
Track
Llama Fundamentals
4 hr
In January 2025, DeepSeek released DeepSeek-R1, the next step in their work on reasoning models. It’s an upgrade from their earlier DeepSeek-R1-Lite-Preview and shows they’re serious about competing with OpenAI’s o1.
Since then, DeepSeek has continued to improve the model. In May 2025, they released DeepSeek-R1-0528, an upgraded version with better benchmark performance, fewer hallucinations, and new capabilities like function calling and JSON output support.
Even though DeepSeek may lag slightly behind competitors in some areas, its open-source nature and significantly lower pricing make it a compelling option for the AI community.
In this blog, I’ll break down DeepSeek-R1’s key features, development process, distilled models, how to access it, pricing, and how it compares to OpenAI’s models.
I originally wrote this article on the day DeepSeek-R1 was released, but I’ve now updated it with a new section covering its aftermath—how it impacted the stock market, the economics of AI (including Jevons’ paradox and the commoditization of AI models), and OpenAI’s accusation that DeepSeek distilled their models. I've also added an updated section on the new DeepSeek-R1-0528.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
DeepSeek-R1 is an open-source reasoning model developed by DeepSeek, a Chinese AI company, to address tasks requiring logical inference, mathematical problem-solving, and real-time decision-making.
What sets reasoning models like DeepSeek-R1 and OpenAI’s o1 apart from traditional language models is their ability to show how they arrived at a conclusion.

With DeepSeek-R1, you can follow its logic, making it easier to understand and, if necessary, challenge its output. This capability gives reasoning models an edge in fields where outcomes need to be explainable, like research or complex decision-making.
What makes DeepSeek-R1 particularly competitive and attractive is its open-source nature. Unlike proprietary models, its open-source nature allows developers and researchers to explore, modify, and deploy it within certain technical limits, such as resource requirements.
In this section, I’ll walk you through how DeepSeek-R1 was developed, starting with its predecessor, DeepSeek-R1-Zero.
DeepSeek-R1 began with R1-Zero, a model trained entirely through reinforcement learning. While this approach allowed it to develop strong reasoning capabilities, it came with major drawbacks. The outputs were often difficult to read, and the model sometimes mixed languages within its responses. These limitations made R1-Zero less practical for real-world applications.
The reliance on pure reinforcement learning created outputs that were logically sound but poorly structured. Without the guidance of supervised data, the model struggled to communicate its reasoning effectively. This was a barrier for users who needed clarity and precision in the results.
To address these issues, DeepSeek made a change in R1’s development by combining reinforcement learning with supervised fine-tuning. This hybrid approach incorporated curated datasets, improving the model’s readability and coherence. Problems like language mixing and fragmented reasoning were significantly reduced, making the model more suitable for practical use.
If you want to learn more about the development of DeepSeek-R1, I recommend reading the release paper.
Distillation in AI is the process of creating smaller, more efficient models from larger ones, preserving much of their reasoning power while reducing computational demands. DeepSeek applied this technique to create a suite of distilled models from R1, using Qwen and Llama architectures.
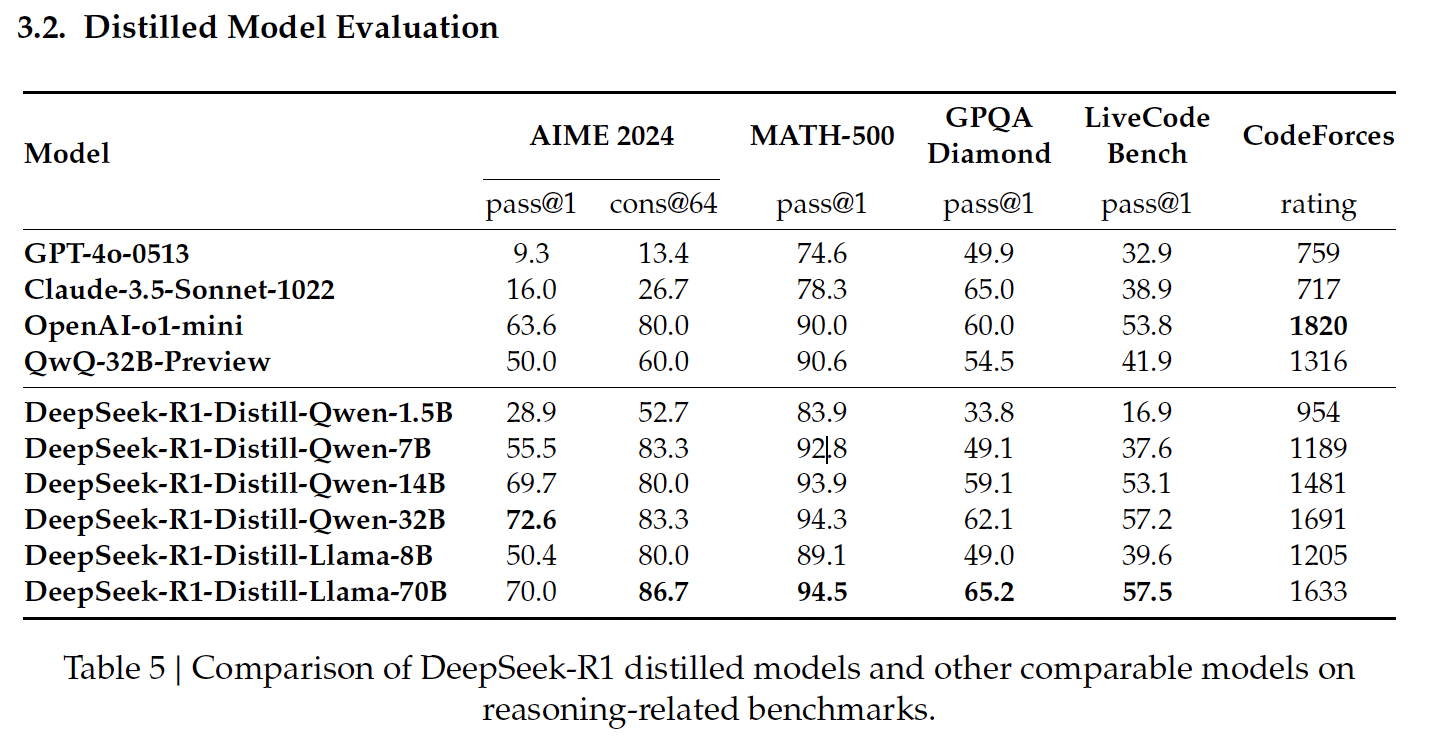
Source: DeepSeek’s release paper
DeepSeek’s Qwen-based distilled models focus on efficiency and scalability, offering a balance between performance and computational requirements.
This is the smallest distilled model, achieving 83.9% on MATH-500. MATH-500 tests the ability to solve high-school-level mathematical problems with logical reasoning and multi-step solutions. This result shows that the model handles basic mathematical tasks well despite its compact size.
However, its performance drops significantly on LiveCodeBench (16.9%), a benchmark designed to assess coding abilities, highlighting its limited capability in programming tasks.
Qwen-7B shines on MATH-500, scoring 92.8%, which demonstrates its strong mathematical reasoning capabilities. It also performs reasonably well on GPQA Diamond (49.1%), which evaluates factual question answering, indicating it has a good balance between mathematical and factual reasoning.
However, its performance on LiveCodeBench (37.6%) and CodeForces (1189 rating) suggests it is less suited for complex coding tasks.
This model performs well on MATH-500 (93.9%), reflecting its ability to handle complex mathematical problems. Its 59.1% score on GPQA Diamond also indicates competence in factual reasoning.
Its performance on LiveCodeBench (53.1%) and CodeForces (1481 rating) shows room for growth in coding and programming-specific reasoning tasks.
The largest Qwen-based model achieves the highest score among its peers on AIME 2024 (72.6%), which evaluates advanced multi-step mathematical reasoning. It also excels on MATH-500 (94.3%) and GPQA Diamond (62.1%), demonstrating its strength in both mathematical and factual reasoning.
Its results on LiveCodeBench (57.2%) and CodeForces (1691 rating) suggest it is versatile but still not optimized for programming tasks compared to models specialized in coding.
DeepSeek’s Llama-based distilled models prioritize high performance and advanced reasoning capabilities, particularly excelling in tasks requiring mathematical and factual precision.
Llama-8B performs well on MATH-500 (89.1%) and reasonably on GPQA Diamond (49.0%), indicating its ability to handle mathematical and factual reasoning. However, it scores lower on coding benchmarks like LiveCodeBench (39.6%) and CodeForces (1205 rating), which highlights its limitations in programming-related tasks compared to Qwen-based models.
The largest distilled model, Llama-70B, delivers top-tier performance on MATH-500 (94.5%), the best among all distilled models, and achieves a strong score of 86.7% on AIME 2024, making it an excellent choice for advanced mathematical reasoning.
It also performs well on LiveCodeBench (57.5%) and CodeForces (1633 rating), suggesting it is more competent in coding tasks than most other models. In this domain, it’s on par with OpenAI’s o1-mini or GPT-4o.
You can access DeepSeek-R1 through two primary methods: the web-based DeepSeek Chat platform and the DeepSeek API, allowing you to choose the option that best fits your needs.
The DeepSeek Chat platform offers a straightforward way to interact with DeepSeek-R1. To access it, you can either go directly to the chat page or click Start Now on the home page.

After registering, you can select the “Deep Think” mode to experience Deepseek-R1’s step-by-step reasoning capabilities.
For integrating DeepSeek-R1 into your applications, the DeepSeek API provides programmatic access.
To get started, you’ll need to obtain an API key by registering on the DeepSeek Platform.
The API is compatible with OpenAI’s format, making integration straightforward if you’re familiar with OpenAI’s tools. You can find more instructions on DeepSeek’s API documentation.
As of May 2025, the chat platform is free to use with the R1 model.
The API offers two models—deepseek-chat (DeepSeek-V3) and deepseek-reasoner (DeepSeek-R1)—with the following pricing structure (per 1M tokens):
|
MODEL |
CONTEXT LENGTH |
MAX COT TOKENS |
MAX OUTPUT TOKENS |
1M TOKENS INPUT PRICE (CACHE HIT) |
1M TOKENS INPUT PRICE (CACHE MISS) |
1M TOKENS OUTPUT PRICE |
|
deepseek-chat |
64K |
- |
8K |
$0.07 $0.014 |
$0.27 $0.14 |
$1.10 $0.28 |
|
deepseek-reasoner |
64K |
32K |
8K |
$0.14 |
$0.55 |
$2.19 |
Source: DeepSeek’s pricing page
To ensure you have the most up-to-date pricing information and understand how to calculate the cost of CoT (Chain-of-Thought) reasoning, visit DeepSeek’s pricing page.
DeepSeek-R1 competes directly with OpenAI o1 across several benchmarks, often matching or surpassing OpenAI’s o1.
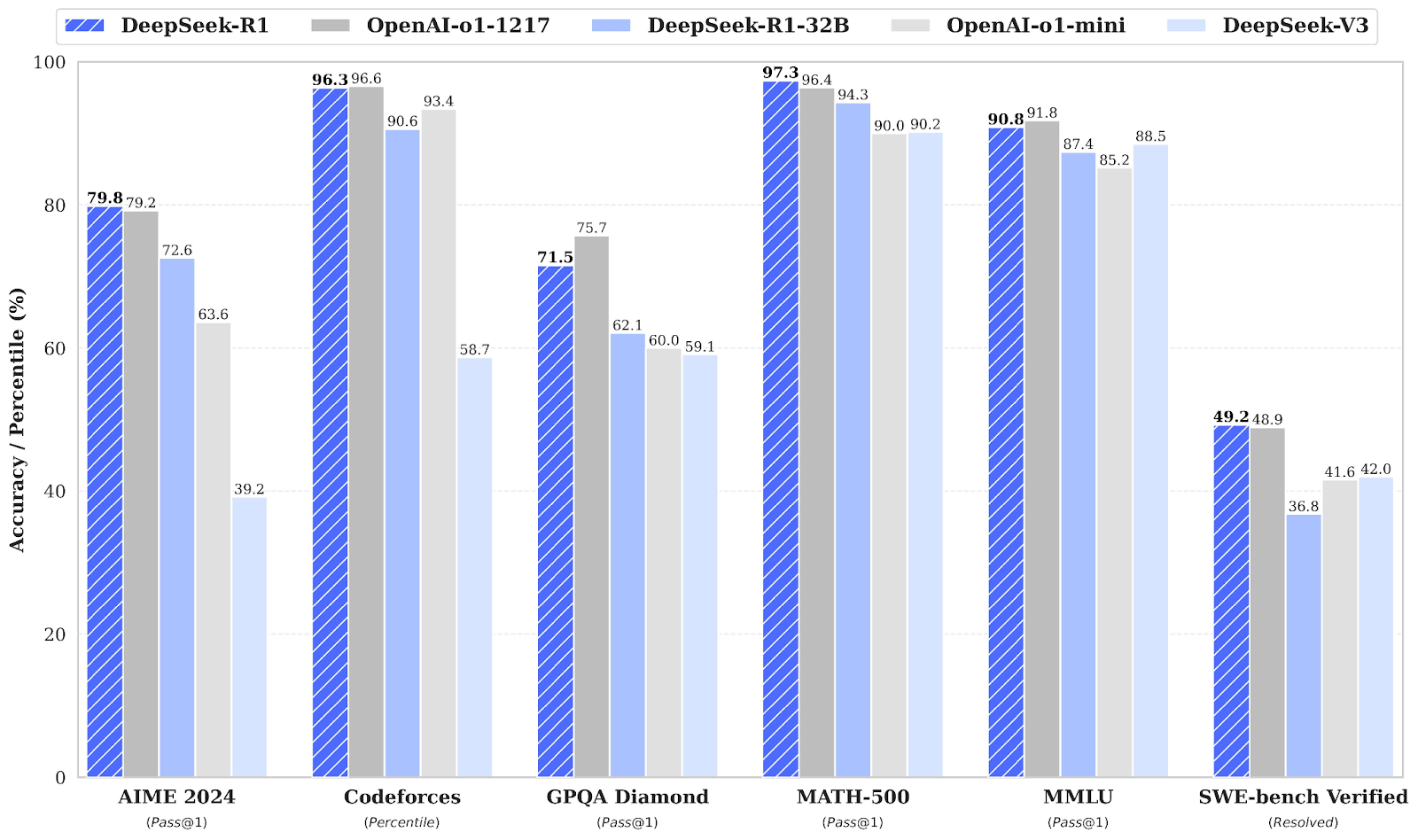
Source: DeepSeek’s release paper
In mathematics benchmarks, DeepSeek-R1 demonstrates strong performance. On AIME 2024, which evaluates advanced multi-step mathematical reasoning, DeepSeek-R1 scores 79.8%, slightly ahead of OpenAI o1-1217 at 79.2%.
On MATH-500, DeepSeek-R1 takes the lead with an impressive 97.3%, slightly surpassing OpenAI o1-1217 at 96.4%. This benchmark tests models on diverse high-school-level mathematical problems requiring detailed reasoning.
The Codeforces benchmark evaluates a model’s coding and algorithmic reasoning capabilities, represented as a percentile ranking against human participants. OpenAI o1-1217 leads with 96.6%, while DeepSeek-R1 achieves a very competitive 96.3%, with only a minor difference.
The SWE-bench Verified benchmark evaluates reasoning in software engineering tasks. DeepSeek-R1 performs strongly with a score of 49.2%, slightly ahead of OpenAI o1-1217’s 48.9%. This result positions DeepSeek-R1 as a strong contender in specialized reasoning tasks like software verification.
For factual reasoning, GPQA Diamond measures the ability to answer general-purpose knowledge questions. DeepSeek-R1 scores 71.5%, trailing OpenAI o1-1217, which achieves 75.7%. This result highlights OpenAI o1-1217’s slight advantage in factual reasoning tasks.
On MMLU, a benchmark that spans various disciplines and evaluates multitask language understanding, OpenAI o1-1217 slightly edges out DeepSeek-R1, scoring 91.8% compared to DeepSeek-R1’s 90.8%.
The release of DeepSeek-R1 has had far-reaching consequences, affecting stock markets, reshaping AI economics, and sparking controversy over model development practices.
DeepSeek’s introduction of its R1 model, which offers advanced AI capabilities at a fraction of the cost of competitors, led to a substantial decline in the stock prices of major U.S. tech companies.
Nvidia, for instance, experienced a nearly 18% drop in its stock value, equating to a loss of approximately $600 billion in market capitalization. This decline was driven by investor concerns that DeepSeek’s efficient AI models could reduce the demand for high-performance hardware traditionally supplied by companies like Nvidia.
Open-weight models like DeepSeek-R1 are lowering costs and forcing AI companies to rethink their pricing strategies. This is evident in the stark pricing contrast:
Some industry leaders have pointed to Jevons’ paradox—the idea that as efficiency increases, overall consumption can rise rather than fall. Microsoft CEO Satya Nadella hinted at this, arguing that as AI gets cheaper, demand will explode.
However, I liked this balanced view from The Economist, which argues that a full Jevons effect is very rare and depends on whether price is the main barrier to adoption. With only “5% of American firms currently using AI and 7% planning to adopt it”, Jevons’ effect will probably be low. Many businesses still find AI integration difficult or unnecessary.
Alongside its disruptive impact, DeepSeek has also found itself at the center of controversy. OpenAI has accused DeepSeek of distilling its models—essentially extracting knowledge from OpenAI’s proprietary systems and replicating their performance in a more compact, efficient model.
So far, OpenAI has provided no direct evidence for this claim, and to many, the accusation looks more like a strategic move to reassure investors amid the shifting AI landscape.
On May 28, 2025, DeepSeek released an upgraded version of its reasoning model: DeepSeek-R1-0528. This update introduces several key improvements:
Despite these additions, there’s no change to the API endpoints—DeepSeek-R1-0528 is fully backward-compatible. Developers can continue using the same interface, with the added benefits of the new model.
You can try it on the DeepSeek Chat platform or explore the open-source weights on Hugging Face.
According to the benchmark chart in the release announcement, DeepSeek-R1-0528 outperforms its predecessor and competes strongly with OpenAI’s o3 and Gemini 2.5 Pro:
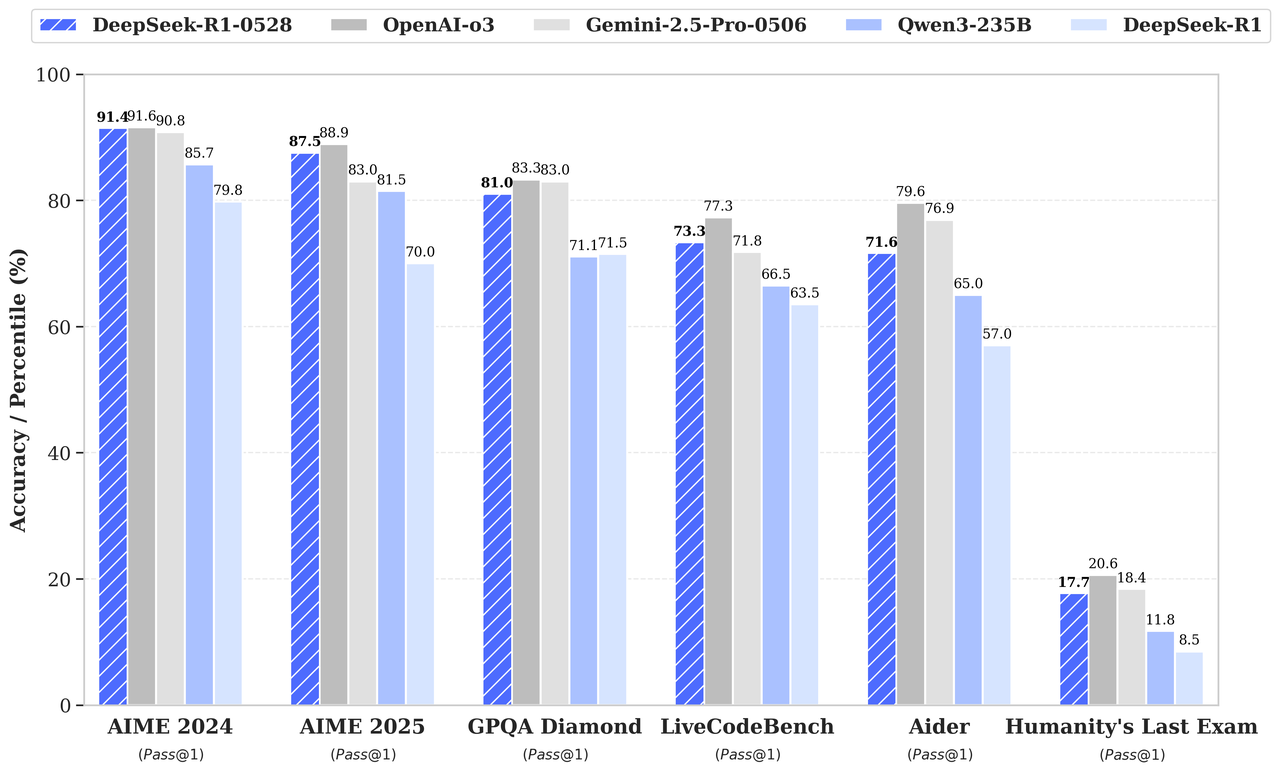
Source: DeepSeek
DeepSeek-R1 is a strong competitor in reasoning-focused AI, performing on par with OpenAI’s o1. While OpenAI’s o1 might have a slight edge in coding and factual reasoning, I think DeepSeek-R1’s open-source nature and cost-efficient access make it an appealing option.
Learn AI with these courses!
Track
Course
Course
blog
Vinod Chugani
7 min
blog
François Aubry
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min


