
Cursus
Les fondamentaux du lama
4 h
En janvier 2025, DeepSeek a publié DeepSeek-R1l'étape suivante de son travail sur les modèles de raisonnement. Il s'agit d'une mise à niveau par rapport à l'ancien modèle DeepSeek-R1-Lite-Preview et montre que l'entreprise est sérieuse dans sa volonté de concurrencer l'offre de l'o1 d'OpenAI.
Depuis, DeepSeek a continué à améliorer le modèle. En mai 2025, ils ont publié DeepSeek-R1-0528, une version améliorée avec de meilleures performances, moins d'hallucinations et de nouvelles capacités comme l'appel de fonctions et la prise en charge de la sortie JSON.
Même si DeepSeek est légèrement en retrait par rapport à ses concurrents dans certains domaines, sa nature open-source et son prix nettement inférieur en font une option convaincante pour la communauté de l'IA.
Dans ce blog, je présenterai les principales caractéristiques de DeepSeek-R1, le processus de développement, les modèles distillés, la manière d'y accéder, le prix et la comparaison avec les modèles d'OpenAI.
J'ai écrit cet article le jour de la sortie de DeepSeek-R1, mais je l'ai maintenant mis à jour avec une nouvelle section couvrant ses conséquences - l'impact sur le marché boursier, l'économie de l'IA (y compris le paradoxe de Jevons et la banalisation des modèles d'IA), et l'accusation d'OpenAI selon laquelle DeepSeek a distillé ses modèles. J'ai également ajouté une section mise à jour sur le nouveau DeepSeek-R1-0528.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
DeepSeek-R1 est un modèle de raisonnement modèle de raisonnement développé par DeepSeek, une entreprise chinoise spécialisée dans l'IA, pour traiter les tâches nécessitant une inférence logique, la résolution de problèmes mathématiques et la prise de décision en temps réel.
Ce qui distingue les modèles de raisonnement tels que DeepSeek-R1 et OpenAI's o1 des modèles de langage traditionnels, c'est leur capacité à montrer comment ils sont arrivés à une conclusion.

Avec DeepSeek-R1, vous pouvez suivre sa logique, la rendre plus facile à comprendre et, si nécessaire, contester ses résultats. Cette capacité donne aux modèles de raisonnement un avantage dans les domaines où les résultats doivent pouvoir être expliqués, comme la recherche ou la prise de décision complexe.
Ce qui rend DeepSeek-R1 particulièrement compétitif et attrayant, c'est son caractère open-source. Contrairement aux modèles propriétaires, sa nature open-source permet aux développeurs et aux chercheurs de l'explorer, de le modifier et de le déployer dans certaines limites techniques, telles que les exigences en matière de ressources.
Dans cette section, je vais vous expliquer comment DeepSeek-R1 a été développé, en commençant par son prédécesseur, DeepSeek-R1-Zero.
DeepSeek-R1 a commencé avec R1-Zero, un modèle entièrement formé par l'apprentissage par renforcement. Cette approche lui a permis de développer de fortes capacités de raisonnement, mais elle présente des inconvénients majeurs. Les résultats étaient souvent difficiles à lire et le modèle mélangeait parfois les langues dans ses réponses. Ces limitations ont rendu R1-Zero moins pratique pour les applications réelles.
Le recours à l'apprentissage par renforcement pur a permis d'obtenir des résultats logiques mais mal structurés. Sans l'aide de données supervisées, le modèle a eu du mal à communiquer son raisonnement de manière efficace. Cela constituait un obstacle pour les utilisateurs qui avaient besoin de clarté et de précision dans les résultats.
Pour résoudre ces problèmes, DeepSeek a modifié le développement de R1 en combinant l'apprentissage par renforcement et la mise au point supervisée. Cette approche hybride a permis d'intégrer des ensembles de données conservées, améliorant ainsi la lisibilité et la cohérence du modèle. Les problèmes tels que le mélange des langues et le raisonnement fragmenté ont été considérablement réduits, ce qui rend le modèle plus adapté à une utilisation pratique.
Si vous voulez en savoir plus sur le développement de DeepSeek-R1, je vous recommande de lire le communiqué de presse.
La distillation dans l'IA est le processus de création de modèles plus petits et plus efficaces à partir de modèles plus grands, préservant une grande partie de leur pouvoir de raisonnement tout en réduisant les demandes de calcul. DeepSeek a appliqué cette technique pour créer une suite de modèles distillés à partir de R1, en utilisant les architectures Qwen et Llama.
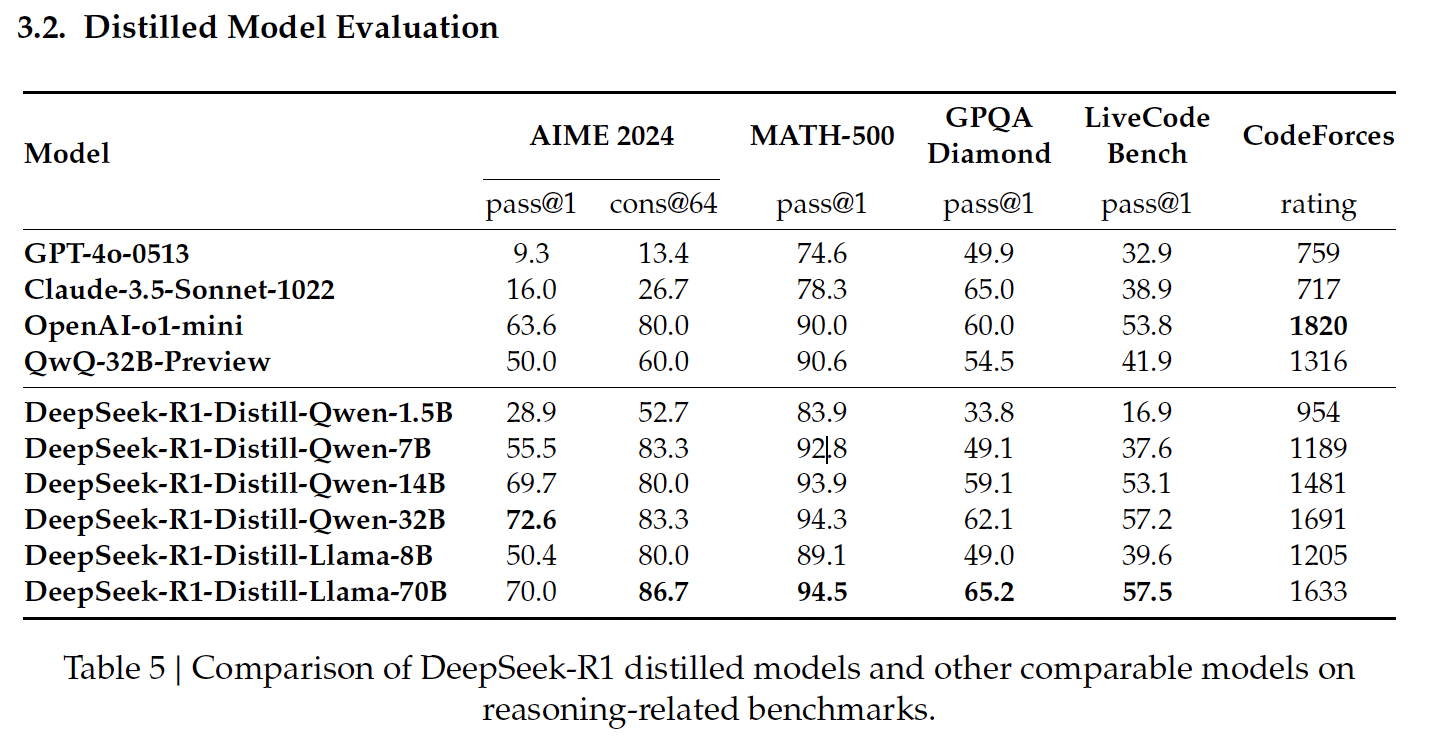
Source : Communiqué de presse de DeepSeek
Les modèles distillés de DeepSeek, basés sur Qwen, se concentrent sur l'efficacité et l'évolutivité, offrant un équilibre entre les performances et les exigences de calcul.
Il s'agit du plus petit modèle distillé, qui a obtenu 83,9 % à MATH-500. MATH-500 teste la capacité à résoudre des problèmes mathématiques de niveau secondaire avec un raisonnement logique et des solutions en plusieurs étapes. Ce résultat montre que le modèle gère bien les tâches mathématiques de base malgré sa taille compacte.
Cependant, ses performances chutent de manière significative sur LiveCodeBench (16,9 %), un test de référence conçu pour évaluer les capacités de codage, ce qui met en évidence ses capacités limitées dans les tâches de programmation.
Qwen-7B brille sur MATH-500, avec un score de 92,8 %, ce qui démontre ses fortes capacités de raisonnement mathématique. Il obtient également d'assez bons résultats au GPQA Diamond (49,1 %), qui évalue la réponse à des questions factuelles, ce qui indique un bon équilibre entre le raisonnement mathématique et le raisonnement factuel.
Toutefois, ses performances sur LiveCodeBench (37,6 %) et CodeForces (1189 points) suggèrent qu'il est moins adapté aux tâches de codage complexes.
Ce modèle obtient de bons résultats à MATH-500 (93,9 %), ce qui témoigne de sa capacité à traiter des problèmes mathématiques complexes. Son score de 59,1 % au GPQA Diamond indique également une compétence en matière de raisonnement factuel.
Ses performances sur LiveCodeBench (53,1 %) et CodeForces (1481 points) montrent qu'il y a une marge de progression pour les tâches de codage et de raisonnement spécifiques à la programmation.
Le plus grand modèle basé sur Qwen obtient le score le plus élevé parmi ses pairs sur AIME 2024 (72,6 %), qui évalue le raisonnement mathématique avancé en plusieurs étapes. Il excelle également en MATH-500 (94,3 %) et en GPQA Diamond (62,1 %), ce qui démontre sa force en matière de raisonnement mathématique et factuel.
Ses résultats sur LiveCodeBench (57,2 %) et CodeForces (1691 points) suggèrent qu'il est polyvalent mais qu'il n'est pas encore optimisé pour les tâches de programmation par rapport aux modèles spécialisés dans le codage.
Les modèles distillés de DeepSeek, basés sur le Llama, privilégient les performances élevées et les capacités de raisonnement avancées, excellant particulièrement dans les tâches nécessitant une précision mathématique et factuelle.
Le lama-8B obtient de bons résultats au MATH-500 (89,1 %) et des résultats raisonnables au GPQA Diamond (49,0 %), ce qui indique qu'il est capable de traiter des raisonnements mathématiques et factuels. Cependant, il obtient de moins bons résultats dans les tests de codage tels que LiveCodeBench (39,6 %) et CodeForces (note de 1205), ce qui souligne ses limites dans les tâches liées à la programmation par rapport aux modèles basés sur Qwen.
Le plus grand modèle distillé, Llama-70B, offre des performances de premier ordre sur MATH-500 (94,5 %), les meilleures parmi tous les modèles distillés, et obtient un score élevé de 86,7 % sur AIME 2024, ce qui en fait un excellent choix pour le raisonnement mathématique avancé.
Il obtient également de bons résultats sur LiveCodeBench (57,5 %) et CodeForces (1633 points), ce qui suggère qu'il est plus compétent dans les tâches de codage que la plupart des autres modèles. Dans ce domaine, il est au même niveau que l'o1-mini ou le GPT-4o d'OpenAI.
Vous pouvez accéder à DeepSeek-R1 par le biais de deux méthodes principales : la plateforme DeepSeek Chat basée sur le web et l'API DeepSeek, ce qui vous permet de choisir l'option qui correspond le mieux à vos besoins.
La plateforme DeepSeek Chat offre un moyen simple d'interagir avec DeepSeek-R1. Pour y accéder, vous pouvez soit vous rendre directement sur la page de chat ou cliquer sur Démarrer maintenant sur la page d'accueil.

Après vous être inscrit, vous pouvez sélectionner le mode "Deep Think" pour découvrir les capacités de raisonnement étape par étape de Deepseek-R1.
Pour intégrer DeepSeek-R1 dans vos applications, l'API DeepSeek fournit un accès programmatique.
Pour commencer, vous devez obtenir une clé API en vous inscrivant sur la plateforme DeepSeek.
L'API est compatible avec le format d'OpenAI, ce qui facilite l'intégration si vous êtes familiarisé avec les outils d'OpenAI. Vous pouvez trouver plus d'instructions sur la documentation API de DeepSeek.
Depuis mai 2025, l'utilisation de la plateforme de chat est gratuite pour le modèle R1.
L'API propose deux modèles :deepseek-chat (DeepSeek-V3) et deepseek-reasoner (DeepSeek-R1) - avec la structure de prix suivante (pour 1 million de jetons) :
|
MODÈLE |
LONGUEUR DU CONTEXTE |
MAX COT TOKENS |
NOMBRE MAXIMAL DE JETONS DE SORTIE |
1M TOKENS PRIX D'ENTRÉE (CACHE HIT) |
1M TOKENS PRIX D'ENTRÉE (CACHE MISS) |
1M TOKENS PRIX DE SORTIE |
|
deepseek-chat |
64K |
- |
8K |
$0.07 $0.014 |
$0.27 $0.14 |
$1.10 $0.28 |
|
deepseek-reasoner |
64K |
32K |
8K |
$0.14 |
$0.55 |
$2.19 |
Source : Page de tarification de DeepSeek
Pour vous assurer que vous disposez des informations tarifaires les plus récentes et comprendre comment calculer le coût du raisonnement CoT (Chain-of-Thought), visitez la page de tarification de DeepSeek.
DeepSeek-R1 est en concurrence directe avec OpenAI o1 sur plusieurs points de référence, égalant ou dépassant souvent OpenAI o1.
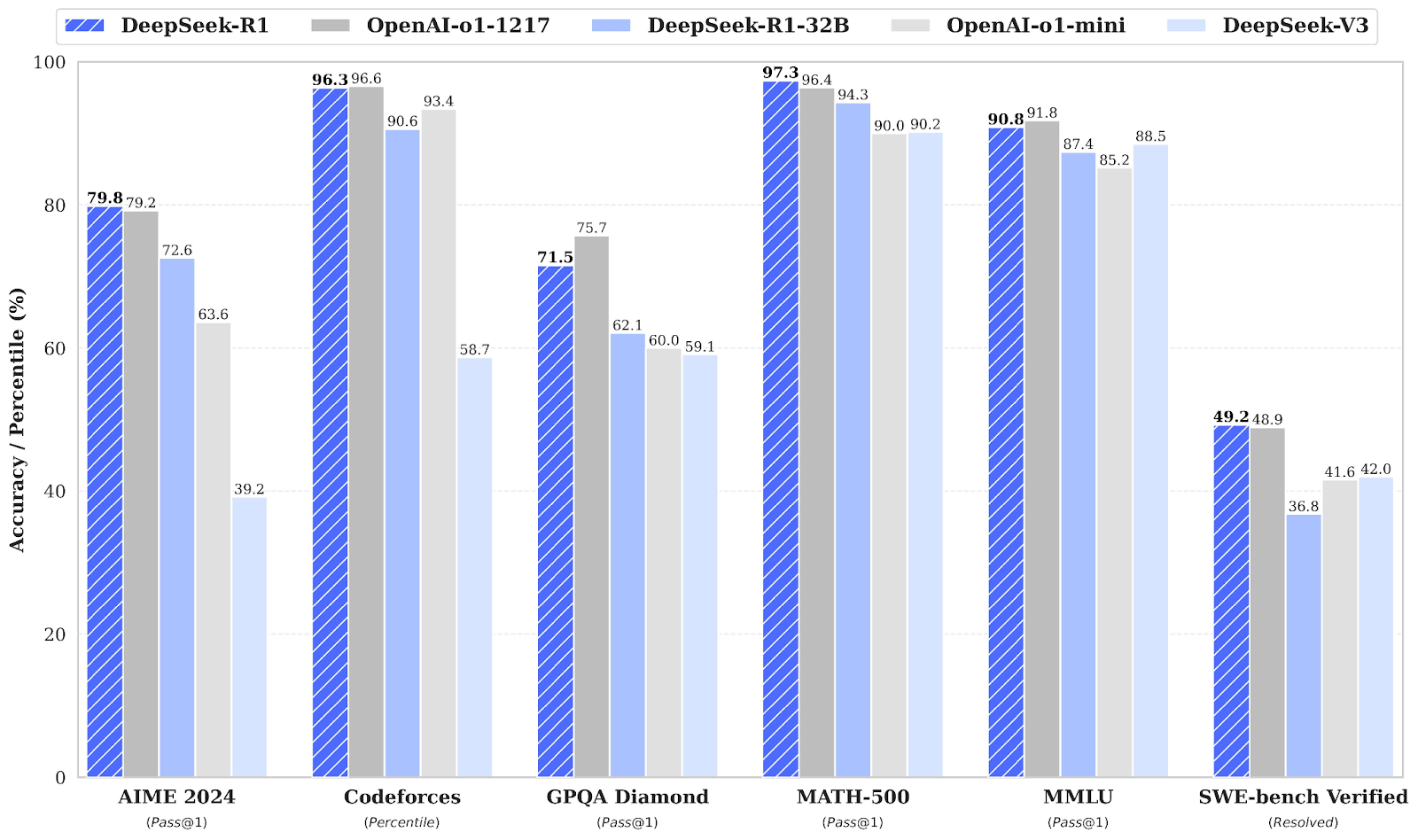
Source : Communiqué de presse de DeepSeek
Dans les tests mathématiques, DeepSeek-R1 fait preuve d'excellentes performances. Sur AIME 2024, qui évalue le raisonnement mathématique avancé à plusieurs étapes, DeepSeek-R1 obtient un score de 79,8 %, légèrement supérieur à celui d'OpenAI o1-1217, qui est de 79,2 %.
Sur MATH-500, DeepSeek-R1 prend la tête avec un score impressionnant de 97,3 %, dépassant légèrement OpenAI o1-1217 avec 96,4 %. Ce test de référence évalue les modèles sur divers problèmes mathématiques de niveau secondaire nécessitant un raisonnement détaillé.
Le benchmark Codeforces évalue les capacités de codage et de raisonnement algorithmique d'un modèle, sous la forme d'un classement par centile par rapport à des participants humains. OpenAI o1-1217 arrive en tête avec 96,6 %, tandis que DeepSeek-R1 obtient un résultat très compétitif de 96,3 %, avec seulement une différence mineure.
Le benchmark vérifié SWE-bench évalue le raisonnement dans les tâches d'ingénierie logicielle. DeepSeek-R1 obtient d'excellents résultats avec un score de 49,2 %, légèrement supérieur à celui d'OpenAI o1-1217 (48,9 %). Ce résultat positionne DeepSeek-R1 comme un concurrent de taille pour les tâches de raisonnement spécialisées telles que la vérification de logiciels.
Pour le raisonnement factuel, GPQA Diamond mesure la capacité à répondre à des questions de connaissances générales. DeepSeek-R1 obtient un score de 71,5 %, talonnant OpenAI o1-1217, qui atteint 75,7 %. Ce résultat met en évidence le léger avantage de l'OpenAI o1-1217 dans les tâches de raisonnement factuel.
Sur MMLU, un benchmark qui couvre plusieurs disciplines et évalue la compréhension du langage en multitâche, OpenAI o1-1217 devance légèrement DeepSeek-R1, avec un score de 91,8 % contre 90,8 % pour DeepSeek-R1.
La publication de Spark-R1 a eu des conséquences considérables, affectant les marchés boursiers, remodelant l'économie de l'IA et suscitant une controverse sur les pratiques de développement des modèles.
L'introduction par DeepSeek de son modèle R1, qui offre des capacités d'IA avancées pour une fraction du coût des concurrents, a entraîné une baisse substantielle du prix des actions des principales entreprises technologiques américaines.
Nvidia, par exemple, a vu sa valeur boursière chuter de près de 18 %, ce qui équivaut à une perte d'environ 600 milliards de dollars en termes de capitalisation boursière. Cette baisse s'explique par les inquiétudes des investisseurs, qui craignent que les modèles d'IA efficaces de DeepSeek ne réduisent la demande de matériel de haute performance. matériel de haute performance de haute performance, traditionnellement fourni par des entreprises comme Nvidia.
Les modèles à poids ouvert comme DeepSeek-R1 font baisser les coûts et obligent les entreprises d'IA à repenser leurs stratégies de tarification. Le contraste des prix en est la preuve :
Certains dirigeants du secteur ont évoqué le paradoxe de Jevons, à savoir que lorsque l'efficacité augmente, la consommation globale peut augmenter au lieu de diminuer. Le PDG de Microsoft, Satya Nadella l'a laissé entendreen affirmant qu'à mesure que l'IA deviendra moins chère, la demande explosera.
Cependant, j'ai apprécié ce point de vue équilibré de The Economist, qui affirme qu'un effet Jevons complet est très rare et dépend de la question de savoir si le prix est le principal obstacle à l'adoption. Avec seulement "5 % des entreprises américaines qui utilisent actuellement l'IA et 7 % qui prévoient de l'adopter", l'effet de Jevons sera probablement faible. De nombreuses entreprises considèrent encore l'intégration de l'IA comme difficile ou inutile.
Outre son impact perturbateur, DeepSeek s'est également retrouvé au centre d'une controverse. OpenAI a accusé DeepSeek de distiller ses modèles, c'est-à-dire d'extraire les connaissances des systèmes propriétaires d'OpenAI et de reproduire leurs performances dans un modèle plus compact et plus efficace.
Jusqu'à présent, OpenAI n'a fourni aucune preuve directe de cette affirmation et, pour beaucoup, l'accusation ressemble davantage à une manœuvre stratégique visant à rassurer les investisseurs dans le contexte de l'évolution du paysage de l'IA.
Le 28 mai 2025, DeepSeek a publié une version améliorée de son modèle de raisonnement : DeepSeek-R1-0528. Cette mise à jour apporte plusieurs améliorations importantes :
Malgré ces ajouts, il n'y a pas de changement dans les points de terminaison de l'API - DeepSeek-R1-0528 est entièrement rétrocompatible. Les développeurs peuvent continuer à utiliser la même interface, avec les avantages supplémentaires du nouveau modèle.
Vous pouvez l'essayer sur la plateforme DeepSeek Chat ou explorer les poids open-source sur Hugging Face.
Selon le tableau de référence figurant dans l'annonce de la version, DeepSeek-R1-0528 surpasse son prédécesseur et rivalise fortement avec o3 et Gemini 2.5 Pro d'OpenAI :
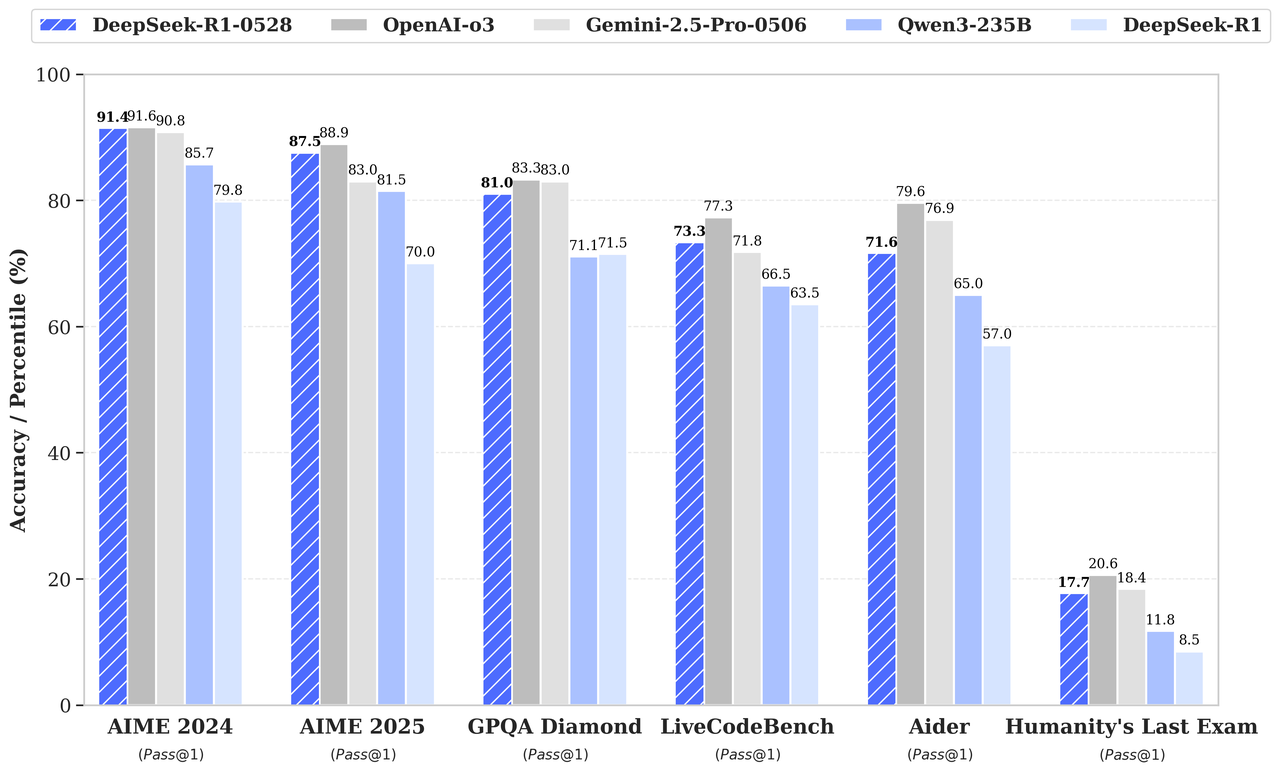
Source : DeepSeek
DeepSeek-R1 est un concurrent de taille dans le domaine de l'IA axée sur le raisonnement, avec des performances équivalentes à celles de o1 d'OpenAI. Bien que l'o1 d'OpenAI puisse avoir un léger avantage en matière de codage et de raisonnement factuel, je pense que la nature open-source et l'accès économique de DeepSeek-R1 en font une option attrayante.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree
