
Cursus
Ingénieur professionnel en données en Python
40 h
Les experts Hadoop développent des applications et analysent des données en constante évolution afin d'obtenir des informations pertinentes et de garantir la sécurité des données. C'est pourquoi les responsables du recrutement ont des critères stricts pour trouver le candidat idéal pour le poste et peuvent vous poser toutes sortes de questions, des plus basiques aux plus avancées.
Dans cet article, nous avons rassemblé les 24 questions et réponses les plus fréquemment posées lors d'entretiens d'embauche concernant Hadoop.
Cet article a pour objectif de vous aider à vous préparer de manière approfondie à votre prochain entretien d'embauche dans le domaine du big data. Il couvre les concepts fondamentaux et les scénarios avancés. Que vous soyez débutant ou professionnel expérimenté, vous trouverez des informations précieuses et pratiques qui vous permettront de renforcer votre confiance et d'augmenter vos chances de réussite.
Les recruteurs commencent généralement l'entretien en posant des questions fondamentales afin d'évaluer votre compréhension de Hadoop et son importance dans la gestion des mégadonnées.
Même si vous êtes un ingénieur expérimenté, assurez-vous d'avoir répondu à ces questions.
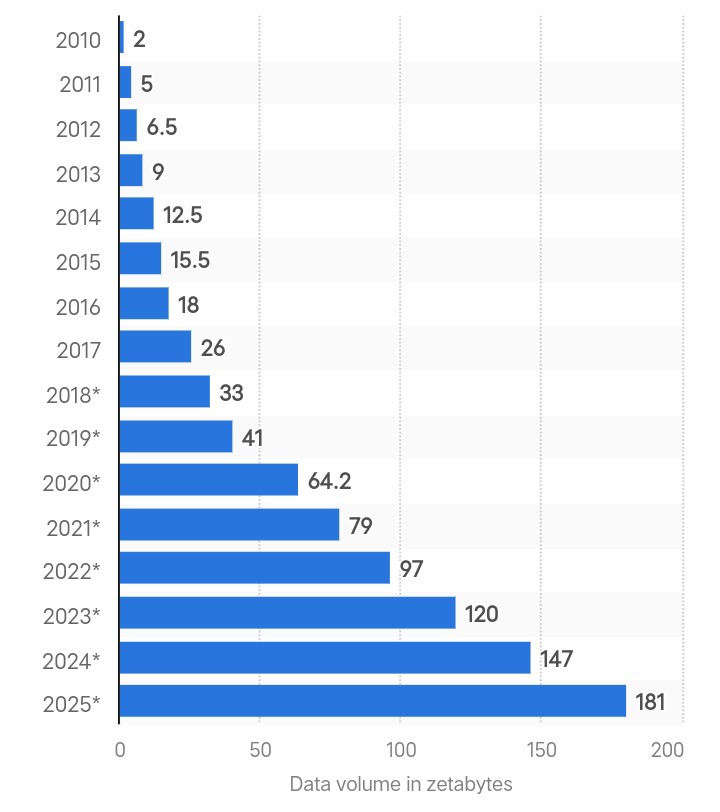
Création mondiale de données en zettaoctets. Source : Statista.
Le terme « mégadonnées » désigne les quantités considérables de données complexes générées à grande vitesse à partir de multiples sources. La quantité totale de données créées à l'échelle mondiale s'élevait à 180 zettaoctets en 2025 et devrait tripler d'ici 2029.
À mesure que la génération de données s'accélère, les méthodes d'analyse traditionnelles ne seront plus en mesure d'assurer le traitement en temps réel et la sécurité des données. C'est pourquoi les entreprises utilisent des infrastructures avancées telles que Hadoop pour traiter et gérer des volumes de données croissants.
Si vous souhaitez débuter votre carrière dans le domaine du big data, veuillez consulter notre guide sur les formations en big data.
Hadoop est un framework open source permettant de traiter de grands ensembles de données répartis sur plusieurs ordinateurs. Il stocke les données sur plusieurs machines sous forme de petits blocs à l'aide du système de fichiers distribués Hadoop (HDFS).
Avec Hadoop, il est possible d'ajouter des nœuds à un cluster et de traiter de grandes quantités de données sans avoir à procéder à des mises à niveau matérielles coûteuses.
Même de grandes entreprises telles que Google et Facebook s'appuient sur Hadoop pour gérer et analyser des téraoctets, voire des pétaoctets, de données quotidiennes.
Voici les deux principaux composants de Hadoop :
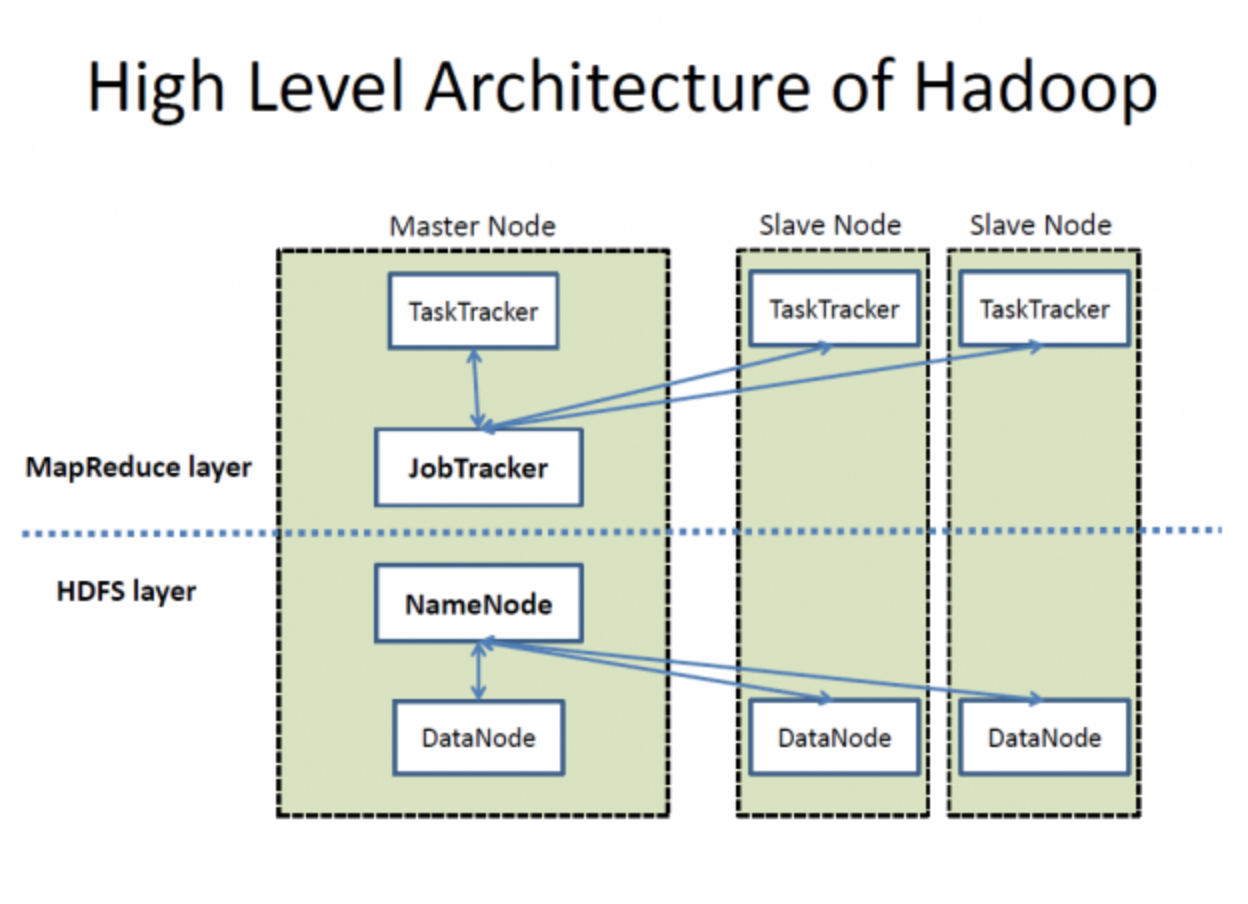
Architecture de haut niveau de Hadoop. Source : Wikimedia Commons
HDFS se compose d'un NameNode et de plusieurs DataNodes pour la gestion des données, comme illustré dans l'image ci-dessus. Voici comment ils fonctionnent :
Dans Hadoop 1.x, MapReduce gère la gestion des ressources et la planification des tâches à l'aide de JobTracker. Cependant, la lenteur du traitement constitue un inconvénient majeur.
Hadoop 2.0 a introduit YARN (Yet Another Resource Negotiator) afin de résoudre ces problèmes. YARN sépare la gestion des ressources et la planification des tâches en composants distincts, ce qui améliore l'évolutivité et l'utilisation des ressources. Les principaux composants de YARN sont les suivants :
Fonctionnement de YARN :
Les questions intermédiaires sont davantage axées sur l'évaluation de vos connaissances techniques du cadre Hadoop. L'intervieweur peut vous interroger sur le cluster Hadoop, ses défis et la comparaison entre différentes versions.
Un cluster Hadoop est un ensemble de nœuds maîtres et esclaves interconnectés, conçu pour stocker et traiter de grands ensembles de données de manière distribuée. L'architecture en cluster garantit une haute disponibilité, une évolutivité et une tolérance aux pannes.
Composants d'un cluster Hadoop :
Il existe deux méthodes principales pour configurer un cluster Hadoop :
Comparaison entre les clusters sur site et les clusters basés sur le cloud :
|
Caractéristique |
Cluster sur site |
Cluster basé sur le cloud |
|
Frais d'installation |
Investissement initial plus élevé |
Modèle de paiement à l'utilisation |
|
Évolutivité |
Limité par le matériel physique |
Pratiquement illimité |
|
Entretien |
Nécessite une gestion interne |
Géré par le fournisseur de services cloud |
|
Flexibilité |
Matériel et logiciels personnalisables |
Options préconfigurées |
|
Durée de déploiement |
Temps de configuration prolongé |
Déploiement rapide et simple |
Il n'y a pas de préférence particulière quant à la taille des clusters. La taille du cluster est facilement modulable et dépend entièrement des besoins en matière de stockage. Les petites entreprises peuvent s'appuyer sur des clusters d'environ 20 nœuds, tandis que des sociétés telles que Yahoo fonctionnent (ou fonctionnaient) sur des clusters pouvant contenir jusqu'à 40 000 nœuds.
Les différents secteurs ont des besoins spécifiques en matière d'analyse et de traitement des données. Hadoop a donc lancé de nombreux projets afin de fournir des solutions adaptées à ces besoins dans le cadre de son écosystème. La liste des projets Hadoop est plus longue que vous ne pouvez l'imaginer, mais voici les plus importants :
Bien que le framework Hadoop soit remarquable pour gérer et traiter d'énormes quantités de données précieuses, il présente certains défis importants.
Comprenons-les :
HBase est une base de données conçue pour permettre un accès rapide à des fichiers volumineux. Il vous permet de lire et d'écrire de grands ensembles de données en temps réel en stockant les données dans des colonnes et en les indexant à l'aide de clés de ligne uniques.
Cette configuration permet une récupération rapide des données et des analyses efficaces, ce qui convient aux tableaux volumineux et peu peuplés, car nous pouvons ajouter autant de nœuds que nécessaire.
HBase comprend trois composants :
Ce tableau compare les deux versions de Hadoop côte à côte :
|
Critères |
Hadoop 1.x |
Hadoop 2.0 |
|
Gestion du NameNode |
Un seul NameNode gère l'espace de noms. |
Plusieurs NameNodes gèrent les espaces de noms via la fédération HDFS. |
|
Prise en charge du système d'exploitation |
Il n'y a pas de prise en charge pour Microsoft Windows. |
Ajout de la prise en charge de Microsoft |
|
Gestion des tâches et des ressources |
Utilise JobTracker et TaskTracker pour la gestion des tâches et des ressources. |
Les avons remplacés par YARN afin de séparer les deux tâches. |
|
Évolutivité |
Peut évoluer jusqu'à 4 000 nœuds par cluster |
Peut évoluer jusqu'à 10 000 nœuds par cluster |
|
Taille du DataNode |
Dispose d'une taille DataNode de 64 Mo. |
A doublé la taille pour atteindre 128 Mo. |
|
Exécution des tâches |
Utilise des emplacements pouvant exécuter des tâches Map ou Reduce. |
Utilise des conteneurs capables d'exécuter n'importe quelle tâche. |
Si vous postulez à un poste d'ingénieur de données, veuillez consulter notre article complet sur les questions d'entretien relatives à l'ingénierie des données.
C'est là que les choses deviennent intéressantes. Ces questions d'entretien sont posées afin d'évaluer vos compétences à un niveau avancé. Ces questions revêtent une importance particulière pour les ingénieurs seniors.
Dans Hadoop 2.0, le NameNode actif gère l'espace de noms du système de fichiers et contrôle l'accès des clients aux fichiers. Au contraire, le Standby NameNode est une sauvegarde et conserve suffisamment d'informations pour prendre le relais en cas de défaillance du NameNode actif.
Ceci résout le problème du point de défaillance unique (SPOF), courant dans Hadoop 1. x.
HDFS n'est pas efficace pour traiter des milliers de petits fichiers, ce qui entraîne une augmentation de la latence. C'est pourquoi le cache distribué vous permet de stocker des fichiers en lecture seule, des fichiers d'archive et des fichiers jar, et de les rendre disponibles pour les tâches dans MapReduce.
Supposons que vous deviez exécuter 40 tâches dans MapReduce et que chaque tâche doive accéder au fichier depuis HDFS. En temps réel, ce nombre peut atteindre des centaines, voire des milliers de lectures. L'application localisera fréquemment ces fichiers dans HDFS, ce qui surchargera HDFS et affectera ses performances.
Cependant, un cache distribué peut gérer un grand nombre de fichiers de petite taille sans compromettre le temps d'accès ni la vitesse de traitement.
Les sommes de contrôle permettent d'identifier les données corrompues dans HDFS. Lorsque les données sont introduites dans le système, elles génèrent une petite valeur appelée « somme de contrôle ». Hadoop recalcule la somme de contrôle lorsqu'un utilisateur demande un transfert de données. Si la nouvelle somme de contrôle correspond à l'originale, les données sont intactes ; dans le cas contraire, elles sont corrompues.
Le code de détection d'erreur pour Hadoop est CRC-32.
HDFS assure la tolérance aux pannes grâce à un processus de réplication qui garantit la fiabilité et la disponibilité. Voici comment fonctionne le processus de réplication :
Oui, il est possible de traiter des fichiers compressés avec MapReduce. Hadoop prend en charge plusieurs formats de compression, mais tous ne sont pas divisibles.
Voici les formats pris en charge par MapReduce :
Parmi tous ces formats, bzip2 est le seul format fractionnable.
HDFS divise les fichiers de très grande taille en parties plus petites, chacune d'une taille de 128 Mo. Par exemple, HDFS divisera un fichier de 1,28 Go en dix blocs. Chaque bloc est ensuite traité par un mappeur distinct dans une tâche MapReduce. Cependant, si un fichier ne peut pas être divisé, un seul mappeur traite l'intégralité du fichier.
Certains postes requièrent une expertise dans l'intégration de Hive avec Hadoop. Dans le cadre d'un poste aussi spécifique, le responsable du recrutement se concentrera sur les questions suivantes :
Hive est un système d'entrepôt de données qui exécute des tâches par lots et des analyses de données. Il a été développé par Facebook pour exécuter des requêtes de type SQL sur des ensembles de données volumineux stockés dans HDFS sans dépendre de Java.
Avec Hive, nous pouvons organiser les données dans des tableaux et utiliser un mégastore pour stocker des métadonnées telles que des schémas. Il prend en charge une gamme de systèmes de stockage, tels que S3, Azure Data Lake Storage (ADL) et Google Cloud Storage.
Le Hive Metastore (HMS) est une base de données centralisée pour les métadonnées. Il contient des informations sur les tables, les vues et les autorisations d'accès stockées dans le stockage d'objets HDFS.
Il existe deux types de tables HIVE Metastore :
/user/hive/warehouse. Hive offre une prise en charge solide pour l'intégration avec plusieurs langages de programmation, ce qui améliore sa polyvalence et sa facilité d'utilisation dans différentes applications :
Grâce à son intégration avec HDFS et à son architecture évolutive, Hive est capable de traiter des pétaoctets de données. Il n'y a pas de limite supérieure fixe à la taille des données que Hive peut gérer, ce qui en fait un outil puissant pour le traitement et l'analyse des mégadonnées.
Hive propose un ensemble complet de types de données pour répondre à différentes exigences en matière de données :
Types de données intégrés :
|
Catégorie |
Type de données |
Description |
Exemple |
|
Types numériques |
TINYINT |
entier signé à 1 octet |
127 |
|
SMALLINT |
entier signé à 2 octets |
32767 |
|
|
INT |
Entier signé de 4 octets |
2147483647 |
|
|
BIGINT |
Entier signé de 8 octets |
9223372036854775807 |
|
|
FLOAT |
Précision simple en virgule flottante |
3,14 |
|
|
DOUBLE |
Double précision en virgule flottante |
3.141592653589793 |
|
|
DÉCIMAL |
Nombre décimal signé à précision arbitraire |
1234567890.1234567890 |
|
|
Types de chaînes |
STRING |
Chaîne de longueur variable |
Bonjour, tout le monde ! |
|
VARCHAR |
Chaîne de longueur variable avec longueur maximale spécifiée |
« Exemple » |
|
|
CHAR |
Chaîne de longueur fixe |
'A' |
|
|
Types Date/Heure |
TIMESTAMP |
Date et heure, y compris le fuseau horaire |
'2023-01-01 12:34:56' |
|
DATE |
Date sans heure |
'2023-01-01' |
|
|
INTERVAL |
Intervalle de temps |
INTERVALLE « 1 » JOUR |
|
|
Types divers |
BOOLÉEN |
Représente vrai ou faux |
VRAI |
|
BINAIRE |
Séquence d'octets |
0x1A2B3C |
Types de données complexes :
|
Type de données |
Description |
Exemple |
|
ARRAY |
Collection ordonnée d'éléments |
ARRAY<STRING> ('pomme', 'banane', 'cerise') |
|
MAP |
Collection de paires clé-valeur |
MAP<STRING, INT> ('key1' -> 1, 'key2' -> 2) |
|
STRUCT |
Ensemble de champs de différents types de données |
STRUCT<nom : STRING, âge : INT> (« Alice », 30 ans) |
|
UNIONTYPE |
Peut contenir l'un des types spécifiés |
UNIONTYPE<INT, DOUBLE, STRING> (1, 2,0, « trois ») |
Ces questions évaluent votre capacité à utiliser Hadoop pour résoudre des problèmes concrets. Ces questions sont particulièrement pertinentes si vous postulez à un poste d'architecte de données, mais elles peuvent être posées lors de tout entretien d'embauche nécessitant des connaissances en Hadoop.
Voici comment Hadoop procède à la réplication des données :
La stratégie de réplication de Hadoop dans un cluster HDFS comprenant trois racks (A, B et C) est conçue pour optimiser la répartition de la charge, renforcer la tolérance aux pannes et améliorer l'efficacité du réseau. De cette manière, l'datafile.text est reproduite de manière à équilibrer performances et fiabilité.
L'utilisation de sommes de contrôle dans l' LocalFileSystem de Hadoop garantit l'intégrité des données en :
.filename.crc » situé dans le même répertoire.ChecksumException Signaler toute anomalie en cas de divergences.En suivant ces étapes, nous pouvons garantir que votre application préserve l'intégrité des données et détecte rapidement toute corruption potentielle des données.
Voici ce que nous pouvons réaliser :
stderr.En suivant ces étapes, nous pouvons systématiquement déboguer les tâches Hadoop à grande échelle et suivre et résoudre efficacement les cas inhabituels affectant le résultat.
Lors de la configuration des paramètres de mémoire pour un cluster Hadoop à l'aide de YARN, il est essentiel d'équilibrer l'allocation de mémoire entre les démons Hadoop, les processus système et le NodeManager afin d'optimiser les performances et l'utilisation des ressources.
Configuration de la mémoire pour NodeManager :
Configuration de la mémoire pour les tâches MapReduce :
mapreduce.map.memory.mb: Ce paramètre définit la quantité de mémoire allouée à chaque tâche de mappage. Veuillez ajuster ce paramètre en fonction des besoins en mémoire de vos tâches cartographiques.mapreduce.map.memory.mb sur 2048 Mo signifie que chaque tâche de mappage se verra allouer 2 Go de mémoire.mapreduce.reduce.memory.mb: Ce paramètre définit la quantité de mémoire allouée à chaque tâche de réduction. Veuillez ajuster ce paramètre en fonction des besoins en mémoire de vos tâches de réduction.mapreduce.reduce.memory.mb sur 4096 Mo signifie que chaque tâche de réduction se verra allouer 4 Go de mémoire.yarn-site.xml à l'aide de paramètres tels que yarn.nodemanager.resource.memory-mb, qui doivent correspondre à la mémoire allouée au NodeManager.yarn.nodemanager.resource.memory-mb sur 59 000 Mo.Résumé de la configuration de la mémoire :
|
Composant |
Configuration |
Exemples de valeurs |
|
NodeManager |
Mémoire physique totale |
64 000 MO |
|
Mémoire pour les démons Hadoop |
3000 MO |
|
|
Mémoire pour les processus système |
2000 MO |
|
|
Mémoire disponible pour NodeManager |
59 000 MO |
|
|
Tâche de cartographie MapReduce |
mapreduce.map.memory.mb |
2048 MO |
|
Tâche de réduction MapReduce |
mapreduce.reduce.memory.mb |
4096 MO |
|
Taille du conteneur |
yarn.nodemanager.resource.memory-mb |
59 000 MO |
Après avoir compris ces questions, vous devriez connaître les termes de base et avoir une
Maîtrise approfondie des complexités des applications Hadoop dans la vie réelle. De plus, il est nécessaire de vous adapter aux nouveaux projets développés sur Hadoop afin de rester compétitif et de réussir vos entretiens.
Vous pouvez également approfondir vos connaissances sur d'autres frameworks Big Data, tels que Spark et Flink, car ils sont rapides et présentent moins de problèmes de latence que Hadoop.
Si vous recherchez un parcours d'apprentissage structuré pour maîtriser le big data, vous pouvez consulter les ressources suivantes :
Veuillez approfondir vos connaissances en ingénierie des données et en mégadonnées grâce à ces cours.
Cursus
Cours
Cours