Cursus
Principes fondamentaux de l'IA
10 h
La publication de DeepSeek-R1 a ébranlé le secteur de l'IA, provoquant une chute importante des actions de NVIDIA et des principales entreprises américaines spécialisées dans l'IA.
DeepSeek vient de présenter Janus-Pro, son dernier modèle multimodal conçu pour la génération de textes et d'images. Comme R1, Janus-Pro est Open-Source et fournit de bons résultats de benchmarking. En termes simples, il s'agit d'un concurrent sérieux de DALL-E 3 d'OpenAI et de Stable Diffusion de Stable AI dans le monde de l'IA multimodale.
Dans cet article, je vais vous expliquer ce qu'est Janus-Pro, ce que signifie l'IA multimodale, comment elle fonctionne et comment y accéder. Je le comparerai également à DALL-E 3 à travers quelques invites.
Janus-Pro est le dernier modèle d'IA multimodale de DeepSeek, conçu pour traiter des tâches impliquant à la fois du texte et des images. Il présente plusieurs améliorations par rapport au modèle Janus original, notamment de meilleures stratégies d'apprentissage, des ensembles de données plus importants et des modèles de taille variable (disponibles dans les versions 1B et 7B).

Janus comparé à Janus Pro-7b. Source : Notes de version de Janus-Pro.
Contrairement aux modèles d'IA qui se spécialisent dans un seul type d'entrée, les modèles d'IA multimodaux comme Janus-Pro sont conçus pour comprendre et relier ces deux modalités. Par exemple, vous pouvez télécharger une image et poser une question textuelle à son sujet, comme l'identification d'objets dans la scène, l'interprétation d'un texte dans l'image ou même l'analyse de son contexte.
Reconnaissance de texte avec Janus-Pro. Source : Notes de version de Janus-Pro.
Janus-Pro peut générer des images de haute qualité à partir de textes, comme la création de dessins détaillés, de concepts de produits ou de visualisations réalistes basées sur des instructions spécifiques. Il peut également analyser des données visuelles, par exemple identifier des objets sur une photo, lire et interpréter un texte dans une image ou répondre à des questions sur un tableau ou un diagramme.

Génération d’image à partir de texte avec Janus-Pro. Source : Notes de version de Janus-Pro.
Janus-Pro est disponible en deux tailles : paramètres 1B et 7B, offrant la flexibilité adaptée en fonction de votre matériel.
Janus-Pro est conçu pour comprendre et générer du texte et des images, et il y parvient en apportant quelques améliorations intelligentes par rapport à son prédécesseur. Permettez-moi d'en expliquer les principaux éléments d'une manière plus digeste.
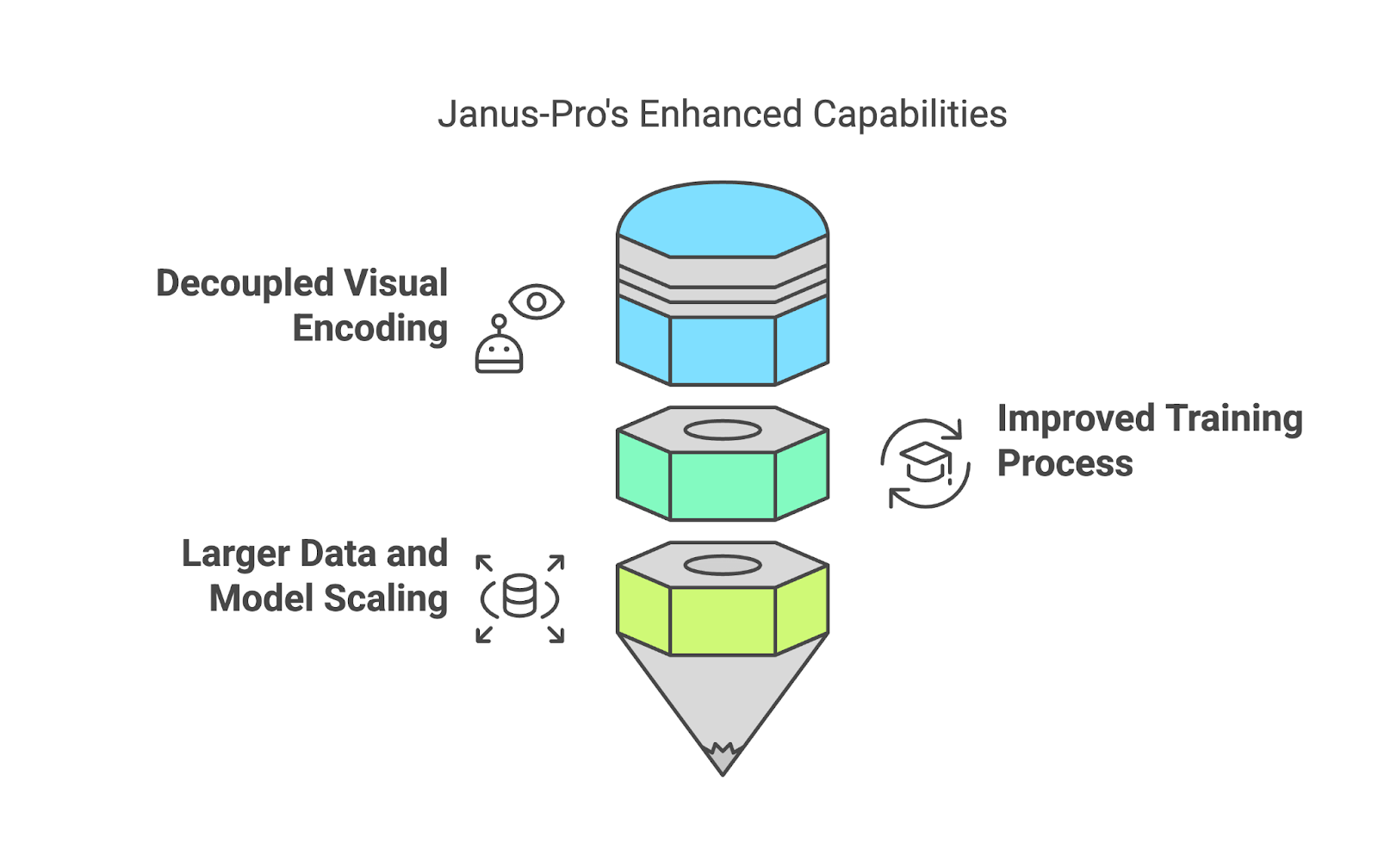
L'une des particularités de Janus-Pro est qu'il n'utilise pas qu’un seul système pour gérer à la fois l'interprétation et la création de visuels. Au lieu de cela, il sépare ces processus (encodage visuel découplé).
Par exemple, lorsque vous téléchargez une image et que vous posez une question à son sujet, Janus-Pro utilise un système spécialisé pour « lire » l'image et déterminer ce qui est important. En revanche, lorsque vous lui demandez de créer une image à partir d'une description textuelle, il passe à un système différent, axé sur la création de visuels. Cette séparation permet au modèle de mieux accomplir les deux tâches, évitant ainsi les compromis qui se produisent lorsqu'un seul système est contraint de tout gérer.
L’entraînement de Janus-Pro est divisé en trois étapes, chacune destinée à affiner ses capacités :
Janus-Pro augmente ses capacités en utilisant à la fois des données réelles et des données synthétiques à parts égales. Ce mélange permet non seulement d'obtenir des résultats de meilleure qualité, mais aussi d'améliorer la stabilité lors de tâches telles que la génération d'images.
Dans cette section, je comparerai Janus-Pro-7B et DALL-E 3 en matière de compréhension multimodale et de génération de texte à partir d’images. Cette comparaison a pour but de vous donner une idée pratique de ces modèles en action, mais elle ne remplace pas la profondeur des mesures de référence systématiques.
J'ai téléchargé l'image ci-dessous et posé la question à Janus-Pro-7B et à DALL-E 3 :
« En une phrase, quel est le principal enseignement à tirer de cette image ?
Source : Page GitHub de Janus-Pro.
Voici les réponses :
Janus-Pro: La principale conclusion à tirer de cette image est que le modèle Janus atteint la performance moyenne la plus élevée dans les tâches de compréhension multimodale, tout en faisant preuve d'une grande précision dans les repères de suivi d'instructions pour la génération de texte à partir d'images.
DALL-E 3 : Les modèles Janus-Pro, en particulier Janus-Pro-7B, surpassent les autres modèles multimodaux à la fois en termes de compréhension et de suivi des instructions, démontrant de fortes capacités dans les tâches liées au texte et à l'image.
Bien que les deux modèles résument bien le graphique, Janus-Pro se réfère à tort au « modèle Janus », sans le distinguer de Janus-Pro. DALL-E 3, cependant, identifie spécifiquement les « modèles Janus-Pro, en particulier Janus-Pro-7B », ce qui témoigne d'une meilleure compréhension du contexte.
Il s'agit d'un exemple isolé, nous ne pouvons donc pas en tirer de conclusions générales.
J'ai essayé ce message parce qu'il pourrait être utile dans la pratique :
« Un espace de bureau moderne avec des postes de travail collaboratifs, des salles de réunion privées et de la lumière naturelle, présenté sous la forme d'un rendu en 3D ».
DALL-E 3 a généré l'image ci-dessous, qui vérifie tous les éléments de l'invite : espace de bureau moderne, postes de travail collaboratifs, salles de réunion privées, lumière naturelle et rendu en 3D. Cependant, en y regardant de plus près, vous remarquerez un certain nombre d'artefacts :

J'ai interrogé Janus-Pro-7B sur Hugging Face. Le modèle a généré cinq images, qui sont toutes assez mauvaises :
En regardant la première image, nous pouvons repérer quelques artefacts majeurs sans trop d'effort :
Vous pourrez reproduire ce résultat sur Hugging Face en utilisant la même invite et les paramètres et semences suivants :
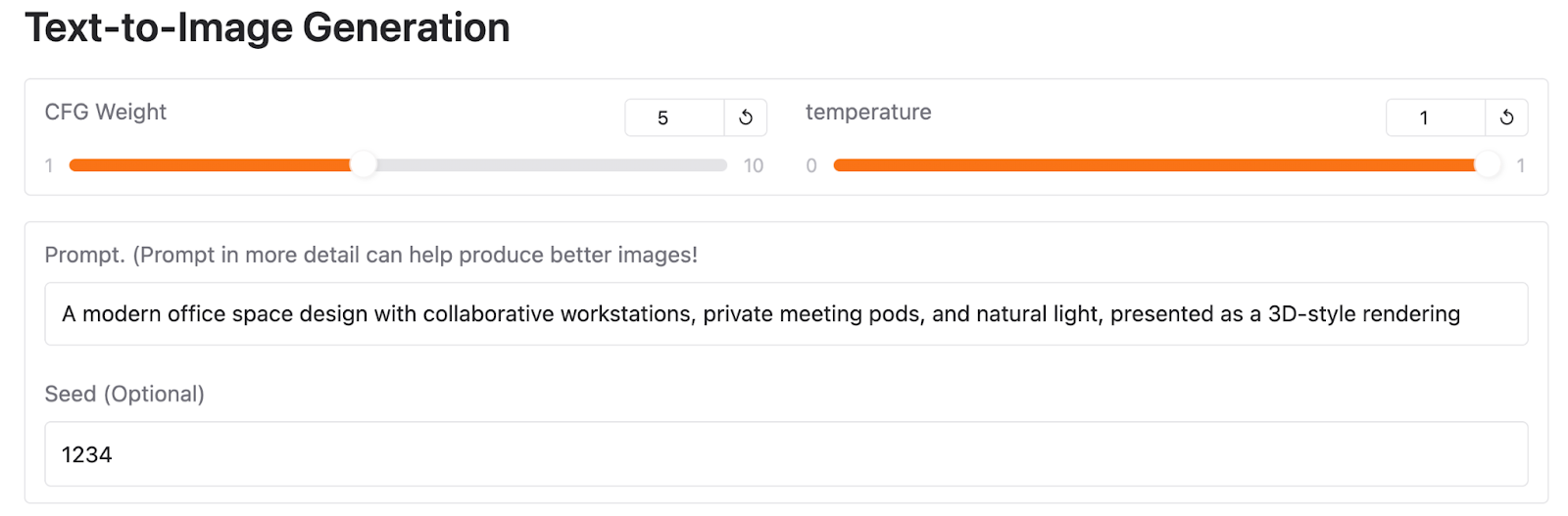
Malgré l'expérimentation de différents paramètres et semences, je n'ai pas pu obtenir de meilleurs résultats avec Janus-Pro-7B. Encore une fois, il ne s'agit que d'un exemple et il n'y a pas assez de preuves pour tirer des conclusions générales sur l'un ou l'autre modèle.
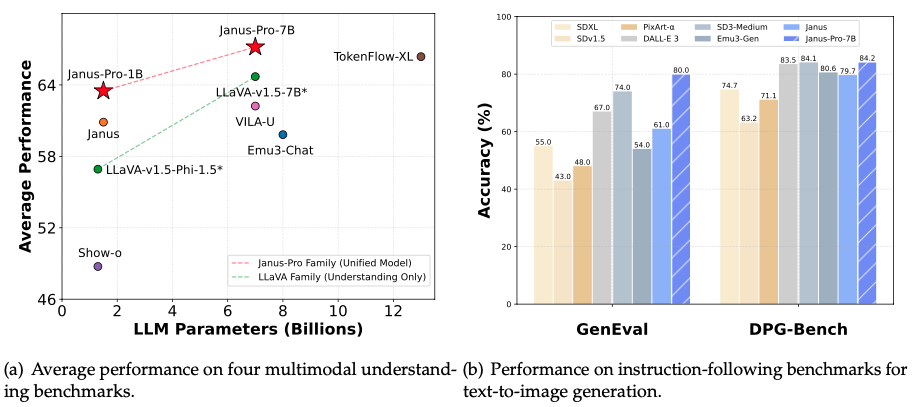
Janus-Pro a été testé sur de nombreux critères afin de mesurer ses performances en matière de compréhension multimodale et de génération de texte à partir d'images. Les résultats montrent des améliorations par rapport à son prédécesseur, Janus, et le placent parmi les modèles les plus performants de sa catégorie.
Source : Page GitHub de Janus-Pro.
Le graphique de gauche dans l'image ci-dessus montre les performances de Janus-Pro sur quatre éléments de référence de compréhension multimodale. L'équipe DeepSeek a calculé la moyenne de la précision de POPE, MME-Perception, GQA, et MMMU. La principale conclusion est que Janus-Pro-7B surpasse son homologue plus petit, Janus-Pro-1B, ainsi que d'autres modèles multimodaux tels que LLaVA-v1.5-7B et VILA-U.
Le graphique de droite compare Janus-Pro-7B à d'autres modèles de premier plan dans le domaine de la génération de texte à partir d'images en suivant les instructions, à savoir GenEval et DPG-Bench :
Vous pouvez essayer Janus-Pro sans installation complexe en utilisant quelques méthodes différentes.
Le moyen le plus rapide de tester Janus-Pro est d'utiliser ses espaces de démonstration Hugging Faceoù vous pouvez saisir des invites et générer du texte ou des images directement dans votre navigateur. Cela ne nécessite aucune installation ou configuration.
Si vous préférez une installation locale avec une interface conviviale, DeepSeek fournit une démo basée sur Gradio. Cela vous permet d'interagir avec Janus-Pro par le biais d'une interface graphique basée sur le web sur votre machine. Pour l'utiliser, suivez les instructions sur le dépôt officiel GitHub de Janus.
Janus-Pro est la dernière initiative de DeepSeek dans le domaine de l'IA multimodale, offrant une alternative Open-Source à des modèles comme DALL-E 3. Il surpasse son prédécesseur grâce à une meilleure formation, à des ensembles de données plus importants et à une architecture découplée permettant de traiter plus efficacement le texte et les images.
Dans ma comparaison avec DALL-E 3, Janus-Pro a montré quelques faiblesses dans la génération de texte à partir d’images, produisant des artefacts et des incohérences notables. Cependant, il a obtenu de bons résultats dans les tâches de compréhension multimodale. Cela dit, il ne s'agit que d'un test limité qui ne permet pas de tirer des conclusions générales sur les capacités globales du modèle.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours