
Lernpfad
Entwicklung von Anwendungen mit LangChain
9 Std.
Die Retrieval-augmented Generation (RAG) wird schnell zu einer der praktischsten Entwicklungen bei der Verwendung großer Sprachmodelle. Es handelt sich nicht um ein neues Modell oder einen Ersatz für LLMs, sondern um ein innovatives System, das ihnen hilft, mit Fakten aus echten Datenquellen zu argumentieren. Im Kern löst RAG einige der größten Herausforderungen der generativen KI: Halluzinationen, begrenztes Gedächtnis und veraltetes Wissen. Durch die Kombination von Abfrage und Generierung in einer einzigen Pipeline können die Modelle ihre Antworten in einem aktuellen, relevanten Kontext verankern, der oft spezifisch für ein Unternehmen oder einen Bereich ist.
Dieser Wandel ist wichtiger denn je. In Unternehmen wird von LLMs erwartet, dass sie mit Genauigkeit und Erklärbarkeit antworten. Entwickler wollen Ergebnisse, die die Produktdokumentation, interne Wikis oder Support-Tickets widerspiegeln, nicht allgemeines Webwissen. Die RAG macht das möglich.
Dieser Leitfaden erklärt, wie das RAG-Framework funktioniert, wo es in deinen KI-Stack passt und wie du es mit grundlegenden Tools und Daten verwendest.
RAG steht für Retrieve, Augment, Generate. Es ist clever, großen Sprachmodellen (LLMs) Zugang zu externem Wissen zu geben, ohne sie neu zu trainieren.
Die Idee ist folgende: Wenn ein/e Nutzer/in eine Frage stellt, stellt RAG diese Frage nicht direkt an das Modell und hofft auf eine gute Antwort, sondern holt sichzunächst relevante Informationen aus einer Wissensdatenbank. Dann ergänzt die ursprüngliche Aufforderung mit diesem zusätzlichen Kontext. Schließlichgeneriert das LLM eine Antwort auf die Frage und die hinzugefügten Informationen.
Dieser Ansatz hilft dabei, die wichtigsten Einschränkungen des LLM zu überwinden - wie Halluzinationen, kurzes Gedächtnis (Kontextfenster) und Wissensabbrüche -, indem reale, aktuelle und relevante Daten spontan eingefügt werden.
Eigenständige LLMs sind beeindruckend, aber sie haben blinde Flecken. Sie halluzinieren, vergessen Dinge und wissen nichts Neues mehr als ihren letzten Trainingslauf. Die RAG ändert das. Durch die Kombination von LLMs mit Echtzeitabfragen erhältst du:
Kurz gesagt: Mit RAG kannst du mit viel weniger Aufwand intelligentere und vertrauenswürdigere KI-Systeme entwickeln.
Das RAG-Ökosystem wächst schnell, mit Dutzenden von Open-Source-Projekten, die Entwicklern helfen, intelligentere Anwendungen mit Suchfunktionen zu entwickeln. Egal, ob du nach einem einfachen Plug-in oder einer kompletten Pipeline mit anpassbaren Komponenten suchst, es gibt bestimmt ein Tool für dich.
Im Folgenden stellen wir die besten Open-Source-RAG-Frameworks vor. Jeder Eintrag hebt die GitHub-Traktion, den Einsatzstil, die besonderen Stärken, die wichtigsten Anwendungsfälle und eine Grafik hervor, die dir ein schnelles Gefühl für das Projekt vermittelt.
Haystack ist ein robustes, modulares Framework, das für den Aufbau produktionsreifer NLP-Systeme entwickelt wurde. Sie unterstützt verschiedene Komponenten wie Retriever, Reader und Generatoren und ermöglicht eine nahtlose Integration mit Tools wie Elasticsearch und Hugging Face Transformers.
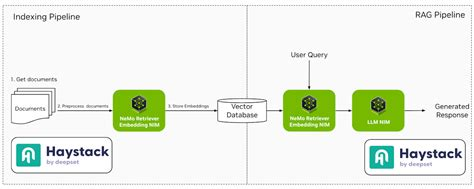
LlamaIndex ist ein Daten-Framework, das benutzerdefinierte Datenquellen mit großen Sprachmodellen verknüpft. Sie vereinfacht die Indizierung und Abfrage von Daten und erleichtert so die Entwicklung von Anwendungen, die kontextbezogene Antworten erfordern.
LangChain ist ein umfassendes Framework, das es Entwicklern ermöglicht, Anwendungen auf Basis von Sprachmodellen zu erstellen. Es bietet Werkzeuge, um verschiedene Komponenten wie Prompt-Vorlagen, Speicher und Agenten miteinander zu verknüpfen und so komplexe Workflows zu erstellen.
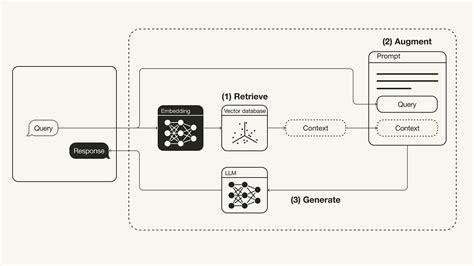
RAGFlow ist eine Open-Source-Engine, die sich auf tiefes Dokumentenverständnis konzentriert. Es bietet einen optimierten Arbeitsablauf für Unternehmen, um RAG-Systeme zu implementieren, wobei der Schwerpunkt auf einer wahrheitsgemäßen Beantwortung von Fragen liegt, die durch Zitate aus komplexen Datenformaten unterstützt werden.
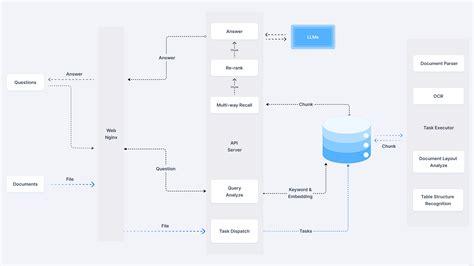
txtAI ist ein All-in-One-KI-Framework, das semantische Suche mit RAG-Funktionen kombiniert. Sie ermöglicht es, Anwendungen zu erstellen, die Informationen effizient suchen, indizieren und abrufen und dabei verschiedene Datentypen und -formate unterstützen.
Cognita ist ein modulares RAG-Framework, das sich leicht anpassen und einsetzen lässt. Es bietet eine Frontend-Oberfläche, um mit verschiedenen RAG-Konfigurationen zu experimentieren und eignet sich daher sowohl für Entwicklungs- als auch für Produktionsumgebungen.
LLMWare bietet ein einheitliches Framework für die Entwicklung von RAG-Anwendungen auf Unternehmensebene. Der Schwerpunkt liegt auf kleinen, spezialisierten Modellen, die privat eingesetzt werden können und die Datensicherheit und Compliance gewährleisten.
STORM ist ein Forschungsassistent, der das Konzept der skizzengesteuerten RAG erweitert. Es konzentriert sich darauf, umfassende Artikel zu erstellen, indem es Informationen aus verschiedenen Quellen zusammenfasst, was es ideal für die Erstellung von Inhalten macht.
R2R (Reason to Retrieve) ist ein fortschrittliches KI-Retrieval-System, das die RAG mit produktionsreifen Funktionen unterstützt. Sie bietet multimodale Inhaltserfassung, hybride Suche und Wissensgraphenintegration und erfüllt damit komplexe Unternehmensanforderungen.
EmbedChain ist eine Python-Bibliothek, die die Erstellung und den Einsatz von KI-Anwendungen mit RAG-Modellen vereinfacht. Sie unterstützt verschiedene Datentypen, darunter PDFs, Bilder und Webseiten, was sie vielseitig für unterschiedliche Anwendungsfälle macht.
RAGatouille integriert fortschrittliche Retrieval-Methoden wie ColBERT in RAG-Pipelines. Es ermöglicht das modulare Experimentieren mit verschiedenen Abfragetechniken und erhöht so die Flexibilität und Leistung von RAG-Systemen.
Verba ist ein anpassbarer persönlicher Assistent, der RAG nutzt, um Daten abzufragen und mit ihnen zu interagieren. Sie ist mit der kontextabhängigen Datenbank von Weaviate integriert und ermöglicht so eine effiziente Informationsbeschaffung und Interaktion.
Jina AI bietet Werkzeuge für den Aufbau multimodaler KI-Anwendungen mit skalierbaren Einsatzmöglichkeiten. Sie unterstützt verschiedene Kommunikationsprotokolle und eignet sich daher für Entwickler, die KI-Dienste aufbauen und skalieren wollen.
Neurite ist ein neues RAG-Framework, das die Entwicklung von KI-gestützten Anwendungen vereinfacht. Der Schwerpunkt auf der Erfahrung der Entwickler und dem schnellen Prototyping macht es zu einer attraktiven Option für Experimente.
LLM-App ist ein Framework zum Erstellen von Anwendungen, die auf großen Sprachmodellen basieren. Es bietet Vorlagen und Werkzeuge, um den Entwicklungsprozess zu rationalisieren und die Integration von RAG-Funktionen in verschiedene Anwendungen zu erleichtern.
Jedes Framework bietet einzigartige Funktionen, die auf unterschiedliche Anwendungsfälle und Einsatzpräferenzen zugeschnitten sind. Je nach deinen spezifischen Anforderungen, der Einfachheit des Einsatzes, der Anpassungsfähigkeit oder den Integrationsmöglichkeiten kannst du das Framework wählen, das am besten zu den Zielen deines Projekts passt.
Die Wahl des geeigneten RAG-Rahmens hängt von deinen spezifischen Bedürfnissen ab: Analyse von Rechtsdokumenten, akademische Forschung oder leichte lokale Entwicklung. Mithilfe dieser Tabelle kannst du beliebte Open-Source-RAG-Frameworks schnell vergleichen, und zwar anhand der Art und Weise, wie sie eingesetzt werden, wie anpassbar sie sind, ob sie erweiterte Abfragen unterstützen, welche Integrationsmöglichkeiten es gibt und wofür die einzelnen Tools am besten geeignet sind.
RAG-Systeme können robust sein, aber sie haben auch ihre Tücken. Wenn du nicht aufpasst, könnten die Antworten deines Modells am Ende schlechter ausfallen, als wenn du keine Abfrage benutzt hättest. Hier sind vier häufige Probleme, die du vermeiden solltest - und was du stattdessen tun kannst.
Nicht alles muss in deinem Vektorladen landen. Es mag sich gründlich anfühlen, wenn du jedes Dokument, jeden Blogeintrag und jede E-Mail auswirfst, aber das verschmutzt nur deine Suche. Der Retriever zieht minderwertigen Kontext heran, den das Modell sortieren muss (was oft missbraucht wird). Stattdessen sollte selektiv sein. Indexiere nur Inhalte, die korrekt, gut geschrieben und nützlich sind. Räumt auf, bevor ihr einlagert.
LLMs haben ein kurzes Gedächtnis. Etwas wird abgeschnitten, wenn dein Prompt plus alle abgerufenen Chunks das Token-Limit des Modells überschreitet. Dieses "etwas" könnte der Teil sein, auf den es ankommt. Halte die Aufforderungen stattdessen knapp. Begrenze die Anzahl der abgerufenen Chunks oder fasse sie zusammen, bevor du sie an das Modell sendest.
Es ist verlockend, mehr Dokumente abzurufen, um sicherzustellen, dass du "alles abdeckst". Aber wenn die zusätzlichen Ergebnisse nur lose miteinander verbunden sind, überfrachtest du die Aufforderung mit Fluff. Das Modell wird abgelenkt oder, schlimmer noch, verwirrt. Strebe stattdessen eine hohe Präzision an. Ein paar hoch relevante Teile sind besser als eine lange Liste von schwachen Treffern.
Wenn das Modell eine schlechte Antwort gibt, weißt du dann, warum? Du tappst bei der Fehlersuche im Dunkeln, wenn du die Abfrage, die abgerufenen Dokumente und die letzte Eingabeaufforderung nicht protokollierst. Protokolliere stattdessen den gesamten RAG-Fluss. Dazu gehören die Benutzereingaben, die abgerufenen Inhalte, das, was an das Modell gesendet wurde, und die Antwort des Modells.
Die RAG ist kein Allheilmittel, aber wenn sie richtig eingesetzt wird, ist sie eine der effektivsten Methoden, um LLMs innovativer und praktischer zu machen und auf die Daten zu stützen, die für dein Unternehmen wichtig sind.
Der Schlüssel ist zu wissen, womit du arbeitest. Die Wahl des richtigen Frameworks ist ein Teil davon, aber der Erfolg hängt davon ab, wie gut du deine Daten verstehst und wie sorgfältig du deine Abfrage-Pipeline abstimmst. Garbage in, garbage out gilt immer noch, vor allem, wenn du Systeme baust, die Sprache erzeugen und nicht nur Fakten abrufen.
Sorge für die richtige Indizierung, achte auf die Verwendung deiner Token und überwache den gesamten Datenfluss. Wenn all diese Teile zusammenpassen, kann RAG deine KI-Anwendungen von beeindruckend zu wirklich hilfreich machen.
KI lernen mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
