Programa
Fundamentos da IA
10 h
O lançamento do DeepSeek-R1 abalou o setor de IA, causando quedas significativas nas ações da NVIDIA e das principais empresas americanas de IA.
A DeepSeek apresentou agora o Janus-Pro, seu mais recente modelo multimodal projetado para geração de texto e imagem. Assim como o R1, o Janus Pro é de código aberto e oferece bons resultados de benchmark. Resumidamente, ele é um concorrente de peso do DALL-E 3 da OpenAI e do Stable Diffusion da Stability AI no segmento de IA multimodal.
Neste blog, explicarei o Janus Pro, o que ele é, o que significa IA multimodal, como ele funciona e como você pode acessá-lo. Também vou compará-lo com o DALL-E 3 em alguns prompts.
O Janus-Pro é o mais novo modelo de IA multimodal da DeepSeek, projetado para lidar com tarefas que envolvem texto e imagens. Ele apresenta vários aprimoramentos em relação ao modelo Janus original, incluindo melhores estratégias de treinamento, conjuntos de dados maiores e tamanhos de modelos escalonados (disponíveis nas versões de parâmetros 1B e 7B).

Janus vs. Janus Pro-7b. Fonte: Artigo de lançamento do Janus-Pro.
Ao contrário dos modelos de IA especializados em apenas um tipo de entrada, os modelos de IA multimodal, como o Janus-Pro, são criados para entender e conectar essas duas modalidades. Por exemplo, você pode carregar uma imagem e escrever uma pergunta sobre ela como, por exemplo, identificar objetos na cena, interpretar o texto dentro da imagem ou até mesmo analisar seu contexto.
Reconhecimento de texto com o Janus-Pro. Fonte: Artigo de lançamento do Janus-Pro.
O Janus-Pro pode gerar imagens de alta qualidade a partir de instruções de texto, como a criação de trabalhos artísticos detalhados, projetos de produtos ou visualizações realistas com base em instruções específicas. Ele também pode analisar entradas visuais, como identificar objetos em uma foto, ler e interpretar textos em uma imagem ou responder a perguntas sobre um gráfico ou diagrama.

Geração de imagens a partir de texto com o Janus-Pro. Fonte: Artigo de lançamento do Janus-Pro.
O Janus-Pro é fornecido em dois tamanhos, parâmetros 1B e 7B, oferecendo flexibilidade, dependendo do seu hardware.
O Janus-Pro foi projetado para lidar tanto com a compreensão quanto com a geração de texto e imagens, e consegue isso com alguns aprimoramentos inteligentes em relação ao seu antecessor. Vou explicar seus principais componentes de uma forma que seja mais fácil de digerir.
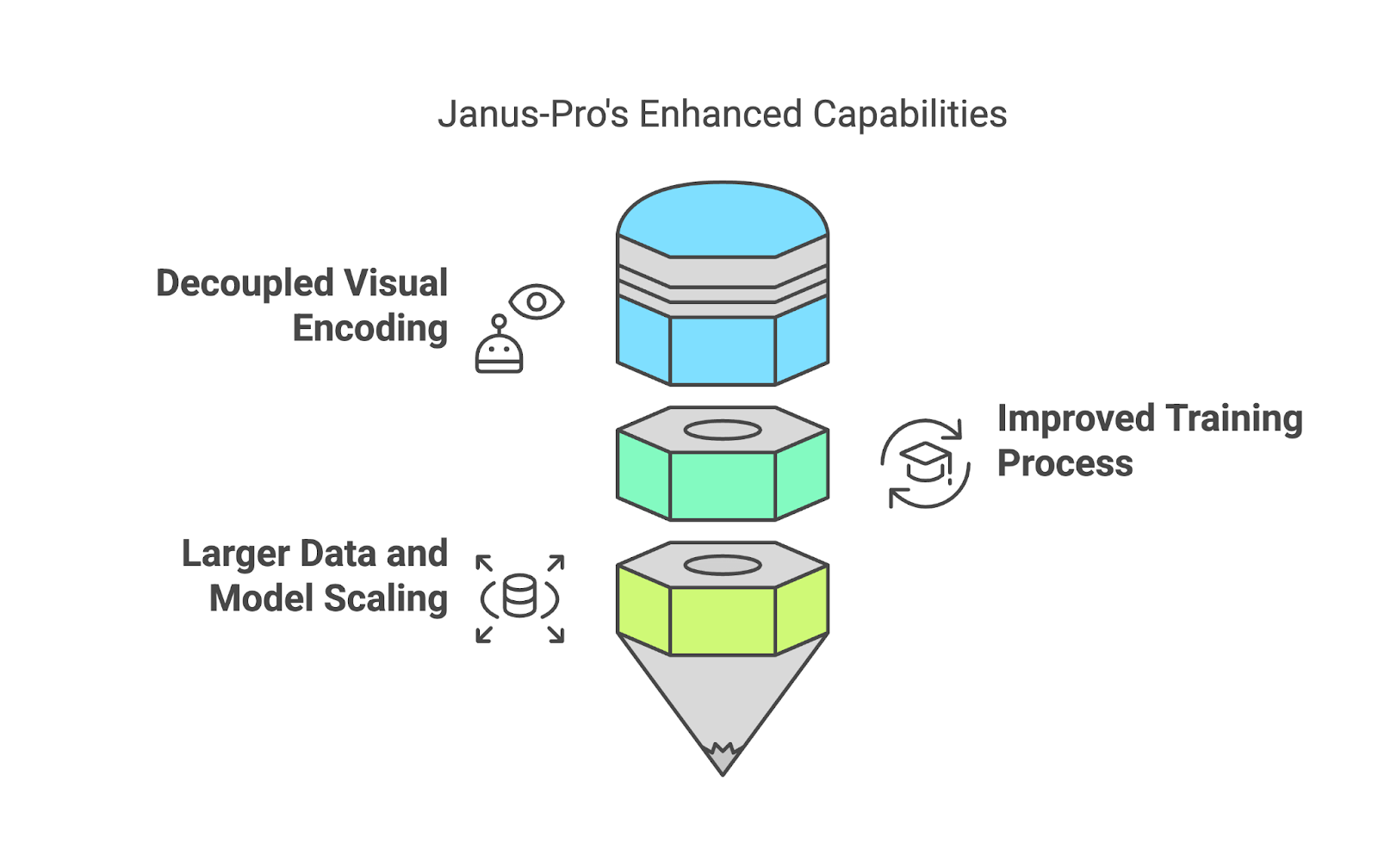
Um dos recursos de destaque do Janus-Pro é que ele não usa um único sistema para lidar com a interpretação e a criação de imagens. Em vez disso, ele separa esses processos (programação visual desacoplada).
Por exemplo, quando você carrega uma imagem e faz uma pergunta sobre ela, o Janus-Pro usa um sistema especializado para "ler" a imagem e descobrir o que é importante. Por outro lado, quando você pede que ele crie uma imagem a partir de uma descrição em texto, ele muda para um sistema diferente que se concentra na geração de imagens. Essa separação permite que o modelo realize melhor as duas tarefas, evitando as concessões que ocorrem quando um sistema é forçado a lidar com tudo.
O treinamento da Janus-Pro é dividido em três etapas, cada uma delas projetada para aperfeiçoar seus recursos:
O Janus-Pro amplia seus recursos usando tanto dados do mundo real quanto dados sintéticos em partes iguais. Essa combinação não apenas garante resultados de maior qualidade, mas também melhora a estabilidade durante tarefas como a geração de imagens.
Nesta seção, compararei o Janus-Pro-7B e o DALL-E 3 na compreensão multimodal e na geração de imagens a partir de texto. Essa comparação tem o objetivo de dar a você uma noção prática desses modelos em ação, mas não substitui a profundidade das medições sistemáticas de benchmark.
Carreguei a imagem abaixo e perguntei ao Janus-Pro-7B e ao DALL-E 3:
"Em uma frase, qual é a principal conclusão dessa imagem?"
Fonte: Página do GitHub do Janus-Pro.
Aqui estão as respostas:
Janus-Pro: A principal conclusão dessa imagem é que o modelo Janus atinge o desempenho médio mais alto em tarefas de compreensão multimodal, além de demonstrar alta precisão em benchmarks de cumprimento de instruções para geração de imagens a partir de texto.
DALL-E 3: Os modelos Janus-Pro, especialmente o Janus-Pro-7B, superam outros modelos multimodais em benchmarks de compreensão e de cumprimento de instruções, demonstrando recursos sólidos em tarefas de texto e imagem.
Embora ambos os modelos resumam bem o gráfico, o Janus-Pro se refere incorretamente ao "modelo Janus", deixando de diferenciá-lo do Janus-Pro. O DALL-E 3, no entanto, identifica especificamente "modelos Janus-Pro, particularmente Janus-Pro-7B", demonstrando melhor compreensão contextual.
Esse é apenas um exemplo isolado, portanto, não podemos tirar conclusões gerais.
Tentei esse prompt porque pode ser algo que tenha um uso real na prática:
"Um projeto de um escritório moderno com estações de trabalho colaborativas, salas de reunião privadas e luz natural, apresentado como uma renderização em estilo 3D"
O DALL-E 3 gerou esta imagem abaixo, que atende a todos os elementos do prompt: escritório moderno, estações de trabalho colaborativas, salas de reunião privadas, luz natural e renderização em estilo 3D. No entanto, se você observar com atenção, perceberá alguns artefatos, como:

Fiz um prompt para o Janus-Pro-7B no Hugging Face. O modelo gerou cinco imagens, e todas elas ficaram muito ruins:
Observando a primeira imagem, podemos identificar alguns artefatos importantes sem muito esforço:
Você poderá reproduzir esse resultado no Hugging Face usando o mesmo prompt e os parâmetros e sementes a seguir:
Apesar de fazer experiências com diferentes parâmetros e sementes, não consegui produzir resultados melhores com o Janus-Pro-7B. Novamente, esse é apenas um exemplo e não fornece evidências suficientes para tirar conclusões amplas sobre qualquer um dos modelos.
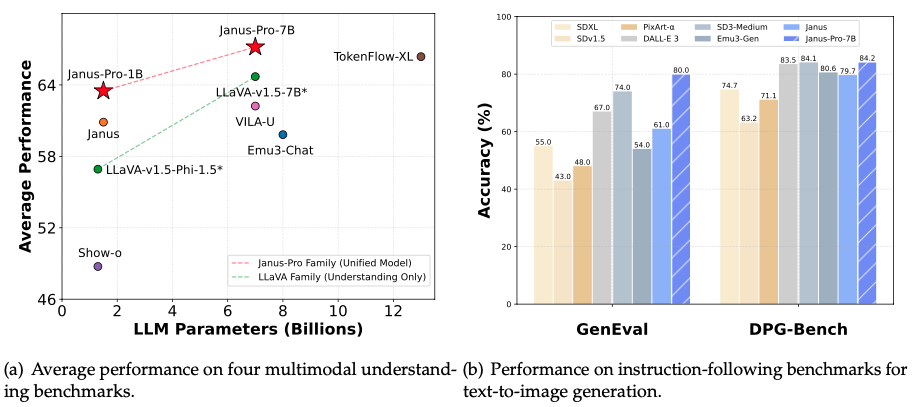
O Janus-Pro foi testado em vários benchmarks para medir seu desempenho tanto na compreensão multimodal quanto na geração de imagens a partir de texto. Os resultados mostram melhorias em relação ao seu antecessor, o Janus, e o colocam entre os modelos de melhor desempenho em sua categoria.
Fonte: Página do GitHub do Janus-Pro.
O gráfico à esquerda na imagem acima mostra o desempenho do Janus-Pro em quatro benchmarks de compreensão multimodal. A equipe do DeepSeek ficou na média de precisão do POPE, MME-Perception, GQA e MMMU. A principal conclusão é que o Janus-Pro-7B supera sua contraparte menor, o Janus-Pro-1B, bem como outros modelos multimodais, como o LLaVA-v1.5-7B e o VILA-U.
O gráfico à direita compara o Janus-Pro-7B com outros modelos líderes em benchmarks de cumprimento de instruções para geração de imagens a partir de texto, especificamente GenEval e DPG-Bench:
Você pode experimentar o Janus-Pro sem configurações complexas usando alguns métodos diferentes.
A maneira mais rápida de testar o Janus-Pro é por meio da sua demonstração do Hugging Face Spacesem que você pode escrever prompts e gerar texto ou imagens diretamente no navegador. Não requer instalação ou configuração.
Se você preferir uma configuração local com uma interface fácil de usar, o DeepSeek fornece uma demonstração baseada no Gradio. Isso permite que você interaja com o Janus-Pro por meio de uma GUI baseada na Web em seu computador. Para usá-lo, siga as instruções no repositório oficial do Janus no GitHub.
O Janus-Pro é a mais recente iniciativa da DeepSeek no espaço da IA multimodal, oferecendo uma alternativa de código aberto a modelos como o DALL-E 3. Ele é melhor que seu antecessor com melhor treinamento, conjuntos de dados maiores e uma arquitetura desacoplada para lidar com textos e imagens de forma mais eficaz.
Na minha comparação direta com o DALL-E 3, o Janus-Pro mostrou alguns pontos fracos na geração de imagens a partir de texto, produzindo artefatos e inconsistências perceptíveis. No entanto, ele teve um bom desempenho em tarefas de compreensão multimodal. Dito isso, este é apenas um teste limitado e não fornece evidências suficientes para tirar conclusões gerais sobre os recursos gerais do modelo.
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
blog
Richie Cotton
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita




