
Track
AI Fundamentals
10 hr
The release of DeepSeek-R1 shook the AI industry, causing significant stock drops for NVIDIA and major American AI companies.
DeepSeek has now introduced Janus-Pro, its latest multimodal model designed for text and image generation. Like R1, Janus Pro is open-source and delivers strong benchmark results. Simply put, it’s a serious competitor to OpenAI’s DALL-E 3 and Stability AI’s Stable Diffusion in the multimodal AI space.
In this blog, I’ll explain Janus Pro, what it is, what multimodal AI means, how it works, and how to access it. I’ll also compare it with DALL-E 3 on a few prompts.
Janus-Pro is DeepSeek’s newest multimodal AI model, designed to handle tasks involving both text and images. It introduces several improvements over the original Janus model, including better training strategies, larger datasets, and scaled model sizes (available in 1B and 7B parameter versions).

Janus vs. Janus Pro-7b. Source: Janus-Pro’s release paper.
Unlike AI models that specialize in only one type of input, multimodal AI models like Janus-Pro are built to understand and connect these two modalities. For example, you can upload an image and ask a text-based question about it—such as identifying objects in the scene, interpreting text within the image, or even analyzing its context.
Text recognition with Janus-Pro. Source: Janus-Pro’s release paper.
Janus-Pro can generate high-quality images from text prompts, such as creating detailed artwork, product designs, or realistic visualizations based on specific instructions. It can also analyze visual inputs, like identifying objects in a photo, reading and interpreting text within an image, or answering questions about a chart or diagram.

Text-to-image generation with Janus-Pro. Source: Janus-Pro’s release paper.
Janus-Pro comes in two sizes—1B and 7B parameters—offering flexibility depending on your hardware.
Janus-Pro is designed to handle both understanding and generating text and images, and it achieves this by making some clever improvements over its predecessor. Let me explain its key components in a way that’s easier to digest.
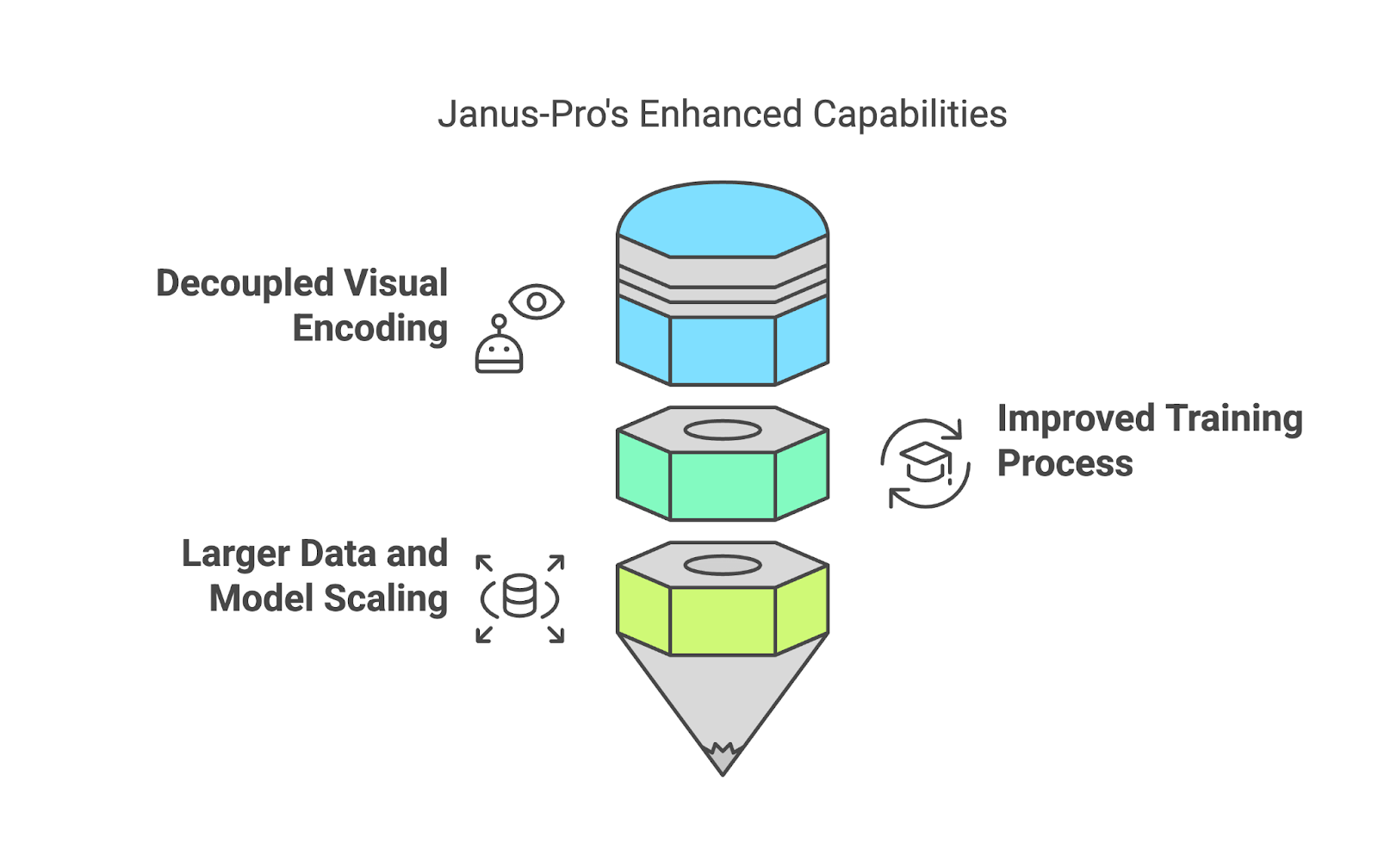
One of the standout features of Janus-Pro is that it doesn’t use a single system to handle both interpreting and creating visuals. Instead, it separates these processes (decoupled visual encoding).
For example, when you upload an image and ask a question about it, Janus-Pro uses a specialized system to “read” the image and figure out what’s important. On the other hand, when you ask it to create an image from a text description, it switches to a different system that focuses on generating visuals. This separation allows the model to do both tasks better—avoiding the compromises that happen when one system is forced to handle everything.
Janus-Pro’s training is divided into three stages, each designed to refine its capabilities:
Janus-Pro scales up its capabilities by using both real-world and synthetic data in equal parts. This mix not only ensures higher-quality results but also improves stability during tasks like image generation.
In this section, I’ll compare Janus-Pro-7B and DALL-E 3 in multimodal understanding and text-to-image generation. This comparison is meant to give you a practical sense of these models in action, but it’s not a substitute for the depth of systematic benchmark measurements.
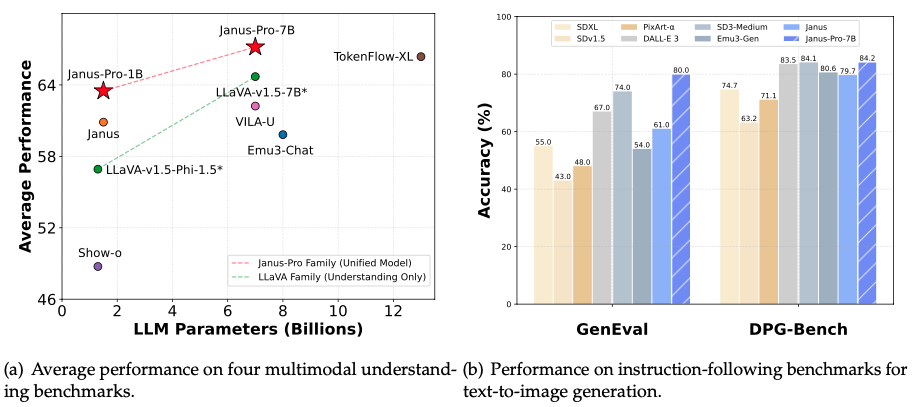
I uploaded the image below and asked both Janus-Pro-7B and DALL-E 3:
“In one sentence, what's the main takeaway of this image?”
Source: Janus-Pro’s GitHub page.
Here are the responses:
Janus-Pro: The main takeaway of this image is that the Janus model achieves the highest average performance on multimodal understanding tasks, while also demonstrating high accuracy on instruction-following benchmarks for text-to-image generation.
DALL-E 3: The Janus-Pro models, particularly Janus-Pro-7B, outperform other multimodal models in both understanding and instruction-following benchmarks, demonstrating strong capabilities across text and image tasks.
While both models summarize the graph well, Janus-Pro incorrectly refers to “the Janus model,” failing to distinguish it from Janus-Pro. DALL-E 3, however, specifically identifies “Janus-Pro models, particularly Janus-Pro-7B,” showing better contextual understanding.
This is just an isolated example, so we can’t draw any general conclusions.
I tried this prompt because it might be something that has an actual use in practice:
“A modern office space design with collaborative workstations, private meeting pods, and natural light, presented as a 3D-style rendering”
DALL-E 3 generated this image below, which checks all the elements in the prompt: modern office space, collaborative workstations, private meeting pods, natural light, and 3D-style rendering. However, once you look closely, you’ll notice quite a few artifacts, like:

I prompted Janus-Pro-7B on Hugging Face. The model generated five images, and all of them look pretty bad:
By looking at the first image, we can spot a few major artifacts without much effort:
You’ll be able to reproduce this result on Hugging Face by using the same prompt and the following parameters and seed:
Despite experimenting with different parameters and seeds, I couldn’t produce better outputs with Janus-Pro-7B. Again, this is just one example and doesn’t provide enough evidence to make broad conclusions about either model.
Janus-Pro has been tested across multiple benchmarks to measure its performance in both multimodal understanding and text-to-image generation. The results show improvements over its predecessor, Janus, and place it among the top-performing models in its category.
Source: Janus-Pro’s GitHub page.
The left chart in the image above shows how Janus-Pro performs on four multimodal understanding benchmarks—the DeepSeek team averaged the accuracy of POPE, MME-Perception, GQA, and MMMU. The key takeaway is that Janus-Pro-7B outperforms its smaller counterpart, Janus-Pro-1B, as well as other multimodal models like LLaVA-v1.5-7B and VILA-U.
The right chart compares Janus-Pro-7B with other leading models in instruction-following benchmarks for text-to-image generation, specifically GenEval and DPG-Bench:
You can try Janus-Pro without complex setup using a few different methods.
The fastest way to test Janus-Pro is through its Hugging Face Spaces demo, where you can enter prompts and generate text or images directly in your browser. This requires no installation or setup.
If you prefer a local setup with a user-friendly interface, DeepSeek provides a Gradio-based demo. This lets you interact with Janus-Pro through a web-based GUI on your machine. To use it, follow the instructions on Janus's official GitHub repository.
Janus-Pro is DeepSeek’s latest move in the multimodal AI space, offering an open-source alternative to models like DALL-E 3. It improves upon its predecessor with better training, larger datasets, and a decoupled architecture for handling text and images more effectively.
In my head-to-head comparison with DALL-E 3, Janus-Pro showed some weaknesses in text-to-image generation, producing noticeable artifacts and inconsistencies. However, it performed well in multimodal understanding tasks. That said, this is just a limited test and doesn’t provide enough evidence to draw general conclusions about the model’s overall capabilities.
Learn AI with these courses!
Track
Track
Course
blog
Alex Olteanu
8 min
blog
François Aubry
8 min
blog
Vinod Chugani
7 min
blog
Dr Ana Rojo-Echeburúa
8 min
Tutorial
Abid Ali Awan
Tutorial
Dr Ana Rojo-Echeburúa

