
programa
Ingeniero de Datos Profesional en Python
40 h
Los expertos en Hadoop escriben aplicaciones y analizan datos en constante cambio para obtener información valiosa y mantener la seguridad de los datos. Por eso, los responsables de contratación tienen criterios estrictos para encontrar al candidato más adecuado para el puesto y pueden preguntarte cualquier cosa, desde lo más básico hasta lo más avanzado.
En este artículo, hemos recopilado las 24 preguntas y respuestas más frecuentes en las entrevistas sobre Hadoop.
Este artículo está diseñado para ayudarte a prepararte a fondo para tu próxima entrevista de trabajo relacionada con el big data. Abarca conceptos fundamentales y escenarios avanzados. Tanto si eres principiante como profesional experimentado, encontrarás información valiosa y práctica que te ayudará a ganar confianza y mejorar tus posibilidades de éxito.
Los entrevistadores suelen comenzar la entrevista con preguntas básicas para evaluar tus conocimientos sobre Hadoop y su relevancia en la gestión de big data.
Incluso si eres un ingeniero con experiencia, asegúrate de tener claras estas preguntas.
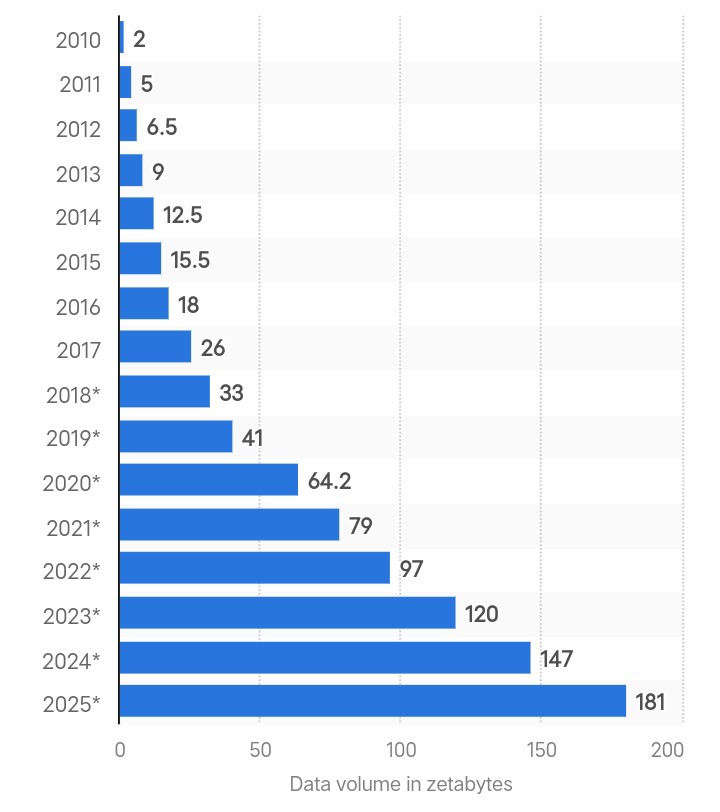
Creación global de datos en zettabytes. Fuente: Statista.
El término «big data» hace referencia a grandes cantidades de datos complejos generados a gran velocidad a partir de múltiples fuentes. La cantidad total de datos creados a nivel mundial fue de 180 zettabytes en 2025 y se prevé que se triplique para 2029.
A medida que se acelera la generación de datos, los métodos de análisis tradicionales no podrán proporcionar un procesamiento en tiempo real ni garantizar la seguridad de los datos. Por eso las empresas utilizan marcos avanzados como Hadoop para procesar y gestionar volúmenes de datos cada vez mayores.
Si deseas iniciar tu carrera profesional en el ámbito del big data, consulta nuestra guía sobre formación en big data.
Hadoop es un marco de código abierto para gestionar grandes conjuntos de datos distribuidos en varios ordenadores. Almacena datos en múltiples máquinas en forma de pequeños bloques utilizando el sistema de archivos distribuidos Hadoop (HDFS).
Con Hadoop, puedes añadir más nodos a un clúster y gestionar grandes volúmenes de datos sin necesidad de costosas actualizaciones de hardware.
Incluso grandes empresas como Google y Facebook confían en Hadoop para gestionar y analizar terabytes y petabytes de datos diarios.
Los siguientes son los dos componentes principales de Hadoop:
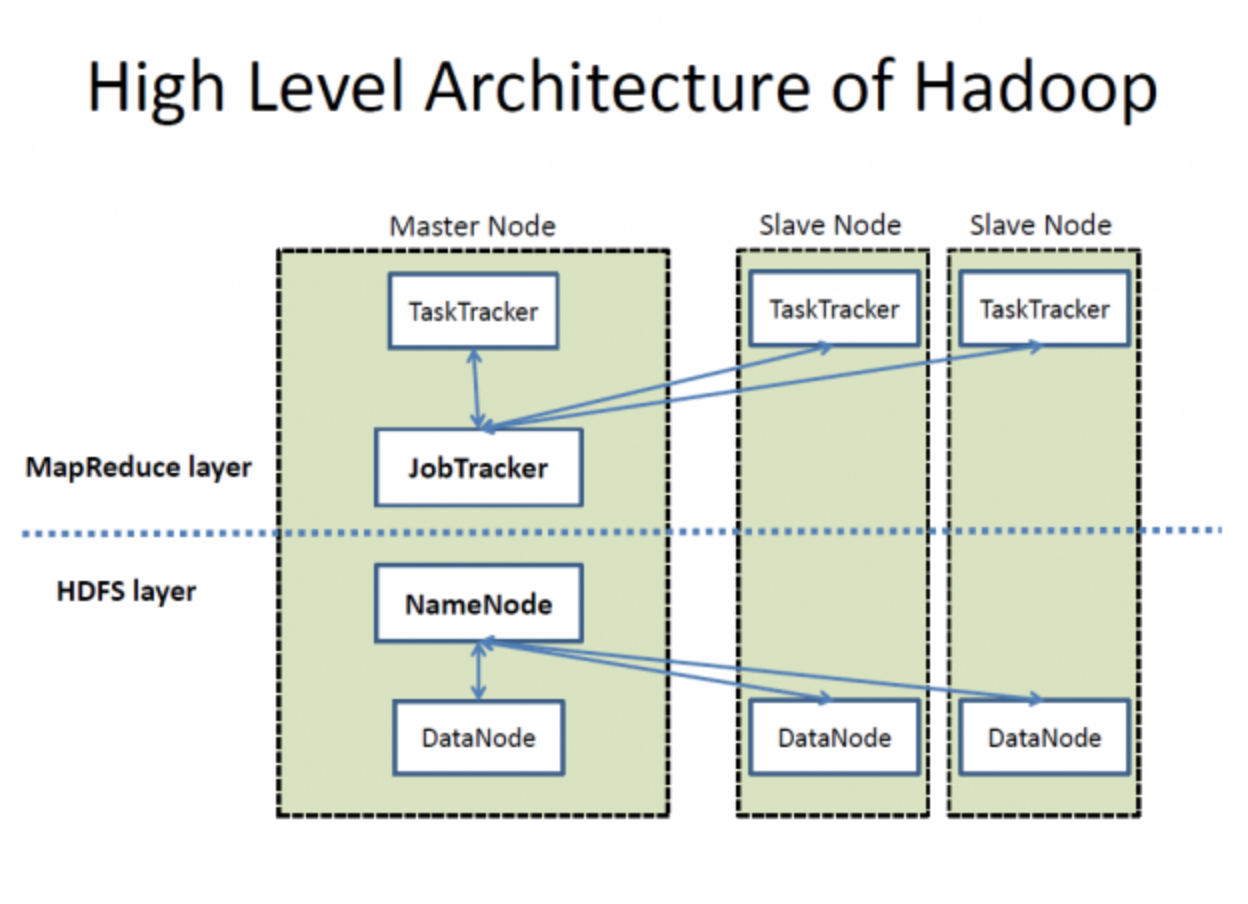
Arquitectura de alto nivel de Hadoop. Fuente: Wikimedia Commons
HDFS consta de un NameNode y varios DataNodes para la gestión de datos, como se ve en la imagen anterior. Así es como funcionan:
En Hadoop 1.x, MapReduce gestiona los recursos y programa los trabajos mediante JobTracker. Sin embargo, la lentitud del procesamiento es un inconveniente importante.
Hadoop 2.0 introdujo YARN (Yet Another Resource Negotiator) para abordar estos problemas. YARN separa la gestión de recursos y la programación de tareas en componentes independientes, lo que mejora la escalabilidad y la utilización de los recursos. Los componentes principales de YARN son:
Cómo funciona YARN:
Las preguntas intermedias se centran más en evaluar tus conocimientos sobre los aspectos técnicos del marco Hadoop. El entrevistador puede preguntarte sobre el clúster Hadoop, sus retos y la comparación entre diferentes versiones.
Un clúster Hadoop es un conjunto de nodos maestros y esclavos interconectados diseñado para almacenar y procesar grandes conjuntos de datos de forma distribuida. La arquitectura en clúster garantiza una alta disponibilidad, escalabilidad y tolerancia a fallos.
Componentes de un clúster Hadoop:
Hay dos formas principales de configurar un clúster Hadoop:
Comparación entre clústeres locales y basados en la nube:
|
Característica |
Clúster local |
Clúster basado en la nube |
|
Costo de instalación |
Mayor inversión inicial |
Modelo de pago por uso |
|
Escalabilidad |
Limitado por el hardware físico |
Prácticamente ilimitado |
|
Mantenimiento |
Requiere gestión interna. |
Gestionado por el proveedor de servicios en la nube |
|
Flexibilidad |
Hardware y software personalizables |
Opciones preconfiguradas |
|
Tiempo de implementación |
Mayor tiempo de configuración |
Implementación rápida y sencilla |
No hay ninguna preferencia específica en cuanto al tamaño del clúster. El tamaño del clúster es fácilmente escalable y depende totalmente de los requisitos de almacenamiento. Las pequeñas empresas pueden basarse en clústeres con alrededor de 20 nodos, mientras que empresas como Yahoo operan (o solían hacerlo) en clústeres tan extensos que contienen hasta 40 000 nodos.
Las diferentes industrias tienen necesidades específicas de análisis y procesamiento de datos. Por lo tanto, Hadoop ha lanzado muchos proyectos para proporcionar soluciones que se adapten a ellos como parte de su ecosistema. La lista de proyectos de Hadoop es más amplia de lo que puedas imaginar, pero estos son los más importantes:
Aunque el marco Hadoop es excelente para gestionar y procesar enormes cantidades de datos valiosos, plantea algunos retos críticos.
Entendámoslos:
HBase es una base de datos diseñada para acceder rápidamente a archivos de gran tamaño. Te permite leer y escribir grandes conjuntos de datos en tiempo real almacenando los datos en columnas e indexándolos con claves de fila únicas.
Esta configuración permite una rápida recuperación de datos y escaneos eficientes, lo que resulta adecuado para tablas grandes y poco pobladas, ya que podemos añadir tantos nodos como sea necesario.
HBase tiene tres componentes:
Esta tabla compara ambas versiones de Hadoop:
|
Criterios |
Hadoop 1.x |
Hadoop 2.0 |
|
Gestión de NameNode |
Un único NameNode gestiona el espacio de nombres. |
Varios NameNodes gestionan los espacios de nombres a través de la federación HDFS. |
|
Compatibilidad con sistemas operativos |
No hay compatibilidad con Microsoft Windows. |
Se ha añadido compatibilidad con Microsoft. |
|
Gestión de trabajos y recursos |
Utiliza JobTracker y TaskTracker para la gestión de trabajos y recursos. |
Los sustituí por YARN para separar ambas tareas. |
|
Escalabilidad |
Puede ampliarse hasta 4000 nodos por clúster. |
Puede ampliarse hasta 10 000 nodos por clúster. |
|
Tamaño del DataNode |
Tiene un tamaño de DataNode de 64 MB. |
Ha duplicado el tamaño a 128 MB. |
|
Ejecución de tareas |
Utiliza ranuras que pueden ejecutar tareas Map o Reduce. |
Utiliza contenedores que pueden ejecutar cualquier tarea. |
Si estás solicitando un puesto de trabajo como ingeniero de datos, consulta nuestro artículo completo sobre preguntas frecuentes en entrevistas de trabajo para ingenieros de datos.
Ahora es cuando las cosas se ponen interesantes. Estas preguntas de la entrevista se formulan para evaluar tus conocimientos a un nivel avanzado. Estas preguntas son especialmente importantes para los ingenieros sénior.
En Hadoop 2.0, el Active NameNode gestiona el espacio de nombres del sistema de archivos y controla el acceso de los clientes a los archivos. Por el contrario, el Standby NameNode es una copia de seguridad y mantiene suficiente información para tomar el control si el Active NameNode falla.
Esto soluciona el problema del punto único de fallo (SPOF), habitual en Hadoop 1. x.
HDFS es ineficaz a la hora de procesar miles de archivos pequeños, lo que provoca un aumento de la latencia. Por eso, la caché distribuida te permite almacenar archivos de solo lectura, archivos de archivo y archivos jar, y ponerlos a disposición para tareas en MapReduce.
Supongamos que necesitas ejecutar 40 trabajos en MapReduce y que cada trabajo necesita acceder al archivo desde HDFS. En tiempo real, este número puede aumentar hasta alcanzar cientos o miles de lecturas. La aplicación localizará con frecuencia estos archivos en HDFS, lo que sobrecargará el HDFS y afectará a su rendimiento.
Sin embargo, una caché distribuida puede gestionar muchos archivos de pequeño tamaño y no compromete el tiempo de acceso ni la velocidad de procesamiento.
Las sumas de comprobación identifican los datos dañados en HDFS. Cuando los datos entran en el sistema, crean un pequeño valor conocido como suma de comprobación. Hadoop vuelve a calcular la suma de comprobación cuando un usuario solicita la transferencia de datos. Si la nueva suma de comprobación coincide con la original, los datos están intactos; si no, están corruptos.
El código de detección de errores para Hadoop es CRC-32.
HDFS logra la tolerancia a fallos mediante un proceso de replicación que garantiza la fiabilidad y la disponibilidad. Así es como funciona el proceso de replicación:
Sí, es posible procesar archivos comprimidos con MapReduce. Hadoop admite múltiples formatos de compresión, pero no todos ellos son divisibles.
A continuación se indican los formatos compatibles con MapReduce:
De todos ellos, bzip2 es el único formato divisible.
HDFS divide los archivos muy grandes en partes más pequeñas, cada una de 128 MB. Por ejemplo, HDFS dividirá un archivo de 1,28 GB en diez bloques. A continuación, cada bloque es procesado por un mapeador independiente en una tarea MapReduce. Pero si un archivo no se puede dividir, un único mapeador se encarga de todo el archivo.
Algunos puestos de trabajo requieren experiencia en la integración de Hive con Hadoop. En un puesto tan específico, el responsable de contratación se centrará en las siguientes preguntas:
Hive es un sistema de almacenamiento de datos que realiza trabajos por lotes y análisis de datos. Fue desarrollado por Facebook para ejecutar consultas similares a SQL en conjuntos de datos masivos almacenados en HDFS sin depender de Java.
Con Hive, podemos organizar los datos en tablas y utilizar un megastore para almacenar metadatos como esquemas. Es compatible con una amplia gama de sistemas de almacenamiento, como S3, Azure Data Lake Storage (ADLs) y Google Cloud Storage.
Hive Metastore (HMS) es una base de datos centralizada para metadatos. Contiene información sobre tablas, vistas y permisos de acceso almacenados en el almacenamiento de objetos HDFS.
Hay dos tipos de tablas HIVE Metastore:
/user/hive/warehouse. Hive ofrece un sólido soporte para la integración con múltiples lenguajes de programación, lo que mejora su versatilidad y facilidad de uso en diferentes aplicaciones:
Gracias a su integración con HDFS y a su arquitectura escalable, Hive puede gestionar petabytes de datos. No hay un límite máximo fijo para el tamaño de los datos que Hive puede gestionar, lo que lo convierte en una potente herramienta para el procesamiento y el análisis de big data.
Hive ofrece un amplio conjunto de tipos de datos para gestionar diferentes requisitos de datos:
Tipos de datos integrados:
|
Categoría |
Tipo de datos |
Descripción |
Ejemplo |
|
Tipos numéricos |
TINYINT |
Entero con signo de 1 byte |
127 |
|
SMALLINT |
Entero con signo de 2 bytes |
32767 |
|
|
INT |
Entero con signo de 4 bytes |
2147483647 |
|
|
BIGINT |
Entero con signo de 8 bytes |
9223372036854775807 |
|
|
FLOTAR |
Punto flotante de precisión simple |
3,14 |
|
|
DOBLE |
Punto flotante de doble precisión |
3,141592653589793 |
|
|
DECIMAL |
Número decimal con signo de precisión arbitraria |
1234567890.1234567890 |
|
|
Tipos de cadenas |
CADENA |
Cadena de longitud variable |
¡Hola, mundo! |
|
VARCHAR |
Cadena de longitud variable con una longitud máxima especificada |
«Ejemplo» |
|
|
CHAR |
Cadena de longitud fija |
«A» |
|
|
Tipos de fecha/hora |
MARCA DE TIEMPO |
Fecha y hora, incluida la zona horaria. |
«01-01-2023, 12:34:56» |
|
FECHA |
Fecha sin hora |
«01-01-2023» |
|
|
INTERVAL |
Intervalo de tiempo |
INTERVALO «1» DÍA |
|
|
Tipos varios |
BOOLEANO |
Representa verdadero o falso. |
VERDADERO |
|
BINARIO |
Secuencia de bytes |
0x1A2B3C |
Tipos de datos complejos:
|
Tipo de datos |
Descripción |
Ejemplo |
|
ARRAY |
Colección ordenada de elementos |
arreglo<STRING> ('manzana', 'plátano', 'cereza') |
|
MAP |
Colección de pares clave-valor |
MAP<STRING, INT> ('clave1' -> 1, 'clave2' -> 2) |
|
ESTRUCTURA |
Colección de campos de diferentes tipos de datos |
STRUCT<nombre: STRING, edad: INT> ('Alice', 30) |
|
TIPO DE UNIÓN |
Puede contener cualquiera de varios tipos especificados. |
UNIONTYPE<INT, DOUBLE, STRING> (1, 2.0, 'tres') |
Estas preguntas evalúan tu capacidad para utilizar Hadoop para resolver problemas de la vida real. Son especialmente relevantes si estás solicitando un puesto de arquitecto de datos, pero pueden preguntarte en cualquier proceso de entrevista que requiera conocimientos de Hadoop.
Así es como Hadoop replicará los datos:
La estrategia de replicación de Hadoop en un clúster HDFS con tres racks (A, B y C) está diseñada para optimizar la distribución de la carga, mejorar la tolerancia a fallos y aumentar la eficiencia de la red. De esta manera, el sistema de gestión de datos de campo ( datafile.text ) se replica de forma que se equilibra el rendimiento y la fiabilidad.
El uso de sumas de comprobación en el proceso de carga, transformación y almacenamiento ( LocalFileSystem ) de Hadoop garantiza la integridad de los datos mediante:
.filename.crc en el mismo directorio.ChecksumException » en caso de discrepancias.Siguiendo estos pasos, podemos garantizar que tu aplicación mantenga la integridad de los datos y detecte rápidamente cualquier posible corrupción de datos.
Esto es lo que podemos hacer:
stderr.Siguiendo estos pasos, podemos depurar sistemáticamente trabajos de Hadoop a gran escala y programar y resolver eficazmente casos inusuales que afecten al resultado.
Al configurar los ajustes de memoria para un clúster Hadoop utilizando YARN, es importante equilibrar la asignación de memoria entre los demonios Hadoop, los procesos del sistema y el NodeManager para optimizar el rendimiento y la utilización de los recursos.
Configuración de la memoria para NodeManager:
Configuración de la memoria para trabajos MapReduce:
mapreduce.map.memory.mb: Este parámetro define la cantidad de memoria asignada para cada tarea de mapeo. Ajusta esta configuración en función de los requisitos de memoria de tus tareas de mapas.mapreduce.map.memory.mb en 2048 MB, se asignarán 2 GB de memoria a cada tarea de mapa.mapreduce.reduce.memory.mb: Este parámetro define la cantidad de memoria asignada para cada tarea de reducción. Ajusta esta configuración en función de los requisitos de memoria de tus tareas de reducción.mapreduce.reduce.memory.mb en 4096 MB, cada tarea de reducción tendrá asignados 4 GB de memoria.yarn-site.xml con parámetros como yarn.nodemanager.resource.memory-mb, que deben coincidir con la memoria asignada al NodeManager.yarn.nodemanager.resource.memory-mb en 59 000 MB.Resumen de la configuración de memoria:
|
Componente |
Configuración |
Valores de ejemplo |
|
NodeManager |
Memoria física total |
64 000 MB |
|
Memoria para los demonios de Hadoop |
3000 MB |
|
|
Memoria para procesos del sistema |
2000 MB |
|
|
Memoria disponible para NodeManager |
59 000 MB |
|
|
Tarea de mapa de MapReduce |
mapreduce.map.memory.mb |
2048 MB |
|
Tarea de reducción de MapReduce |
mapreduce.reduce.memory.mb |
4096 MB |
|
Tamaño del contenedor |
yarn.nodemanager.resource.memory-mb |
59 000 MB |
Después de comprender estas preguntas, debes conocer los términos básicos y tener un
Gran dominio de las complejidades de las aplicaciones Hadoop en la vida real. Además, debes adaptarte a los nuevos proyectos basados en Hadoop para seguir siendo relevante y destacar en tus entrevistas.
También puedes ampliar tus conocimientos sobre otros marcos de big data, como Spark y Flink, ya que son rápidos y tienen menos problemas de latencia que Hadoop.
Pero si buscas un itinerario de aprendizaje estructurado para dominar el big data, puedes consultar los siguientes recursos:
¡Aprende más sobre ingeniería de datos y big data con estos cursos!
programa
Curso
Curso