
Track
Professional Data Engineer in Python
40 hr
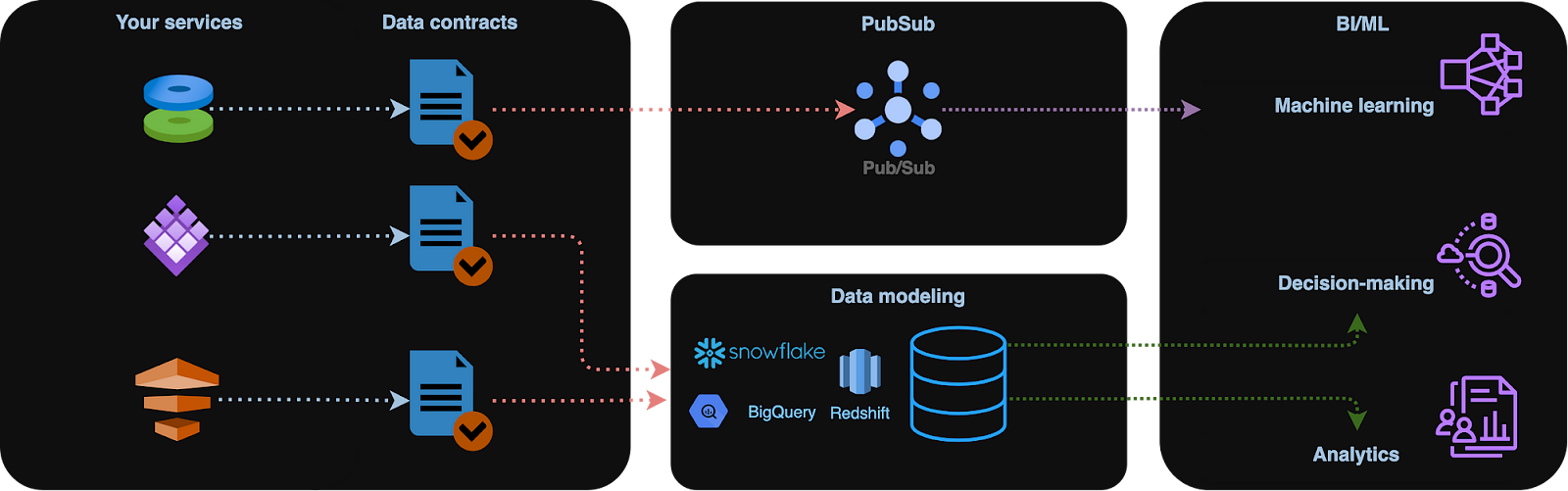
Data contracts are the backbone of data quality and scalability for distributed data solutions. They specify the format, schema, and protocols governing the exchange between database entities. These formal agreements eliminate ambiguities and undocumented assumptions about the data.
In this article, I will clarify the concept of data contracts by offering both foundational and advanced techniques to facilitate their effective implementation.
A single data contract delineates the precise parameters for data exchange between two models. These formal agreements ensure that there are no ambiguities regarding the data format and schemas.
Data contract definitions and validation are crucial for effective cross-team collaboration.
In a nutshell, a data contract is a formal agreement between the process that changes the original state of our data (producers) and destinations (consumers). It’s very similar to how business contracts work. They represent obligations between suppliers and consumers of a business product. Data contracts do the same with data products, i.e., tables, views, data models, etc.
The aim is to mitigate data pipeline downstream disruptions and make data transformations stable and reliable.
The main components of a data contract are schema (columns and formats), semantic layer part (measures, calculations, and restrictions), service level agreements (SLAs), and data governance.
The benefits of data contracts include:
Data contracts. Image by author.
In a data contract, schemas define attribute names, data types, and whether attributes are mandatory. They may also specify the format, length, and acceptable value ranges for columns.
Let’s consider a dbt model schema defined as follows in a YAML file. Our table schema is defined under columns:
models:
- name: dim_orders
config:
materialized: table
contract:
enforced: true
columns:
- name: order_id
data_type: int
constraints:
- type: not_null
- name: order_type
data_type: stringNow let’s imagine we define our dim_orders model as this:
select
'abc123' as order_id,
'Some order type' as order_typeHaving a contract as enforced: true in our model definition will trigger the following error if we try to materialize dim_orders into a table in our data platform:
20:53:45 Compilation Error in model dim_customers (models/dim_orders.sql)
20:53:45 This model has an enforced contract that failed.
20:53:45 Please ensure the name, data_type, and number of columns in your contract match the columns in your model's definition.
20:53:45
20:53:45 | column_name | definition_type | contract_type | mismatch_reason |
20:53:45 | ----------- | --------------- | ------------- | ------------------ |
20:53:45 | order_id | TEXT | INT | data type mismatch |
20:53:45
20:53:45
20:53:45 > in macro assert_columns_equivalent (macros/materializations/models/table/columns_spec_ddl.sql)The same would have happened with extra columns, SLA checks, and missing metadata, should we have chosen to define them.
A more advanced dbt example would contain enforced model constraints:
# models/schema.yaml
models:
- name: orders
# required
config:
contract:
enforced: true
# model-level constraints
constraints:
- type: primary_key
columns: [id]
- type: FOREIGN_KEY # multi_column
columns: [order_type, SECOND_COLUMN, ...]
expression: "OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_FIRST_COLUMN, OTHER_MODEL_SECOND_COLUMN, ...)"
- type: check
columns: [FIRST_COLUMN, SECOND_COLUMN, ...]
expression: "FIRST_COLUMN != SECOND_COLUMN"
name: HUMAN_FRIENDLY_NAME
- type: ...
columns:
- name: FIRST_COLUMN
data_type: DATA_TYPE
# column-level constraints
constraints:
- type: not_null
- type: unique
- type: foreign_key
expression: OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_COLUMN)
- type: …Providing a schema definition as a set of rules and constraints applied to the columns of a dataset offers very important information for processing and analyzing data.
Schemas tend to change over time.
This is a common scenario. Let’s imagine our source table added an extra contracted column:
select
'abc123' as order_id,
'Some order type' as order_type,
'USD' as currencyIt’s essential to consider schema changes while performing incremental updates because otherwise, the output of the downstream incremental model would invalidate the contract.
This can be solved by adding on_schema_change: append to the dbt incremental strategy.
Schema validations can be explicit or implicit.
Some big data file formats, like AVRO and Parquet, support onboard schema and implicit schema definitions by default, so there is no need for extra external validation.
On the contrary, schema-less data file formats like JSON require external schema validation. Some Python libraries, such as pydantic or a simple @dataclass, can perform this:
from pydantic import BaseModel
class ConnectionDataRecord(BaseModel):
user: str
ts: int
record = ConnectionDataRecord(user="user1", ts=123456789)If we break the rules and assign some values that don’t match our criteria, the exception will be thrown. For example, the exception will be raised if we try to call ConnectionDataRecord('', 1).
Learn more about data engineering with these courses!
Track
Course
Course
blog
Kurtis Pykes
11 min
blog
Vincent Vankrunkelsven
15 min
blog
Srujana Maddula
9 min
Tutorial
Amberle McKee
Tutorial
Eduardo Oliveira
Tutorial
Kurtis Pykes


