
Track
Microsoft Azure Fundamentals (AZ-900)
9 hr
Microsoft Synapse Analytics, formerly known as Azure SQL Data Warehouse, is an integrated analytics service offering a unified platform for big data and data warehousing.
By seamlessly combining enterprise data warehousing and big data analytics, Synapse allows users to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. This powerful service supports multiple languages such as SQL, Python, and Spark, enabling a broad range of data processing and transformation capabilities. Furthermore, its serverless architecture ensures scalability to handle any volume of data, making it an indispensable tool for modern data professionals.
This guide provides essential topics and questions to help you prepare for your Synapse interview. These questions reflect my own experience interviewing and working with data professionals using Synapse, providing valuable insight into what hiring managers look for.
In addition to working through this interview guide, I suggest browsing Microsoft Azure Synapse Analytics Documentation for specific questions you might have along the way.
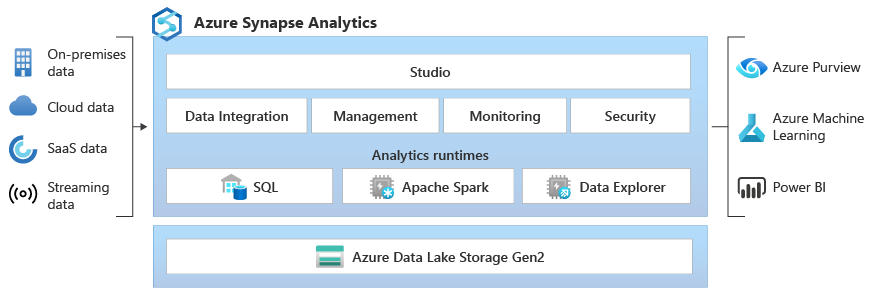
At the basic level, questions will cover your foundational knowledge of Synapse, including tasks such as navigating the Synapse Studio, understanding its core components, and performing simple data exploration. Expect these questions if you have limited Synapse experience or if the interviewer is assessing your fundamental understanding.
If you are asked to give a high-level overview of Synapse, you should be able to describe Synapse Analytics and its role in a modern data landscape.
Synapse Analytics is a limitless analytics service that brings together enterprise data warehousing and big data analytics. Key features include:
The core architecture includes:
You can query data in Synapse using:
These questions gauge your deeper understanding of Synapse and its configuration. You'll need to demonstrate your ability to manage resources, implement data processing workflows, and optimize performance.
This builds upon your basic knowledge and requires understanding of:
To create a SQL Pool, you navigate to the Synapse Studio, select the "Manage" hub, and then "SQL pools." You can then configure the pool's performance level (Data Warehouse Units - DWUs) based on your workload requirements.
Managing involves monitoring performance, scaling resources, and pausing/resuming the pool as needed.
Synapse uses Spark Pools to provide Apache Spark as a service. This allows you to:
Data pipelines are automated workflows for data ingestion, transformation, and loading. In Synapse, you create them using the "Integrate" hub, which provides a visual interface (Azure Data Factory) to design and manage pipelines.
These pipelines can connect to various data sources, perform transformations using activities like data flow or stored procedure execution, and load data into target systems.
You can monitor resources via the "Monitor" hub in Synapse Studio. This hub provides insights into SQL Pool and Spark Pool performance, pipeline executions, and overall system health. You can also use Azure Monitor for more detailed monitoring and alerting capabilities.
Synapse Analytics offers a variety of data storage options to suit different needs and scenarios, ensuring flexibility and efficiency in handling diverse datasets. These options include:
Advanced users are expected to handle performance optimization, create complex workflows, and implement sophisticated analytics and machine learning models. These questions are typical for senior data positions or roles with a DevOps component.
This builds on basic and intermediate knowledge, requiring practical experience in:
Proper Indexing: Optimize SQL Pool performance by using clustered columnstore indexes and appropriate non-clustered indexes.
Use Azure DevOps or GitHub Actions to automate the build, test, and deployment of Synapse solutions. This includes:
Handling complex analytics and ensuring seamless data operations within Synapse Analytics requires a multifaceted approach. This involves automated testing, deployment strategies, and advanced analytical techniques.
Below, you'll find essential methods to achieve these goals effectively:
Deploying machine learning models in Synapse Analytics involves several key steps, from training and registering models to deploying them for practical use. Here is a structured approach to successfully deploying machine learning models:
Data Engineers are responsible for designing, building, and maintaining data pipelines, ensuring data quality, and optimizing performance. For Data Engineer positions focusing on Synapse, you should understand:
When designing data pipelines in Synapse Analytics, several key components must be considered to ensure efficient and reliable data processing:
In the context of Synapse Analytics, implementing effective ETL (Extract, Transform, Load) processes is crucial for ensuring efficient data management and analytics. The following best practices are recommended to optimize ETL processes within Synapse Analytics:
As a data engineer, one encounters numerous challenges that require innovative solutions and robust methodologies. Working with and handling real-time data is one of them. Here are some experiences and techniques commonly employed:
Ensuring data security in Synapse Analytics is paramount to protect sensitive information and maintain compliance with regulatory standards. Several key strategies can be implemented to safeguard data within the Synapse environment:
This guide has equipped you with key insights to confidently tackle your Microsoft Synapse Analytics interview, whether you're a data engineer or software engineer.
Remember to showcase not only your theoretical knowledge but also your practical experience in designing data pipelines, optimizing performance, and ensuring robust data security.
Beyond the technical aspects, highlight your problem-solving skills and ability to learn continuously, as Synapse Analytics is a rapidly evolving platform. Stay curious, keep exploring Microsoft's resources, and demonstrate your passion for leveraging data to drive impactful business outcomes. Good luck!
Learn Azure with DataCamp
Track
Course
Course
blog
Dhiraj Kumar
15 min
blog
Josep Ferrer
14 min
blog
Josep Ferrer
15 min
blog
Flavio Matos
15 min
blog
Patrick Brus
15 min
blog
Marie Fayard
15 min