programa
Fundamentos de la IA
10 h
El aprendizaje por refuerzo es una técnica muy utilizada para entrenar a agentes inteligentes para que tomen decisiones eficaces en su entorno. En el ámbito de los grandes modelos lingüísticos (LLM), esto suele implicar guiar el proceso de aprendizaje mediante retroalimentación humana.
Sin embargo, confiar en los humanos para que proporcionen retroalimentación puede ser caro, llevar mucho tiempo y, a veces, ser incoherente. El aprendizaje por refuerzo a partir de la retroalimentación de la IA (RLAIF) presenta una solución alternativa que aprovecha la potencia de los modelos de IA existentes.
En este artículo, desglosaremos los conceptos básicos de la RLAIF, exploraremos cómo funciona en la práctica y debatiremos sus implicaciones para el futuro del desarrollo de la IA.
Si quieres saber más sobre el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF), consulta este artículo sobre Qué es el aprendizaje por refuerzo a partir de la retroalimentación humana.
El aprendizaje por refuerzo a partir de la retroalimentación de la IA (RLAIF) es una técnica de aprendizaje automático en la que los modelos de IA proporcionan retroalimentación a otros modelos de IA durante el proceso de aprendizaje por refuerzo.
En lugar de depender únicamente de la aportación humana, RLAIF aprovecha las capacidades de los sistemas de IA existentes, como los grandes modelos lingüísticos, para evaluar las acciones y guiar el aprendizaje de otros agentes.
Esta retroalimentación de la IA puede adoptar diversas formas, como generar recompensas, clasificar las respuestas o sugerir directamente mejoras. Al automatizar el bucle de retroalimentación, RLAIF tiene el potencial de agilizar el entrenamiento, reducir los costes y mejorar el rendimiento de diversos sistemas de IA, incluidos los grandes modelos lingüísticos.
Para entender cómo se compara la RLAIF con la RLHF, empecemos por considerar esta tabla:
|
Función |
RLHF (Aprendizaje por Refuerzo a partir de la Retroalimentación Humana) |
RLAIF (Aprendizaje por Refuerzo a partir de la Retroalimentación de la IA) |
|
Fuente de información |
Anotadores humanos |
Modelos de IA existentes (por ejemplo, LLM) |
|
Escalabilidad |
Limitada por la disponibilidad y el coste de la mano de obra humana |
Altamente escalable gracias a la automatización |
|
Calidad de la información |
Alto potencial para captar las preferencias humanas matizadas |
Depende de las capacidades del modelo de IA que proporciona la información |
|
Coste |
Puede ser caro debido a la necesidad de mano de obra humana |
Potencialmente más rentable gracias a la automatización |
|
Velocidad |
Más lento debido al tiempo necesario para la anotación humana |
Más rápido gracias a la generación automática de respuestas |
|
Sesgo |
Puede estar sujeto a sesgos humanos |
Puede heredar sesgos del modelo de IA que proporciona la información |
Para comprender mejor las diferencias entre RLHF y RLAIF, consideremos también este diagrama del documento RLAIF: Escalar el aprendizaje por refuerzo a partir de la retroalimentación humana con la retroalimentación de la IA (Lee et al., 2023):
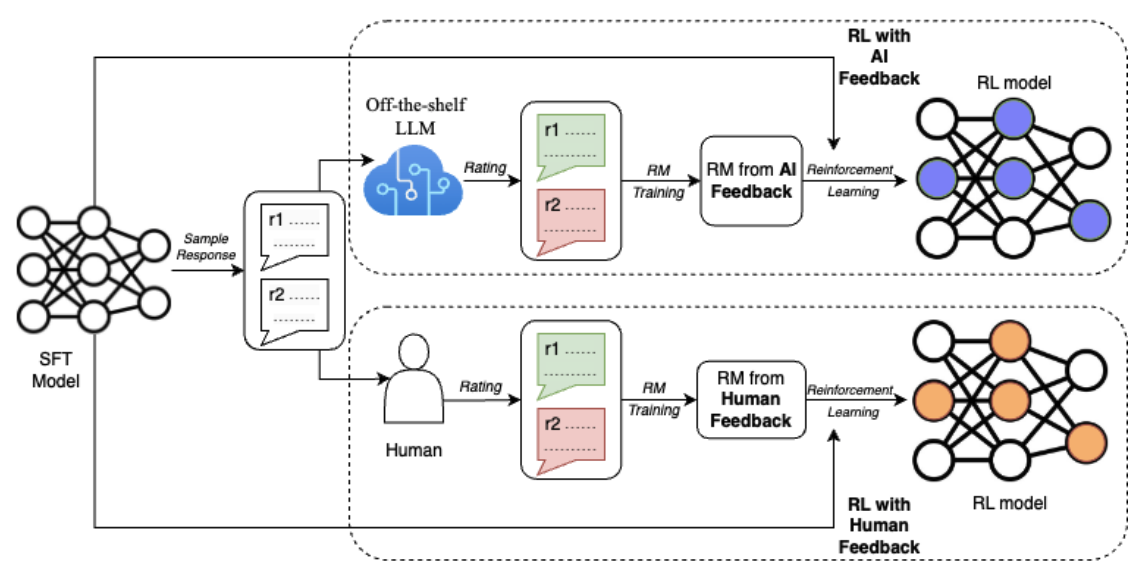
Fuente: Lee y otros, 2023
El diagrama ilustra la diferencia clave entre RLHF y RLAIF en el proceso de aprendizaje por refuerzo. Ambos enfoques parten de un modelo inicial (Modelo SFT) que genera respuestas muestrales. Sin embargo, en RLHF, los evaluadores humanos dan puntuaciones a estas respuestas, mientras que en RLAIF, un LLM estándar actúa como juez.
Estas valoraciones se utilizan después para entrenar un modelo de recompensa (MR). Por último, en el bucle de aprendizaje por refuerzo, el modelo RL recibe recompensas del MR, que está entrenado en base a la retroalimentación humana (RLHF) o a la retroalimentación de la IA (RLAIF). Este bucle de retroalimentación permite al modelo RL aprender continuamente y mejorar su rendimiento en función del tipo específico de retroalimentación que recibe.
Ahora que hemos establecido los conceptos básicos de la RLAIF y su diferenciación de la RLHF, vamos a sumergirnos en los pasos prácticos para aplicar este enfoque. El proceso RLAIF suele constar de cuatro etapas clave, cada una de las cuales desempeña un papel crucial a la hora de permitir que los modelos de IA aprendan de los comentarios generados por la IA.
En el artículo original de RLAIF (Lee et.al., 2023), se utilizó un LLM "estándar" como modelo de retroalimentación para el etiquetado de preferencias. Esto sirve como un buen punto de partida, pero en determinados escenarios, sobre todo los que implican conocimientos o terminología específicos del dominio, puede ser ventajoso afinar más el LLM sobre los datos relevantes.
Por ejemplo, si el objetivo es desarrollar un asistente de IA adaptado a los campos de las finanzas o la medicina, afinar el LLM en un corpus de textos financieros o médicos puede mejorar significativamente su comprensión de conceptos y jerga específicos del dominio.
Este paso adicional garantiza que el modelo pueda proporcionar juicios de preferencia más precisos y relevantes, mejorando en última instancia la calidad general y la fiabilidad del sistema de IA en aplicaciones especializadas.
Una vez que tenemos nuestro modelo de retroalimentación LLM -ya sea una versión estándar o una variante ajustada- podemos utilizarlo para generar etiquetas de preferencia.
Para generar la respuesta de la IA, al modelo de respuesta se le presenta el contexto y dos respuestas candidatas. A continuación, se pide al modelo que determine qué respuesta prefiere. En el documento RLAIF, la pregunta de entrada al modelo de retroalimentación sigue un formato estructurado:
Para comprender mejor esta estructura, considera la siguiente imagen:

Fuente: Lee y otros, 2023
Este enfoque estructurado garantiza que el modelo de respuesta pueda evaluar eficazmente la calidad de las respuestas y proporcionar etiquetas de preferencia precisas. Incluyendo ejemplares de pocas tomas, podemos mejorar aún más el funcionamiento del modelo, mostrando ejemplos concretos de cómo evaluar las respuestas, y haciendo que la respuesta sea más coherente y fiable.
Dada la pregunta de entrada, el modelo de retroalimentación LLM genera las probabilidades logarítmicas de los símbolos "1" y "2", que representan la preferencia del modelo por la primera o la segunda respuesta. A continuación, estas log-probabilidades se pasan por una función softmax para obtener una distribución de preferencias.
En el documento RLAIF, se experimentó con dos estilos de preámbulos: "Base" y "Detallado". Un preámbulo Base pide al modelo de retroalimentación que juzgue qué respuesta es mejor, mientras que un preámbulo Detallado proporciona instrucciones exhaustivas que suelen darse a los anotadores humanos. Para entenderlo mejor, veamos este ejemplo:

Fuente: Lee y otros, 2023
Por último, se exploraron dos consideraciones importantes para mejorar la eficacia de la metodología RLAIF:
Para comprender mejor esta técnica de CoT, considera este diagrama del documento:
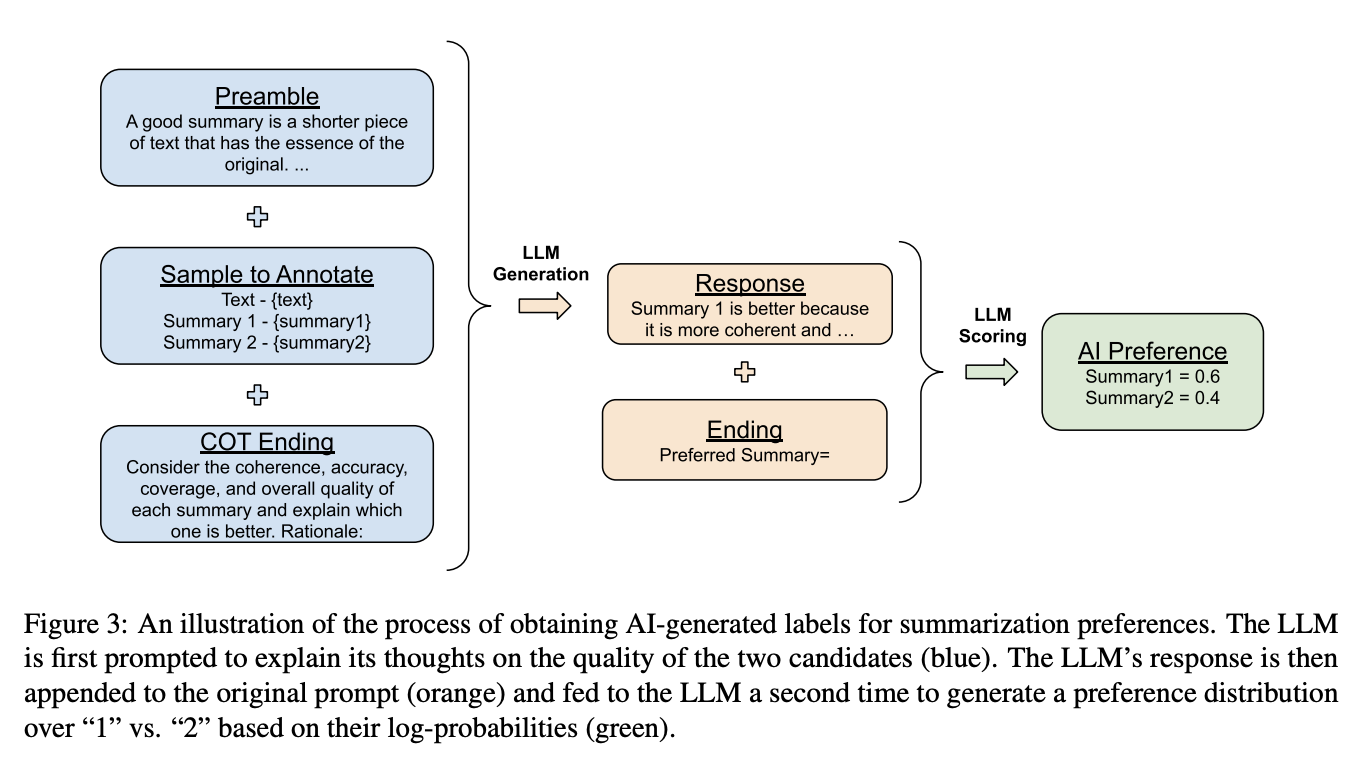
Fuente: Lee y otros, 2023
Una vez que hemos obtenido las etiquetas de preferencia del modelo de retroalimentación LLM, el siguiente paso es utilizar estas etiquetas para entrenar un modelo de preferencia.
El modelo de preferencias aprende a asignar el contexto y las respuestas de los candidatos a una señal de recompensa escalar, que sirve como sustituto de las preferencias humanas. A continuación, este modelo de preferencias entrenado se integra en el ciclo de aprendizaje por refuerzo.
El documento RLAIF explora un enfoque alternativo en el que la retroalimentación del LLM se utiliza directamente como señal de recompensa, eliminando la necesidad de un modelo de preferencias separado. Sin embargo, este método RLAIF "directo" es costoso desde el punto de vista informático, sobre todo a medida que aumenta el tamaño del etiquetador LLM.
Una vez establecido el modelo de preferencias, se puede realizar el aprendizaje por refuerzo utilizando la retroalimentación de la IA como señal de recompensa. El agente (LLM base) interactúa con el entorno, y sus resultados son evaluados por el modelo de preferencias, que asigna una recompensa en función de lo bien que la acción se alinea con las preferencias deseadas codificadas en el modelo de retroalimentación.
La RLAIF ofrece varias ventajas convincentes sobre la RLHF tradicional, lo que la convierte en una alternativa atractiva para entrenar y perfeccionar grandes modelos lingüísticos. Profundicemos en algunas de las principales ventajas que aporta la RLAIF.
Al automatizar el proceso de generación de opiniones, RLAIF elimina la necesidad de comentaristas humanos, lo que hace que la recopilación de opiniones a gran escala sea más eficaz y rentable.
Este enfoque reduce significativamente los cuellos de botella asociados a la recogida humana de información, como el tiempo, el trabajo y los gastos. A medida que los LLM se vuelven más capaces, aprovechar los sistemas de IA para supervisar a otras IA resulta cada vez más beneficioso, especialmente cuando la supervisión humana puede ser insuficiente para modelos muy avanzados.
RLAIF es muy flexible y adaptable a diversas tareas y ámbitos. Al no depender de conjuntos de datos fijos de retroalimentación humana, podemos ajustar fácilmente la constitución o los datos de entrenamiento utilizados para afinar el modelo de retroalimentación. Esto nos permite adaptar el comportamiento del LLM para que se adapte mejor a diferentes tareas y dominios, proporcionando una solución más personalizada y eficaz.
Además, los principios que guían el modelo de retroalimentación deseado se codifican explícitamente en instrucciones de lenguaje natural, formando una "constitución". Este enfoque aumenta la transparencia, ya que los criterios de evaluación están claramente articulados, a diferencia de los métodos tradicionales, en los que los principios de retroalimentación pueden estar dispersos en miles de etiquetas humanas individuales.
Los resultados experimentales del artículo original de RLAIF indican que RLAIF iguala el rendimiento de RLHF y, en algunos casos, incluso lo supera. Esto demuestra el potencial de RLAIF no sólo para agilizar el proceso de retroalimentación, sino también para mejorar el rendimiento general de los modelos que entrena.
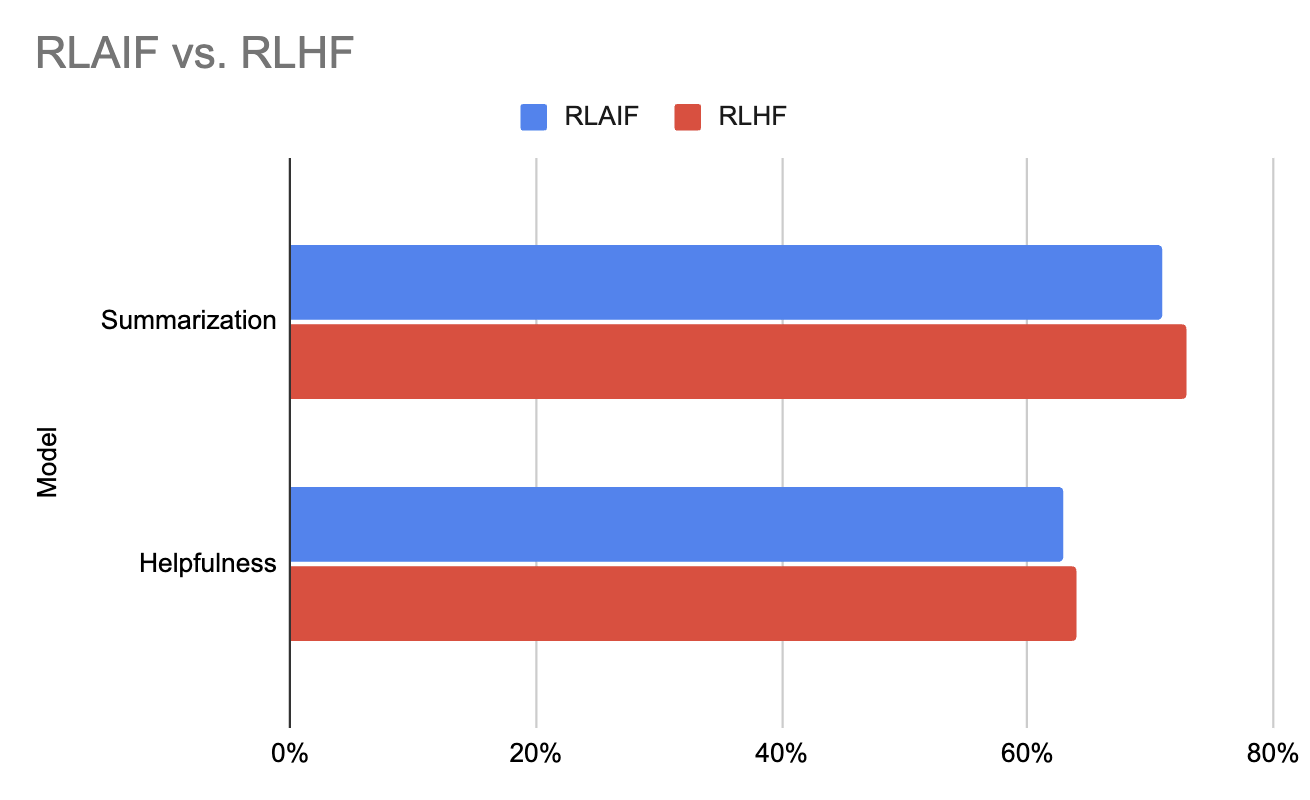
Gráfico generado con los datos de este trabajo (Lee et al., 2023)
Consideremos también este gráfico, que muestra que RLAIF produce el mayor porcentaje de diálogo inofensivo en comparación con RLHF y SFT.
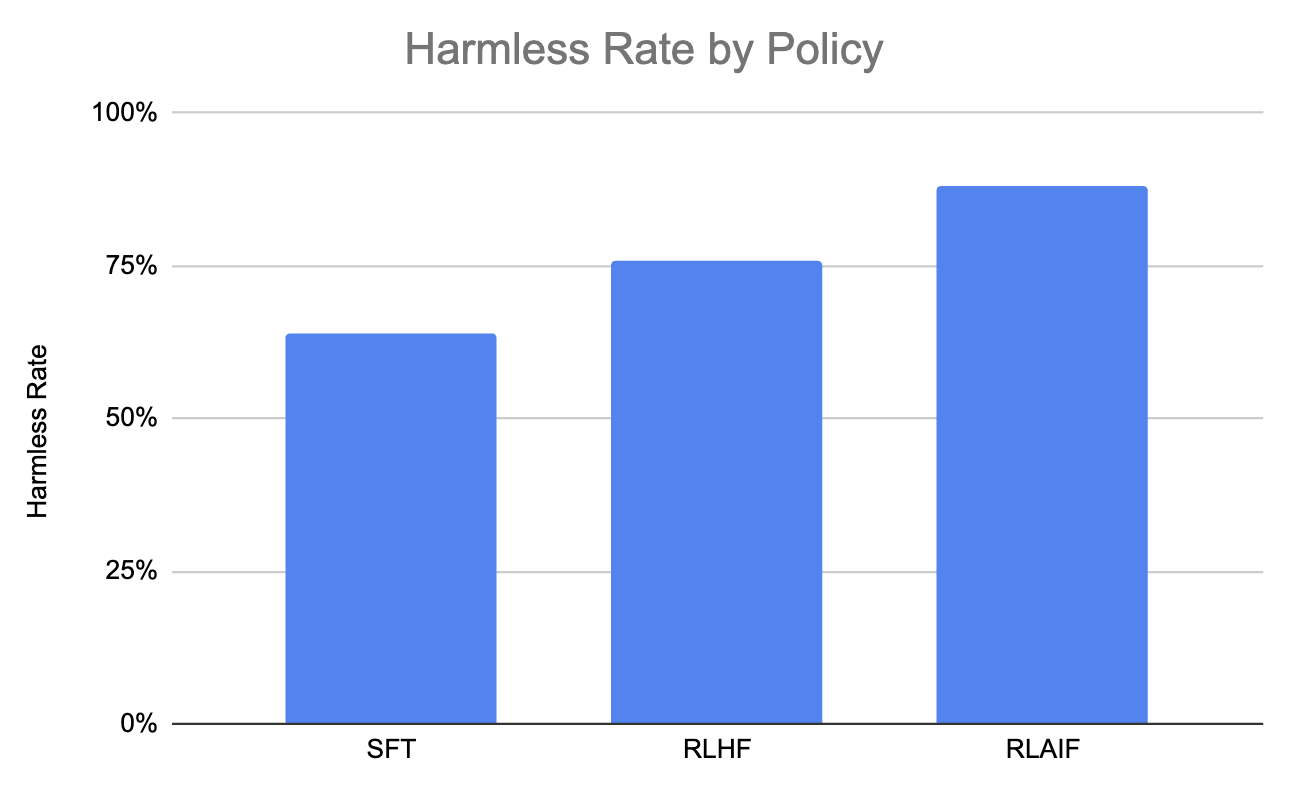
Gráfico generado con los datos de este trabajo (Lee et al., 2023)
Aunque el RLAIF ha demostrado unos resultados impresionantes, también introduce nuevos retos que deben abordarse:
Aunque la "constitución" del lenguaje natural proporciona más transparencia que las etiquetas humanas individuales, el preentrenamiento LLM sigue siendo una "caja negra". Por ello, garantizar que el modelo de retroalimentación se ajuste a los valores y preferencias humanos es un reto fundamental, ya que los desajustes o sesgos en el modelo de retroalimentación pueden provocar consecuencias no deseadas o un comportamiento subóptimo del agente.
Por lo tanto, para mitigar este riesgo, la retroalimentación de la IA podría complementar la supervisión humana en lugar de sustituirla por completo. Este doble enfoque podría ayudar a garantizar que los modelos no se alejen del comportamiento preferido por los humanos a lo largo del tiempo, manteniendo la alineación con los valores humanos.
Aunque escalar la supervisión humana para modelos muy grandes es un reto, la capacidad de los sistemas de IA actuales para supervisar de forma fiable y mantener un comportamiento robusto en asistentes de IA más capaces sigue siendo una cuestión abierta. Como tal, es esencial disponer de métricas de evaluación rigurosas para valorar la calidad y la alineación de la retroalimentación de la IA generada por el modelo de retroalimentación, garantizando su fiabilidad y eficacia.
Como cualquier modelo de aprendizaje automático, los modelos de retroalimentación pueden presentar sesgos derivados de los datos de entrenamiento o del propio proceso de aprendizaje. Las estrategias para mitigar los sesgos en la retroalimentación de la IA, como el uso de datos de entrenamiento diversos y representativos, el empleo de métodos de evaluación robustos y la incorporación de técnicas como el razonamiento en cadena, son cruciales.
Al abordar estos retos, RLAIF puede convertirse en una herramienta robusta y fiable para entrenar sistemas avanzados de IA, garantizando que estén alineados con los valores humanos y sean capaces de mantener un alto rendimiento en diversas tareas y dominios.
Podemos aplicar RLAIF a muchas tareas de procesamiento del lenguaje natural, entre ellas:
En general, el documento RLAIF (Lee et al. 2023) introduce un enfoque escalable para entrenar LLMs sin depender de etiquetas de retroalimentación humana. Aprovechando una "constitución" de principios codificados en lenguaje natural y la capacidad de autocrítica de un modelo inicial útil, los autores demuestran resultados prometedores en la dirección del comportamiento del modelo lingüístico, al tiempo que mejoran la transparencia y la flexibilidad.
Una conclusión clave es que la RLAIF muestra potencial para ampliar la supervisión a medida que los modelos sean más capaces, complementando y automatizando parcialmente la supervisión humana. También mitiga problemas como la especificación errónea de la recompensa y el comportamiento evasivo observados en anteriores enfoques de retroalimentación humana. Sin embargo, mantener una sólida alineación humana, gestionar el cambio distributivo y garantizar una supervisión fiable de los sistemas avanzados de IA siguen siendo retos pendientes.
De cara al futuro, el trabajo podría explorar la integración de demostraciones de razonamiento humano de alta calidad para enfocar y mejorar aún más los modelos RLAIF. Ampliar el enfoque para dirigir el comportamiento de los LLM en otros ejes como la personalidad y el estilo de escritura es también una dirección intrigante.
Para saber más sobre el aprendizaje por refuerzo, consulta este tutorial introductorio sobre Aprendizaje por Refuerzo: Una introducción con ejemplos de Python.
Más información sobre el aprendizaje por refuerzo y la IA
programa
Curso
Curso
blog
DataCamp Team
4 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
11 min
Tutorial
Zoumana Keita

