
Programa
Engenheiro de dados profissional Em Python
40 h
Os especialistas em Hadoop criam aplicativos e analisam dados que mudam o tempo todo para entender melhor as coisas e manter a segurança dos dados. É por isso que os gerentes de contratação têm critérios bem rígidos pra achar a pessoa certa pro cargo e podem perguntar qualquer coisa, desde o básico até o avançado.
Neste artigo, juntamos as 24 perguntas e respostas mais comuns em entrevistas sobre Hadoop.
Esse artigo foi feito pra te ajudar a se preparar direitinho pra sua próxima entrevista de emprego na área de big data. Ele aborda conceitos básicos e cenários avançados. Seja você um iniciante ou um profissional experiente, vai encontrar dicas valiosas e informações práticas para aumentar sua confiança e melhorar suas chances de sucesso.
Os entrevistadores geralmente começam a entrevista fazendo perguntas básicas para ver se você entende o Hadoop e como ele é importante para gerenciar big data.
Mesmo que você seja um engenheiro experiente, certifique-se de ter respostas para essas perguntas.
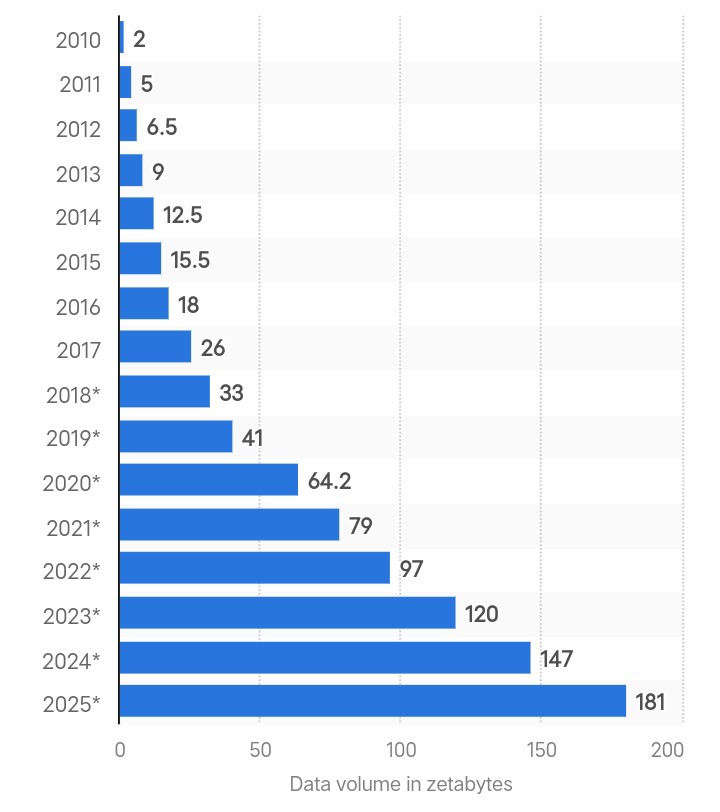
Criação global de dados em zettabytes. Fonte: Statista.
Big data é quando tem um monte de dados complexos que são gerados rapidinho de várias fontes. A quantidade total de dados criados no mundo todo foi de 180 zettabytes em 2025 e deve triplicar até 2029.
À medida que a geração de dados acelera, os métodos tradicionais de análise não vão conseguir oferecer processamento em tempo real e segurança dos dados. É por isso que as empresas usam estruturas avançadas como o Hadoop para processar e gerenciar volumes crescentes de dados.
Se você quer começar sua carreira em big data, dá uma olhada no nosso guia sobre treinamento em big data.
O Hadoop é uma estrutura de código aberto para lidar com grandes conjuntos de dados distribuídos por vários computadores. Ele guarda dados em várias máquinas como pequenos blocos usando o Sistema de Arquivos Distribuídos Hadoop (HDFS).
Com o Hadoop, você pode adicionar mais nós a um cluster e lidar com grandes volumes de dados sem precisar fazer atualizações caras de hardware.
Até mesmo grandes empresas como Google e Facebook dependem do Hadoop para gerenciar e analisar terabytes a petabytes de dados diariamente.
Aqui estão os dois principais componentes do Hadoop:
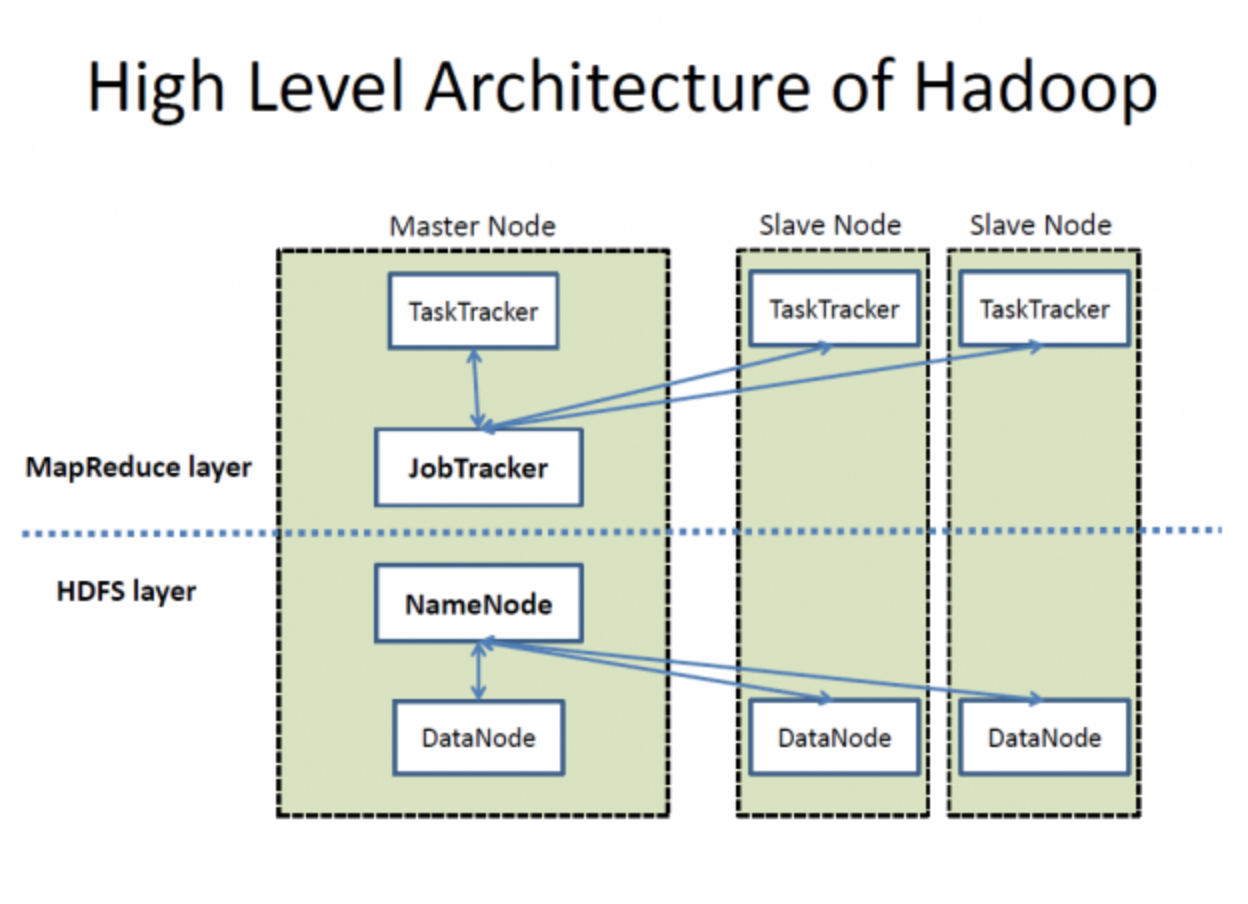
Arquitetura de alto nível do Hadoop. Fonte: Wikimedia Commons
O HDFS é composto por um NameNode e vários DataNodes para gerenciamento de dados, como mostra a imagem acima. Eis como funcionam:
No Hadoop 1.x, o MapReduce cuida do gerenciamento de recursos e do agendamento de tarefas usando o JobTracker. Mas, o processamento lento é uma grande desvantagem.
O Hadoop 2.0 trouxe o YARN (Yet Another Resource Negotiator) pra resolver esses problemas. O YARN separa o gerenciamento de recursos e o agendamento de tarefas em componentes diferentes, o que melhora a escalabilidade e a utilização dos recursos. Os principais componentes do YARN são:
Como funciona o YARN:
As perguntas intermediárias são mais focadas em avaliar o seu conhecimento sobre os detalhes técnicos da estrutura Hadoop. O entrevistador pode perguntar sobre o cluster Hadoop, seus desafios e a comparação entre diferentes versões.
Um cluster Hadoop é um conjunto de nós mestres e escravos interconectados, projetado para armazenar e processar grandes conjuntos de dados de forma distribuída. A arquitetura em cluster garante alta disponibilidade, escalabilidade e tolerância a falhas.
Componentes de um cluster Hadoop:
Tem duas maneiras principais de configurar um cluster Hadoop:
Comparando clusters locais e baseados em nuvem:
|
Recurso |
Cluster local |
Cluster baseado em nuvem |
|
Custo de instalação |
Maior investimento inicial |
Modelo de pagamento conforme o uso |
|
Escalabilidade |
Limitado pelo hardware físico |
Praticamente ilimitado |
|
Manutenção |
Precisa de gestão interna |
Gerenciado pelo provedor de nuvem |
|
Flexibilidade |
Hardware e software personalizáveis |
Opções pré-configuradas |
|
Tempo de implantação |
Mais tempo de configuração |
Implantação rápida e fácil |
Não tem preferência específica pro tamanho do cluster. O tamanho do cluster é fácil de ajustar e depende totalmente dos requisitos de armazenamento. Pequenas empresas podem usar clusters com cerca de 20 nós, enquanto empresas como o Yahoo operam (ou operavam) em clusters com até 40.000 nós.
Diferentes setores têm necessidades específicas de análise e processamento de dados. Então, o Hadoop lançou vários projetos pra oferecer soluções que atendem a essas necessidades como parte do seu ecossistema. A lista de projetos Hadoop é maior do que você imagina, mas aqui estão os mais importantes:
Embora a estrutura Hadoop seja excelente para gerenciar e processar enormes quantidades de dados valiosos, ela apresenta alguns desafios críticos.
Vamos entender o que são:
O HBase é um banco de dados feito pra acessar arquivos grandes rapidinho. Ele permite que você leia e escreva grandes conjuntos de dados em tempo real, armazenando os dados em colunas e indexando-os com chaves de linha exclusivas.
Essa configuração permite uma recuperação rápida de dados e varreduras eficientes, o que é ideal para tabelas grandes e pouco preenchidas, porque a gente pode adicionar quantos nós forem necessários.
O HBase tem três componentes:
Essa tabela compara as duas versões do Hadoop lado a lado:
|
Critérios |
Hadoop 1.x |
Hadoop 2.0 |
|
Gerenciamento do NameNode |
Um único NameNode cuida do namespace. |
Vários NameNodes lidam com namespaces por meio da federação HDFS |
|
Suporte ao sistema operacional |
Não há suporte para o Microsoft Windows. |
Adicionado suporte para Microsoft |
|
Gerenciamento de tarefas e recursos |
Usa o JobTracker e o TaskTracker para gerenciar tarefas e recursos |
Troquei por YARN pra separar as duas tarefas. |
|
Escalabilidade |
Pode escalar até 4.000 nós por cluster |
Pode escalar até 10.000 nós por cluster |
|
Tamanho do DataNode |
Tem um tamanho de DataNode de 64 MB |
Aumentou o tamanho para 128 MB |
|
Execução da tarefa |
Usa slots que podem executar tarefas Map ou Reduce |
Usa contêineres que podem executar qualquer tarefa |
Se você está se candidatando a um emprego na área de engenharia de dados, confira nosso artigo completo sobre perguntas em entrevistas para engenheiros de dados.
Agora é que as coisas ficam interessantes. Essas perguntas da entrevista são feitas pra testar você num nível mais avançado. Essas questões são especialmente importantes para engenheiros seniores.
No Hadoop 2.0, o Active NameNode cuida do namespace do sistema de arquivos e controla o acesso dos clientes aos arquivos. Por outro lado, o Standby NameNode é um backup e mantém informações suficientes para assumir o controle caso o Active NameNode falhe.
Isso resolve o problema do ponto único de falha (SPOF), comum no Hadoop 1.x.
O HDFS não é muito bom em lidar com milhares de arquivos pequenos, o que faz com que a latência aumente. É por isso que o cache distribuído permite que você armazene arquivos somente leitura, arquivos de arquivo e arquivos jar e os disponibilize para tarefas no MapReduce.
Digamos que você precise rodar 40 tarefas no MapReduce, e cada uma delas precisa acessar o arquivo do HDFS. Em tempo real, esse número pode chegar a centenas ou milhares de leituras. O aplicativo frequentemente localizará esses arquivos no HDFS, o que sobrecarregará o HDFS e afetará seu desempenho.
Mas, um cache distribuído consegue lidar com muitos arquivos pequenos e não prejudica o tempo de acesso e a velocidade de processamento.
As somas de verificação identificam dados corrompidos no HDFS. Quando os dados entram no sistema, eles criam um pequeno valor chamado checksum. O Hadoop recalcula a soma de verificação quando um usuário pede a transferência de dados. Se a nova soma de verificação corresponder à original, os dados estão intactos; caso contrário, estão corrompidos.
O código de detecção de erros para o Hadoop é CRC-32.
O HDFS consegue tolerância a falhas por meio de um processo de replicação que garante confiabilidade e disponibilidade. Veja como funciona o processo de replicação:
Sim, dá pra processar arquivos compactados com o MapReduce. O Hadoop suporta vários formatos de compactação, mas nem todos são divisíveis.
Aqui estão os formatos que o MapReduce aceita:
De todos esses, o bzip2 é o único formato que dá pra dividir.
O HDFS divide arquivos muito grandes em partes menores, cada uma com 128 MB. Por exemplo, o HDFS vai dividir um arquivo de 1,28 GB em dez blocos. Cada bloco é então processado por um mapeador separado em uma tarefa MapReduce. Mas se um arquivo não puder ser dividido, um único mapeador cuidará de todo o arquivo.
Alguns trabalhos exigem experiência em integração do Hive com o Hadoop. Nessa função específica, o gerente de contratação vai se concentrar nessas questões:
O Hive é um sistema de warehouse de dados que faz trabalhos em lote e análises de dados. Foi desenvolvido pelo Facebook para executar consultas semelhantes a SQL em conjuntos de dados massivos armazenados no HDFS sem depender do Java.
Com o Hive, a gente pode organizar os dados em tabelas e usar um megastore pra guardar metadados, tipo esquemas. Ele suporta uma variedade de sistemas de armazenamento, como S3, Azure Data Lake Storage (ADLs) e Google Cloud Storage.
O Hive Metastore (HMS) é um banco de dados centralizado para metadados. Tem informações sobre tabelas, visualizações e permissões de acesso guardadas no armazenamento de objetos HDFS.
Existem dois tipos de tabelas HIVE Metastore:
/user/hive/warehouse. O Hive oferece um suporte robusto para integração com várias linguagens de programação, aumentando sua versatilidade e usabilidade em diferentes aplicações:
Por causa da integração com o HDFS e da arquitetura escalável, o Hive consegue lidar com petabytes de dados. Não tem um limite máximo fixo para o tamanho dos dados que o Hive consegue gerenciar, o que faz dele uma ferramenta poderosa para processamento e análise de big data.
O Hive tem um monte de tipos de dados pra lidar com diferentes necessidades:
Tipos de dados integrados:
|
Categoria |
Tipo de dados |
Descrição |
Exemplo |
|
Tipos numéricos |
TINYINT |
Inteiro assinado de 1 byte |
127 |
|
SMALLINT |
Inteiro assinado de 2 bytes |
32767 |
|
|
INT |
Inteiro com sinal de 4 bytes |
2147483647 |
|
|
BIGINT |
Inteiro assinado de 8 bytes |
9223372036854775807 |
|
|
FLOAT |
Ponto flutuante de precisão simples |
3,14 |
|
|
DUPLO |
Ponto flutuante de precisão dupla |
3,141592653589793 |
|
|
DECIMAL |
Número decimal com precisão arbitrária e sinal |
1234567890.1234567890 |
|
|
Tipos de string |
STRING |
String de comprimento variável |
Oi, mundo! |
|
VARCHAR |
String de comprimento variável com comprimento máximo especificado |
'Exemplo' |
|
|
CHAR |
String de comprimento fixo |
'A' |
|
|
Tipos de data/hora |
CARIMBO DE DATA/HORA |
Data e hora, incluindo fuso horário |
“01/01/2023 12:34:56” |
|
DATA |
Data sem hora |
“01/01/2023” |
|
|
INTERVALO |
Intervalo de tempo |
INTERVALO '1' DIA |
|
|
Tipos diversos |
BOOLEANO |
Representa verdadeiro ou falso |
VERDADEIRO |
|
BINÁRIO |
Sequência de bytes |
0x1A2B3C |
Tipos de dados complexos:
|
Tipo de Dados |
Descrição |
Exemplo |
|
MATRIZ |
Coleção ordenada de elementos |
ARRAY<STRING> ('maçã', 'banana', 'cereja') |
|
MAP |
Coleção de pares chave-valor |
MAP<STRING, INT> ('chave1' -> 1, 'chave2' -> 2) |
|
STRUCT |
Coleção de campos de diferentes tipos de dados |
STRUCT<nome: STRING, idade: INT> ('Alice', 30) |
|
TIPO DE UNIÃO |
Pode conter qualquer um dos vários tipos especificados |
TIPO DE UNIÃO<INT, DOUBLE, STRING> (1, 2,0, 'três') |
Essas perguntas testam sua habilidade de usar o Hadoop para lidar com problemas da vida real. Elas são especialmente importantes se você estiver se candidatando a uma vaga de arquiteto de dados, mas podem ser feitas em qualquer entrevista que exija conhecimento de Hadoop.
Veja como o Hadoop vai replicar os dados:
A estratégia de replicação do Hadoop em um cluster HDFS com três racks (A, B e C) foi projetada para otimizar a distribuição de carga, aumentar a tolerância a falhas e melhorar a eficiência da rede. Assim, o datafile.text é replicado de uma forma que equilibra desempenho e confiabilidade.
Usar checksums no Hadoop's LocalFileSystem garante a integridade dos dados ao:
.filename.crc no mesmo diretório.ChecksumException " em caso de discrepâncias.Seguindo essas etapas, podemos garantir que seu aplicativo mantenha a integridade dos dados e detecte rapidamente qualquer possível corrupção de dados.
E aí, o que a gente pode fazer:
stderr.Seguindo essas etapas, podemos depurar sistematicamente tarefas Hadoop em grande escala e programar e resolver com eficácia casos incomuns que afetam a saída.
Ao configurar as definições de memória para um cluster Hadoop usando o YARN, é importante equilibrar a alocação de memória entre os daemons Hadoop, os processos do sistema e o NodeManager para otimizar o desempenho e a utilização dos recursos.
Configurando a memória para o NodeManager:
Configurando a memória para tarefas MapReduce:
mapreduce.map.memory.mb: Esse parâmetro define a quantidade de memória alocada para cada tarefa do mapa. Ajuste essa configuração com base nos requisitos de memória das suas tarefas de mapa.mapreduce.map.memory.mb como 2048 MB significa que cada tarefa de mapeamento vai ter 2 GB de memória.mapreduce.reduce.memory.mb: Esse parâmetro define a quantidade de memória alocada para cada tarefa de redução. Ajuste essa configuração com base nos requisitos de memória das suas tarefas de redução.mapreduce.reduce.memory.mb como 4096 MB significa que cada tarefa de redução vai receber 4 GB de memória.yarn-site.xml com parâmetros como yarn.nodemanager.resource.memory-mb, que devem estar alinhados com a memória alocada para o NodeManager.yarn.nodemanager.resource.memory-mb como 59.000 MB.Resumo da configuração da memória:
|
Componente |
Configuração |
Exemplos de valores |
|
Gerenciador de Nós |
Memória física total |
64.000 MB |
|
Memória para daemons Hadoop |
3000 MB |
|
|
Memória para processos do sistema |
2000 MB |
|
|
Memória disponível para o NodeManager |
59.000 MB |
|
|
Tarefa de mapeamento do MapReduce |
mapreduce.map.memória.mb |
2048 MB |
|
Tarefa de redução do MapReduce |
mapreduce.reduce.memória.mb |
4096 MB |
|
Tamanho do contêiner |
yarn.nodemanager.resource.memory-mb |
59.000 MB |
Depois de entender essas questões, você deve conhecer os termos básicos e ter uma
domínio sólido das complexidades das aplicações Hadoop na vida real. Além disso, você precisa se adaptar aos novos projetos criados no Hadoop para continuar relevante e se sair bem nas entrevistas.
Você também pode expandir seus conhecimentos sobre outras estruturas de big data, como Spark e Flink, pois elas são rápidas e têm menos problemas de latência do que o Hadoop.
Mas se você está procurando uma trilha de aprendizagem estruturada para dominar o big data, dá uma olhada nos recursos a seguir:
Aprenda mais sobre engenharia de dados e big data com esses cursos!
Programa
Curso
Curso