
Cursus
Développement d’applications avec LangChain
9 h
La génération augmentée par récupération (RAG) devient rapidement l'une des évolutions les plus pratiques dans l'utilisation de grands modèles linguistiques. Il ne s'agit pas d'un nouveau modèle ni d'un substitut aux LLM, mais d'un système innovant qui les aide à raisonner à partir de faits tirés de sources de données réelles. À la base, RAG résout certains des plus grands défis de l'IA générative : les hallucinations, la mémoire limitée et les connaissances obsolètes. La combinaison de la recherche et de la génération dans un seul pipeline permet aux modèles d'ancrer leurs réponses dans un contexte actuel et pertinent, souvent spécifique à une entreprise ou à un domaine.
Cette évolution est plus importante que jamais. Dans les entreprises, on attend des LLM qu'ils répondent de manière précise et explicite. Les développeurs veulent des résultats reflétant la documentation du produit, les wikis internes ou les tickets d'assistance, et non des connaissances génériques sur le web. RAG rend cela possible.
Ce guide explique comment fonctionne le cadre RAG, où il s'insère dans votre pile d'IA et comment l'utiliser avec des outils et des données fondamentaux.
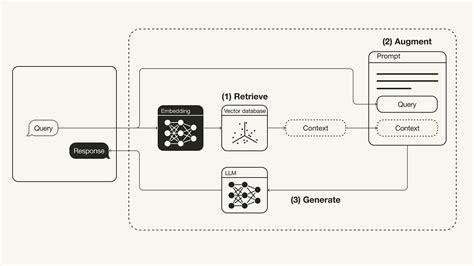
RAG signifie Retrieve, Augment, Generate. Il est judicieux de permettre aux grands modèles de langage (LLM) d'accéder à des connaissances externes sans avoir à les entraîner à nouveau.
Voici l'idée : lorsqu'un utilisateur pose une question, au lieu de la poser directement au modèle et d'espérer une bonne réponse, RAG récupère d'abord les informations pertinentes sur le site à partir d'une base de connaissances. Ensuite, il complète l'invite originale avec ce contexte supplémentaire. Enfin, lesite LLM génère une réponse à partir de la question et des informations ajoutées.
Cette approche permet de résoudre les principales limitations de la LLM, telles que les hallucinations, la mémoire courte (fenêtres contextuelles) et les coupures de connaissances, en introduisant à la volée des données réelles, actuelles et pertinentes.
Les LLM autonomes sont impressionnants, mais ils présentent des lacunes. Ils ont des hallucinations, oublient des choses et ne connaissent rien de plus récent que leur dernière course d'entraînement. Les RAG changent la donne. En combinant les LLM avec la recherche en temps réel, vous obtenez :
En bref, RAG vous permet de construire des systèmes d'IA plus intelligents et plus fiables avec beaucoup moins d'efforts.
L'écosystème RAG se développe rapidement, avec des dizaines de projets open-source aidant les développeurs à créer des applications plus intelligentes, augmentées par la recherche. Que vous recherchiez quelque chose d'enfichable et de simple ou un pipeline complet avec des composants personnalisables, il y a probablement un outil pour vous.
Ci-dessous, nous allons passer en revue les meilleurs frameworks RAG open-source. Chaque entrée met en évidence sa traction GitHub, son style de déploiement, ses forces uniques, ses principaux cas d'utilisation, ainsi qu'un visuel pour vous donner une idée rapide du projet.
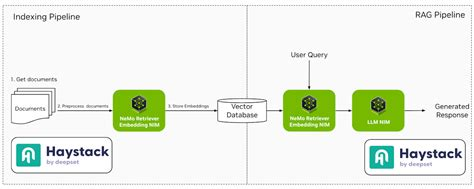
Haystack est un cadre robuste et modulaire conçu pour construire des systèmes NLP prêts à la production. Il prend en charge divers composants tels que les récupérateurs, les lecteurs et les générateurs, ce qui permet une intégration transparente avec des outils tels qu'Elasticsearch et Hugging Face Transformers.
LlamaIndex est un cadre de données qui relie des sources de données personnalisées à de grands modèles linguistiques. Il simplifie le processus d'indexation et d'interrogation des données, ce qui facilite la création d'applications nécessitant des réponses adaptées au contexte.
LangChain est un cadre complet qui permet aux développeurs de créer des applications basées sur des modèles linguistiques. Il offre des outils permettant d'enchaîner différents composants tels que des modèles d'invite, des mémoires et des agents afin de créer des flux de travail complexes.
RAGFlow est un moteur open-source axé sur la compréhension approfondie des documents. Il fournit aux entreprises un flux de travail rationalisé pour la mise en œuvre des systèmes RAG, en mettant l'accent sur des questions-réponses véridiques étayées par des citations tirées de formats de données complexes.
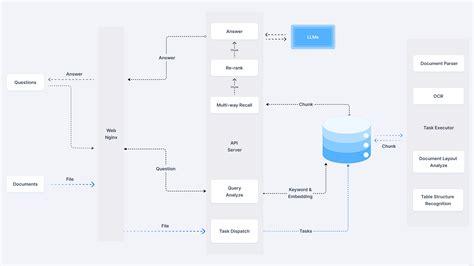
txtAI est un cadre d'IA tout-en-un qui combine la recherche sémantique et les capacités de RAG. Il permet de créer des applications qui recherchent, indexent et récupèrent efficacement des informations, en prenant en charge différents types et formats de données.
Cognita est un cadre RAG modulaire conçu pour faciliter la personnalisation et le déploiement. Il offre une interface frontale permettant d'expérimenter différentes configurations RAG, ce qui le rend adapté aux environnements de développement et de production.
LLMWare fournit un cadre unifié pour la création d'applications RAG de niveau entreprise. Elle met l'accent sur l'utilisation de petits modèles spécialisés qui peuvent être déployés de manière privée, tout en garantissant la sécurité des données et la conformité.
STORM est un assistant de recherche qui étend le concept de RAG axé sur les contours. Il se concentre sur la création d'articles complets en synthétisant des informations provenant de diverses sources, ce qui le rend idéal pour les tâches de création de contenu.
R2R (Reason to Retrieve) est un système avancé de récupération de l'IA qui soutient RAG avec des caractéristiques prêtes pour la production. Il permet l'ingestion de contenus multimodaux, la recherche hybride et l'intégration de graphes de connaissances, répondant ainsi aux besoins complexes des entreprises.
EmbedChain est une bibliothèque Python qui simplifie la création et le déploiement d'applications d'IA utilisant des modèles RAG. Il prend en charge différents types de données, notamment les PDF, les images et les pages web, ce qui le rend polyvalent pour différents cas d'utilisation.
RAGatouille intègre des méthodes de recherche avancées comme ColBERT dans les pipelines RAG. Il permet d'expérimenter de manière modulaire différentes techniques de recherche, améliorant ainsi la flexibilité et les performances des systèmes RAG.
Verba est un assistant personnel personnalisable qui utilise RAG pour interroger et interagir avec les données. Il s'intègre à la base de données contextuelle de Weaviate, ce qui permet une recherche d'informations et une interaction efficaces.
Jina AI offre des outils pour construire des applications d'IA multimodales avec des options de déploiement évolutives. Il prend en charge différents protocoles de communication, ce qui le rend adapté aux développeurs qui souhaitent créer et mettre à l'échelle des services d'intelligence artificielle.
Neurite est un cadre RAG émergent qui simplifie la création d'applications alimentées par l'IA. L'accent mis sur l'expérience du développeur et le prototypage rapide en font une option attrayante pour l'expérimentation.
LLM-App est un cadre pour la création d'applications basées sur de grands modèles de langage. Il fournit des modèles et des outils pour rationaliser le processus de développement, facilitant ainsi l'intégration des capacités RAG dans diverses applications.
Chaque cadre offre des caractéristiques uniques adaptées aux différents cas d'utilisation et aux préférences de déploiement. En fonction de vos besoins spécifiques, de la facilité de déploiement, de la personnalisation ou des capacités d'intégration, vous pouvez choisir le cadre qui correspond le mieux aux objectifs de votre projet.
Le choix du cadre RAG approprié dépend de vos besoins spécifiques : analyse de documents juridiques, recherche universitaire ou développement local léger. Utilisez ce tableau pour comparer rapidement les cadres RAG open-source les plus populaires en fonction de leur mode de déploiement, de leur degré de personnalisation, de leur prise en charge de la recherche avancée, de leurs capacités d'intégration et de l'utilisation optimale de chaque outil.
Les systèmes RAG peuvent être robustes, mais ils présentent aussi des arêtes vives. Si vous ne faites pas attention, les réponses de votre modèle risquent d'être moins bonnes que si vous n'aviez pas utilisé l'extraction. Voici quatre problèmes courants à éviter et ce qu'il faut faire à la place.
Il n'est pas nécessaire de tout mettre dans votre boutique vectorielle. Le fait de jeter tous les documents, articles de blog ou courriels peut sembler exhaustif, mais cela ne fait que polluer votre recherche. Le récupérateur attire un contexte de faible valeur, que le modèle doit trier (souvent mal utilisé). Au lieu de cela, , soyez sélectif. N'indexez que les contenus exacts, bien rédigés et utiles. Nettoyez avant de stocker.
Les LLM ont la mémoire courte. Quelque chose est coupé si votre invite, plus tous les morceaux récupérés, dépasse la limite de jetons du modèle. Ce "quelque chose" pourrait être la partie qui compte. Au lieu de cela, vous devez vous en tenir à un nombre restreint de questions. Limitez le nombre de morceaux récupérés ou résumez-les avant de les envoyer au modèle.
Il est tentant de récupérer davantage de documents pour s'assurer de "tout couvrir". Mais si les résultats supplémentaires sont vaguement liés, vous encombrez l'invite avec des informations superficielles. Le modèle est distrait ou, pire, confus. Visez plutôt une grande précision. Quelques morceaux très pertinents valent mieux qu'une longue liste de matches médiocres.
Lorsque le modèle donne une mauvaise réponse, savez-vous pourquoi ? Vous déboguez dans l'obscurité si vous n'enregistrez pas la requête, les documents récupérés et l'invite finale. Au lieu de cela, enregistrez l'ensemble du flux RAG. Il s'agit de l'entrée de l'utilisateur, du contenu récupéré, de ce qui a été envoyé au modèle et de la réponse du modèle.
Le RAG n'est pas la solution miracle à tout, mais lorsqu'il est utilisé correctement, c'est l'un des moyens les plus efficaces pour rendre les MLD plus innovants, plus pratiques et mieux ancrés dans les données qui comptent pour votre entreprise.
La clé est de savoir avec quoi vous travaillez. Le choix du bon cadre en fait partie, mais le succès dépend de la façon dont vous comprenez vos données et de l'attention que vous portez à votre pipeline d'extraction. Le principe du "garbage in, garbage out" s'applique toujours, en particulier lorsque vous construisez des systèmes qui génèrent du langage et ne se contentent pas d'extraire des faits.
Veillez à ce que votre indexation soit correcte, surveillez l'utilisation de vos jetons et contrôlez le flux de bout en bout. Lorsque toutes ces pièces s'emboîtent, RAG peut transformer vos applications d'IA d'impressionnantes en véritablement utiles.
Apprenez l'IA avec DataCamp
Cursus
Cours
Cours