
Programa
Desenvolvimento de aplicativos com LangChain
9 h
A geração aumentada por recuperação (RAG) está se tornando rapidamente uma das evoluções mais práticas no uso de grandes modelos de linguagem. Não se trata de um novo modelo ou de um substituto para os LLMs; em vez disso, é um sistema inovador que os ajuda a raciocinar com fatos extraídos de fontes de dados reais. Em sua essência, o RAG resolve alguns dos maiores desafios da IA generativa: alucinações, memória limitada e conhecimento desatualizado. A combinação da recuperação e da geração em um único pipeline permite que os modelos fundamentem suas respostas em um contexto atual e relevante, geralmente específico de um negócio ou domínio.
Essa mudança é mais importante do que nunca. Em ambientes corporativos, espera-se que os LLMs respondam com precisão e explicação. Os desenvolvedores querem resultados que reflitam a documentação do produto, wikis internos ou tíquetes de suporte, e não conhecimento genérico da Web. O RAG torna isso possível.
Este guia explica como a estrutura RAG funciona, onde ela se encaixa em sua pilha de IA e como usá-la com ferramentas e dados fundamentais.
RAG significa Retrieve, Augment, Generate (Recuperar, Aumentar, Gerar). É inteligente dar aos modelos de linguagem grandes (LLMs) acesso ao conhecimento externo sem precisar treiná-los novamente.
A ideia é a seguinte: quando um usuário faz uma pergunta, em vez de lançá-la diretamente no modelo e esperar uma boa resposta, o RAG primeiro recupera informações relevantes de uma base de conhecimento. Em seguida, ele aumenta o prompt original com esse contexto extra. Por fim, o LLM gera uma resposta usando a pergunta e as informações adicionadas.
Essa abordagem ajuda a solucionar as principais limitações do LLM, como alucinações, memória curta (janelas de contexto) e interrupções de conhecimento, inserindo dados reais, atuais e relevantes em tempo real.
Os LLMs autônomos são impressionantes, mas têm pontos cegos. Eles têm alucinações, esquecem coisas e não sabem nada mais recente do que sua última corrida de treinamento. O RAG muda isso. Ao combinar LLMs com recuperação em tempo real, você obtém:
Em resumo, o RAG permite que você crie sistemas de IA mais inteligentes e confiáveis com muito menos esforço.
O ecossistema RAG está crescendo rapidamente, com dezenas de projetos de código aberto que ajudam os desenvolvedores a criar aplicativos mais inteligentes e com aumento de recuperação. Não importa se você está procurando algo conectável e direto ou um pipeline de pilha completa com componentes personalizáveis, provavelmente há uma ferramenta para você.
A seguir, analisaremos as principais estruturas RAG de código aberto. Cada entrada destaca a tração no GitHub, o estilo de implantação, os pontos fortes exclusivos, os principais casos de uso e um visual para que você tenha uma ideia rápida do projeto.
O Haystack é uma estrutura robusta e modular projetada para criar sistemas de PNL prontos para produção. Ele oferece suporte a vários componentes, como recuperadores, leitores e geradores, permitindo uma integração perfeita com ferramentas como Elasticsearch e Hugging Face Transformers.
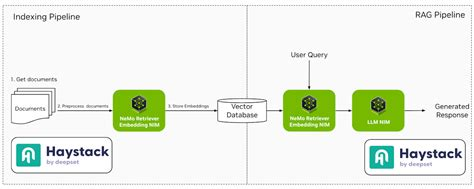
O LlamaIndex é uma estrutura de dados que conecta fontes de dados personalizadas a grandes modelos de linguagem. Ele simplifica o processo de indexação e consulta de dados, facilitando a criação de aplicativos que exigem respostas com reconhecimento de contexto.
O LangChain é uma estrutura abrangente que permite aos desenvolvedores criar aplicativos com base em modelos de linguagem. Ele oferece ferramentas para que você possa unir diferentes componentes, como modelos de prompt, memória e agentes, para criar fluxos de trabalho complexos.
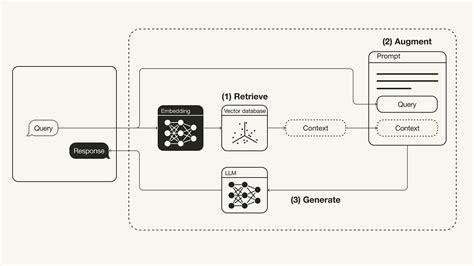
O RAGFlow é um mecanismo de código aberto voltado para a compreensão profunda de documentos. Ele fornece um fluxo de trabalho simplificado para que as empresas implementem sistemas RAG, enfatizando respostas verdadeiras a perguntas apoiadas por citações de formatos de dados complexos.
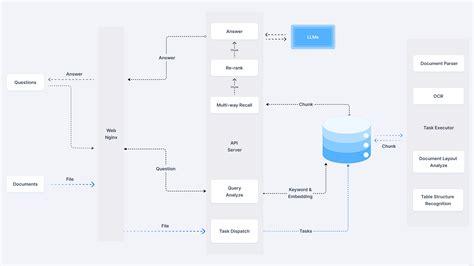
O txtAI é uma estrutura de IA completa que combina pesquisa semântica com recursos de RAG. Ele permite a criação de aplicativos que pesquisam, indexam e recuperam informações com eficiência, oferecendo suporte a vários tipos e formatos de dados.
O Cognita é uma estrutura RAG modular projetada para facilitar a personalização e a implementação. Ele oferece uma interface de front-end para que você possa experimentar diferentes configurações do RAG, tornando-o adequado para ambientes de desenvolvimento e produção.
O LLMWare oferece uma estrutura unificada para a criação de aplicativos RAG de nível empresarial. Ele enfatiza o uso de modelos pequenos e especializados que podem ser implantados de forma privada, garantindo a segurança e a conformidade dos dados.
O STORM é um assistente de pesquisa que amplia o conceito de RAG orientado por contornos. Ele se concentra na geração de artigos abrangentes, sintetizando informações de várias fontes, o que o torna ideal para tarefas de criação de conteúdo.
O R2R (Reason to Retrieve) é um sistema avançado de recuperação de IA que oferece suporte ao RAG com recursos prontos para produção. Ele oferece ingestão de conteúdo multimodal, pesquisa híbrida e integração de gráficos de conhecimento, atendendo a necessidades empresariais complexas.
EmbedChain é uma biblioteca Python que simplifica a criação e a implantação de aplicativos de IA usando modelos RAG. Ele suporta vários tipos de dados, incluindo PDFs, imagens e páginas da Web, o que o torna versátil para diferentes casos de uso.
O RAGatouille integra métodos avançados de recuperação, como o ColBERT, aos pipelines do RAG. Ele permite a experimentação modular com diferentes técnicas de recuperação, aprimorando a flexibilidade e o desempenho dos sistemas RAG.
O Verba é um assistente pessoal personalizável que utiliza o RAG para consultar e interagir com os dados. Ele se integra ao banco de dados com reconhecimento de contexto da Weaviate, permitindo a recuperação e a interação eficientes de informações.
A Jina AI oferece ferramentas para a criação de aplicativos de IA multimodais com opções de implementação dimensionáveis. Ele oferece suporte a vários protocolos de comunicação, o que o torna adequado para desenvolvedores que desejam criar e dimensionar serviços de IA.
Neurite é uma estrutura RAG emergente que simplifica a criação de aplicativos com tecnologia de IA. Sua ênfase na experiência do desenvolvedor e na prototipagem rápida o torna uma opção atraente para a experimentação.
O LLM-App é uma estrutura para a criação de aplicativos alimentados por grandes modelos de linguagem. Ele fornece modelos e ferramentas para otimizar o processo de desenvolvimento, facilitando a integração dos recursos do RAG em vários aplicativos.
Cada estrutura oferece recursos exclusivos adaptados a diferentes casos de uso e preferências de implementação. Dependendo dos seus requisitos específicos, da facilidade de implementação, da personalização ou dos recursos de integração, você pode escolher a estrutura que melhor se alinha aos objetivos do seu projeto.
A seleção da estrutura RAG apropriada depende das suas necessidades específicas: análise de documentos legais, pesquisa acadêmica ou desenvolvimento local leve. Use esta tabela para comparar rapidamente as estruturas RAG populares de código aberto com base em como elas são implantadas, quão personalizáveis são, seu suporte para recuperação avançada, recursos de integração e para que cada ferramenta é melhor usada.
Os sistemas RAG podem ser robustos, mas também possuem bordas afiadas. Se você não tomar cuidado, as respostas do seu modelo podem acabar sendo piores do que se você não tivesse usado nenhuma recuperação. Aqui estão quatro problemas comuns que você deve evitar e o que fazer em vez disso.
Nem tudo precisa ser colocado em sua loja de vetores. Você pode achar que todos os documentos, publicações em blogs ou conversas por e-mail são completos, mas isso apenas polui sua pesquisa. O retriever puxa o contexto de baixo valor, que o modelo deve classificar (geralmente mal utilizado). Em vez disso, seja seletivo. Somente indexar conteúdo preciso, bem escrito e útil. Limpe tudo antes de você armazenar.
Os LLMs têm memória curta. Algo será cortado se o seu prompt, mais todos os blocos recuperados, exceder o limite de tokens do modelo. Esse "algo" pode ser a parte que importa. Em vez disso, mantenha os prompts apertados. Limitar o número de blocos recuperados ou resumi-los antes de enviá-los ao modelo.
É tentador obter mais documentos para garantir que você "cubra tudo". Porém, se os resultados extras estiverem pouco relacionados, você encherá o prompt com coisas sem importância. O modelo fica distraído ou, pior, confuso. Em vez disso, busque alta precisão. Algumas partes altamente relevantes são melhores do que uma longa lista de partidas fracas.
Quando o modelo dá uma resposta ruim, você sabe por quê? Você está depurando no escuro se não estiver registrando a consulta, os documentos recuperados e o prompt final. Em vez disso, registre o fluxo completo do RAG. Isso inclui a entrada do usuário, o conteúdo recuperado, o que foi enviado ao modelo e a resposta do modelo.
O RAG não é uma solução mágica para tudo, mas, quando usado corretamente, é uma das maneiras mais eficazes de tornar os LLMs mais inovadores, práticos e fundamentados nos dados que são importantes para a sua empresa.
O segredo é saber com o que você está trabalhando. Escolher a estrutura certa é parte disso, mas o sucesso se resume a quão bem você entende seus dados e quão cuidadosamente você ajusta seu pipeline de recuperação. A regra "lixo entra, lixo sai" ainda se aplica, especialmente quando você está criando sistemas que geram linguagem, não apenas recuperam fatos.
Faça a indexação correta, observe o uso de tokens e monitore o fluxo de ponta a ponta. Quando todas essas peças se encaixam, o RAG pode transformar seus aplicativos de IA de impressionantes em genuinamente úteis.
Aprenda IA com o DataCamp
Programa
Curso
Curso
blog
Natassha Selvaraj
10 min
blog
Yuliya Melnik
15 min
blog
Abid Ali Awan
8 min
Tutorial
Ryan Ong
