
Lernpfad
Professioneller Dateningenieur in Python
40 Std.
Hadoop-Experten schreiben Programme und checken ständig wechselnde Daten, um Erkenntnisse zu gewinnen und die Datensicherheit zu gewährleisten. Deshalb haben Personalchefs strenge Kriterien, um den besten Kandidaten für die Stelle zu finden, und können dir alle möglichen Fragen stellen, von einfachen bis hin zu anspruchsvollen.
In diesem Artikel haben wir die 24 häufigsten Fragen und Antworten zu Hadoop aus Vorstellungsgesprächen zusammengestellt.
Dieser Artikel soll dir dabei helfen, dich gründlich auf dein nächstes Vorstellungsgespräch im Bereich Big Data vorzubereiten. Es geht um grundlegende Konzepte und fortgeschrittene Szenarien. Egal, ob du Anfänger oder erfahrener Profi bist, hier findest du wertvolle Einblicke und praktische Infos, die dein Selbstvertrauen stärken und deine Erfolgschancen verbessern.
Interviewer fangen ein Interview meistens mit einfachen Fragen an, um zu sehen, wie gut du Hadoop verstehst und wie wichtig es für die Verwaltung von Big Data ist.
Auch wenn du ein erfahrener Ingenieur bist, solltest du sicherstellen, dass du diese Fragen beantwortet hast.
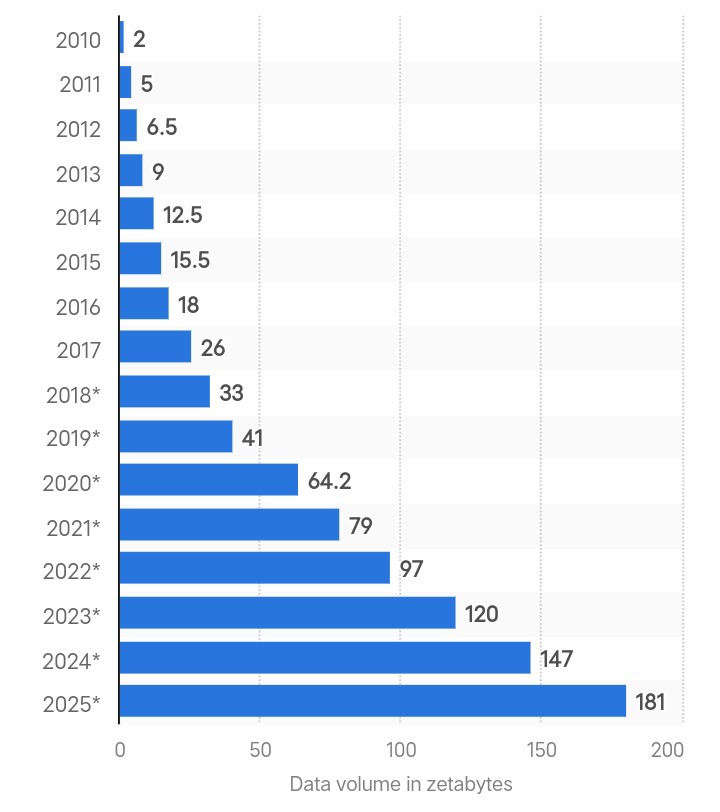
Globale Datenerstellung in Zettabyte. Quelle: Statista.
Big Data ist der Begriff für riesige Mengen komplexer Daten, die schnell aus vielen Quellen zusammenkommen. Die Menge an Daten, die weltweit erstellt wurde, lag 2025 bei 180 Zettabyte und soll sich bis 2029 verdreifachen.
Da immer mehr Daten anfallen, werden die alten Analysemethoden nicht mehr ausreichen, um Echtzeitverarbeitung und Datensicherheit zu gewährleisten. Deshalb nutzen Firmen moderne Frameworks wie Hadoop, um die immer größer werdenden Datenmengen zu verarbeiten und zu verwalten.
Wenn du deine Karriere im Bereich Big Data starten willst, schau dir unseren Leitfaden zur Big-Data-Ausbildung an.
Hadoop ist ein Open-Source-Framework für die Verarbeitung großer Datensätze, die auf mehrere Computer verteilt sind. Es speichert Daten über mehrere Maschinen hinweg als kleine Blöcke mithilfe des Hadoop Distributed File System (HDFS).
Mit Hadoop kannst du einem Cluster mehr Knoten hinzufügen und große Datenmengen verarbeiten, ohne teure Hardware-Upgrades machen zu müssen.
Sogar große Firmen wie Google und Facebook nutzen Hadoop, um täglich Terabytes bis Petabytes an Daten zu verwalten und zu analysieren.
Hier sind die beiden Hauptkomponenten von Hadoop:
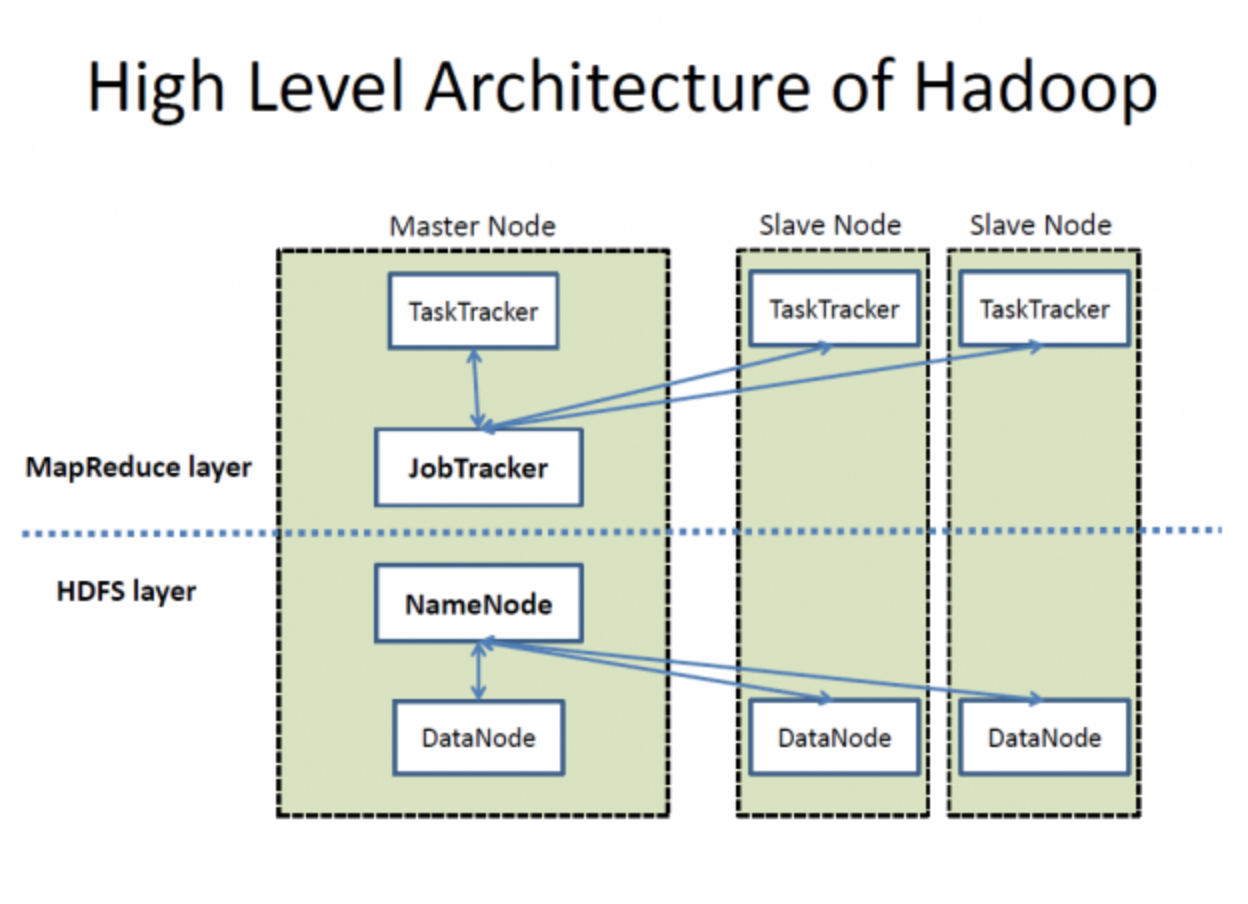
Die Architektur von Hadoop auf hoher Ebene. Quelle: Wikimedia Commons
HDFS besteht aus einem NameNode und mehreren DataNodes für die Datenverwaltung, wie in der Abbildung oben zu sehen ist. So funktionieren sie:
In Hadoop 1.x kümmert sich MapReduce mit JobTracker um die Verwaltung der Ressourcen und die Planung der Jobs. Die langsame Verarbeitung ist allerdings ein ziemlicher Nachteil.
Hadoop 2.0 hat YARN (Yet Another Resource Negotiator) eingeführt, um diese Probleme zu lösen. YARN trennt die Ressourcenverwaltung und die Jobplanung in separate Komponenten, was die Skalierbarkeit und die Ressourcennutzung verbessert. Die Hauptkomponenten von YARN sind:
So funktioniert YARN:
Die Zwischenfragen konzentrieren sich mehr darauf, dein Wissen über die technischen Details des Hadoop-Frameworks zu checken. Der Interviewer kann dich zum Hadoop-Cluster, seinen Herausforderungen und dem Vergleich verschiedener Versionen fragen.
Ein Hadoop-Cluster ist eine Gruppe von miteinander verbundenen Master- und Slave-Knoten, die dafür gemacht sind, große Datensätze verteilt zu speichern und zu verarbeiten. Die Cluster-Architektur sorgt für hohe Verfügbarkeit, Skalierbarkeit und Ausfallsicherheit.
Teile eines Hadoop-Clusters:
Es gibt zwei Hauptmethoden, um einen Hadoop-Cluster einzurichten:
Vergleich zwischen lokalen und Cloud-basierten Clustern:
|
Feature |
Lokaler Cluster |
Cloud-basierter Cluster |
|
Einrichtungskosten |
Höhere Anfangsinvestition |
Umlageverfahren |
|
Skalierbarkeit |
Durch die physische Hardware eingeschränkt |
Praktisch unbegrenzt |
|
Wartung |
Muss intern verwaltet werden |
Vom Cloud-Anbieter verwaltet |
|
Flexibilität |
Anpassbare Hardware und Software |
Vorkonfigurierte Optionen |
|
Bereitstellungszeit |
Längere Einrichtungszeit |
Schnelle und einfache Bereitstellung |
Es gibt keine bestimmte Vorliebe für die Clustergröße. Die Clustergröße ist einfach skalierbar und hängt komplett von den Speicheranforderungen ab. Kleine Firmen nutzen vielleicht Cluster mit etwa 20 Knoten, während Unternehmen wie Yahoo auf Clustern mit bis zu 40.000 Knoten laufen (oder früher gelaufen sind).
Verschiedene Branchen haben ganz bestimmte Anforderungen an die Datenanalyse und -verarbeitung. Also hat Hadoop viele Projekte rausgebracht, um Lösungen anzubieten, die genau auf sie zugeschnitten sind, als Teil seines Ökosystems. Die Liste der Hadoop-Projekte ist länger, als du dir vorstellen kannst – aber hier sind die wichtigsten:
Das Hadoop-Framework ist zwar super im Verwalten und Verarbeiten riesiger Mengen wertvoller Daten, bringt aber auch ein paar kritische Herausforderungen mit sich.
Lass uns das mal verstehen:
HBase ist eine Datenbank, die für den schnellen Zugriff auf große Dateien entwickelt wurde. Damit kannst du große Datensätze in Echtzeit lesen und schreiben, indem du die Daten in Spalten speicherst und mit eindeutigen Zeilenschlüsseln indizierst.
Diese Konfiguration ermöglicht schnelles Abrufen von Daten und effiziente Scans, was besonders für große und spärlich besetzte Tabellen gut ist, weil wir so viele Knoten hinzufügen können, wie wir brauchen.
HBase hat drei Teile:
Diese Tabelle zeigt die beiden Hadoop-Versionen nebeneinander:
|
Kriterien |
Hadoop 1.x |
Hadoop 2.0 |
|
NameNode-Verwaltung |
Ein einzelner NameNode kümmert sich um den Namensraum. |
Mehrere NameNodes verwalten Namespaces über die HDFS-Föderation. |
|
Unterstützte Betriebssysteme |
Es gibt keine Unterstützung für Microsoft Windows. |
Unterstützung für Microsoft hinzugefügt |
|
Job- und Ressourcenmanagement |
Nutzt JobTracker und TaskTracker für die Job- und Ressourcenverwaltung |
Ich habe sie durch YARN ersetzt, um die beiden Aufgaben zu trennen. |
|
Skalierbarkeit |
Kann auf bis zu 4.000 Knoten pro Cluster erweitert werden |
Kann auf bis zu 10.000 Knoten pro Cluster erweitert werden |
|
Größe des Datenknotens |
Hat eine DataNode-Größe von 64 MB |
Hat die Größe auf 128 MB verdoppelt |
|
Aufgabenerledigung |
Nutzt Slots, die entweder Map- oder Reduce-Aufgaben ausführen können. |
Verwendet Container, die jede Aufgabe ausführen können |
Wenn du dich für einen Job im Bereich Data Engineering bewirbst, schau dir unseren umfassenden Artikel zu Fragen im Vorstellungsgespräch für Data Engineering an.
Jetzt wird's spannend. Diese Interviewfragen sind dazu da, dich auf einem fortgeschrittenen Niveau zu testen. Diese Fragen sind besonders wichtig für leitende Ingenieure.
In Hadoop 2.0 kümmert sich der Active NameNode um den Dateisystem-Namespace und regelt, wie Clients auf Dateien zugreifen können. Im Gegenteil, der Standby NameNode ist ein Backup und hat genug Infos, um einzuspringen, wenn der Active NameNode mal ausfällt.
Das löst das Problem des Single Point of Failure (SPOF), das bei Hadoop 1. x oft auftritt.
HDFS ist nicht so gut darin, viele kleine Dateien zu verarbeiten, was zu einer längeren Latenz führt. Deshalb kannst du mit dem verteilten Cache schreibgeschützte Dateien, Archivdateien und JAR-Dateien speichern und sie für Aufgaben in MapReduce bereitstellen.
Angenommen, du musst 40 Jobs in MapReduce ausführen, und jeder Job muss auf die Datei aus HDFS zugreifen. In Echtzeit kann diese Zahl auf Hunderte oder Tausende von Lesevorgängen ansteigen. Die Anwendung sucht diese Dateien oft in HDFS, was HDFS überlastet und die Leistung beeinträchtigt.
Ein verteilter Cache kann aber viele kleine Dateien verarbeiten, ohne dass die Zugriffszeit und die Verarbeitungsgeschwindigkeit darunter leiden.
Prüfsummen erkennen beschädigte Daten in HDFS. Wenn Daten ins System kommen, wird ein kleiner Wert erstellt, den man als Prüfsumme bezeichnet. Hadoop berechnet die Prüfsumme neu, wenn jemand Daten übertragen will. Wenn die neue Prüfsumme mit der ursprünglichen übereinstimmt, sind die Daten in Ordnung; wenn nicht, sind sie kaputt.
Der Fehlererkennungscode für Hadoop ist CRC-32.
HDFS ist dank eines Replikationsprozesses, der für Zuverlässigkeit und Verfügbarkeit sorgt, ziemlich robust. So läuft der Replikationsprozess ab:
Ja, komprimierte Dateien kann man mit MapReduce bearbeiten. Hadoop kann mit mehreren Komprimierungsformaten umgehen, aber nicht alle lassen sich aufteilen.
Hier sind die Formate, die MapReduce unterstützt:
Von all diesen ist bzip2 das einzige Format, das man aufteilen kann.
HDFS teilt echt große Dateien in kleinere Teile auf, die jeweils 128 MB groß sind. HDFS teilt zum Beispiel eine 1,28 GB große Datei in zehn Blöcke auf. Jeder Block wird dann von einem separaten Mapper in einem MapReduce-Job bearbeitet. Aber wenn eine Datei nicht geteilt werden kann, kümmert sich ein einzelner Mapper um die ganze Datei.
Manche Jobs brauchen Fachwissen über die Integration von Hive mit Hadoop. Bei so einer speziellen Stelle wird sich der Personalchef auf diese Fragen konzentrieren:
Hive ist ein Data-Warehouse-System, das Batch-Jobs und Datenanalysen macht. Es wurde von Facebook entwickelt, um SQL-ähnliche Abfragen auf riesigen Datensätzen auszuführen, die in HDFS gespeichert sind, ohne dabei auf Java angewiesen zu sein.
Mit Hive können wir Daten in Tabellen organisieren und einen Megastore nutzen, um Metadaten wie Schemata zu speichern. Es unterstützt eine Reihe von Speichersystemen wie S3, Azure Data Lake Storage (ADLs) und Google Cloud Storage.
Der Hive Metastore (HMS) ist eine zentrale Datenbank für Metadaten. Es enthält Infos zu Tabellen, Ansichten und Zugriffsberechtigungen, die im HDFS-Objektspeicher gespeichert sind.
Es gibt zwei Arten von HIVE Metastore-Tabellen:
/user/hive/warehouse. Hive bietet super Unterstützung für die Integration mit vielen Programmiersprachen, was seine Vielseitigkeit und Benutzerfreundlichkeit in verschiedenen Anwendungen verbessert:
Dank der Integration mit HDFS und seiner skalierbaren Architektur kann Hive mit Petabytes an Daten umgehen. Es gibt keine feste Obergrenze für die Datenmenge, die Hive verarbeiten kann, was es zu einem super Tool für die Verarbeitung und Analyse von Big Data macht.
Hive hat eine ganze Reihe von Datentypen, um verschiedene Datenanforderungen zu erfüllen:
Eingebaute Datentypen:
|
Kategorie |
Datentyp |
Beschreibung |
Beispiel |
|
Numerische Typen |
TINYINT |
1-Byte-Ganzzahl mit Vorzeichen |
127 |
|
SMALLINT |
2-Byte-Ganzzahl mit Vorzeichen |
32767 |
|
|
INT |
4-Byte-Ganzzahl mit Vorzeichen |
2147483647 |
|
|
BIGINT |
8-Byte-Ganzzahl mit Vorzeichen |
9223372036854775807 |
|
|
FLOAT |
Einfachpräzisions-Gleitkomma |
3,14 |
|
|
DOUBLE |
Doppelpräzisions-Gleitkomma |
3.141592653589793 |
|
|
DECIMAL |
Beliebig genaue Dezimalzahl mit Vorzeichen |
1234567890.1234567890 |
|
|
Zeichenkettentypen |
STRING |
Zeichenkette mit variabler Länge |
Hey, Welt! |
|
VARCHAR |
Zeichenkette mit variabler Länge und einer festgelegten maximalen Länge |
'Beispiel' |
|
|
CHAR |
Zeichenkette mit fester Länge |
'A' |
|
|
Datums-/Zeit-Typen |
TIMESTAMP |
Datum und Uhrzeit, inklusive Zeitzone |
'2023-01-01 12:34:56' |
|
DATUM |
Datum ohne Uhrzeit |
„01.01.2023“ |
|
|
INTERVAL |
Zeitintervall |
INTERVALL „1“ TAG |
|
|
Verschiedene Typen |
BOOLEAN |
Stimmt oder stimmt nicht |
TRUE |
|
BINÄR |
Reihenfolge der Bytes |
0x1A2B3C |
Komplexe Datentypen:
|
Datentyp |
Beschreibung |
Beispiel |
|
ARRAY |
Geordnete Sammlung von Elementen |
ARRAY<STRING> ('Apfel', 'Banane', 'Kirsche') |
|
MAP |
Sammlung von Schlüssel-Wert-Paaren |
MAP<STRING, INT> ('Schlüssel1' -> 1, 'Schlüssel2' -> 2) |
|
STRUCT |
Sammlung von Feldern mit verschiedenen Datentypen |
STRUCT<name: STRING, Alter: INT> („Alice“, 30) |
|
UNIONTYPE |
Kann einen von mehreren bestimmten Typen aufnehmen |
UNIONTYPE<INT, DOUBLE, STRING> (1, 2.0, 'drei') |
Diese Fragen prüfen, wie gut du Hadoop für echte Probleme einsetzen kannst. Diese Fragen sind besonders wichtig, wenn du dich für eine Stelle als Datenarchitekt bewirbst, können aber auch in jedem anderen Vorstellungsgespräch gestellt werden, in dem Hadoop-Kenntnisse gefragt sind.
So repliziert Hadoop die Daten:
Die Replikationsstrategie von Hadoop in einem HDFS-Cluster mit drei Racks (A, B und C) ist so gemacht, dass sie die Lastverteilung optimiert, die Fehlertoleranz erhöht und die Netzwerkeffizienz verbessert. So wird das „ datafile.text “ auf eine Art und Weise nachgebildet, die Leistung und Zuverlässigkeit gut ausbalanciert.
Die Verwendung von Prüfsummen in Hadoops „ LocalFileSystem ” sorgt für Datenintegrität, indem:
.filename.crc ” im selben Verzeichnis.ChecksumException “ ausgelöst.Wenn wir diese Schritte befolgen, können wir sicherstellen, dass deine Anwendung die Datenintegrität aufrechterhält und mögliche Datenbeschädigungen sofort erkennt.
Hier ist, was wir machen können:
stderr zu protokollieren.Mit diesen Schritten können wir große Hadoop-Jobs systematisch debuggen und ungewöhnliche Fälle, die sich auf die Ausgabe auswirken, effektiv verfolgen und lösen.
Wenn du die Speichereinstellungen für einen Hadoop-Cluster mit YARN machst, ist es wichtig, die Speicherzuweisung zwischen Hadoop-Daemons, Systemprozessen und dem NodeManager auszugleichen, um die Leistung und die Ressourcennutzung zu optimieren.
Speicher für den NodeManager einstellen:
Speicher für MapReduce-Jobs einstellen:
mapreduce.map.memory.mb-Einstellungen anpassen: Dieser Parameter legt fest, wie viel Speicherplatz jeder Map-Aufgabe zugewiesen wird. Passe diese Einstellung an die Speicheranforderungen deiner Kartenaufgaben an.mapreduce.map.memory.mb “ auf 2048 MB setzt, bekommt jede Map-Aufgabe 2 GB Speicher.mapreduce.reduce.memory.mb-Einstellungen anpassen: Dieser Parameter legt fest, wie viel Speicherplatz für jede Reduzierungsaufgabe bereitgestellt wird. Passe diese Einstellung entsprechend den Speicheranforderungen deiner Reduzierungsaufgaben an.mapreduce.reduce.memory.mb “ auf 4096 MB setzt, bekommt jede Reduzierungsaufgabe 4 GB Speicher zugeteilt.yarn-site.xml “ mit Parametern wie „ yarn.nodemanager.resource.memory-mb “ richtig eingestellt ist. Diese sollte mit dem dem NodeManager zugewiesenen Speicher übereinstimmen.yarn.nodemanager.resource.memory-mb “ auf 59.000 MB setzen.Zusammenfassung der Speicherkonfiguration:
|
Komponente |
Konfiguration |
Beispielwerte |
|
NodeManager |
Gesamter physischer Speicher |
64.000 MB |
|
Speicher für Hadoop-Daemons |
3000 MB |
|
|
Speicher für Systemprozesse |
2000 MB |
|
|
Verfügbarer Speicher für NodeManager |
59.000 MB |
|
|
MapReduce-Map-Aufgabe |
mapreduce.map.memory.mb |
2048 MB |
|
MapReduce-Reduzierungsaufgabe |
mapreduce.reduce.memory.mb |
4096 MB |
|
Containergröße |
yarn.nodemanager.resource.memory-mb |
59.000 MB |
Nachdem du diese Fragen verstanden hast, solltest du die grundlegenden Begriffe kennen und ein
gute Kenntnisse der Komplexität realer Hadoop-Anwendungen. Außerdem musst du dich an neue Projekte auf Basis von Hadoop anpassen, um auf dem Laufenden zu bleiben und bei deinen Vorstellungsgesprächen zu punkten.
Du kannst auch dein Wissen über andere Big-Data-Frameworks wie Spark und Flink erweitern, da diese schnell sind und weniger Probleme mit Latenzzeiten haben als Hadoop.
Wenn du aber nach einem strukturierten Lernpfad suchst, um Big Data zu meistern, kannst du dir die folgenden Ressourcen anschauen:
Lerne mit diesen Kursen mehr über Data Engineering und Big Data!
Lernpfad
Kurs
Kurs