
Curso
Introdução à Ciência de Dados em Python
4 h
498.4K
Recentemente, tive o privilégio de obter acesso antecipado ao mecanismo de GPU Polars, desenvolvido pelo NVIDIA RAPIDS cuDF, antes do lançamento da versão beta aberta. lançamento da versão beta aberta. Esse recurso de ponta tem o potencial de transformar os fluxos de trabalho de dados, acelerando as operações do Polars em até 13 vezes com as GPUs NVIDIA. Se você trabalha com conjuntos de dados de grande escala em Python, este é um divisor de águas que você não vai querer perder.
Nesta publicação do blog, explicarei tudo o que você precisa saber sobre o novo mecanismo de GPU Polars e fornecerei um guia passo a passo para ajudá-lo a começar!

No centro da maioria dos fluxos de trabalho de ciência de dados está o DataFrame, uma estrutura de dados tabulares que é flexível e intuitiva para lidar com dados estruturados. Em resumo, todos os profissionais da ciência de dados já trabalharam com DataFrames.
Os DataFrames permitem a fácil manipulação, exploração e análise de dados, fornecendo uma interface familiar e consistente para limpeza, filtragem, agrupamento e transformação de dados.
No entanto, no contexto de big data, as bibliotecas DataFrame tradicionais podem não ter desempenho e escalabilidade, e é aí que o Polars entra em cena.
Polars é uma biblioteca DataFrame rápida e eficiente que se tornou rapidamente uma das principais opções para o processamento de dados de alto desempenho. Escrito do zero em Rust, o Polars foi projetado para operar próximo ao hardware, otimizando a velocidade e o uso de recursos sem depender de dependências externas.
A introdução Introdução ao Polars é um excelente recurso para você começar a usar a biblioteca em Python.
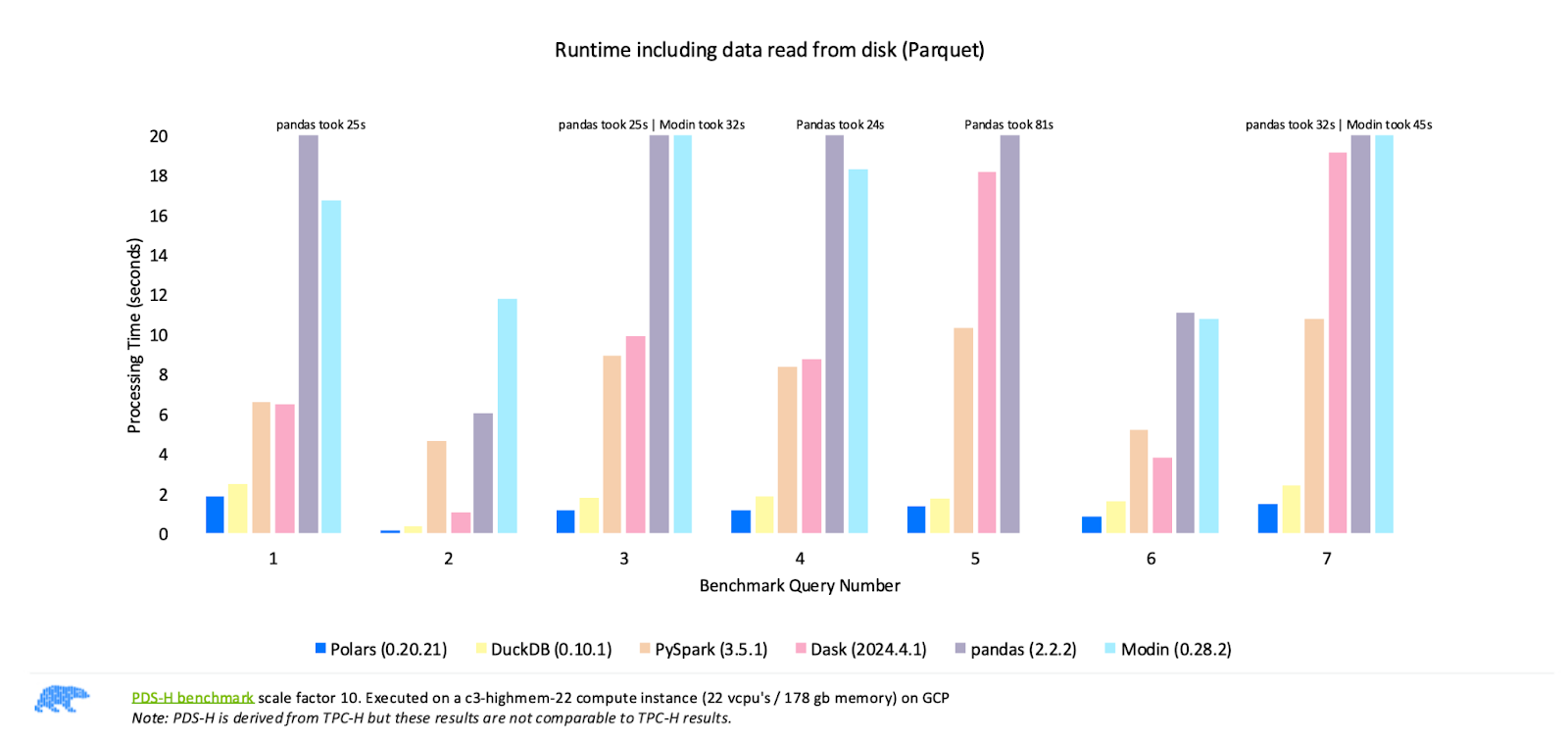
Comparando o desempenho das bibliotecas DataFrame mais populares. Fonte da imagem: Polares
Os resultados de benchmark publicados pela Polars, mostrados na imagem acima, demonstram que a Polars supera consistentemente o desempenho de outras bibliotecas, como Pandas, Modin, PySpark e Dask, em diferentes consultas. Esses resultados destacam a força do Polars como a opção mais rápida para o processamento de dados de alto desempenho.
Mas como isso é possível? Esses são alguns dos recursos que tornam o Polars extremamente rápido:
E com o recente anúncio da versão beta aberta do mecanismo de GPU Polars, ele está prestes a ficar ainda mais rápido!
A demanda por processamento e análise de dados mais rápidos cresceu exponencialmente nos últimos anos, à medida que os conjuntos de dados aumentaram para centenas de milhões ou até bilhões de linhas. Para enfrentar esse desafio, o campo da ciência de dados tem visto uma mudança crescente do processamento tradicional baseado em CPU para a computação acelerada por GPU. É nesse ponto que o NVIDIA RAPIDS cuDF entra em ação.
NVIDIA RAPIDS é um conjunto de bibliotecas de código aberto que permite a ciência e a análise de dados aceleradas por GPU. Em sua essência, o RAPIDS foi projetado para simplificar os fluxos de trabalho de dados, utilizando o paralelismo maciço das GPUs NVIDIA para acelerar tarefas que normalmente são vinculadas à CPU.
No RAPIDS, cuDF é a biblioteca responsável pelas operações do DataFrame. O cuDF estende a abstração familiar do DataFrame para a memória da GPU, permitindo a integração em fluxos de trabalho de dados sem grandes alterações no código. A biblioteca oferece suporte a todas as principais operações que os cientistas de dados realizam nos DataFrames: filtragem, agregação, mesclagem e classificação, tudo com o auxílio da GPU para aumentar a velocidade.
NVIDIA e Polars acabam de anunciar o lançamento da versão beta aberta do mecanismo de GPU Python Polars, com base no RAPIDS cuDF. Esse novo recurso representa um salto significativo para o processamento de dados de alto desempenho, proporcionando fluxos de trabalho até 13 vezes mais rápidos para os usuários do Polars com GPUs NVIDIA!
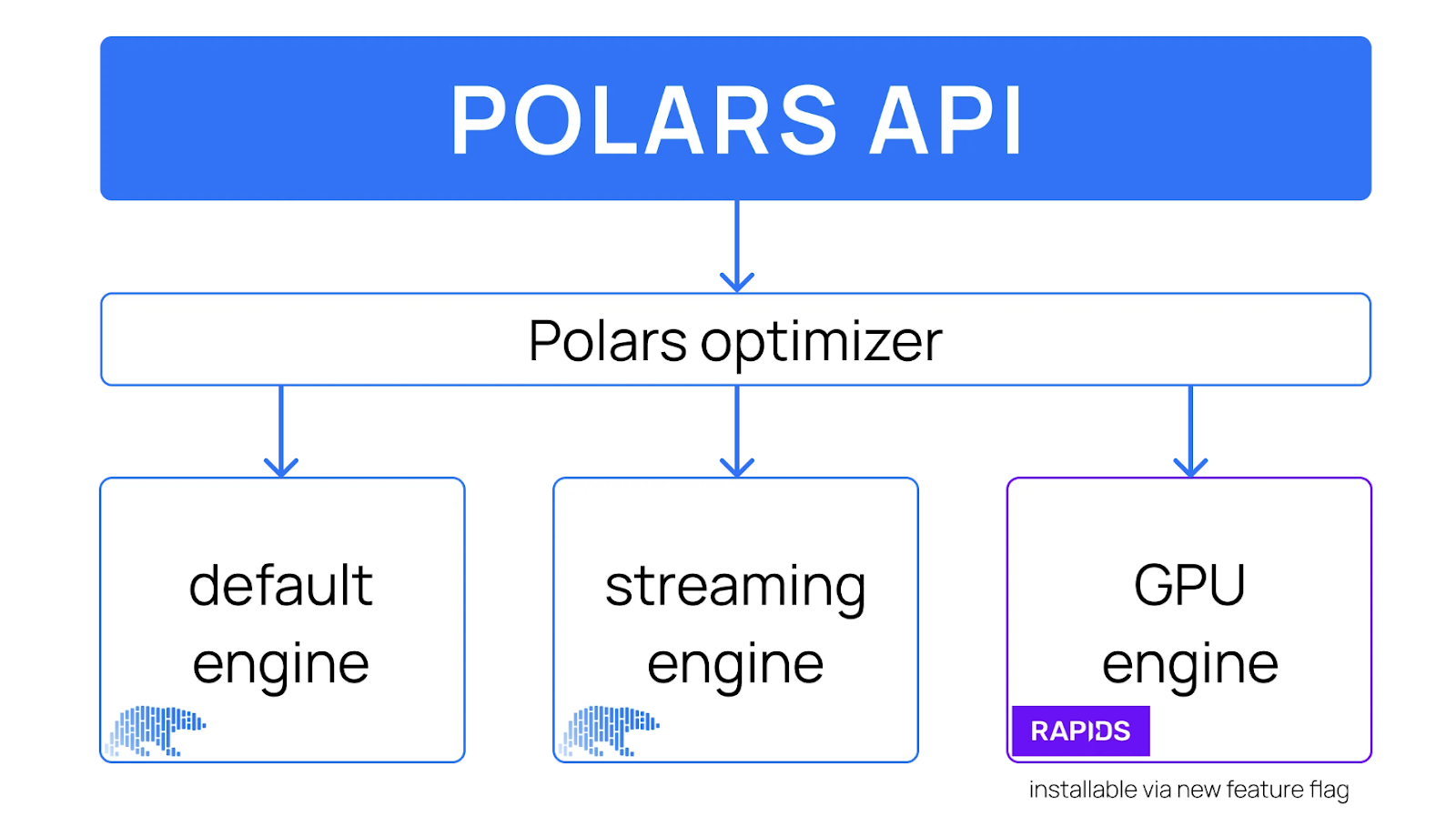
Projeto de alto nível da API Polars, incluindo um mecanismo de GPU. Fonte da imagem: Polares
Com a adição do mecanismo de GPU, os usuários do Polars podem decidir em qual mecanismo executar suas cargas de trabalho de dados. O otimizador Polars é compatível com todos os mecanismos, determinando dinamicamente quais consultas podem ser executadas na GPU ou na CPU.
Portanto, agora você tem algum contexto sobre o Polars e a biblioteca NVIDIA RAPIDS cuDF e como ambos se integram e são disponibilizados por meio da API Python Polars. Mas o que isso significa para os desenvolvedores e cientistas de dados?
Aqui está um resumo do que o mecanismo de GPU Polars permite:
engine="gpu" para a operação collect() na API Lazy do Polars, permitindo o processamento da GPU sem alterações significativas no código.Então, quais são os resultados até agora? Vejamos.
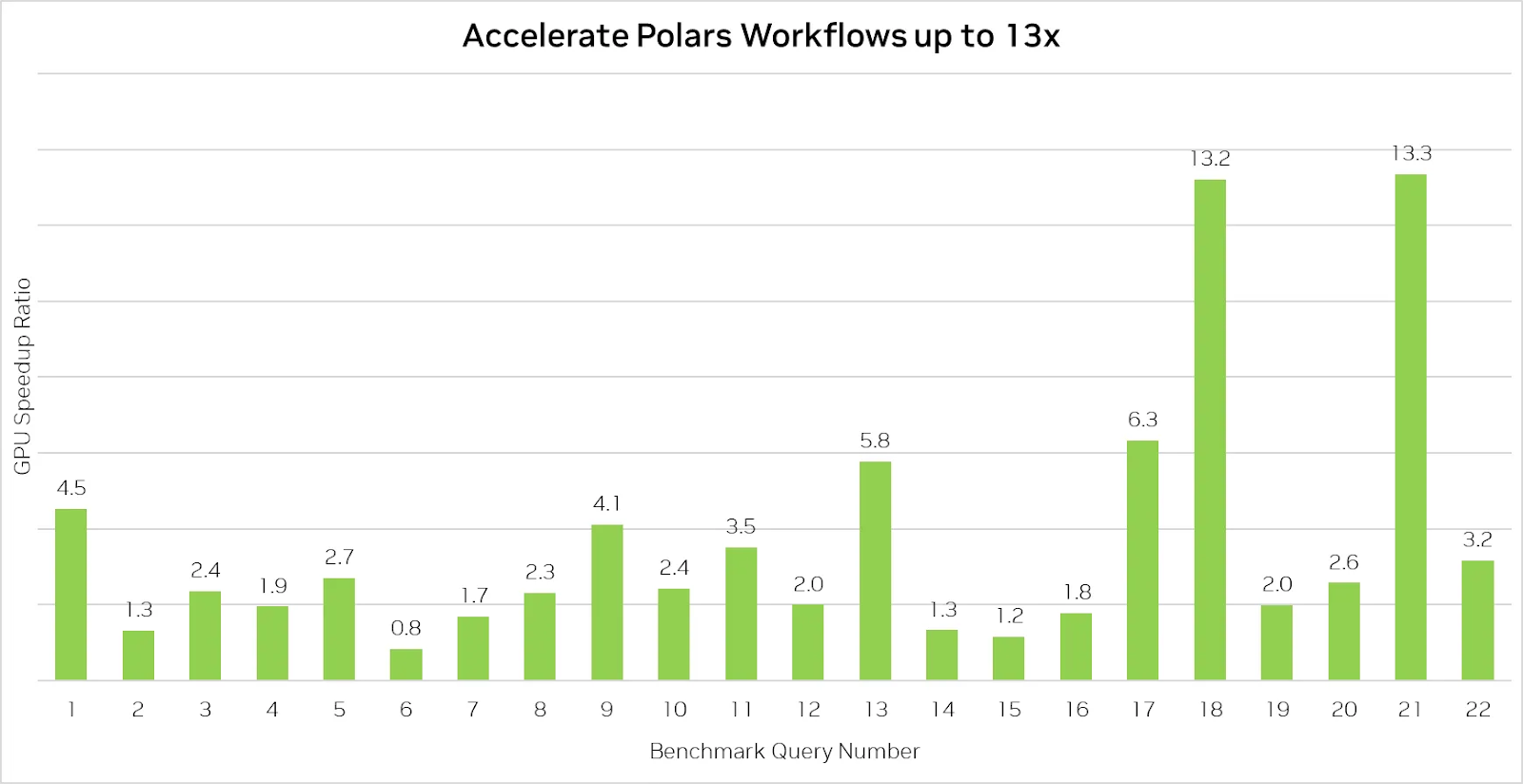
O Polars GPU Engine acelera o processamento de dados em até 13 vezes. Fonte da imagem: Polares
O benchmark acima demonstra os recursos impressionantes do mecanismo de GPU Polars, acelerando as consultas em até 13 vezes.
No entanto, é importante observar que nem sempre é garantido que o uso do Polars em uma GPU seja mais rápido do que em uma CPU, especialmente para consultas mais simples que não são computacionalmente intensivas. Nesses casos, o desempenho geralmente é limitado pela velocidade de leitura de dados do disco, o que significa que a aceleração da GPU oferece menos vantagens quando as operações de entrada/saída (E/S) são a principal restrição.
Dito isso, o mecanismo de GPU oferece aumentos de velocidade significativos para operações de dados mais complexas, o que o torna uma ferramenta valiosa para equipes que lidam com grandes conjuntos de dados ou consultas que envolvem uniões, agrupamentos e processamento de strings.
Um dos recursos mais atraentes dessa nova integração é sua flexibilidade. Conforme mencionado anteriormente, o otimizador pode alternar entre a execução da CPU e da GPU com base na complexidade de suas consultas. Mas como exatamente essa transição funciona?
Ao executar o Polars na CPU, o mecanismo segue um pipeline estruturado e altamente otimizado para executar operações de dados. Esse processo envolve aproximadamente as seguintes etapas:
Quando você ativa a aceleração da GPU passando engine="gpu" para o método .collect(), o processo permanece essencialmente o mesmo na superfície, mas com verificações e otimizações adicionais nos bastidores para determinar quanto da carga de trabalho pode ser transferida para a GPU, por meio do cuDF:
Esse modelo de execução híbrido, em que a GPU e a CPU são usadas em conjunto, torna o Polars altamente flexível. Você se beneficia da aceleração da GPU sem sacrificar a compatibilidade com consultas não compatíveis com a GPU. Os Polares publicação no blog de lançamento explica isso com mais detalhes técnicos.
Finalmente, a parte mais emocionante! Nesta seção, examinarei as etapas necessárias para configurar seu ambiente e começar a aproveitar o processamento de dados acelerado por GPU.
A maneira mais simples de começar a trabalhar é seguir este caderno do Google Colab.
O Colab oferece uso limitado e gratuito da GPU, o que é particularmente útil se você não tiver acesso imediato a uma GPU. Se você estiver usando o notebook fornecido, começaremos a partir da etapa 2 abaixo, portanto, você pode pular as etapas anteriores.
Antes de instalar o mecanismo de GPU Polars, verifique se o seu sistema atende aos requisitos do NVIDIA RAPIDS cuDF. Você pode revisar as especificações necessárias do sistema, incluindo a compatibilidade da GPU e os requisitos de driver, na página de documentação do página de documentação do RAPIDS.
Para começar a usar o mecanismo de GPU Polars, a prática recomendada é criar um ambiente virtual para isolar as dependências do projeto.
Eu usei o conda neste exemplo, mas você pode usar o gerenciador de pacotes de sua preferência.
Além do Python, você pode incluir o JupyterLab no ambiente para exploração e desenvolvimento de dados interativos, o que é especialmente útil para executar pequenos trechos de código e analisar conjuntos de dados em tempo real.
conda create -n polars-gpu -c conda-forge python=3.11 jupyterlabDepois de criar o ambiente virtual, ative-o usando:
conda activate polars-gpuAgora, vamos ativar a aceleração de GPU instalando o Polars e o mecanismo de GPU. Isso também configurará o cuDF e outras dependências necessárias para o uso de GPUs NVIDIA:
pip install -U polars[gpu] --extra-index-url=https://pypi.nvidia.comQuando o mecanismo de GPU do Polars estiver instalado, você terá a mesma sensação de trabalhar com a CPU, mas com resultados muito mais rápidos para fluxos de trabalho complexos ou com muitos dados.
Conforme explicado anteriormente, o mecanismo Polars otimiza automaticamente o plano de execução, utilizando totalmente a GPU NVIDIA para acelerar as operações e minimizar o uso da memória. Para consultas que não são compatíveis com a aceleração de GPU, o mecanismo de GPU do Polars tem um fallback de CPU gracioso, garantindo que o fluxo de trabalho continue sem interrupções.
Vamos colocar o mecanismo em ação com alguns exemplos simples!
Para esta demonstração, usaremos um conjunto de dados de conjunto de dados de 22 GB de transações financeiras simuladas do Kaggle. A NVIDIA hospeda o conjunto de dados em um bucket do Google Cloud Storage (GCS), garantindo velocidades de download rápidas.
Para começar, faça o download do conjunto de dados:
!wget https://storage.googleapis.com/rapidsai/polars-demo/transactions.parquet -O transactions.parquetComo esse conjunto de dados é proveniente do Kaggle, ele é regido por uma licença específica do conjunto de dados do Kaggle e pelos termos de uso.
Vamos carregar o conjunto de dados usando o Polars e inspecionar o esquema:
import polars as pl
from polars.testing import assert_frame_equal
transactions = pl.scan_parquet("transactions.parquet")
transactions.collect_schema()Aqui está o resultado:
Schema([('CUST_ID', String),
('START_DATE', Date),
('END_DATE', Date),
('TRANS_ID', String),
('DATE', Date),
('YEAR', Int64),
('MONTH', Int64),
('DAY', Int64),
('EXP_TYPE', String),
('AMOUNT', Float64)])Agora, vamos calcular o volume total de transações somando a coluna AMOUNT. Primeiro, vamos tentar sem a aceleração da GPU:
transactions.select(pl.col("AMOUNT").sum()).collect()Saída:
AMOUNT
f64
3.6183e9Esse é um grande volume total de transações! Vamos executar a mesma consulta na GPU:
transactions.select(pl.col("AMOUNT").sum()).collect(engine="gpu")Saída:
AMOUNT
f64
3.6183e9Para operações simples como essa, a CPU e a GPU produzem o mesmo resultado com velocidade semelhante, pois a consulta não é computacionalmente intensiva o suficiente para se beneficiar muito da aceleração da GPU. No entanto, a GPU se destacará ao lidar com consultas mais complexas.
Agora, vamos passar para uma consulta mais complexa. Nessa consulta, agrupamos as transações por ID de cliente (CUST_ID), somamos os valores totais das transações e, em seguida, classificamos os resultados pelos maiores gastadores.
Primeiro, vamos executá-lo na CPU:
%%time
res_cpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect()
)
res_cpuAqui está o resultado:
CPU times: user 4.63 s, sys: 3.75 s, total: 8.38 s
Wall time: 6.04 s
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6Agora, vamos executar a mesma consulta na GPU:
%%time
res_gpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect(engine=”gpu”)
)
res_gpuSaída:
CPU times: user 347 ms, sys: 0 ns, total: 347 ms
Wall time: 353 ms
shape: (5, 2)
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6Como podemos ver, o uso da GPU para consultas mais complexas oferece ganhos significativos de desempenho, reduzindo o tempo de execução de 6,04 segundos na CPU para apenas 353 milissegundos na GPU!
Esse exemplo demonstra o poderoso aumento de desempenho que o mecanismo de GPU Polars oferece para operações de dados em grande escala.
Você pode encontrar exemplos mais avançados no Caderno do Colab.
O mecanismo de GPU Polars, alimentado pelo NVIDIA RAPIDS cuDF, traz melhorias de velocidade impressionantes, com processamento de dados até 13 vezes mais rápido para operações complexas. Para conjuntos de dados em grande escala, o Polars oferece uma clara vantagem sobre as bibliotecas DataFrame tradicionais.
Mesmo que nem todas as consultas se beneficiem igualmente da aceleração da GPU, o Polars continua sendo uma ferramenta poderosa para quem trabalha com grandes conjuntos de dados. A facilidade de integração, combinada com seu modelo de execução híbrido CPU-GPU, torna o Polars um forte concorrente para os fluxos de trabalho de dados modernos.
Se você estiver interessado em desenvolver suas habilidades de manipulação de dados, especialmente com o Pandas, recomendo vivamente que dê uma olhada nesses cursos:
Esses recursos darão a você uma base sólida que complementa os recursos avançados de ferramentas como o Polars!
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Aprenda mais sobre ciência de dados e Python com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
9 min
Tutorial
Abid Ali Awan
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
Tutorial
Abid Ali Awan
