
Course
Introduction to Data Science in Python
4 hr
498.3K
Recently, I had the privilege of getting early access to the Polars GPU engine, powered by NVIDIA RAPIDS cuDF, before its open beta release. This cutting-edge feature has the potential to transform data workflows by accelerating Polars operations up to 13x with NVIDIA GPUs. If you work with large-scale datasets in Python, this is a game-changer you won’t want to miss.
In this blog post, I’ll explain everything you need to know about the new Polars GPU engine and provide a step-by-step guide to help you get started!

At the core of most data science workflows is the DataFrame, a tabular data structure that is both flexible and intuitive for handling structured data. Simply put, everyone in data science has worked with DataFrames.
DataFrames allow easy data manipulation, exploration, and analysis, providing a familiar and consistent interface for data cleaning, filtering, grouping, and transforming data.
However, in the context of big data, traditional DataFrame libraries can lack performance and scalability, which is where Polars enters the scene.
Polars is a fast, efficient DataFrame library that has quickly become a top choice for high-performance data processing. Written from scratch in Rust, Polars is designed to operate close to the hardware, optimizing speed and resource usage without relying on external dependencies.
The Introduction to Polars blog post is an excellent resource for getting started with the library in Python.
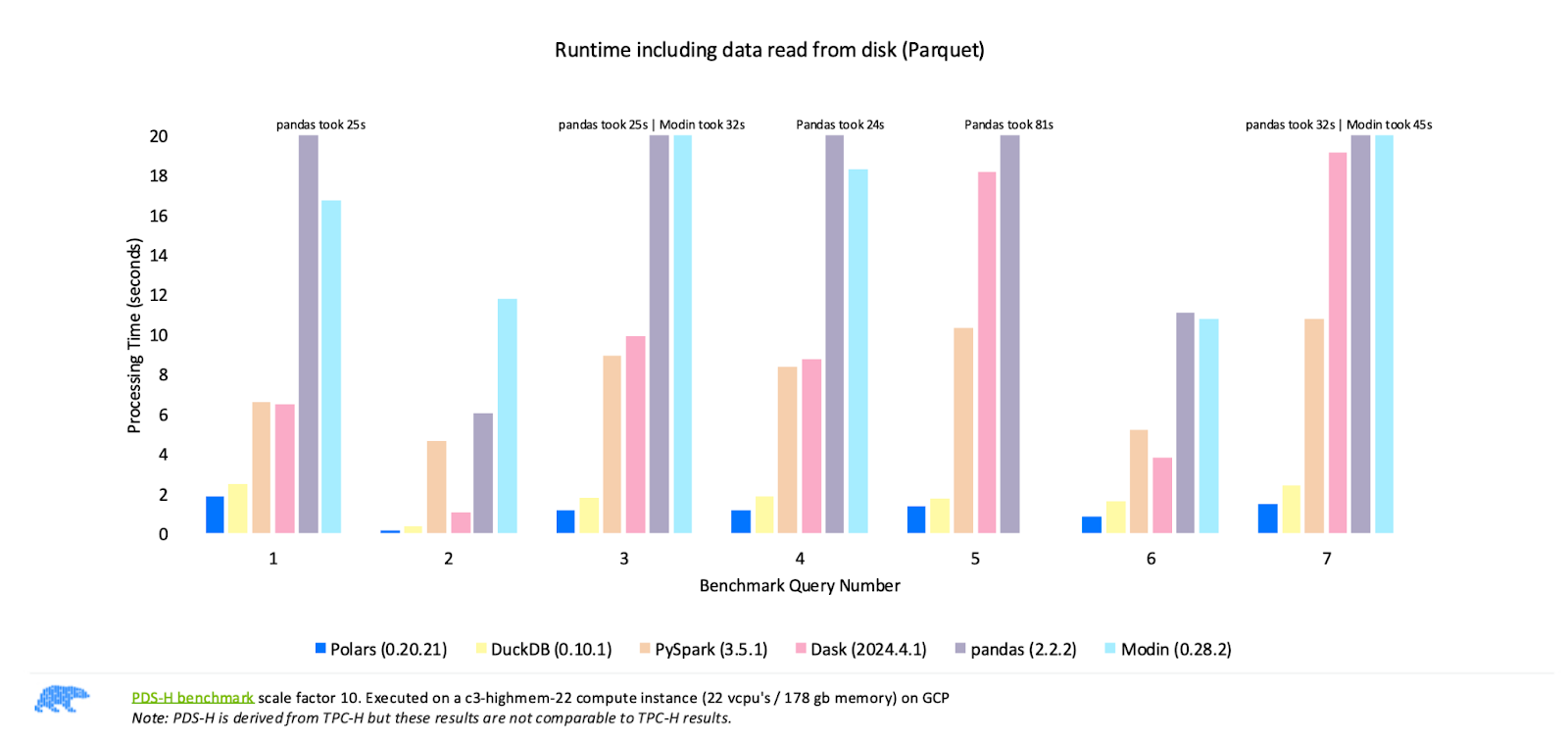
Comparing the performance of the most popular DataFrame libraries. Image source: Polars
The benchmark results published by Polars, shown in the image above, demonstrate that Polars consistently outperforms other libraries like Pandas, Modin, PySpark, and Dask across different queries. These results highlight Polars’ strength as the fastest option for high-performance data processing.
But how is that even possible? These are some of the features that make Polars blazing fast:
And with the recent open beta announcement of the Polars GPU engine, it’s about to become even faster!
The demand for faster data processing and analysis has grown exponentially in recent years as datasets have scaled to hundreds of millions or even billions of rows. To address this challenge, the data science field has seen a growing shift from traditional CPU-based processing to GPU-accelerated computing. This is where NVIDIA RAPIDS cuDF comes into play.
NVIDIA RAPIDS is an open-source suite of libraries that enables GPU-accelerated data science and analytics. At its core, RAPIDS is designed to streamline data workflows by utilizing the massive parallelism of NVIDIA GPUs to accelerate tasks that are typically CPU-bound.
Within RAPIDS, cuDF is the library responsible for DataFrame operations. cuDF extends the familiar DataFrame abstraction to GPU memory, allowing integration into data workflows without extensive code changes. The library supports all the key operations data scientists perform on DataFrames: filtering, aggregating, merging, and sorting, all powered by the GPU for speed.
NVIDIA and Polars just announced the open beta release of the Python Polars GPU engine, powered by RAPIDS cuDF. This new feature marks a significant leap forward for high-performance data processing, delivering up to 13x faster workflows for Polars users with NVIDIA GPUs!
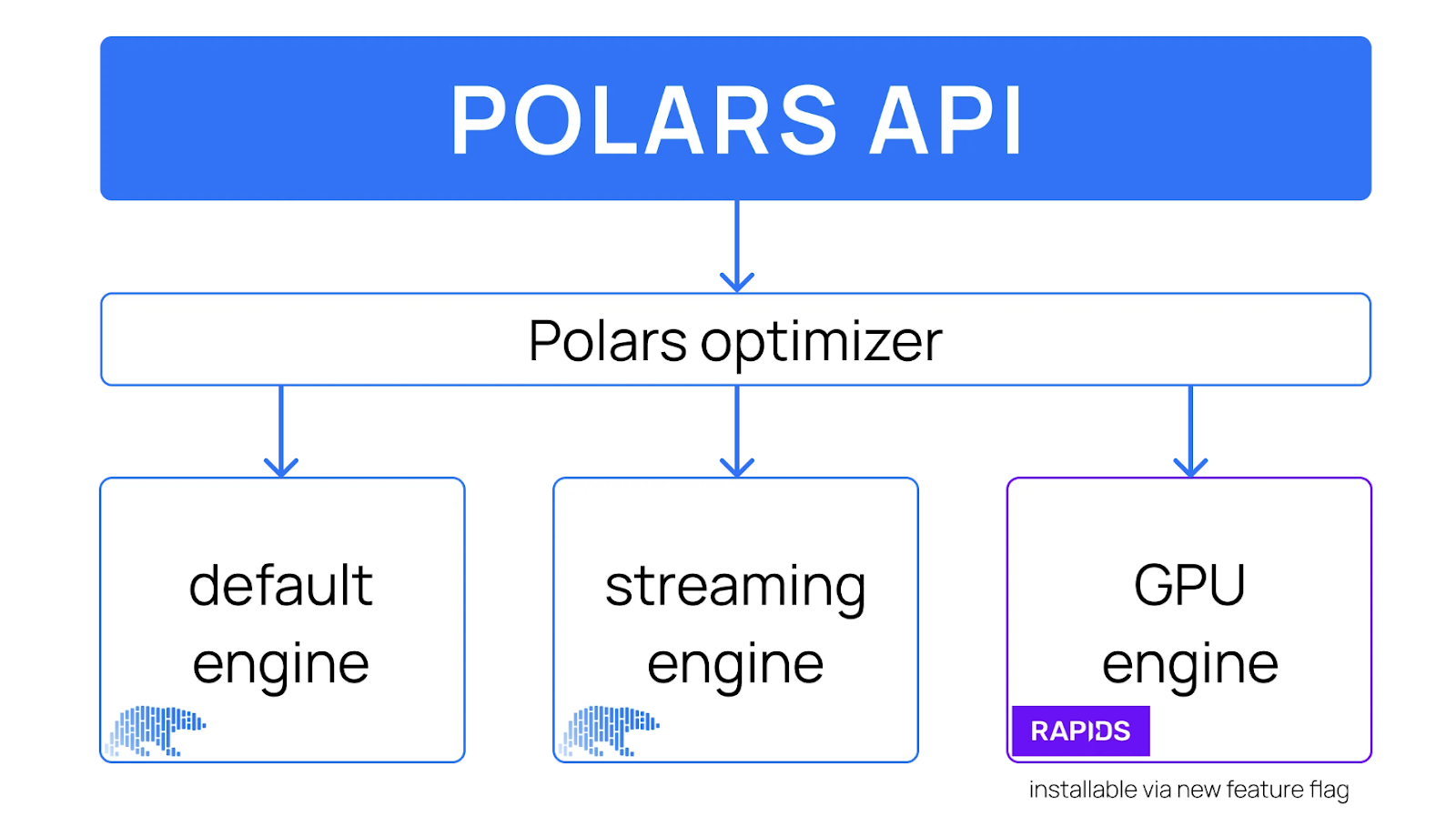
High-level design of the Polars API, including a GPU engine. Image source: Polars
With the addition of the GPU engine, Polars users can decide which engine to run their data workloads on. The Polars optimizer supports all engines, dynamically determining which queries can execute on the GPU or CPU.
So now you have some context on Polars and the NVIDIA RAPIDS cuDF library and how both integrate and are made available through the Python Polars API. But what does this mean for developers and data scientists?
Here’s a summary of what the Polars GPU engine enables:
engine="gpu" to the collect() operation in Polars’ Lazy API, enabling GPU processing without significant code changes.So, what are the results so far? Let’s see.
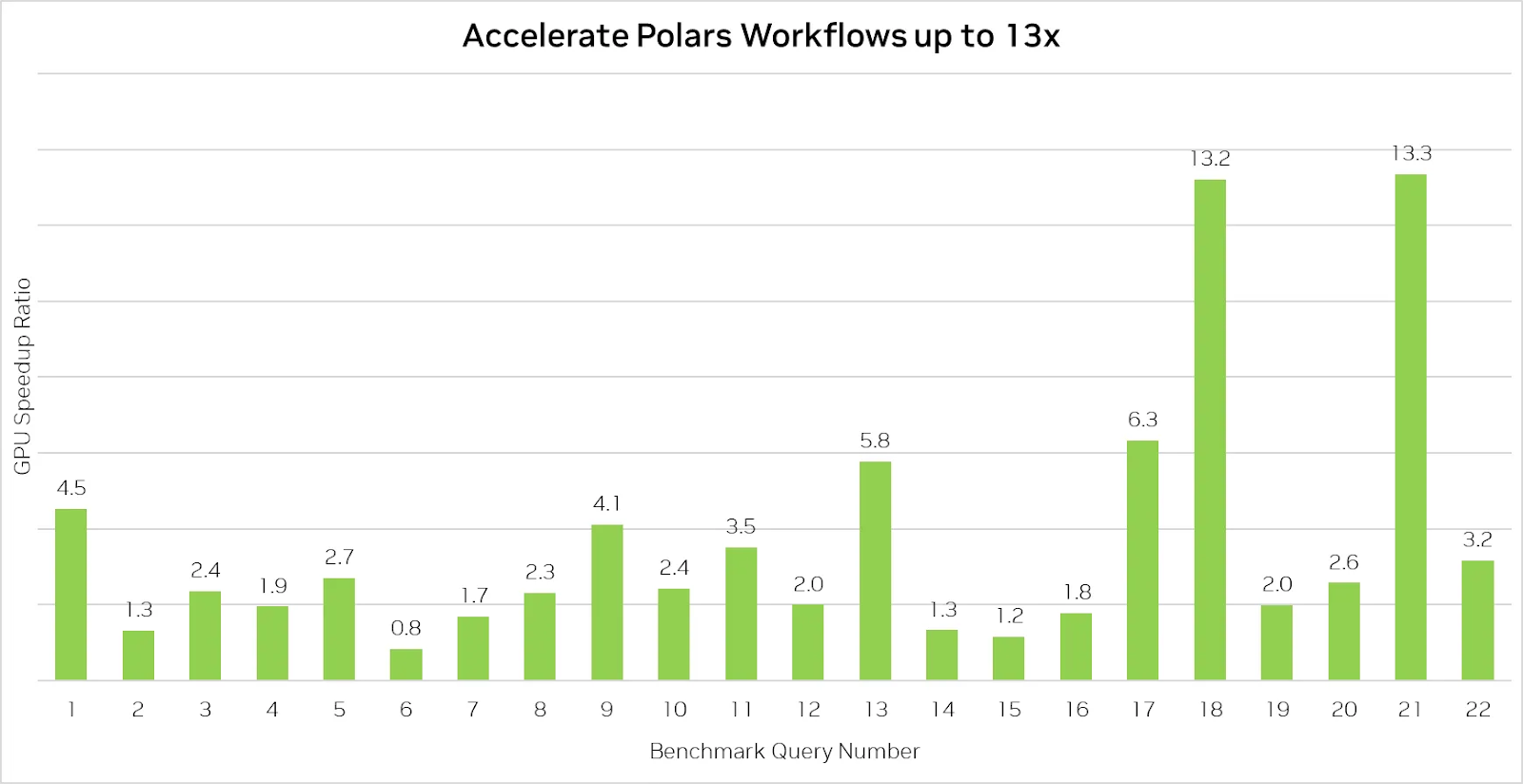
Polars GPU Engine accelerates data processing up to 13x. Image source: Polars
The benchmark above demonstrates the impressive capabilities of the Polars GPU engine by accelerating queries up to 13x.
However, it's important to note that using Polars on a GPU isn’t always guaranteed to be faster than on a CPU, particularly for simpler queries that aren’t computationally intensive. In such cases, performance is often limited by the speed of reading data from disk, meaning GPU acceleration offers less of an advantage when input/output (I/O) operations are the primary constraint.
That said, the GPU engine provides significant speedups for more complex data operations, making it a valuable tool for teams handling large datasets or queries involving joins, group-bys, and string processing.
One of the most compelling features of this new integration is its flexibility. As previously mentioned, the optimizer can switch between CPU and GPU execution based on the complexity of your queries. But how exactly does this transition work?
When running Polars on the CPU, the engine follows a structured and highly optimized pipeline to execute data operations. This process involves roughly the following steps:
When you enable GPU acceleration by passing engine="gpu" to the .collect() method, the process remains essentially the same on the surface but with additional checks and optimizations behind the scenes to determine how much of the workload can be offloaded to the GPU, via cuDF:
This hybrid execution model—where GPU and CPU are used in tandem—makes Polars highly flexible. You benefit from GPU acceleration without sacrificing compatibility for queries not supported on the GPU. The Polars release blog post explains this in deeper technical detail.
Finally, the most exciting part! In this section, I’ll walk through the steps needed to set up your environment and begin taking advantage of GPU-accelerated data processing.
The most straightforward way to get up and running is to follow along with this Google Colab notebook.
Colab offers free limited GPU usage, particularly useful if you don’t have immediate access to a GPU. If you’re using the provided notebook, we start from step 2 below, so you can skip the previous steps.
Before installing the Polars GPU engine, ensure your system meets the requirements for NVIDIA RAPIDS cuDF. You can review the necessary system specifications, including GPU compatibility and driver requirements, on the RAPIDS documentation page.
To start with the Polars GPU engine, it's best practice to create a virtual environment to isolate your project dependencies.
I use conda for this example but feel free to use your preferred package manager.
In addition to Python, you can include JupyterLab in the environment for interactive data exploration and development, which is especially useful for running small code snippets and analyzing datasets on the fly.
conda create -n polars-gpu -c conda-forge python=3.11 jupyterlabAfter creating the virtual environment, activate it using:
conda activate polars-gpuNow, let’s enable GPU acceleration by installing Polars and the GPU engine. This will also set up cuDF and other dependencies required for using NVIDIA GPUs:
pip install -U polars[gpu] --extra-index-url=https://pypi.nvidia.comOnce the Polars GPU engine is installed, using Polars on a GPU will feel similar to working with the CPU but with much faster results for complex or data-heavy workflows.
As explained before, the Polars engine automatically optimizes the execution plan, fully utilizing the NVIDIA GPU to speed up operations and minimize memory usage. For queries that do not support GPU acceleration, the Polars GPU engine has graceful CPU fallback, ensuring the workflow continues uninterrupted.
Let’s put the engine into action with a few simple examples!
For this demonstration, we'll use a 22GB dataset of simulated financial transactions from Kaggle. NVIDIA hosts the dataset on a Google Cloud Storage (GCS) bucket, ensuring fast download speeds.
To start, download the dataset:
!wget https://storage.googleapis.com/rapidsai/polars-demo/transactions.parquet -O transactions.parquetSince this dataset is sourced from Kaggle, it's governed by a Kaggle dataset-specific license and terms of use.
Let’s load the dataset using Polars and inspect the schema:
import polars as pl
from polars.testing import assert_frame_equal
transactions = pl.scan_parquet("transactions.parquet")
transactions.collect_schema()Here’s the output:
Schema([('CUST_ID', String),
('START_DATE', Date),
('END_DATE', Date),
('TRANS_ID', String),
('DATE', Date),
('YEAR', Int64),
('MONTH', Int64),
('DAY', Int64),
('EXP_TYPE', String),
('AMOUNT', Float64)])Now, let’s calculate the total transaction volume by summing the AMOUNT column. First, let’s try it without GPU acceleration:
transactions.select(pl.col("AMOUNT").sum()).collect()Output:
AMOUNT
f64
3.6183e9That’s a high total transaction volume! Let's run the same query on the GPU:
transactions.select(pl.col("AMOUNT").sum()).collect(engine="gpu")Output:
AMOUNT
f64
3.6183e9For simple operations like this, the CPU and GPU produce the same result with similar speed, as the query is not computationally intensive enough to benefit much from GPU acceleration. However, the GPU will shine when handling more complex queries.
Now, let’s move on to a more complex query. In this query, we group transactions by customer ID (CUST_ID), sum the total transaction amounts, and then sort the results by the highest spenders.
First, we’ll run it on the CPU:
%%time
res_cpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect()
)
res_cpuHere’s the output:
CPU times: user 4.63 s, sys: 3.75 s, total: 8.38 s
Wall time: 6.04 s
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6Now, let’s run the same query on the GPU:
%%time
res_gpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect(engine=”gpu”)
)
res_gpuOutput:
CPU times: user 347 ms, sys: 0 ns, total: 347 ms
Wall time: 353 ms
shape: (5, 2)
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6As we can see, using the GPU for more complex queries offers significant performance gains, reducing execution time from 6.04 seconds on the CPU to just 353 milliseconds on the GPU!
This example demonstrates the powerful performance boost the Polars GPU engine provides for large-scale data operations.
You can find more advanced examples in the accompanying Colab notebook.
The Polars GPU Engine, powered by NVIDIA RAPIDS cuDF, brings impressive speed improvements, with up to 13x faster data processing for complex operations. For large-scale datasets, Polars offers a clear advantage over traditional DataFrame libraries.
Even though not every query will benefit equally from GPU acceleration, Polars remains a powerful tool for anyone working with large datasets. The ease of integration, combined with its hybrid CPU-GPU execution model, makes Polars a strong contender for modern data workflows.
If you're interested in developing your data manipulation skills, especially with Pandas, I highly recommend checking out these courses:
These resources will give you a solid foundation which complements the powerful capabilities of tools like Polars!
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn more about data science and Python with these courses!
Course
Course
Course
blog
Moez Ali
9 min
blog
Richie Cotton
8 min
Tutorial
Javier Canales Luna
Tutorial
Dario Radečić
Tutorial
Zoumana Keita
code-along
Vino Duraisamy




