programa
Fundamentos de la IA
10 h
El lanzamiento de DeepSeek-R1 sacudió la industria de la IA y provocó importantes caídas en las acciones de NVIDIA y las principales empresas estadounidenses de IA.
DeepSeek acaba de presentar Janus-Pro, su modelo multimodal más reciente diseñado para la generación de texto e imágenes. Al igual que R1, Janus Pro es de código abierto y obtiene buenos resultados en los benchmarks. En pocas palabras, es un serio competidor del DALL-E 3 de OpenAI y del Stable Diffusion de Stability AI en el ámbito de la IA multimodal.
En este blog, te presentaré Janus Pro y explicaré qué es, qué es la IA multimodal, cómo funciona y cómo acceder. También lo compararé con DALL-E 3 con algunos prompts.
Janus-Pro es el modelo de IA multimodal más reciente de DeepSeek, diseñado para manejar tareas que implican tanto texto como imágenes. Introduce varias mejoras respecto al modelo Janus original, como mejores estrategias de entrenamiento, conjuntos de datos más amplios y tamaños de modelo escalados (disponibles en las versiones de parámetros 1B y 7B).

Janus frente a Janus Pro-7b. Fuente: Documento de lanzamiento de Janus-Pro.
A diferencia de los modelos de IA que se especializan en un solo tipo de entrada, los modelos de IA multimodal como Janus-Pro se construyen para comprender y conectar estas dos modalidades. Por ejemplo, puedes subir una imagen y hacer una pregunta de texto sobre ella, como identificar objetos en la escena, interpretar texto dentro de la imagen o incluso analizar su contexto.
Reconocimiento de texto con Janus-Pro. Fuente: Documento de lanzamiento de Janus-Pro.
Janus-Pro puede generar imágenes de alta calidad a partir de prompts de texto, como la creación de ilustraciones detalladas, diseños de productos o imágenes realistas basadas en instrucciones específicas. También puede analizar entradas visuales, como identificar objetos en una foto, leer e interpretar texto dentro de una imagen o responder preguntas sobre un gráfico o diagrama.

Generación de texto a imagen con Janus-Pro. Fuente: Documento de lanzamiento de Janus-Pro.
Janus-Pro viene en dos tamaños (parámetros 1B y 7B) que ofrecen flexibilidad en función del hardware del que dispongas.
Janus-Pro está diseñado para manejar tanto la comprensión como la generación de texto e imágenes. Para ello, introduce algunas mejoras inteligentes respecto a su predecesor. Deja que te explique sus componentes clave de una forma más fácil de digerir.
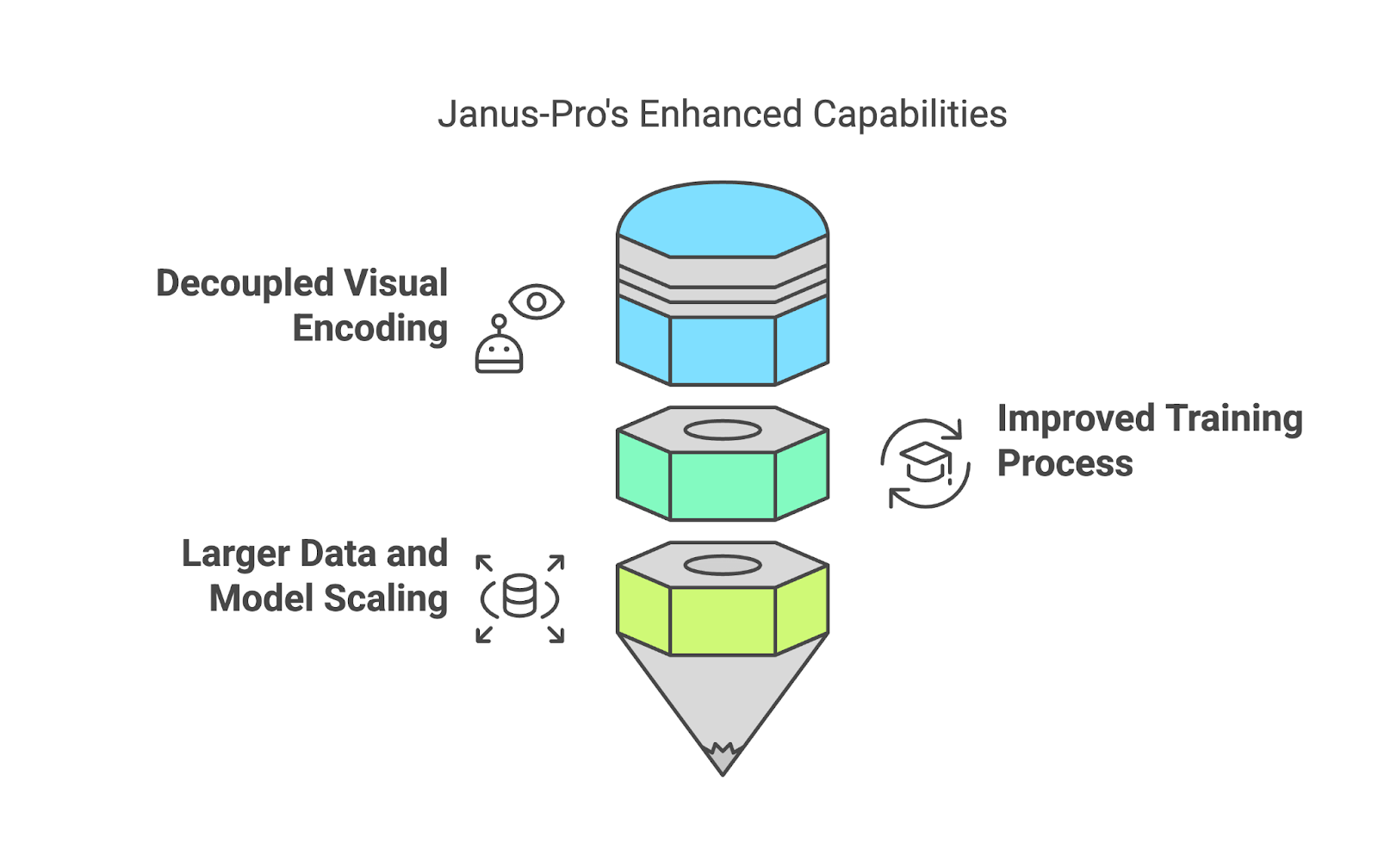
Una de las funciones más destacadas de Janus-Pro es que no utiliza un único sistema para gestionar tanto la interpretación como la creación de imágenes. En su lugar, separa estos procesos (codificación visual desacoplada).
Por ejemplo, cuando subes una imagen y haces una pregunta sobre ella, Janus-Pro utiliza un sistema especializado para "leer" la imagen y averiguar qué es importante. En cambio, cuando le pides que cree una imagen a partir de una descripción de texto, cambia a un sistema diferente que se centra en generar elementos visuales. Esta separación permite al modelo realizar mejor ambas tareas y evitar las limitaciones derivadas de obligar a un sistema a encargarse de todo.
El entrenamiento de Janus-Pro se divide en tres etapas, cada una destinada a perfeccionar sus capacidades:
Janus-Pro amplía sus capacidades al utilizar tanto datos del mundo real como datos sintéticos a partes iguales. Esta mezcla no solo garantiza resultados de mayor calidad, sino que también mejora la estabilidad durante tareas como la generación de imágenes.
En esta sección, compararé Janus-Pro-7B y DALL-E 3 en cuanto a comprensión multimodal y generación de texto a imagen. Esta comparación pretende darte una idea práctica de estos modelos en acción, pero no sustituye la profundidad de las mediciones sistemáticas de referencia.
He subido la imagen que se muestra a continuación y he preguntado tanto a Janus-Pro-7B como a DALL-E 3:
"En una frase, ¿cuál es la idea principal de esta imagen?"
Fuente: Página GitHub de Janus-Pro.
Aquí tienes las respuestas:
Janus-Pro: La principal conclusión de esta imagen es que el modelo Janus consigue el mayor rendimiento medio en las tareas de comprensión multimodal, al tiempo que demuestra una gran precisión en los benchmarks de seguimiento de instrucciones para la generación de texto a imagen.
DALL-E 3: Los modelos Janus-Pro, en particular Janus-Pro-7B, superan a otros modelos multimodales tanto en comprensión como en seguimiento de instrucciones, por lo que demuestran una gran capacidad en tareas de texto e imagen.
Aunque ambos modelos resumen bien el gráfico, Janus-Pro denomina incorrectamente el gráfico "modelo Janus", sin distinguirlo de Janus-Pro. Sin embargo, DALL-E 3 identifica específicamente los "modelos Janus-Pro, en particular Janus-Pro-7B", lo que demuestra una mejor comprensión del contexto.
Se trata solo de un ejemplo aislado, por lo que no podemos sacar conclusiones generales.
He probado este prompt porque puede ser algo que tenga un uso real en la práctica:
"Un diseño moderno de un espacio de oficina con puestos de trabajo colaborativos, cabinas de reunión privadas y luz natural, renderizado en estilo 3D"
DALL-E 3 ha generado esta imagen a continuación, que contiene todos los elementos del prompt: espacio de oficina moderno, puestos de trabajo colaborativos, cabinas de reunión privadas, luz natural y renderizado en 3D. Sin embargo, si te fijas bien, notarás bastantes artefactos, como los siguientes:

He introducido un prompt para Janus-Pro-7B sobre Hugging Face. El modelo ha generado cinco imágenes y todas ellas tienen muy mal aspecto:
En la primera imagen, podemos detectar algunos artefactos importantes sin mucho esfuerzo:
Podrás reproducir este resultado en Hugging Face con el mismo prompt y los siguientes parámetros y semillas:
A pesar de experimentar con distintos parámetros y semillas, no pude obtener mejores resultados con Janus-Pro-7B. De nuevo, esto es solo un ejemplo y no aporta pruebas suficientes para sacar conclusiones generales sobre ninguno de los dos modelos.
Janus-Pro se ha probado en varios benchmarks para medir su rendimiento tanto en la comprensión multimodal como en la generación de texto a imagen. Los resultados muestran mejoras respecto a su predecesor, Janus, y lo sitúan entre los modelos de mayor rendimiento de su categoría.
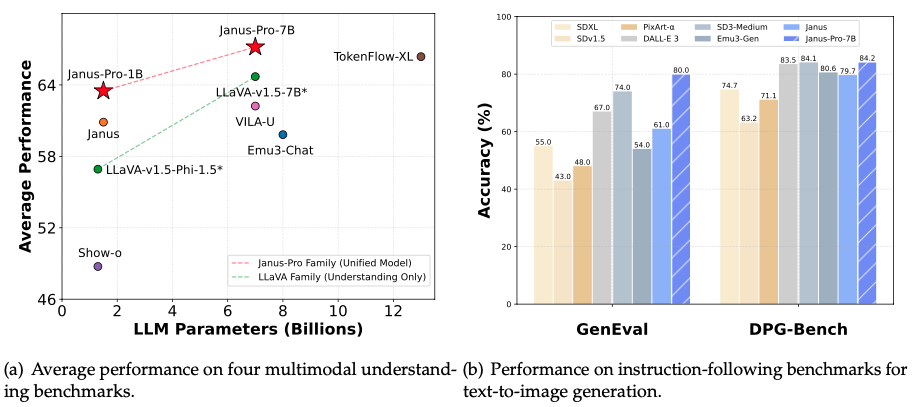
Fuente: Página GitHub de Janus-Pro.
El gráfico de la izquierda de la imagen superior muestra el rendimiento de Janus-Pro en cuatro benchmarks de comprensión multimodal: el equipo de DeepSeek promedió la precisión de POPE, MME-Perception, GQA y MMMU. La conclusión clave es que Janus-Pro-7B supera a su homólogo más pequeño, Janus-Pro-1B, así como a otros modelos multimodales como LLaVA-v1,5-7B y VILA-U.
El gráfico de la derecha compara Janus-Pro-7B con otros modelos líderes en bechmarks de seguimiento de instrucciones para la generación de texto a imagen, concretamente GenEval y DPG-Bench:
Puedes probar Janus-Pro sin una configuración compleja si utilizas algunos métodos diferentes.
La forma más rápida de probar Janus-Pro es a través de su demo Hugging Face Spaces, donde puedes introducir prompts y generar texto o imágenes directamente en tu navegador. No requiere instalación ni configuración.
Si prefieres una configuración local con una interfaz fácil de usar, DeepSeek proporciona una demo basada en Gradio. Esto te permite interactuar con Janus-Pro a través de una GUI basada en la web en tu equipo. Para utilizarla, sigue las instrucciones del repositorio oficial de Janus en el repositorio oficial de GitHub.
Janus-Pro es el último movimiento de DeepSeek en el espacio de la IA multimodal y ofrece una alternativa de código abierto a modelos como DALL-E 3. Mejora a su predecesor con un mejor entrenamiento, conjuntos de datos más amplios y una arquitectura desacoplada para manejar texto e imágenes con mayor eficacia.
En mi comparación directa con DALL-E 3, Janus-Pro mostró algunas debilidades en la generación de texto a imagen y produjo notables artefactos e incoherencias. Sin embargo, obtuvo buenos resultados en tareas de comprensión multimodal. Dicho esto, se trata solo de una prueba limitada y no aporta pruebas suficientes para sacar conclusiones generales sobre las capacidades generales del modelo.
Aprende IA con estos cursos
programa
programa
Curso
blog
Ryan Ong
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Kurtis Pykes
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali

