
Track
Developing Applications with LangChain
9 hr
Retrieval-augmented generation (RAG) is quickly becoming one of the most practical evolutions in using large language models. It's not a new model or a replacement for LLMs; instead, it's an innovative system that helps them reason with facts pulled from real data sources. At its core, RAG solves some of the biggest challenges in generative AI: hallucinations, limited memory, and outdated knowledge. Combining retrieval and generation into a single pipeline lets models ground their answers in a current, relevant context, often specific to a business or domain.
This shift matters more than ever. In enterprise settings, LLMs are expected to answer with accuracy and explainability. Developers want outputs reflecting product documentation, internal wikis, or support tickets, not generic web knowledge. RAG makes that possible.
This guide explains how the RAG framework works, where it fits your AI stack, and how to use it with fundamental tools and data.
RAG stands for Retrieve, Augment, Generate. It's smart to give large language models (LLMs) access to external knowledge without retraining them.
Here’s the idea: when a user asks a question, instead of throwing that question straight at the model and hoping for a good answer, RAG first retrieves relevant information from a knowledge base. Then, it augments the original prompt with this extra context. Finally, the LLM generates a response using the question and the added information.
This approach helps solve key LLM limitations—like hallucinations, short memory (context windows), and knowledge cutoffs—by plugging in real, current, and relevant data on the fly.
Standalone LLMs are impressive, but they have blind spots. They hallucinate, forget things, and know nothing newer than their last training run. RAG changes that. By combining LLMs with real-time retrieval, you get:
In short, RAG lets you build smarter, more trustworthy AI systems with far less effort.
The RAG ecosystem is growing fast, with dozens of open-source projects helping developers build smarter, retrieval-augmented applications. Whether you're looking for something pluggable and straightforward or a full-stack pipeline with customizable components, there’s likely a tool for you.
Below, we'll review the top open-source RAG frameworks. Each entry highlights its GitHub traction, deployment style, unique strengths, primary use cases, and a visual to give you a quick feel for the project.
Haystack is a robust, modular framework designed for building production-ready NLP systems. It supports various components like retrievers, readers, and generators, allowing seamless integration with tools like Elasticsearch and Hugging Face Transformers.
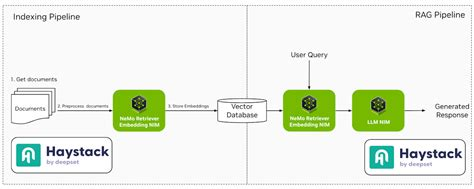
LlamaIndex is a data framework that connects custom data sources to large language models. It simplifies the process of indexing and querying data, making it easier to build applications that require context-aware responses.
LangChain is a comprehensive framework that enables developers to build applications powered by language models. It offers tools for chaining together different components like prompt templates, memory, and agents to create complex workflows.
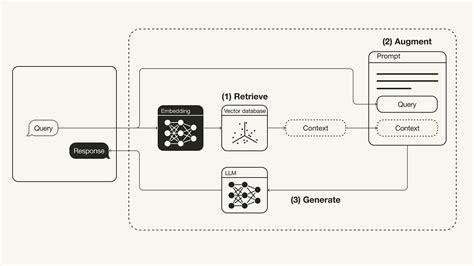
RAGFlow is an open-source engine focused on deep document understanding. It provides a streamlined workflow for businesses to implement RAG systems, emphasizing truthful question-answering backed by citations from complex data formats.
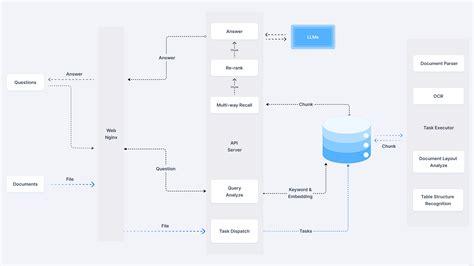
txtAI is an all-in-one AI framework that combines semantic search with RAG capabilities. It allows for building applications that efficiently search, index, and retrieve information, supporting various data types and formats.
Cognita is a modular RAG framework designed for easy customization and deployment. It offers a frontend interface to experiment with different RAG configurations, making it suitable for both development and production environments.
LLMWare provides a unified framework for building enterprise-grade RAG applications. It emphasizes using small, specialized models that can be deployed privately, ensuring data security and compliance.
STORM is a research assistant that extends the concept of outline-driven RAG. It focuses on generating comprehensive articles by synthesizing information from various sources, making it ideal for content creation tasks.
R2R (Reason to Retrieve) is an advanced AI retrieval system supporting RAG with production-ready features. It offers multimodal content ingestion, hybrid search, and knowledge graph integration, catering to complex enterprise needs.
EmbedChain is a Python library that simplifies the creation and deployment of AI applications using RAG models. It supports various data types, including PDFs, images, and web pages, making it versatile for different use cases.
RAGatouille integrates advanced retrieval methods like ColBERT into RAG pipelines. It allows for modular experimentation with different retrieval techniques, enhancing the flexibility and performance of RAG systems.
Verba is a customizable personal assistant that utilizes RAG to query and interact with data. It integrates with Weaviate's context-aware database, enabling efficient information retrieval and interaction.
Jina AI offers tools for building multimodal AI applications with scalable deployment options. It supports various communication protocols, making it suitable for developers aiming to build and scale AI services.
Neurite is an emerging RAG framework that simplifies building AI-powered applications. Its emphasis on developer experience and rapid prototyping makes it an attractive option for experimentation.
LLM-App is a framework for building applications powered by large language models. It provides templates and tools to streamline the development process, making integrating RAG capabilities into various applications easier.
Each framework offers unique features tailored to different use cases and deployment preferences. Depending on your specific requirements, ease of deployment, customization, or integration capabilities, you can choose the framework that best aligns with your project's goals.
Selecting the appropriate RAG framework depends on your specific needs: legal document analysis, academic research, or lightweight local development. Use this table to quickly compare popular open-source RAG frameworks based on how they're deployed, how customizable they are, their support for advanced retrieval, integration capabilities, and what each tool is best used for.
RAG systems can be robust, but they also come with sharp edges. If you're not careful, your model's answers might end up worse than if you'd used no retrieval. Here are four common issues to avoid—and what to do instead.
Not everything needs to go into your vector store. Dumping every document, blog post, or email thread might feel thorough, but it just pollutes your search. The retriever pulls in low-value context, which the model must sort through (often misused). Instead, be selective. Only index content that's accurate, well-written, and useful. Clean up before you store.
LLMs have short memories. Something gets cut off if your prompt, plus all the retrieved chunks, exceeds the model's token limit. That "something" might be the part that mattered. Instead, keep prompts tight. Limit the number of retrieved chunks or summarize them before sending them to the model.
It's tempting to retrieve more documents to ensure you "cover everything." But if the extra results are loosely related, you crowd the prompt with fluff. The model gets distracted or, worse, confused. Instead, aim for high precision. A few highly relevant chunks are better than a long list of weak matches.
When the model gives a bad answer, do you know why? You're debugging in the dark if you're not logging the query, retrieved documents, and the final prompt. Instead, Log the full RAG flow. That includes user input, retrieved content, what was sent to the model, and the model's response.
RAG isn't a magic fix for everything, but when used correctly, it's one of the most effective ways to make LLMs more innovative, practical, and grounded in the data that matters to your business.
The key is knowing what you're working with. Choosing the right framework is part of it, but success comes down to how well you understand your data and how carefully you tune your retrieval pipeline. Garbage in, garbage out still applies, especially when you're building systems that generate language, not just retrieve facts.
Get your indexing right, watch your token usage, and monitor the flow end-to-end. When all those pieces click, RAG can transform your AI applications from impressive to genuinely helpful.
Learn AI with DataCamp
Track
Course
Course
blog
Natassha Selvaraj
10 min
blog
Stanislav Karzhev
12 min
Tutorial
Iván Palomares Carrascosa
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
code-along
Dan Becker
