Lernpfad
Grundlagen der KI
10 Std.
Die Veröffentlichung von DeepSeek-R1 erschütterte die KI-Branche und führte zu erheblichen Aktienverlusten bei NVIDIA und großen amerikanischen KI-Unternehmen.
DeepSeek hat jetzt Janus-Provorgestellt , sein neuestes multimodales Modell, das für die Text- und Bilderzeugung entwickelt wurde. Wie R1 ist auch Janus Pro quelloffen und liefert starke Benchmark-Ergebnisse. Einfach gesagt, ist es ein ernsthafter Konkurrent für DALL-E 3 von OpenAI und Stable Diffusion von Stability AI im Bereich der multimodalen KI.
In diesem Blog erkläre ich dir, was Janus Pro ist, was multimodale KI bedeutet, wie sie funktioniert und wie du sie nutzen kannst. Ich vergleiche es auch mit DALL-E 3 in einigen Punkten.
Janus-Pro ist DeepSeeks neuestes multimodales KI-Modell, das für die Bearbeitung von Aufgaben entwickelt wurde, die sowohl Text als auch Bilder beinhalten. Es enthält mehrere Verbesserungen gegenüber dem ursprünglichen Janus-Modell, darunter bessere Trainingsstrategien, größere Datensätze und skalierte Modellgrößen (verfügbar in den Parameterversionen 1B und 7B).

Janus vs. Janus Pro-7b. Quelle: Janus-Pro's Veröffentlichungspapier.
Im Gegensatz zu KI-Modellen, die sich nur auf eine Art von Input spezialisieren, sind multimodale KI-Modelle wie Janus-Pro darauf ausgelegt, diese beiden Modalitäten zu verstehen und zu verbinden. Du kannst z.B. ein Bild hochladen und eine textbasierte Frage dazu stellen, wie z.B. Objekte in der Szene zu identifizieren, Text im Bild zu interpretieren oder sogar den Kontext zu analysieren.
Texterkennung mit Janus-Pro. Quelle: Janus-Pro's Veröffentlichungspapier.
Janus-Pro kann hochwertige Bilder aus Textvorgaben generieren, z. B. detaillierte Grafiken, Produktdesigns oder realistische Visualisierungen auf der Grundlage bestimmter Anweisungen. Er kann auch visuelle Eingaben analysieren, z. B. Objekte auf einem Foto identifizieren, Text in einem Bild lesen und interpretieren oder Fragen zu einer Tabelle oder einem Diagramm beantworten.

Text-zu-Bild-Generierung mit Janus-Pro. Quelle: Janus-Pro's Veröffentlichungspapier.
Janus-Pro ist in zwei Größen erhältlich - 1B und 7B Parameter - und bietet damit Flexibilität je nach deiner Hardware.
Janus-Pro ist so konzipiert, dass es sowohl das Verstehen als auch das Erzeugen von Text und Bildern beherrscht, und das erreicht es durch einige clevere Verbesserungen gegenüber seinem Vorgänger. Ich möchte dir die wichtigsten Bestandteile auf eine leichter verdauliche Art und Weise erklären.
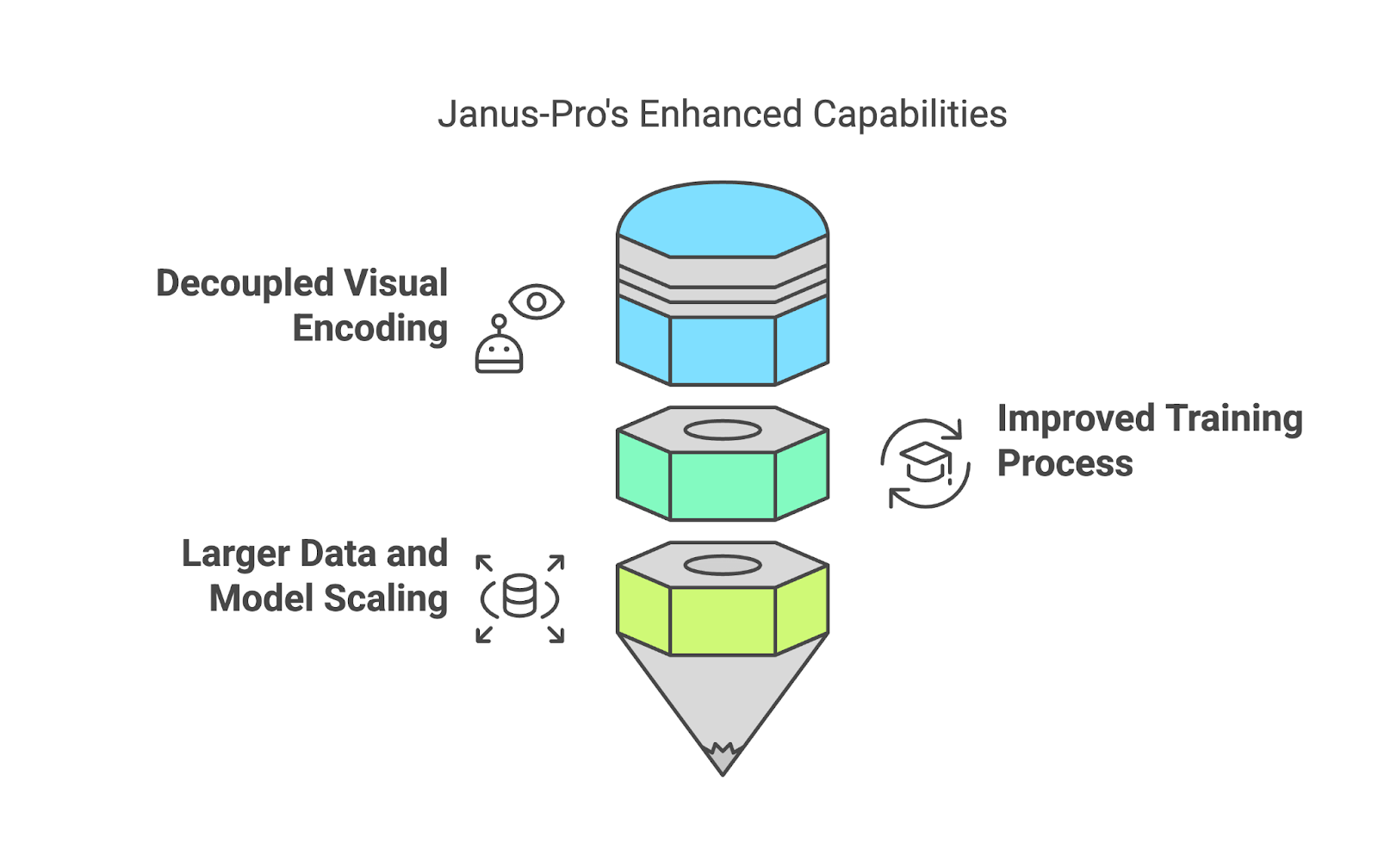
Eines der herausragenden Merkmale von Janus-Pro ist, dass es kein einziges System verwendet, um sowohl die Interpretation als auch die Erstellung von Bildern zu verwalten. Stattdessen werden diese Prozesse voneinander getrennt (entkoppelte visuelle Kodierung).
Wenn du zum Beispiel ein Bild hochlädst und eine Frage dazu stellst, verwendet Janus-Pro ein spezielles System, um das Bild zu "lesen" und herauszufinden, was wichtig ist. Wenn du ihn dagegen bittest, ein Bild aus einer Textbeschreibung zu erstellen, schaltet er auf ein anderes System um, das sich auf die Erstellung von Bildern konzentriert. Durch diese Trennung kann das Modell beide Aufgaben besser erfüllen - und vermeidet die Kompromisse, die entstehen, wenn ein System gezwungen ist, alles zu erledigen.
Die Ausbildung von Janus-Pro ist in drei Stufen unterteilt, die jeweils dazu dienen, ihre Fähigkeiten zu verfeinern:
Janus-Pro skaliert seine Fähigkeiten, indem es sowohl reale als auch synthetische Daten zu gleichen Teilen verwendet. Diese Mischung sorgt nicht nur für qualitativ hochwertigere Ergebnisse, sondern verbessert auch die Stabilität bei Aufgaben wie der Bilderstellung.
In diesem Abschnitt vergleiche ich Janus-Pro-7B und DALL-E 3 in Bezug auf multimodales Verstehen und Text-zu-Bild-Erzeugung. Dieser Vergleich soll dir ein praktisches Gefühl für diese Modelle in Aktion vermitteln, ersetzt aber nicht die Tiefe der systematischen Benchmark-Messungen.
Ich habe das Bild unten hochgeladen und sowohl Janus-Pro-7B als auch DALL-E 3 gefragt:
"In einem Satz: Was ist die Hauptaussage dieses Bildes?"
Quelle: Janus-Pro's GitHub Seite.
Hier sind die Antworten:
Janus-Pro: Die wichtigste Erkenntnis aus diesem Bild ist, dass das Janus-Modell die höchste durchschnittliche Leistung bei multimodalen Verstehensaufgaben erzielt und gleichzeitig eine hohe Genauigkeit bei den Benchmarks zur Text-Bild-Erzeugung zeigt, bei denen Anweisungen befolgt werden.
DALL-E 3: Die Janus-Pro-Modelle, insbesondere Janus-Pro-7B, übertreffen andere multimodale Modelle sowohl beim Verstehen als auch beim Befolgen von Anweisungen und zeigen starke Fähigkeiten bei Text- und Bildaufgaben.
Obwohl beide Modelle die Grafik gut zusammenfassen, bezieht sich Janus-Pro fälschlicherweise auf "das Janus-Modell" und unterscheidet es nicht von Janus-Pro. In DALL-E 3 werden jedoch ausdrücklich "Janus-Pro-Modelle, insbesondere Janus-Pro-7B" genannt, was ein besseres Verständnis des Kontextes zeigt.
Dies ist nur ein einzelnes Beispiel, daher können wir keine allgemeinen Schlussfolgerungen ziehen.
Ich habe diese Aufforderung ausprobiert, weil sie in der Praxis nützlich sein könnte:
"Ein modernes Bürodesign mit kollaborativen Arbeitsplätzen, privaten Besprechungsräumen und natürlichem Licht, präsentiert als 3D-Rendering".
DALL-E 3 hat das folgende Bild erstellt, das alle Elemente der Aufforderung abdeckt: moderne Büroräume, Arbeitsplätze für die Zusammenarbeit, private Besprechungsräume, natürliches Licht und eine 3D-Darstellung. Wenn du jedoch genau hinsiehst, wirst du einige Artefakte bemerken, wie zum Beispiel:

Ich habe Janus-Pro-7B auf Hugging Face. Das Modell hat fünf Bilder erzeugt, die alle ziemlich schlecht aussehen:
Wenn wir uns das erste Bild ansehen, können wir ohne viel Aufwand ein paar größere Artefakte erkennen:
Du kannst dieses Ergebnis auf Hugging Face reproduzieren, indem du die gleiche Eingabeaufforderung und die folgenden Parameter und Seeds verwendest:
Obwohl ich mit verschiedenen Parametern und Samen experimentiert habe, konnte ich mit dem Janus-Pro-7B keine besseren Ergebnisse erzielen. Auch hier handelt es sich nur um ein Beispiel, das nicht genug Beweise liefert, um allgemeine Schlussfolgerungen über eines der Modelle zu ziehen.
Janus-Pro wurde in mehreren Benchmarks getestet, um seine Leistung sowohl beim multimodalen Verstehen als auch bei der Text-zu-Bild-Erzeugung zu messen. Die Ergebnisse zeigen Verbesserungen gegenüber dem Vorgängermodell Janus und machen es zu einem der leistungsstärksten Modelle in seiner Kategorie.
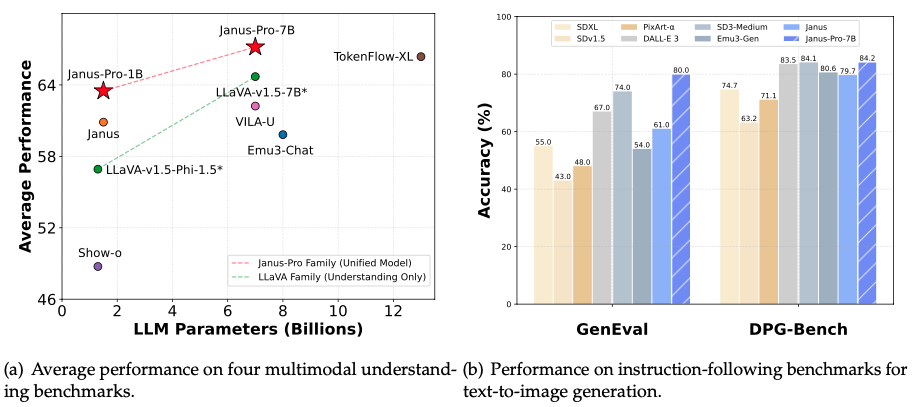
Quelle: Janus-Pro's GitHub Seite.
Das linke Diagramm in der Abbildung oben zeigt, wie Janus-Pro bei vier multimodalen Verständnis-Benchmarks abschneidet - das DeepSeek-Team hat die Genauigkeit von POPE, MME-Perception, GQA und MMMU gemittelt. Die wichtigste Erkenntnis ist, dass Janus-Pro-7B sein kleineres Gegenstück, Janus-Pro-1B, sowie andere multimodale Modelle wie LLaVA-v1.5-7B und VILA-U übertrifft.
Das rechte Diagramm vergleicht den Janus-Pro-7B mit anderen führenden Modellen in anweisungsgetreuen Benchmarks für die Text-zu-Bild-Generierung, insbesondere GenEval und DPG-Bench:
Du kannst Janus-Pro ohne komplizierte Einrichtung mit ein paar verschiedenen Methoden ausprobieren.
Der schnellste Weg, Janus-Pro zu testen, ist über die Hugging Face Spaces Demowo du direkt in deinem Browser Eingabeaufforderungen eingeben und Texte oder Bilder erzeugen kannst. Dies erfordert keine Installation oder Einrichtung.
Wenn du eine lokale Einrichtung mit einer benutzerfreundlichen Oberfläche bevorzugst, bietet DeepSeek eine Gradio-basierte Demo an. So kannst du mit Janus-Pro über eine webbasierte Benutzeroberfläche auf deinem Rechner interagieren. Um es zu verwenden, folgen Sie den Anweisungen im offiziellen Janus offiziellen GitHub-Repository.
Janus-Pro ist der neueste Schritt von DeepSeek im Bereich der multimodalen KI und bietet eine Open-Source-Alternative zu Modellen wie DALL-E 3. Er verbessert seinen Vorgänger durch besseres Training, größere Datensätze und eine entkoppelte Architektur, um Text und Bilder effektiver zu verarbeiten.
In meinem direkten Vergleich mit DALL-E 3 zeigte Janus-Pro einige Schwächen bei der Text-Bild-Erzeugung und produzierte auffällige Artefakte und Unstimmigkeiten. Bei multimodalen Verstehensaufgaben schnitt er jedoch gut ab. Allerdings ist dies nur ein begrenzter Test und bietet nicht genügend Anhaltspunkte, um allgemeine Rückschlüsse auf die Fähigkeiten des Modells zu ziehen.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
