
programa
Llama Fundamentals
4 h
En enero de 2025, DeepSeek lanzó DeepSeek-R1el siguiente paso en su trabajo sobre los modelos de razonamiento. Es una actualización de su anterior DeepSeek-R1-Lite-Preview y demuestra que se toman en serio la competencia con o1 de OpenAI.
Desde entonces, DeepSeek ha seguido mejorando el modelo. En mayo de 2025, publicaron DeepSeek-R1-0528, una versión actualizada con mejor rendimiento en los benchmarks, menos alucinaciones y nuevas capacidades como la llamada a funciones y el soporte de salida JSON.
Aunque DeepSeek puede ir ligeramente por detrás de sus competidores en algunas áreas, su naturaleza de código abierto y su precio significativamente más bajo lo convierten en una opción atractiva para la comunidad de IA.
En este blog, desglosaré las principales características de DeepSeek-R1, su proceso de desarrollo, los modelos destilados, cómo acceder a él, su precio y cómo se compara con los modelos de OpenAI.
Escribí este artículo el día que se publicó DeepSeek-R1, pero ahora lo he actualizado con una nueva sección que cubre sus consecuencias: cómo afectó al mercado de valores, la economía de la IA (incluida la paradoja de Jevons y la mercantilización de los modelos de IA) y la acusación de OpenAI de que DeepSeek destiló sus modelos. También he añadido una sección actualizada sobre el nuevo DeepSeek-R1-0528.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
DeepSeek-R1 es un modelo de razonamiento modelo de razonamiento desarrollado por DeepSeek, una empresa china de IA, para abordar tareas que requieren inferencia lógica, resolución de problemas matemáticos y toma de decisiones en tiempo real.
Lo que diferencia a los modelos de razonamiento como DeepSeek-R1 y o1 de OpenAI de los modelos lingüísticos tradicionales es su capacidad para mostrar cómo han llegado a una conclusión.

Con DeepSeek-R1, puedes seguir su lógica, lo que facilita su comprensión y, si es necesario, impugnar su resultado. Esta capacidad da a los modelos de razonamiento una ventaja en campos en los que los resultados deben ser explicables, como la investigación o la toma de decisiones complejas.
Lo que hace que DeepSeek-R1 sea especialmente competitivo y atractivo es su naturaleza de código abierto. A diferencia de los modelos propietarios, su naturaleza de código abierto permite a programadores e investigadores explorarlo, modificarlo y desplegarlo dentro de ciertos límites técnicos, como los requisitos de recursos.
En esta sección, te explicaré cómo se desarrolló DeepSeek-R1, empezando por su predecesor, DeepSeek-R1-Zero.
DeepSeek-R1 comenzó con R1-Zero, un modelo entrenado completamente mediante aprendizaje por refuerzo. Aunque este enfoque le permitió desarrollar una gran capacidad de razonamiento, tuvo importantes inconvenientes. Los resultados eran a menudo difíciles de leer, y el modelo a veces mezclaba idiomas en sus respuestas. Estas limitaciones hicieron que el R1-Cero fuera menos práctico para las aplicaciones del mundo real.
La dependencia del aprendizaje por refuerzo puro creaba resultados lógicamente sólidos, pero mal estructurados. Sin la orientación de los datos supervisados, el modelo tuvo dificultades para comunicar su razonamiento con eficacia. Esto suponía un obstáculo para los usuarios que necesitaban claridad y precisión en los resultados.
Para resolver estos problemas, DeepSeek introdujo un cambio en el desarrollo de R1 combinando el aprendizaje por refuerzo con el ajuste fino supervisado. Este enfoque híbrido incorporó conjuntos de datos curados, mejorando la legibilidad y coherencia del modelo. Se redujeron significativamente problemas como la mezcla de idiomas y el razonamiento fragmentado, lo que hizo que el modelo fuera más adecuado para el uso práctico.
Si quieres saber más sobre el desarrollo de DeepSeek-R1, te recomiendo que leas el documento de lanzamiento.
Destilación en IA es el proceso de crear modelos más pequeños y eficientes a partir de otros más grandes, conservando gran parte de su poder de razonamiento y reduciendo al mismo tiempo las demandas computacionales. DeepSeek aplicó esta técnica para crear un conjunto de modelos destilados a partir de R1, utilizando las arquitecturas Qwen y Llama.
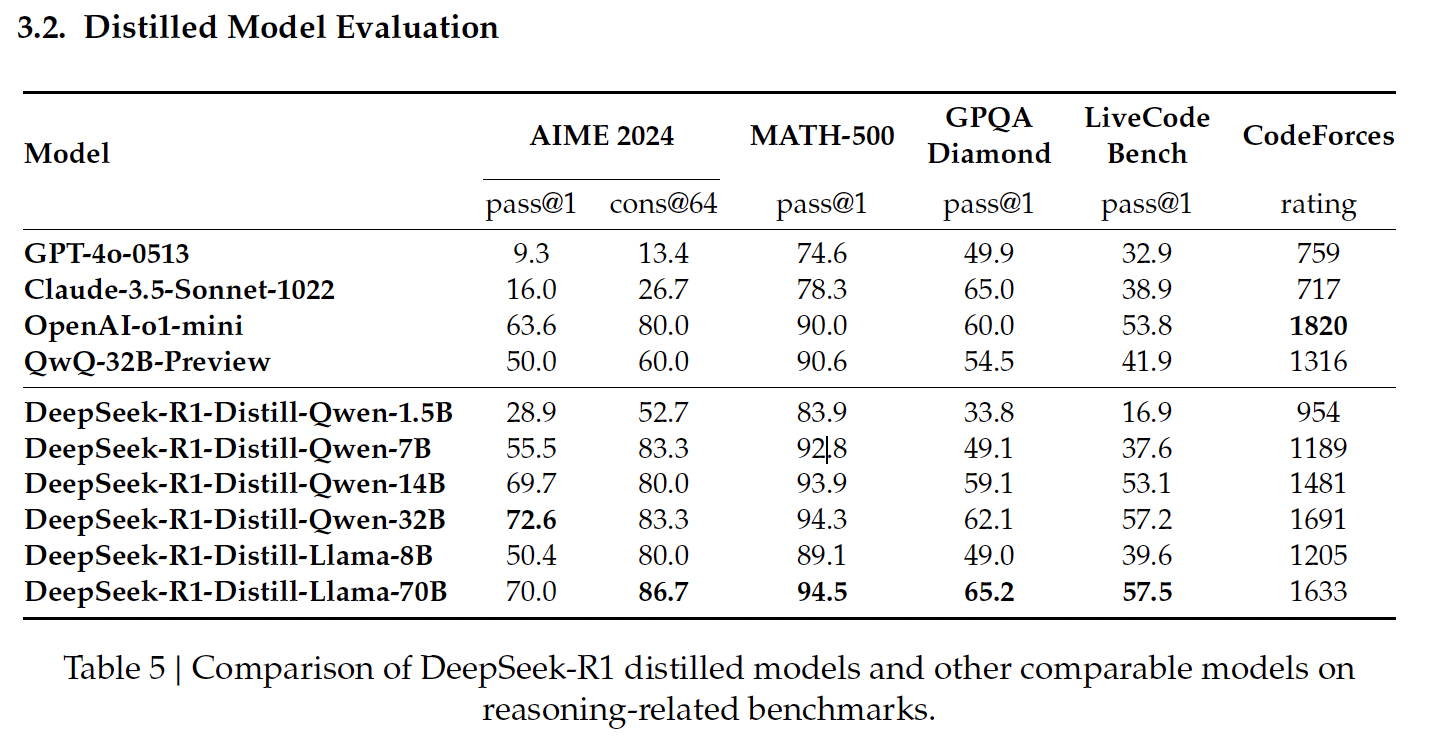
Fuente: Documento de publicación de DeepSeek
Los modelos destilados basados en Qwen de DeepSeek se centran en la eficacia y la escalabilidad, ofreciendo un equilibrio entre el rendimiento y los requisitos computacionales.
Este es el modelo destilado más pequeño, que obtiene un 83,9% en MATH-500. MATH-500 evalúa la capacidad de resolver problemas matemáticos de nivel de enseñanza secundaria con razonamiento lógico y soluciones de varios pasos. Este resultado demuestra que el modelo maneja bien las tareas matemáticas básicas a pesar de su tamaño compacto.
Sin embargo, su rendimiento desciende significativamente en LiveCodeBench (16,9%), una prueba de referencia diseñada para evaluar las capacidades de codificación, lo que pone de manifiesto su limitada capacidad en tareas de programación.
Qwen-7B brilla en MATH-500, con una puntuación del 92,8%, lo que demuestra su gran capacidad de razonamiento matemático. También obtiene unos resultados razonablemente buenos en el GPQA Diamante (49,1%), que evalúa la respuesta a preguntas factuales, lo que indica que tiene un buen equilibrio entre razonamiento matemático y factual.
Sin embargo, su rendimiento en LiveCodeBench (37,6%) y CodeForces (1189 puntos) sugiere que es menos adecuado para tareas de codificación complejas.
Este modelo obtiene buenos resultados en MATH-500 (93,9%), lo que refleja su capacidad para tratar problemas matemáticos complejos. Su puntuación del 59,1% en el GPQA Diamante también indica competencia en razonamiento factual.
Su rendimiento en LiveCodeBench (53,1%) y CodeForces (1481 de puntuación) muestra margen de crecimiento en tareas de codificación y razonamiento específico de programación.
El modelo más grande basado en Qwen obtiene la puntuación más alta entre sus compañeros en AIME 2024 (72,6%), que evalúa el razonamiento matemático avanzado de varios pasos. También sobresale en MATH-500 (94,3%) y GPQA Diamond (62,1%), lo que demuestra su fortaleza tanto en razonamiento matemático como fáctico.
Sus resultados en LiveCodeBench (57,2%) y CodeForces (1691 de valoración) sugieren que es versátil, pero aún no está optimizado para tareas de programación en comparación con los modelos especializados en codificación.
Los modelos destilados basados en Llama de DeepSeek priorizan el alto rendimiento y las capacidades avanzadas de razonamiento, destacando especialmente en tareas que requieren precisión matemática y factual.
Llama-8B obtiene buenos resultados en MATH-500 (89,1%) y razonables en GPQA Diamond (49,0%), lo que indica su capacidad para manejar el razonamiento matemático y factual. Sin embargo, obtiene puntuaciones más bajas en pruebas comparativas de codificación como LiveCodeBench (39,6%) y CodeForces (puntuación de 1205), lo que pone de manifiesto sus limitaciones en tareas relacionadas con la programación en comparación con los modelos basados en Qwen.
El modelo destilado más grande, Llama-70B, ofrece un rendimiento de primer nivel en MATH-500 (94,5%), el mejor entre todos los modelos destilados, y alcanza una sólida puntuación del 86,7% en AIME 2024, lo que lo convierte en una opción excelente para el razonamiento matemático avanzado.
También obtiene buenos resultados en LiveCodeBench (57,5%) y CodeForces (1633 de puntuación), lo que sugiere que es más competente en tareas de codificación que la mayoría de los demás modelos. En este ámbito, está a la altura del o1-mini de OpenAI o del GPT-4o.
Puedes acceder a DeepSeek-R1 a través de dos métodos principales: la plataforma web DeepSeek Chat y la API DeepSeek, lo que te permite elegir la opción que mejor se adapte a tus necesidades.
La plataforma DeepSeek Chat ofrece una forma sencilla de interactuar con DeepSeek-R1. Para acceder a él, puedes ir directamente a la página del chat o hacer clic en Empezar ahora en la página de inicio.

Tras registrarte, puedes seleccionar el modo "Pensamiento Profundo" para experimentar las capacidades de razonamiento paso a paso de Deepseek-R1.
Para integrar DeepSeek-R1 en tus aplicaciones, la API de DeepSeek proporciona acceso programático.
Para empezar, necesitarás obtener una clave API registrándote en la Plataforma DeepSeek.
La API es compatible con el formato de OpenAI, lo que facilita la integración si estás familiarizado con las herramientas de OpenAI. Puedes encontrar más instrucciones en documentación de la API de DeepSeek.
A partir de mayo de 2025, la plataforma de chat es de uso gratuito con el modelo R1.
La API ofrece dos modelos:deepseek-chat (DeepSeek-V3) y deepseek-reasoner (DeepSeek-R1)- con la siguiente estructura de precios (por 1M de tokens):
|
MODELO |
LONGITUD DEL CONTEXTO |
MAX COT TOKENS |
TOKENS DE SALIDA MÁX. |
1M TOKENS PRECIO DE ENTRADA (CACHE HIT) |
1M TOKENS PRECIO DE ENTRADA (CACHE MISS) |
1M TOKENS PRECIO DE SALIDA |
|
deepseek-chat |
64K |
- |
8K |
$0.07 $0.014 |
$0.27 $0.14 |
$1.10 $0.28 |
|
deepseek-reasoner |
64K |
32K |
8K |
$0.14 |
$0.55 |
$2.19 |
Fuente: Página de precios de DeepSeek
Para asegurarte de que dispones de la información más actualizada sobre precios y saber cómo calcular el coste del razonamiento CoT (Cadena de Pensamiento), visita la página de precios de DeepSeek.
DeepSeek-R1 compite directamente con OpenAI o1 en varias pruebas comparativas, a menudo igualando o superando a OpenAI o1.
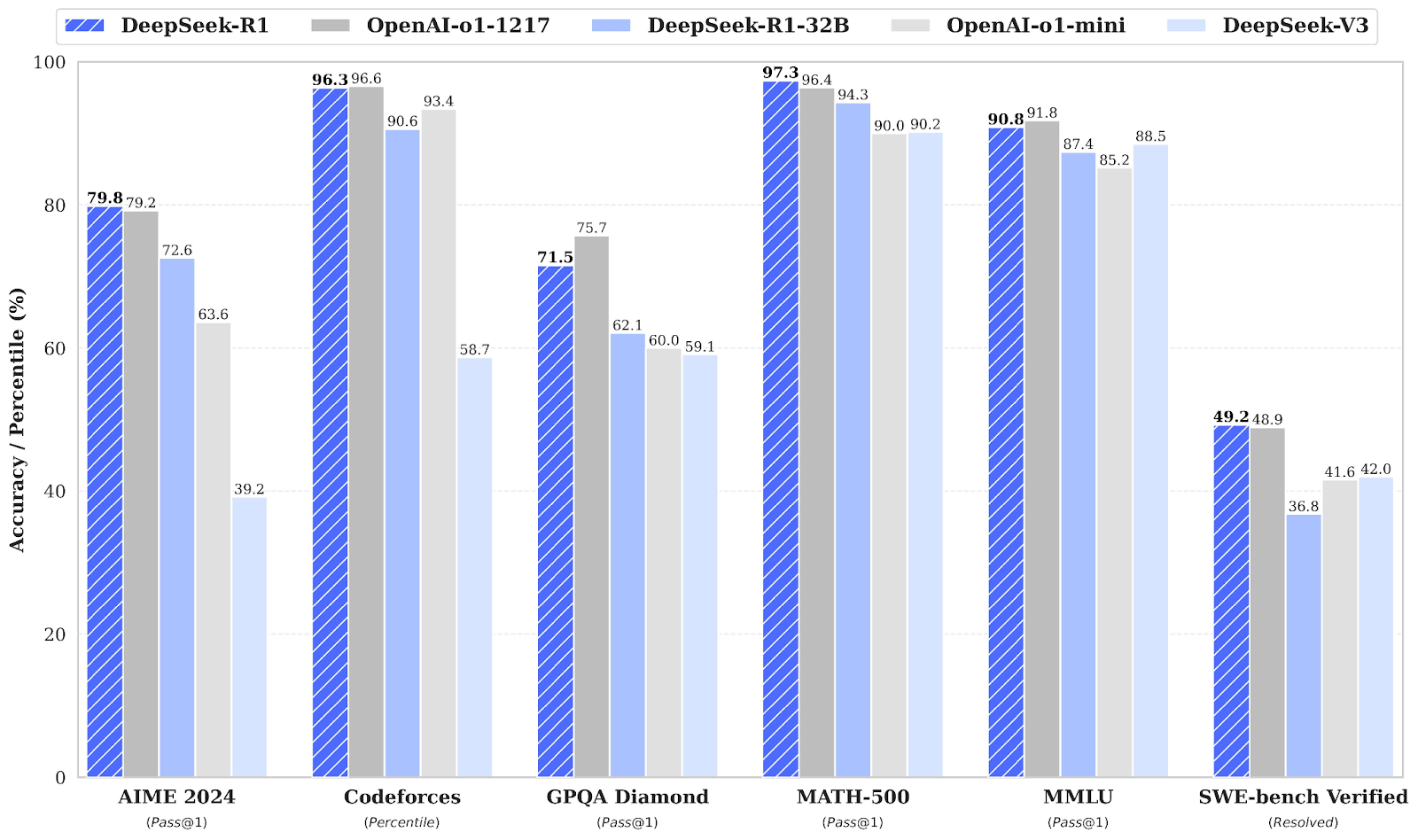
Fuente: Documento de publicación de DeepSeek
En las pruebas de matemáticas, DeepSeek-R1 demuestra un gran rendimiento. En AIME 2024, que evalúa el razonamiento matemático avanzado de varios pasos, DeepSeek-R1 obtiene una puntuación del 79,8%, ligeramente por delante de OpenAI o1-1217 con un 79,2%.
En MATH-500, DeepSeek-R1 toma la delantera con un impresionante 97,3%, superando ligeramente a OpenAI o1-1217 con un 96,4%. Este punto de referencia pone a prueba los modelos en diversos problemas matemáticos de nivel de secundaria que requieren un razonamiento detallado.
La referencia Codeforces evalúa las capacidades de codificación y razonamiento algorítmico de un modelo, representadas como una clasificación percentil frente a participantes humanos. OpenAI o1-1217 lidera con un 96,6%, mientras que DeepSeek-R1 alcanza un 96,3% muy competitivo, con una diferencia mínima.
El banco de pruebas SWE-bench Verified evalúa el razonamiento en tareas de ingeniería de software. DeepSeek-R1 obtiene unos buenos resultados con una puntuación del 49,2%, ligeramente por delante del 48,9% de OpenAI o1-1217. Este resultado posiciona a DeepSeek-R1 como un fuerte competidor en tareas de razonamiento especializado como la verificación de software.
Para el razonamiento factual, el GPQA Diamond mide la capacidad de responder a preguntas de conocimientos generales. DeepSeek-R1 obtiene una puntuación del 71,5%, por detrás de OpenAI o1-1217, que alcanza el 75,7%. Este resultado pone de manifiesto la ligera ventaja de OpenAI o1-1217 en las tareas de razonamiento factual.
En MMLU, una prueba comparativa que abarca varias disciplinas y evalúa la comprensión lingüística multitarea, OpenAI o1-1217 supera ligeramente a DeepSeek-R1, con una puntuación del 91,8% frente al 90,8% de DeepSeek-R1.
La publicación de DeepSeek-R1 ha tenido consecuencias de gran alcance, afectando a los mercados de valores, remodelando la economía de la IA y suscitando controversia sobre las prácticas de desarrollo de modelos.
La introducción por parte de DeepSeek de su modelo R1, que ofrece capacidades avanzadas de IA a una fracción del coste de los competidores, provocó un descenso sustancial de las cotizaciones bursátiles de las principales empresas tecnológicas estadounidenses.
Nvidia, por ejemplo, experimentó una caída de casi el 18% en el valor de sus acciones, lo que equivale a una pérdida de aproximadamente 600.000 millones de dólares en capitalización bursátil. Este descenso fue impulsado por la preocupación de los inversores de que los eficientes modelos de IA de DeepSeek pudieran reducir la demanda de hardware de alto rendimiento tradicionalmente suministrado por empresas como Nvidia.
Los modelos de peso abierto como DeepSeek-R1 están reduciendo los costes y obligando a las empresas de IA a replantearse sus estrategias de precios. Esto es evidente en el marcado contraste de precios:
Algunos líderes del sector han señalado la paradoja de Jevons: la idea de que, a medida que aumenta la eficiencia, el consumo global puede aumentar en lugar de disminuir. El consejero delegado de Microsoft, Satya Nadella lo insinuóargumentando que a medida que la IA se abarate, la demanda se disparará.
Sin embargo, me gustó esta visión equilibrada de The Economist, que sostiene que un efecto Jevons completo es muy raro y depende de si el precio es la principal barrera para la adopción. Dado que sólo "el 5% de las empresas estadounidenses utiliza actualmente la IA y el 7% tiene previsto adoptarla", el efecto de Jevons será probablemente escaso. Muchas empresas siguen considerando difícil o innecesaria la integración de la IA.
Además de su impacto perturbador, DeepSeek también se ha encontrado en el centro de la polémica. OpenAI ha acusado a DeepSeek de destilar sus modelos, es decir, de extraer conocimientos de los sistemas patentados de OpenAI y replicar su rendimiento en un modelo más compacto y eficiente.
Hasta ahora, OpenAI no ha aportado pruebas directas de esta afirmación y, para muchos, la acusación parece más bien un movimiento estratégico para tranquilizar a los inversores en medio del cambiante panorama de la IA.
El 28 de mayo de 2025, DeepSeek publicó una versión mejorada de su modelo de razonamiento: DeepSeek-R1-0528. Esta actualización introduce varias mejoras clave:
A pesar de estas adiciones, no hay cambios en los puntos finales de la API: DeepSeek-R1-0528 es totalmente compatible con versiones anteriores. Los programadores pueden seguir utilizando la misma interfaz, con las ventajas añadidas del nuevo modelo.
Puedes probarlo en la plataforma DeepSeek Chat o explorar las pesos de código abierto en Hugging Face.
Según la tabla de puntos de referencia que aparece en el anuncio de la versión, DeepSeek-R1-0528 supera a su predecesor y compite fuertemente con o3 de OpenAI y Gemini 2.5 Pro:
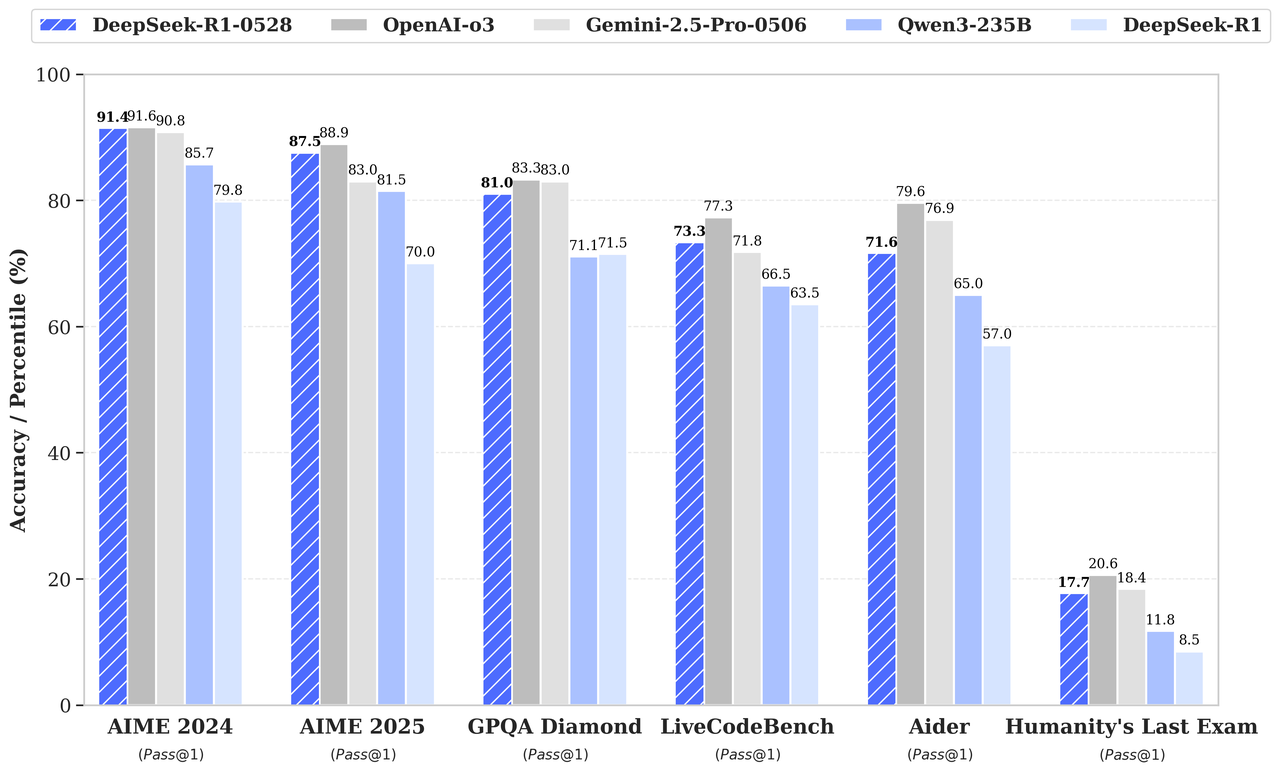
Fuente: DeepSeek
DeepSeek-R1 es un fuerte competidor en IA centrada en el razonamiento, con un rendimiento equiparable al de la o1 de OpenAI. Aunque la o1 de OpenAI podría tener una ligera ventaja en codificación y razonamiento factual, creo que la naturaleza de código abierto de DeepSeek-R1 y su acceso rentable la convierten en una opción atractiva.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Josep Ferrer
8 min
blog
Ryan Ong
8 min
blog
Richie Cotton
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
