurs langages tels que SQL, Python et Spark, offrant ainsi un large éventail de capacités de traitement et de transformation des données. De plus, son architecture sans serveur garantit une évolutivité permettant de traiter n'importe quel volume de données, ce qui en fait un outil indispensable pour les professionnels des données modernes.
Ce guide présente les thèmes et questions essentiels pour vous aider à préparer votre entretien Synapse. Ces questions reflètent ma propre expérience en matière d'entretiens et de collaboration avec des professionnels des données utilisant Synapse, et fournissent des informations précieuses sur ce que recherchent les responsables du recrutement.
En plus de suivre ce guide d'entretien, je vous recommande de consulter la documentation Microsoft Azure Synapse Analytics pour toute question spécifique que vous pourriez vous poser au cours du processus.
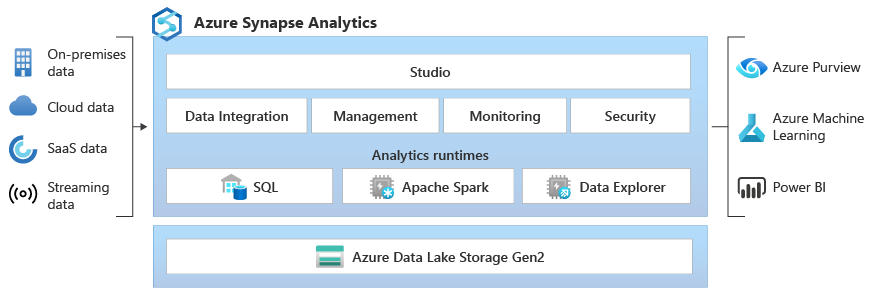
Au niveau élémentaire, les questions porteront sur vos connaissances fondamentales de Synapse, notamment sur des tâches telles que la navigation dans Synapse Studio, la compréhension de ses composants principaux et la réalisation d'explorations de données simples. Attendez-vous à ces questions si vous avez une expérience limitée de Synapse ou si le recruteur évalue vos connaissances fondamentales.
Si l'on vous demande de présenter Synapse de manière générale, vous devriez être en mesure de décrire Synapse Analytics et son rôle dans un environnement de données moderne.
Synapse Analytics est un service d'analyse illimité qui combine le stockage des données d'entreprise et l'analyse des mégadonnées. Les principales caractéristiques sont les suivantes :
L'architecture principale comprend :
Vous pouvez interroger les données dans Synapse en utilisant :
Ces questions évaluent votre compréhension approfondie de Synapse et de sa configuration. Vous devrez démontrer votre capacité à gérer les ressources, à mettre en œuvre des flux de travail pour le traitement des données et à optimiser les performances.
Ceci s'appuie sur vos connaissances de base et nécessite la compréhension des éléments suivants :
Pour créer un pool SQL, veuillez vous rendre dans Synapse Studio, sélectionner le hub « Manage » (Gérer), puis « SQL pools » (Pools SQL). Vous pouvez ensuite configurer le niveau de performance du pool (unités de stockage de données - DWU) en fonction de vos besoins en matière de charge de travail.
La gestion implique de surveiller les performances, d'ajuster les ressources et de suspendre/reprendre le pool selon les besoins.
Synapse utilise Spark Pools pour fournir Apache Spark en tant que service. Cela vous permet de :
Les pipelines de données sont des flux de travail automatisés pour l'ingestion, la transformation et le chargement des données. Dans Synapse, vous les créez à l'aide du hub « Intégrer », qui fournit une interface visuelle (Azure Data Factory) pour concevoir et gérer les pipelines.
Ces pipelines peuvent se connecter à diverses sources de données, effectuer des transformations à l'aide d'activités telles que le flux de données ou l'exécution de procédures stockées, et charger les données dans les systèmes cibles.
Vous pouvez surveiller les ressources via le hub « Monitor » dans Synapse Studio. Ce hub fournit des informations sur les performances de SQL Pool et Spark Pool, les exécutions de pipelines et l'état général du système. Vous pouvez également utiliser Azure Monitor pour bénéficier de fonctionnalités de surveillance et d'alerte plus détaillées.
Synapse Analytics propose diverses options de stockage de données adaptées à différents besoins et scénarios, garantissant flexibilité et efficacité dans le traitement de divers ensembles de données. Ces options comprennent :
Les utilisateurs avancés sont censés gérer l'optimisation des performances, créer des flux de travail complexes et mettre en œuvre des modèles sophistiqués d'analyse et d'apprentissage automatique. Ces questions sont typiques des postes de haut niveau dans le domaine des données ou des rôles comportant une composante DevOps.
Ceci s'appuie sur des connaissances de base et intermédiaires, et nécessite une expérience pratique dans les domaines suivants :
Indexation appropriée : Optimisez les performances du pool SQL en utilisant des index clusterisés de type columnstore et des index non clusterisés appropriés.
Veuillez utiliser Azure DevOps ou GitHub Actions pour automatiser la création, le test et le déploiement des solutions Synapse. Cela comprend :
La gestion d'analyses complexes et la garantie d'opérations de données fluides au sein de Synapse Analytics nécessitent une approche multiforme. Cela implique des tests automatisés, des stratégies de déploiement et des techniques analytiques avancées.
Vous trouverez ci-dessous les méthodes essentielles pour atteindre efficacement ces objectifs :
Le déploiement de modèles d'apprentissage automatique dans Synapse Analytics implique plusieurs étapes clés, depuis la formation et l'enregistrement des modèles jusqu'à leur déploiement pour une utilisation pratique. Voici une approche structurée pour déployer avec succès des modèles d'apprentissage automatique :
Les ingénieurs de données sont chargés de concevoir, de créer et de maintenir des pipelines de données, de garantir la qualité des données et d'optimiser les performances. Pour les postes d'ingénieur de données axés sur Synapse, il est important de comprendre :
Lors de la conception de pipelines de données dans Synapse Analytics, plusieurs éléments clés doivent être pris en compte afin de garantir un traitement efficace et fiable des données :
Dans le contexte de Synapse Analytics, la mise en œuvre de processus ETL (Extract, Transform, Load) efficaces est essentielle pour garantir une gestion et une analyse efficaces des données. Les meilleures pratiques suivantes sont recommandées pour optimiser les processus ETL dans Synapse Analytics :
En tant qu'ingénieur de données, on est confronté à de nombreux défis qui nécessitent des solutions innovantes et des méthodologies robustes. Travailler avec des données en temps réel et les gérer en fait partie. Voici quelques expériences et techniques couramment utilisées :
Il est essentiel de garantir la sécurité des données dans Synapse Analytics afin de protéger les informations sensibles et de maintenir la conformité aux normes réglementaires. Plusieurs stratégies clés peuvent être mises en œuvre pour protéger les données dans l'environnement Synapse :
Ce guide vous a fourni des informations clés pour aborder en toute confiance votre entretien chez Microsoft Synapse Analytics, que vous soyez ingénieur de données ou ingénieur logiciel.
N'oubliez pas de mettre en avant non seulement vos connaissances théoriques, mais également votre expérience pratique dans la conception de pipelines de données, l'optimisation des performances et la garantie d'une sécurité des données robuste.
Au-delà des aspects techniques, veuillez mettre en avant vos compétences en matière de résolution de problèmes et votre capacité à apprendre en permanence, car Synapse Analytics est une plateforme en constante évolution. Restez curieux, continuez à explorer les ressources Microsoft et démontrez votre passion pour l'exploitation des données afin d'obtenir des résultats commerciaux significatifs. Je vous souhaite bonne chance.
Apprenez Azure avec DataCamp
Cursus
Cours
Cours