
programa
Desarrollar aplicaciones con LangChain
9 h
La generación aumentada por recuperación (RAG) se está convirtiendo rápidamente en una de las evoluciones más prácticas en el uso de grandes modelos lingüísticos. No se trata de un nuevo modelo ni de sustituir a los LLM, sino de un sistema innovador que les ayuda a razonar con hechos extraídos de fuentes de datos reales. En esencia, la RAG resuelve algunos de los mayores retos de la IA generativa: las alucinaciones, la memoria limitada y los conocimientos obsoletos. Combinar la recuperación y la generación en un único proceso permite a los modelos basar sus respuestas en un contexto actual y relevante, a menudo específico de un negocio o dominio.
Este cambio es más importante que nunca. En entornos empresariales, se espera que los LLM respondan con precisión y explicabilidad. Los programadores quieren resultados que reflejen la documentación del producto, las wikis internas o los tickets de soporte, no conocimientos web genéricos. El GAR lo hace posible.
Esta guía explica cómo funciona el marco RAG, dónde encaja en tu pila de IA y cómo utilizarlo con herramientas y datos fundamentales.
RAG significa Recuperar, Aumentar, Generar. Es inteligente dar a los grandes modelos lingüísticos (LLM) acceso a conocimientos externos sin volver a entrenarlos.
Ésta es la idea: cuando un usuario hace una pregunta, en lugar de lanzarla directamente al modelo y esperar una buena respuesta, RAG recuperaprimero información relevante de una base de conocimientos. Después, aumenta la indicación original con este contexto extra. Por último, elLLM genera una respuesta utilizando la pregunta y la información añadida.
Este enfoque ayuda a resolver las limitaciones clave del LLM -como las alucinaciones, la memoria corta (ventanas de contexto) y los cortes de conocimiento- introduciendo datos reales, actuales y relevantes sobre la marcha.
Los LLM independientes son impresionantes, pero tienen puntos ciegos. Alucinan, olvidan cosas y no saben nada más nuevo que su último entrenamiento. Los GAR cambian eso. Al combinar los LLM con la recuperación en tiempo real, obtienes:
En resumen, RAG te permite construir sistemas de IA más inteligentes y fiables con mucho menos esfuerzo.
El ecosistema RAG está creciendo rápidamente, con docenas de proyectos de código abierto que ayudan a los programadores a crear aplicaciones más inteligentes y mejoradas para la recuperación. Tanto si buscas algo conectable y sencillo como un pipeline completo con componentes personalizables, es probable que haya una herramienta para ti.
A continuación, repasaremos los principales marcos RAG de código abierto. Cada entrada destaca su tracción en GitHub, estilo de despliegue, puntos fuertes únicos, casos de uso principales y un elemento visual para que te hagas una idea rápida del proyecto.
Haystack es un marco robusto y modular diseñado para construir sistemas de PNL listos para la producción. Admite varios componentes, como recuperadores, lectores y generadores, lo que permite una integración perfecta con herramientas como Elasticsearch y Hugging Face Transformers.
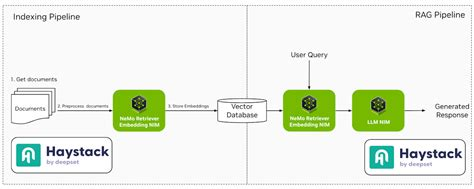
LlamaIndex es un marco de datos que conecta fuentes de datos personalizadas con grandes modelos lingüísticos. Simplifica el proceso de indexación y consulta de datos, facilitando la creación de aplicaciones que requieren respuestas conscientes del contexto.
LangChain es un marco integral que permite a los programadores crear aplicaciones basadas en modelos lingüísticos. Ofrece herramientas para encadenar distintos componentes, como plantillas de avisos, memorias y agentes, para crear flujos de trabajo complejos.
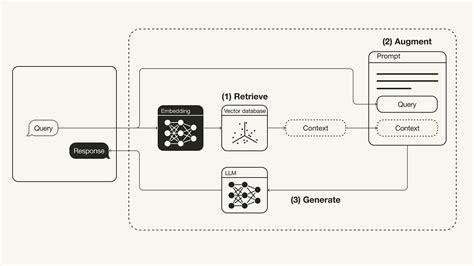
RAGFlow es un motor de código abierto centrado en la comprensión profunda de documentos. Proporciona un flujo de trabajo racionalizado para que las empresas implanten sistemas GAR, haciendo hincapié en la veracidad de las respuestas a las preguntas, respaldadas por citas de formatos de datos complejos.
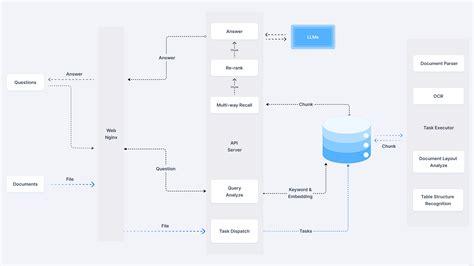
txtAI es un marco de IA todo en uno que combina la búsqueda semántica con las capacidades de la GAR. Permite crear aplicaciones que busquen, indexen y recuperen información de forma eficaz, admitiendo varios tipos y formatos de datos.
Cognita es un marco RAG modular diseñado para facilitar la personalización y el despliegue. Ofrece una interfaz frontal para experimentar con distintas configuraciones de RAG, lo que la hace adecuada tanto para entornos de desarrollo como de producción.
LLMWare proporciona un marco unificado para crear aplicaciones RAG de nivel empresarial. Hace hincapié en el uso de modelos pequeños y especializados que puedan desplegarse de forma privada, garantizando la seguridad de los datos y el cumplimiento de la normativa.
STORM es un asistente de investigación que amplía el concepto de GAR basado en esquemas. Se centra en generar artículos completos sintetizando información de varias fuentes, lo que lo hace ideal para tareas de creación de contenidos.
R2R (Reason to Retrieve) es un sistema avanzado de recuperación de IA compatible con el GAR con funciones listas para la producción. Ofrece ingesta de contenido multimodal, búsqueda híbrida e integración de grafos de conocimiento, atendiendo a las complejas necesidades empresariales.
EmbedChain es una biblioteca de Python que simplifica la creación y el despliegue de aplicaciones de IA utilizando modelos RAG. Admite varios tipos de datos, como PDF, imágenes y páginas web, lo que lo hace versátil para distintos casos de uso.
RAGatouille integra métodos avanzados de recuperación, como ColBERT, en los conductos RAG. Permite la experimentación modular con distintas técnicas de recuperación, mejorando la flexibilidad y el rendimiento de los sistemas RAG.
Verba es un asistente personal personalizable que utiliza RAG para consultar datos e interactuar con ellos. Se integra con la base de datos consciente del contexto de Weaviate, lo que permite una recuperación de la información y una interacción eficaces.
Jina AI ofrece herramientas para crear aplicaciones multimodales de IA con opciones de despliegue escalables. Es compatible con varios protocolos de comunicación, lo que la hace adecuada para programadores que quieran crear y ampliar servicios de IA.
Neurite es un marco RAG emergente que simplifica la creación de aplicaciones potenciadas por IA. Su énfasis en la experiencia de los programadores y la creación rápida de prototipos la convierten en una opción atractiva para la experimentación.
LLM-App es un marco para crear aplicaciones basadas en grandes modelos lingüísticos. Proporciona plantillas y herramientas para agilizar el proceso de desarrollo, facilitando la integración de las capacidades de RAG en diversas aplicaciones.
Cada marco ofrece características únicas adaptadas a diferentes casos de uso y preferencias de despliegue. En función de tus requisitos específicos, la facilidad de despliegue, la personalización o las capacidades de integración, puedes elegir el marco que mejor se ajuste a los objetivos de tu proyecto.
La selección del marco GAR adecuado depende de tus necesidades específicas: análisis de documentos legales, investigación académica o desarrollo local ligero. Utiliza esta tabla para comparar rápidamente los marcos RAG de código abierto más populares en función de cómo se despliegan, lo personalizables que son, su compatibilidad con la recuperación avanzada, las capacidades de integración y para qué se utiliza mejor cada herramienta.
Los sistemas RAG pueden ser robustos, pero también tienen aristas afiladas. Si no tienes cuidado, las respuestas de tu modelo pueden acabar peor que si no hubieras utilizado la recuperación. He aquí cuatro problemas comunes que debes evitar, y qué hacer en su lugar.
No todo tiene que ir a tu tienda de vectores. Volcar cada documento, entrada de blog o hilo de correo electrónico puede parecer minucioso, pero sólo contamina tu búsqueda. El recuperador atrae contexto de poco valor, que el modelo debe clasificar (a menudo mal utilizado). En su lugar, sé selectivo. Sólo indexa contenidos que sean precisos, estén bien escritos y sean útiles. Limpia antes de guardar.
Los LLM tienen poca memoria. Algo se corta si tu petición, más todos los trozos recuperados, supera el límite de tokens del modelo. Ese "algo" podría ser la parte importante. En lugar de eso, mantén las indicaciones ajustadas. Limita el número de trozos recuperados o resúmelos antes de enviarlos al modelo.
Es tentador recuperar más documentos para asegurarte de que "lo cubres todo". Pero si los resultados adicionales están poco relacionados, llenas el mensaje de palabrería. El modelo se distrae o, peor aún, se confunde. En lugar de eso, busca una gran precisión. Unos pocos trozos muy relevantes son mejores que una larga lista de partidos débiles.
Cuando el modelo da una mala respuesta, ¿sabes por qué? Estás depurando en la oscuridad si no registras la consulta, los documentos recuperados y la consulta final. En su lugar, Registra el flujo RAG completo. Eso incluye la entrada del usuario, el contenido recuperado, lo que se envió al modelo y la respuesta del modelo.
La RAG no es una solución mágica para todo, pero cuando se utiliza correctamente, es una de las formas más eficaces de hacer que los LLM sean más innovadores, prácticos y basados en los datos que importan a tu empresa.
La clave está en saber con qué trabajas. Elegir el marco adecuado forma parte de ello, pero el éxito se reduce a lo bien que entiendas tus datos y a lo cuidadosamente que afines tu canal de recuperación. El principio de "basura entrante, basura saliente" sigue siendo válido, sobre todo cuando construyes sistemas que generan lenguaje, no sólo recuperan hechos.
Haz una indexación correcta, vigila el uso de tokens y controla el flujo de extremo a extremo. Cuando todas esas piezas encajan, RAG puede transformar tus aplicaciones de IA de impresionantes a auténticamente útiles.
Aprende IA con DataCamp
programa
Curso
Curso
blog
Yuliya Melnik
15 min
blog
Hesam Sheikh Hassani
12 min
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan

