
Track
Professional Data Engineer in Python
40 hr
Hadoop experts write applications and analyze constantly changing data to obtain insights and maintain data security. That’s why hiring managers have strict criteria to find the best fit for the position and can ask you anything from basic to advanced.
In this article, we’ve collected 24 most commonly asked Hadoop interview questions and answers.
This article is designed to help you prepare thoroughly for your next big data job interview. It covers fundamental concepts and advanced scenarios. Whether you are a beginner or an experienced professional, you'll find valuable insights and practical information to boost your confidence and improve your chances of success.
Interviewers typically start an interview by asking basic questions to assess your understanding of Hadoop and its relevance in managing big data.
Even if you’re an experienced engineer, make sure you have these questions covered.
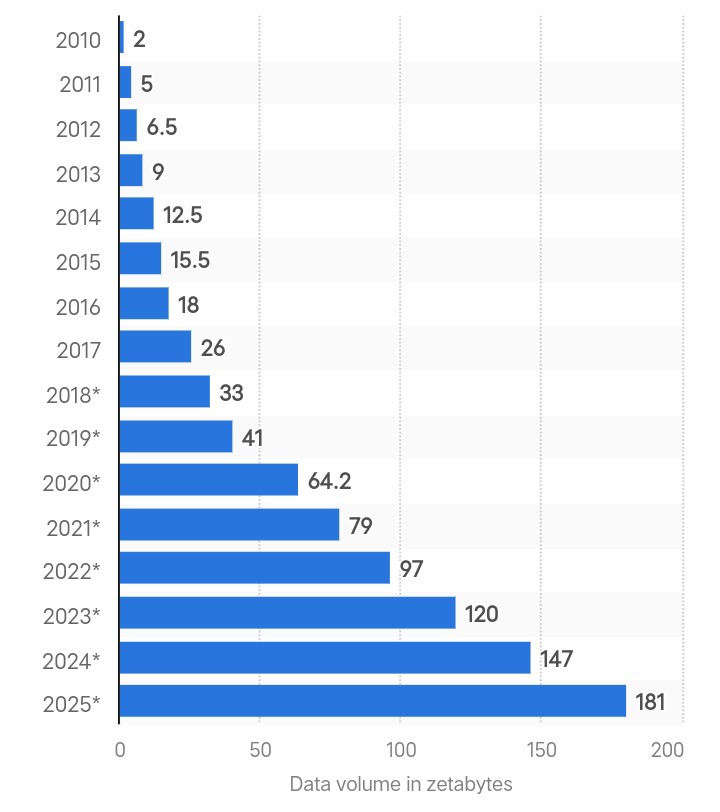
Global data creation in Zettabytes. Source: Statista.
Big data refers to massive amounts of complex data generated at high speed from multiple sources. The total amount of data created globally was 180 zettabytes in 2025 and is projected to triple by 2029.
As data generation accelerates, traditional analysis methods will fail to provide real-time processing and data security. That’s why companies use advanced frameworks like Hadoop to process and manage growing volumes of data.
If you want to start your career in big data, check out our guide on big data training.
Hadoop is an open-source framework for handling large datasets distributed across multiple computers. It stores data across multiple machines as small blocks using the Hadoop Distributed File System (HDFS).
With Hadoop, you can add more nodes to a cluster and handle extensive data without expensive hardware upgrades.
Even big companies like Google and Facebook rely on Hadoop to manage and analyze terabytes to petabytes of daily data.
The following are the two main components of Hadoop:
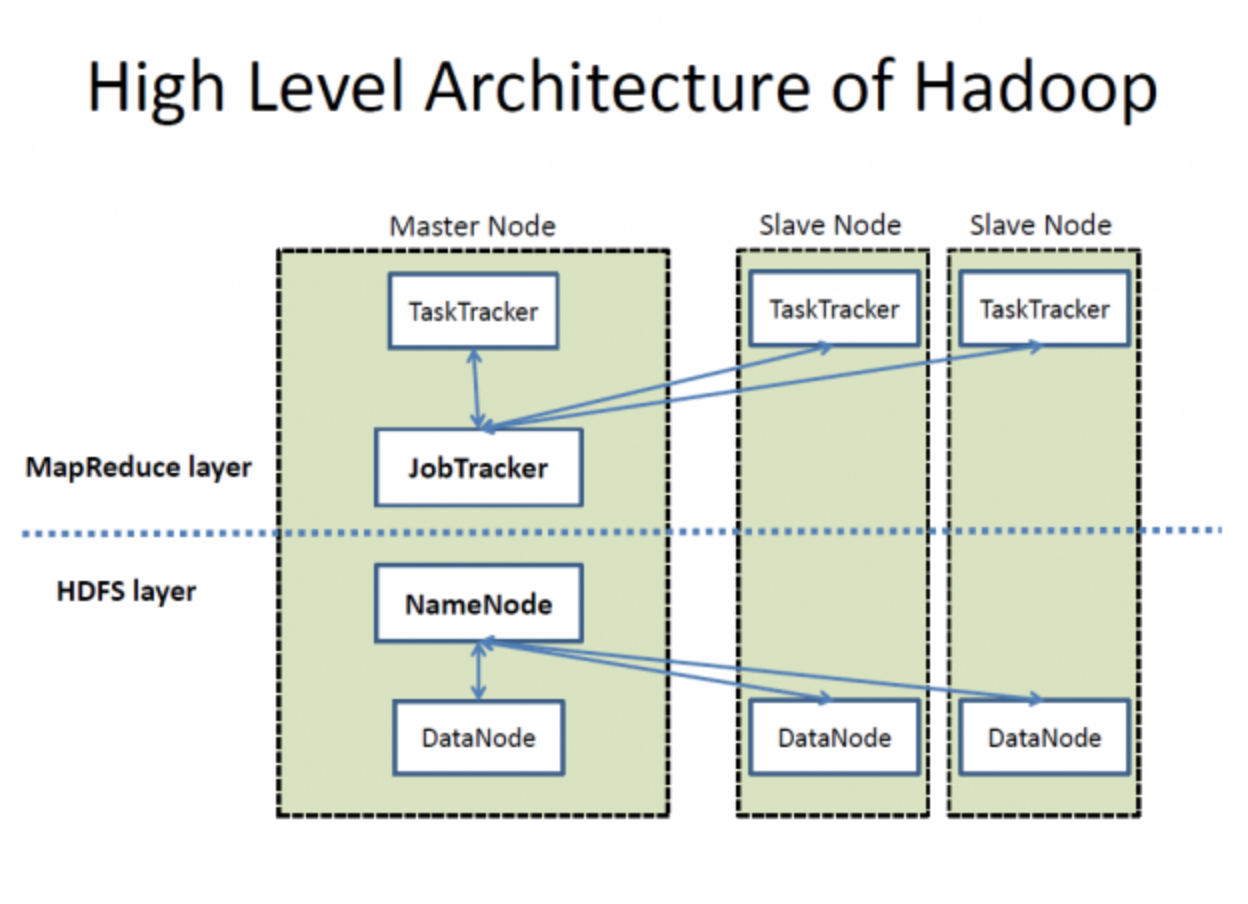
High-level architecture of Hadoop. Source: Wikimedia Commons
HDFS consists of a NameNode and multiple DataNodes for data management, as seen in the image above. Here's how they work:
In Hadoop 1.x, MapReduce handles resource management and job scheduling using JobTracker. However, slow processing is a significant drawback.
Hadoop 2.0 introduced YARN (Yet Another Resource Negotiator) to address these issues. YARN decouples resource management and job scheduling into separate components, which improves scalability and resource utilization. The primary components of YARN are:
How YARN works:
The intermediate questions are more focused on assessing your knowledge of the technicalities of the Hadoop framework. The interviewer can ask you about the Hadoop cluster, its challenges, and the comparison of different versions.
A Hadoop cluster is a collection of interconnected master and slave nodes designed to store and process large datasets in a distributed manner. The cluster architecture ensures high availability, scalability, and fault tolerance.
Components of a Hadoop Cluster:
There are two primary ways to set up a Hadoop cluster:
Comparison of On-Premises and Cloud-Based Clusters:
|
Feature |
On-premises cluster |
Cloud-based cluster |
|
Setup cost |
Higher initial investment |
Pay-as-you-go model |
|
Scalability |
Limited by physical hardware |
Virtually unlimited |
|
Maintenance |
Requires in-house management |
Managed by the cloud provider |
|
Flexibility |
Customizable hardware and software |
Pre-configured options |
|
Deployment time |
Longer setup time |
Quick and easy deployment |
There's no specific preference for cluster size. Cluster size is easily scalable and entirely dependent on the storage requirements. Small companies may rely on clusters with around 20 nodes, while businesses like Yahoo operate (or used to) on clusters as extensive as containing 40,000 nodes.
Different industries have specific data analysis and processing needs. So, Hadoop has released many projects to provide solutions that cater to them as part of its ecosystem. The list of Hadoop projects is broader than you can imagine—but here are the most essential ones:
Although the Hadoop framework is excellent at managing and processing enormous amounts of valuable data, it poses some critical challenges.
Let’s understand them:
HBase is a database designed for quick access to large files. It allows you to read and write big datasets in real time by storing data in columns and indexing them with unique row keys.
This setup enables quick data retrieval and efficient scans, which is suitable for large and sparsely populated tables because we can add as many nodes as needed.
HBase has three components:
This table compares both Hadoop versions side-by-side:
|
Criteria |
Hadoop 1.x |
Hadoop 2.0 |
|
NameNode management |
A single NameNode manages the Namespace |
Multiple NameNodes handle namespaces through HDFS federation |
|
Operating system support |
There's no support for Microsoft Windows |
Added support for Microsoft |
|
Job and resource management |
Uses JobTracker and TaskTracker for job and resource management |
Replaced them with YARN to separate both tasks |
|
Scalability |
Can scale up to 4,000 nodes per cluster |
Can scale up to 10,000 nodes per cluster |
|
DataNode size |
Has DataNode size of 64 MB |
Has doubled the size to 128 MB |
|
Task execution |
Uses slots that can run either Map or Reduce tasks |
Uses containers that can run any task |
If you’re applying for a data engineering job, check out our comprehensive article on data engineering interview questions.
Now, this is where things get interesting. These interview questions are asked to test you on an advanced level. These questions are particularly important for senior engineers.
In Hadoop 2.0, the Active NameNode manages the file system namespace and controls clients' access to files. On the contrary, the Standby NameNode is a backup and maintains enough information to take over if the Active NameNode fails.
This addresses the single point of failure (SPOF) issue, common in Hadoop 1. x.
HDFS is inefficient at processing thousands of small files, which results in increased latency. That’s why distributed cache allows you to store read-only, archive, and jar files and make them available for tasks in MapReduce.
Suppose you need to run 40 jobs in MapReduce, and each job needs to access the file from HDFS. In real-time, this number can grow to hundreds or thousands of reads. The application will frequently locate these files in HDFS, which will overload the HDFS and affect its performance.
However, a distributed cache can handle many small-sized files and doesn't compromise access time and processing speed.
Checksums identify corrupted data in HDFS. When data enters the system, it creates a small value known as a checksum. Hadoop recalculates the checksum when a user requests data transfer. If the new checksum matches the original, the data is intact; if not, it is corrupt.
Error detecting code for Hadoop is CRC-32.
HDFS achieves fault tolerance through a replication process that ensures reliability and availability. Here's how the replication process works:
Yes, it's possible to process compressed files with MapReduce. Hadoop supports multiple compression formats, but not all of them are splittable.
Following are the formats that MapReduce supports:
Out of all these, bzip2 is the only splittable format.
HDFS divides very large files into smaller parts, each 128 MB. For example, HDFS will break down a 1.28 GB file into ten blocks. Each block is then processed by a separate mapper in a MapReduce job. But if a file is unsplittable, a single mapper handles the entire file.
Some jobs require expertise in Hive integration with Hadoop. In such a specific role, the hiring manager will focus on these questions:
Hive is a data warehouse system that performs batch jobs and data analyses. It was developed by Facebook to run SQL–like queries on massive datasets stored in HDFS without relying on Java.
With Hive, we can organize data into tables and use a megastore to store metadata like schemas. It supports a spectrum of storage systems, such as S3, Azure Data Lake Storage (ADLs), and Google Cloud Storage.
The Hive Metastore (HMS) is a centralized database for metadata. It contains information about tables, views, and access permissions stored in HDFS object storage.
There are two types of HIVE Metastore tables:
/user/hive/warehouse. Hive provides robust support for integrating with multiple programming languages, enhancing its versatility and usability in different applications:
Due to its integration with HDFS and scalable architecture, Hive can handle petabytes of data. There is no fixed upper limit on the data size Hive can manage, making it a powerful tool for big data processing and analytics.
Hive offers a rich set of data types to handle different data requirements:
Built-in data types:
|
Category |
Data type |
Description |
Example |
|
Numeric types |
TINYINT |
1-byte signed integer |
127 |
|
SMALLINT |
2-byte signed integer |
32767 |
|
|
INT |
4-byte signed integer |
2147483647 |
|
|
BIGINT |
8-byte signed integer |
9223372036854775807 |
|
|
FLOAT |
Single-precision floating-point |
3.14 |
|
|
DOUBLE |
Double-precision floating-point |
3.141592653589793 |
|
|
DECIMAL |
Arbitrary-precision signed decimal number |
1234567890.1234567890 |
|
|
String types |
STRING |
Variable-length string |
'Hello, World!' |
|
VARCHAR |
Variable-length string with specified max length |
'Example' |
|
|
CHAR |
Fixed-length string |
'A' |
|
|
Date/Time types |
TIMESTAMP |
Date and time, including timezone |
'2023-01-01 12:34:56' |
|
DATE |
Date without time |
'2023-01-01' |
|
|
INTERVAL |
Time interval |
INTERVAL '1' DAY |
|
|
Misc. types |
BOOLEAN |
Represents true or false |
TRUE |
|
BINARY |
Sequence of bytes |
0x1A2B3C |
Complex Data Types:
|
Data Type |
Description |
Example |
|
ARRAY |
Ordered collection of elements |
ARRAY<STRING> ('apple', 'banana', 'cherry') |
|
MAP |
Collection of key-value pairs |
MAP<STRING, INT> ('key1' -> 1, 'key2' -> 2) |
|
STRUCT |
Collection of fields of different data types |
STRUCT<name: STRING, age: INT> ('Alice', 30) |
|
UNIONTYPE |
Can hold any one of several specified types |
UNIONTYPE<INT, DOUBLE, STRING> (1, 2.0, 'three') |
These questions test your ability to use Hadoop to handle real-life problems. They are particularly relevant if you’re applying for a data architect role but can be asked in any interview process that requires Hadoop knowledge.
Here's how Hadoop will replicate the data:
Hadoop's replication strategy in an HDFS cluster with three racks (A, B, and C) is designed to optimize load distribution, enhance fault tolerance, and improve network efficiency. This way, the datafile.text is replicated in a way that balances performance and reliability.
Using checksums in Hadoop's LocalFileSystem ensures data integrity by:
.filename.crc file in the same directory.ChecksumException in case of discrepancies.By following these steps, we can ensure that your application maintains data integrity and promptly detects any potential data corruption.
Here's what we can do:
stderr.Following these steps, we can systematically debug large-scale Hadoop jobs and effectively track and resolve unusual cases affecting the output.
When configuring memory settings for a Hadoop cluster using YARN, it’s important to balance the memory allocation between Hadoop daemons, system processes, and the NodeManager to optimize performance and resource utilization.
Setting memory for the NodeManager:
Setting memory for MapReduce jobs:
mapreduce.map.memory.mb: This parameter defines the amount of memory allocated for each map task. Adjust this setting based on the memory requirements of your map tasks.mapreduce.map.memory.mb to 2048 MB means each map task will be allocated 2 GB of memory.mapreduce.reduce.memory.mb: This parameter defines the amount of memory allocated for each reduce task. Adjust this setting based on the memory requirements of your reduce tasks.mapreduce.reduce.memory.mb to 4096 MB means each reduce task will be allocated 4 GB of memory.yarn-site.xml with parameters like yarn.nodemanager.resource.memory-mb, which should align with the memory allocated to the NodeManager.yarn.nodemanager.resource.memory-mb to 59,000 MB.Summary of memory configuration:
|
Component |
Configuration |
Example Values |
|
NodeManager |
Total physical memory |
64,000 MB |
|
Memory for Hadoop daemons |
3000 MB |
|
|
Memory for system processes |
2000 MB |
|
|
Available memory for NodeManager |
59,000 MB |
|
|
MapReduce map task |
mapreduce.map.memory.mb |
2048 MB |
|
MapReduce reduce task |
mapreduce.reduce.memory.mb |
4096 MB |
|
Container size |
yarn.nodemanager.resource.memory-mb |
59,000 MB |
After understanding these questions, you should know basic terms and have a
strong command of the complexities of real-life Hadoop applications. In addition to this, you must adapt to new projects built on Hadoop to stay relevant and ace your interviews.
You can also expand your knowledge on other big data frameworks, such as Spark and Flink, as they're fast and have lower latency issues than Hadoop.
But if you’re looking for a structured learning path to master big data, you can check out the following resources:
Learn more about data engineering and big data with these courses!
Track
Course
Course
blog
Marie Fayard
15 min
blog
Abid Ali Awan
15 min
blog
Vikash Singh
15 min
blog
Thalia Barrera
15 min
blog
Maria Eugenia Inzaugarat
15 min
blog
Gus Frazer
12 min
