
Programa
Llama Fundamentals
4 h
Em janeiro de 2025, a DeepSeek lançou o DeepSeek-R1a próxima etapa de seu trabalho em modelos de raciocínio. É uma atualização de seu anterior DeepSeek-R1-Lite-Preview e mostra que eles estão levando a sério a concorrência com o o1 da OpenAI.
Desde então, o DeepSeek continuou a aprimorar o modelo. Em maio de 2025, eles lançaram o DeepSeek-R1-0528, uma versão atualizada com melhor desempenho de benchmark, menos alucinações e novos recursos, como chamada de função e suporte a saída JSON.
Embora o DeepSeek possa ficar um pouco atrás dos concorrentes em algumas áreas, sua natureza de código aberto e o preço significativamente mais baixo o tornam uma opção atraente para a comunidade de IA.
Neste blog, vou detalhar os principais recursos do DeepSeek-R1, o processo de desenvolvimento, os modelos destilados, como acessá-lo, o preço e como ele se compara aos modelos da OpenAI.
Escrevi este artigo originalmente no dia em que o DeepSeek-R1 foi lançado, mas agora o atualizei com uma nova seção que cobre as consequências - como ele impactou o mercado de ações, a economia da IA (incluindo o paradoxo de Jevons e a comoditização dos modelos de IA) e a acusação da OpenAI de que o DeepSeek destilou seus modelos. Também adicionei uma seção atualizada sobre o novo DeepSeek-R1-0528.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O DeepSeek-R1 é um modelo de raciocínio de código aberto modelo de raciocínio de código aberto desenvolvido pela DeepSeek, uma empresa chinesa de IA, para lidar com tarefas que exigem inferência lógica, solução de problemas matemáticos e tomada de decisões em tempo real.
O que diferencia os modelos de raciocínio como o DeepSeek-R1 e o o1 da OpenAI dos modelos de linguagem tradicionais é sua capacidade de mostrar como chegaram a uma conclusão.

Com o DeepSeek-R1, você pode seguir sua lógica, facilitando a compreensão e, se necessário, desafiando seu resultado. Esse recurso dá aos modelos de raciocínio uma vantagem em campos em que os resultados precisam ser explicáveis, como pesquisa ou tomada de decisões complexas.
O que torna o DeepSeek-R1 particularmente competitivo e atraente é sua natureza de código aberto. Ao contrário dos modelos proprietários, sua natureza de código aberto permite que os desenvolvedores e pesquisadores explorem, modifiquem e implantem o modelo dentro de certos limites técnicos, como requisitos de recursos.
Nesta seção, mostrarei a você como o DeepSeek-R1 foi desenvolvido, começando com seu antecessor, o DeepSeek-R1-Zero.
O DeepSeek-R1 começou com o R1-Zero, um modelo treinado inteiramente por meio de aprendizado por reforço. Embora essa abordagem tenha permitido que ele desenvolvesse fortes recursos de raciocínio, ela teve grandes desvantagens. Os resultados eram muitas vezes difíceis de ler, e o modelo às vezes misturava idiomas em suas respostas. Essas limitações tornaram o R1-Zero menos prático para aplicações no mundo real.
A confiança no aprendizado por reforço puro criou resultados que eram logicamente sólidos, mas mal estruturados. Sem a orientação de dados supervisionados, o modelo teve dificuldades para comunicar seu raciocínio de forma eficaz. Isso era uma barreira para os usuários que precisavam de clareza e precisão nos resultados.
Para resolver esses problemas, o DeepSeek fez uma alteração no desenvolvimento do R1, combinando o aprendizado por reforço com o ajuste fino supervisionado. Essa abordagem híbrida incorporou conjuntos de dados com curadoria, melhorando a legibilidade e a coerência do modelo. Problemas como mistura de idiomas e raciocínio fragmentado foram significativamente reduzidos, tornando o modelo mais adequado para uso prático.
Se você quiser saber mais sobre o desenvolvimento do DeepSeek-R1, recomendo a leitura do documento de lançamento.
Destilação em IA é o processo de criação de modelos menores e mais eficientes a partir de modelos maiores, preservando grande parte de seu poder de raciocínio e reduzindo as demandas computacionais. O DeepSeek aplicou essa técnica para criar um conjunto de modelos destilados do R1, usando as arquiteturas Qwen e Llama.
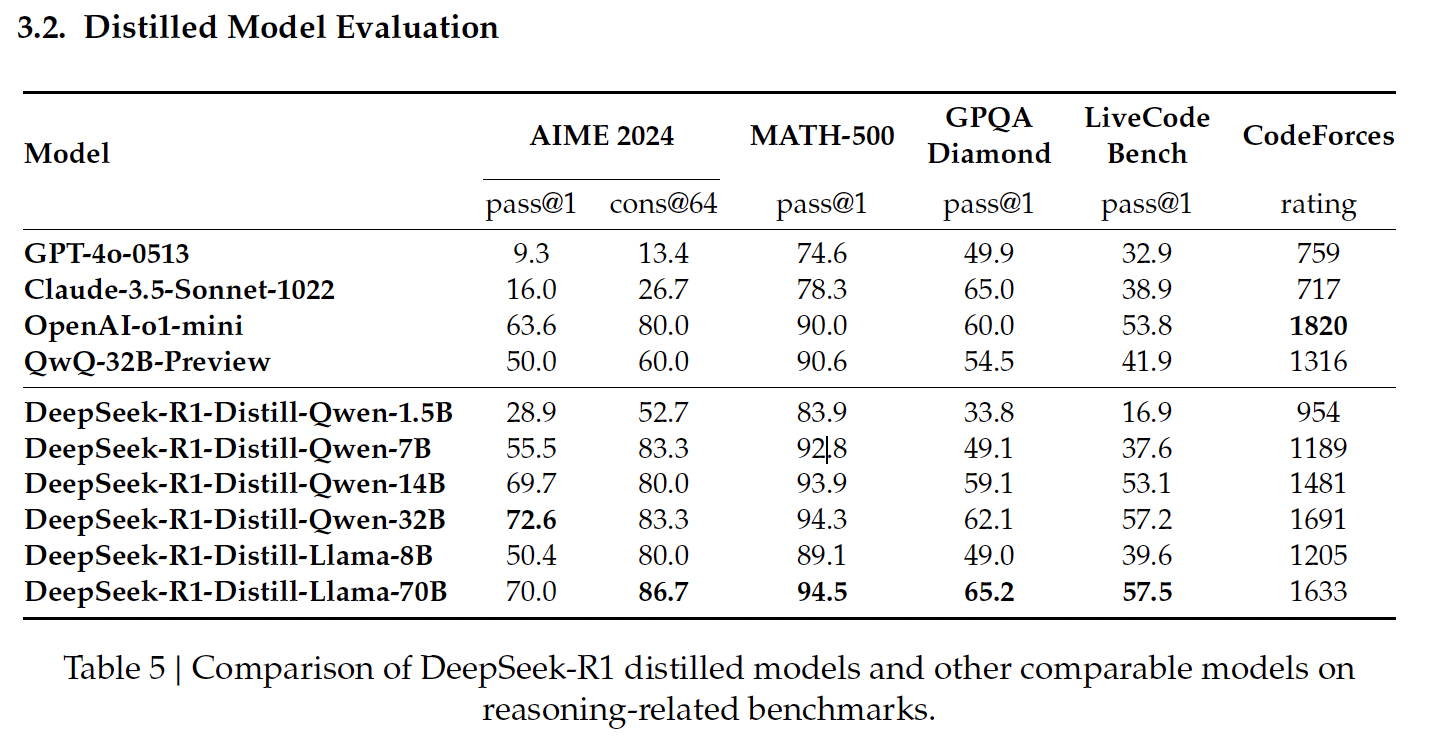
Fonte: Documento de lançamento do DeepSeek
Os modelos destilados baseados em Qwen do DeepSeek se concentram na eficiência e no dimensionamento, oferecendo um equilíbrio entre o desempenho e os requisitos computacionais.
Esse é o menor modelo destilado, com 83,9% de acerto no MATH-500. O MATH-500 testa a capacidade de resolver problemas matemáticos de nível de ensino médio com raciocínio lógico e soluções em várias etapas. Esse resultado mostra que o modelo lida bem com tarefas matemáticas básicas, apesar de seu tamanho compacto.
No entanto, seu desempenho cai significativamente no LiveCodeBench (16,9%), um benchmark criado para avaliar as habilidades de codificação, destacando sua capacidade limitada em tarefas de programação.
O Qwen-7B se destaca no MATH-500, com uma pontuação de 92,8%, o que demonstra sua forte capacidade de raciocínio matemático. Ele também tem um desempenho razoavelmente bom no GPQA Diamond (49,1%), que avalia a resposta a perguntas factuais, indicando que ele tem um bom equilíbrio entre o raciocínio matemático e o factual.
No entanto, seu desempenho no LiveCodeBench (37,6%) e no CodeForces (classificação de 1189) sugere que ele é menos adequado para tarefas de codificação complexas.
Esse modelo tem um bom desempenho no MATH-500 (93,9%), o que reflete sua capacidade de lidar com problemas matemáticos complexos. Sua pontuação de 59,1% no GPQA Diamond também indica competência em raciocínio factual.
Seu desempenho no LiveCodeBench (53,1%) e no CodeForces (classificação de 1481) mostra espaço para crescimento em tarefas de raciocínio específicas de codificação e programação.
O maior modelo baseado em Qwen atinge a pontuação mais alta entre seus pares no AIME 2024 (72,6%), que avalia o raciocínio matemático avançado em várias etapas. Ele também se destaca no MATH-500 (94,3%) e no GPQA Diamond (62,1%), demonstrando sua força no raciocínio matemático e factual.
Seus resultados no LiveCodeBench (57,2%) e no CodeForces (classificação de 1691) sugerem que ele é versátil, mas ainda não foi otimizado para tarefas de programação em comparação com modelos especializados em codificação.
Os modelos destilados baseados em Llama do DeepSeek priorizam o alto desempenho e os recursos avançados de raciocínio, destacando-se particularmente em tarefas que exigem precisão matemática e factual.
O Llama-8B tem bom desempenho no MATH-500 (89,1%) e razoável no GPQA Diamond (49,0%), indicando sua capacidade de lidar com raciocínio matemático e factual. No entanto, sua pontuação é menor em benchmarks de codificação, como o LiveCodeBench (39,6%) e o CodeForces (classificação 1205), o que destaca suas limitações em tarefas relacionadas à programação em comparação com os modelos baseados em Qwen.
O maior modelo destilado, o Llama-70B, oferece um desempenho de alto nível no MATH-500 (94,5%), o melhor entre todos os modelos destilados, e obtém uma pontuação forte de 86,7% no AIME 2024, o que o torna uma excelente opção para raciocínio matemático avançado.
Ele também tem bom desempenho no LiveCodeBench (57,5%) e no CodeForces (classificação de 1633), sugerindo que é mais competente em tarefas de codificação do que a maioria dos outros modelos. Nesse domínio, ele está no mesmo nível do o1-mini ou do GPT-4o da OpenAI.
Você pode acessar o DeepSeek-R1 por meio de dois métodos principais: a plataforma de bate-papo do DeepSeek baseada na Web e a API do DeepSeek, permitindo que você escolha a opção que melhor atenda às suas necessidades.
A plataforma DeepSeek Chat oferece uma maneira direta de você interagir com o DeepSeek-R1. Para acessá-lo, você pode ir diretamente para a página de bate-papo ou clicar em Iniciar agora na página inicial.

Depois de se registrar, você pode selecionar o modo "Deep Think" para experimentar os recursos de raciocínio passo a passo do Deepseek-R1.
Para integrar o DeepSeek-R1 em seus aplicativos, a API do DeepSeek fornece acesso programático.
Para começar, você precisará obter uma chave de API registrando-se na Plataforma DeepSeek.
A API é compatível com o formato da OpenAI, tornando a integração simples se você estiver familiarizado com as ferramentas da OpenAI. Você pode encontrar mais instruções na Documentação da API do DeepSeek.
Desde maio de 2025, a plataforma de bate-papo é gratuita para uso com o modelo R1.
A API oferece dois modelos:deepseek-chat (DeepSeek-V3) e deepseek-reasoner (DeepSeek-R1) - com a seguinte estrutura de preços (por 1 milhão de tokens):
|
MODELO |
COMPRIMENTO DO CONTEXTO |
MAX COT TOKENS |
MÁXIMO DE TOKENS DE SAÍDA |
1 MILHÃO DE FICHAS PREÇO DE ENTRADA (CACHE HIT) |
1 MILHÃO DE FICHAS PREÇO DE ENTRADA (CACHE MISS) |
1 MILHÃO DE FICHAS PREÇO DE SAÍDA |
|
deepseek-chat |
64K |
- |
8K |
$0.07 $0.014 |
$0.27 $0.14 |
$1.10 $0.28 |
|
deepseek-reasoner |
64K |
32K |
8K |
$0.14 |
$0.55 |
$2.19 |
Fonte: Página de preços do DeepSeek
Para garantir que você tenha as informações de preço mais atualizadas e entenda como calcular o custo do raciocínio CoT (Chain-of-Thought), visite a página de preços do DeepSeek.
O DeepSeek-R1 compete diretamente com o OpenAI o1 em vários benchmarks, muitas vezes igualando ou superando o o1 do OpenAI.
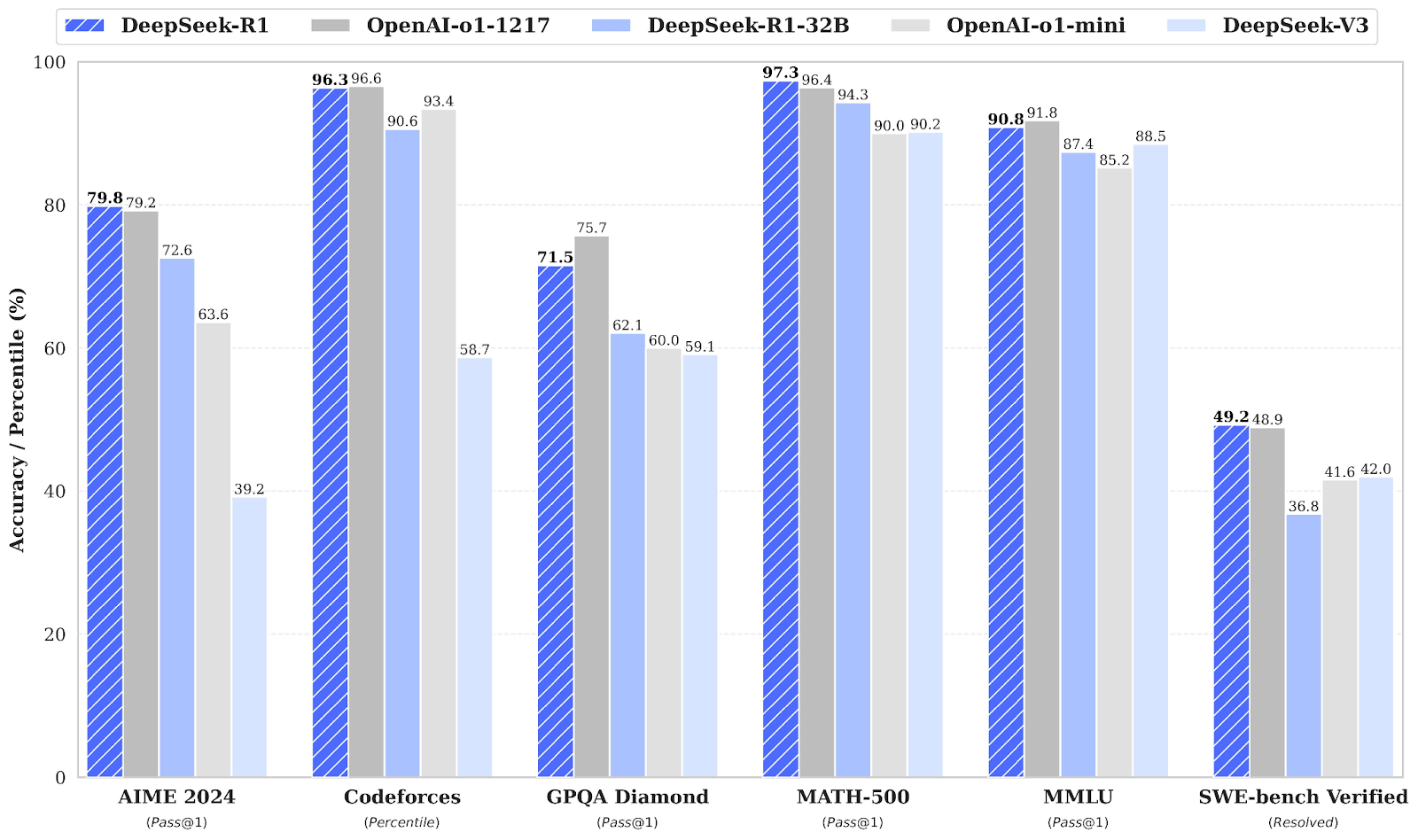
Fonte: Documento de lançamento do DeepSeek
Em benchmarks de matemática, o DeepSeek-R1 demonstra um bom desempenho. No AIME 2024, que avalia o raciocínio matemático avançado em várias etapas, o DeepSeek-R1 obteve 79,8% de pontuação, um pouco à frente do OpenAI o1-1217, com 79,2%.
No MATH-500, o DeepSeek-R1 assume a liderança com impressionantes 97,3%, superando ligeiramente o OpenAI o1-1217 com 96,4%. Esse benchmark testa modelos em diversos problemas matemáticos de nível de ensino médio que exigem raciocínio detalhado.
O benchmark Codeforces avalia os recursos de codificação e raciocínio algorítmico de um modelo, representados como uma classificação percentual em relação aos participantes humanos. O OpenAI o1-1217 lidera com 96,6%, enquanto o DeepSeek-R1 alcança 96,3% muito competitivo, com apenas uma pequena diferença.
O benchmark SWE-bench Verified avalia o raciocínio em tarefas de engenharia de software. O DeepSeek-R1 tem um bom desempenho com uma pontuação de 49,2%, um pouco à frente dos 48,9% do OpenAI o1-1217. Esse resultado posiciona o DeepSeek-R1 como um forte concorrente em tarefas de raciocínio especializadas, como a verificação de software.
Para o raciocínio factual, o GPQA Diamond mede a capacidade de responder a perguntas de conhecimento de propósito geral. O DeepSeek-R1 obteve uma pontuação de 71,5%, ficando atrás do OpenAI o1-1217, que atingiu 75,7%. Esse resultado destaca a pequena vantagem da OpenAI o1-1217 em tarefas de raciocínio factual.
No MMLU, um parâmetro de comparação que abrange várias disciplinas e avalia a compreensão de idiomas em várias tarefas, o OpenAI o1-1217 supera ligeiramente o DeepSeek-R1, com uma pontuação de 91,8% em comparação com os 90,8% do DeepSeek-R1.
O lançamento do DeepSeek-R1 teve consequências de longo alcance, afetando os mercados de ações, reformulando a economia da IA e gerando controvérsias sobre as práticas de desenvolvimento de modelos.
A introdução do modelo R1 da DeepSeek, que oferece recursos avançados de IA por uma fração do custo dos concorrentes, levou a uma queda substancial nos preços das ações das principais empresas de tecnologia dos EUA.
A Nvidia, por exemplo, sofreu uma queda de quase 18% no valor de suas ações, o que equivale a uma perda de aproximadamente US$ 600 bilhões em capitalização de mercado. Essa queda foi motivada por preocupações dos investidores de que os modelos eficientes de IA da DeepSeek poderiam reduzir a demanda por hardware de alto desempenho tradicionalmente fornecido por empresas como a Nvidia.
Modelos de peso aberto, como o DeepSeek-R1, estão reduzindo os custos e forçando as empresas de IA a repensar suas estratégias de preços. Isso fica evidente no forte contraste de preços:
Alguns líderes do setor apontaram o paradoxo de Jevons - a ideia de que, à medida que a eficiência aumenta, o consumo geral pode aumentar em vez de diminuir. O CEO da Microsoft, Satya Nadella deu a entender issoargumentando que, à medida que a IA ficar mais barata, a demanda explodirá.
No entanto, eu gostei desta visão equilibrada da The Economist, que argumenta que um efeito Jevons completo é muito raro e depende do fato de o preço ser a principal barreira à adoção. Com apenas "5% das empresas americanas usando IA atualmente e 7% planejando adotá-la", o efeito de Jevons provavelmente será baixo. Muitas empresas ainda consideram a integração da IA difícil ou desnecessária.
Além de seu impacto disruptivo, o DeepSeek também se encontra no centro de controvérsias. A OpenAI acusou a DeepSeek de destilar seus modelos - essencialmente extraindo conhecimento dos sistemas proprietários da OpenAI e replicando seu desempenho em um modelo mais compacto e eficiente.
Até o momento, a OpenAI não forneceu nenhuma evidência direta para essa alegação e, para muitos, a acusação parece mais um movimento estratégico para tranquilizar os investidores em meio ao cenário mutável da IA.
Em 28 de maio de 2025, o DeepSeek lançou uma versão atualizada de seu modelo de raciocínio: DeepSeek-R1-0528. Essa atualização apresenta vários aprimoramentos importantes:
Apesar dessas adições, não há alteração nos pontos de extremidade da API - o DeepSeek-R1-0528 é totalmente compatível com as versões anteriores. Os desenvolvedores podem continuar usando a mesma interface, com os benefícios adicionais do novo modelo.
Você pode experimentá-lo na plataforma do DeepSeek Chat ou explorar os pesos de código aberto no Hugging Face.
De acordo com o gráfico de benchmark no anúncio de lançamento, o DeepSeek-R1-0528 supera seu antecessor e compete fortemente com o o3 da OpenAI e o Gemini 2.5 Pro:
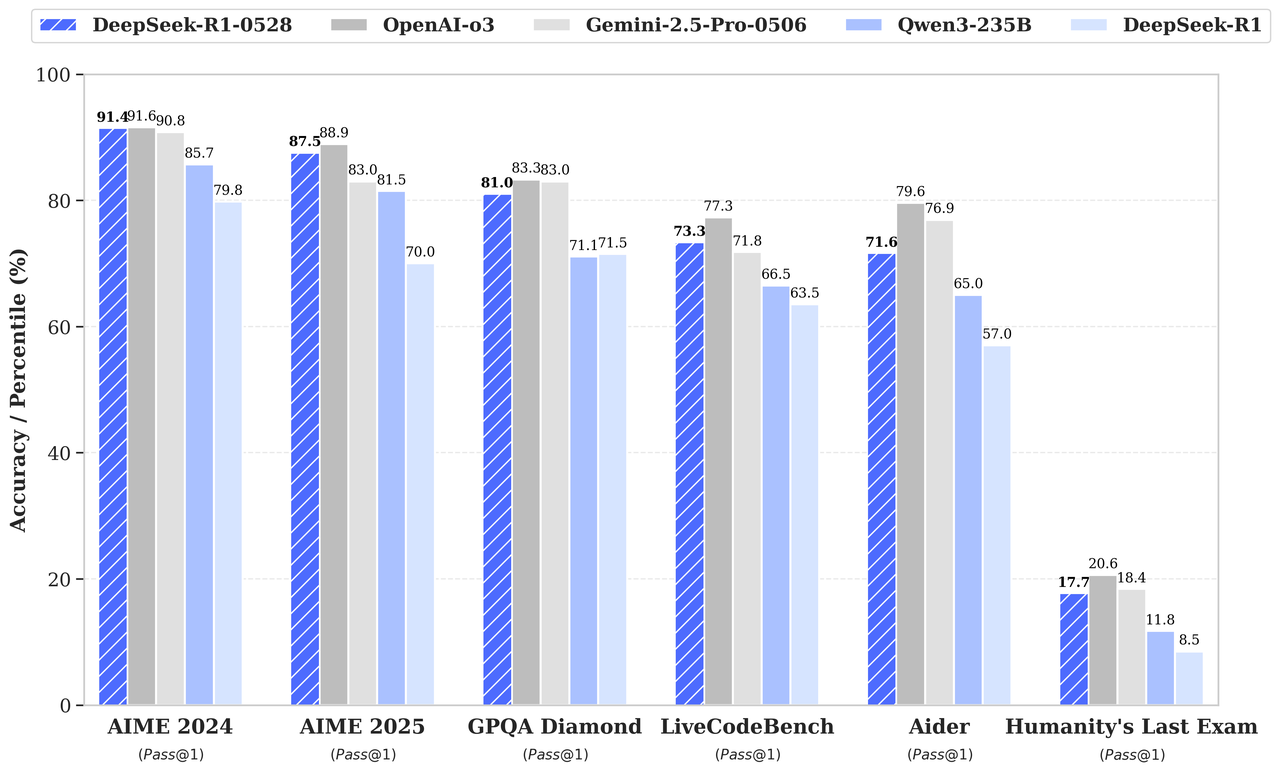
Fonte: DeepSeek
O DeepSeek-R1 é um forte concorrente na IA voltada para o raciocínio, com desempenho equivalente ao do o1 da OpenAI. Embora o o1 da OpenAI possa ter uma pequena vantagem em termos de codificação e raciocínio factual, acho que a natureza de código aberto e o acesso econômico do DeepSeek-R1 o tornam uma opção atraente.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Richie Cotton
7 min
blog
Richie Cotton
8 min
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer


