
Track
AI Fundamentals
10 hr
Reinforcement learning is a widely used technique for training intelligent agents to make effective decisions within their environment. In the realm of large language models (LLMs), this often involves guiding the learning process through human feedback.
However, relying on humans to provide feedback can be expensive, time-consuming, and sometimes inconsistent. Reinforcement learning from AI feedback (RLAIF) presents an alternative solution leveraging existing AI models' power.
In this article, we’ll break down the core concepts of RLAIF, explore how it works in practice, and discuss its implications for the future of AI development.
If you want to learn more about reinforcement learning from human feedback (RLHF), check out this article on What is Reinforcement Learning from Human Feedback.
Reinforcement learning from AI feedback (RLAIF) is a machine learning technique in which AI models provide feedback to other AI models during the reinforcement learning process.
Instead of relying solely on human input, RLAIF leverages the capabilities of existing AI systems, such as large language models, to evaluate actions and guide the learning of other agents.
This AI feedback can take various forms, including generating rewards, ranking responses, or directly suggesting improvements. By automating the feedback loop, RLAIF has the potential to streamline training, reduce costs, and enhance the performance of various AI systems, including large language models.
To understand how RLAIF compares to RLHF, let’s start by considering this table:
|
Feature |
RLHF (Reinforcement Learning from Human Feedback) |
RLAIF (Reinforcement Learning from AI Feedback) |
|
Feedback Source |
Human annotators |
Existing AI models (e.g., LLMs) |
|
Scalability |
Limited by the availability and cost of human labor |
Highly scalable due to automation |
|
Feedback Quality |
High potential for capturing nuanced human preferences |
Dependent on the capabilities of the AI model providing feedback |
|
Cost |
Can be expensive due to the need for human labor |
Potentially more cost-effective due to automation |
|
Speed |
Slower due to the time required for human annotation |
Faster due to automated feedback generation |
|
Bias |
Can be subject to human biases |
Can inherit biases from the AI model providing feedback |
To better understand the differences between RLHF and RLAIF, let’s also consider this diagram from the paper RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback (Lee et al., 2023):
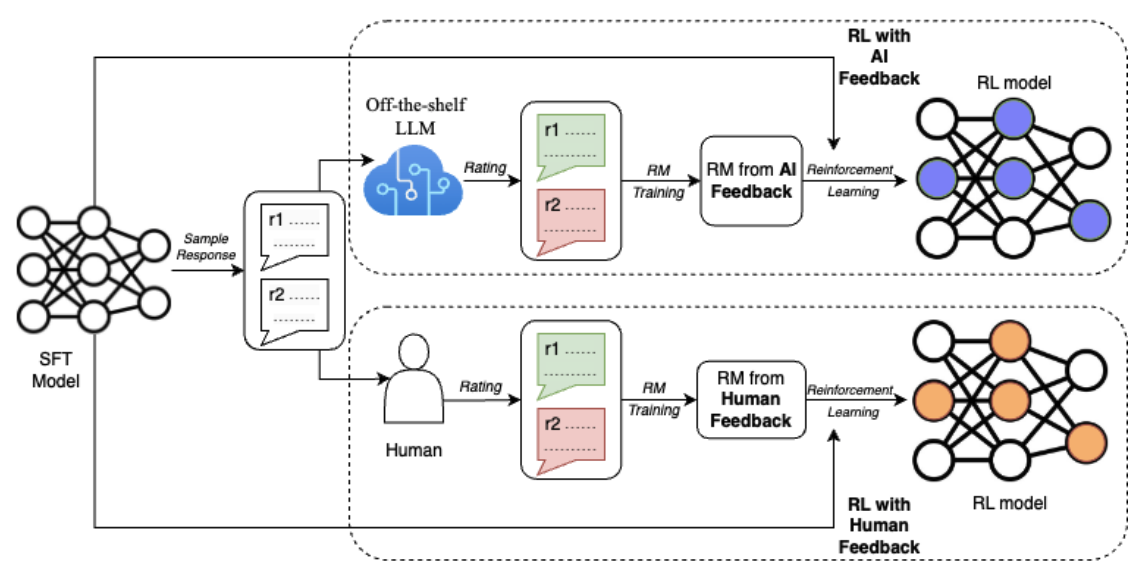
Source: Lee et al., 2023
The diagram illustrates the key difference between RLHF and RLAIF in the reinforcement learning process. Both approaches start with an initial model (SFT Model) generating sample responses. However, in RLHF, human evaluators provide ratings for these responses, while in RLAIF, an off-the-shelf LLM acts as the judge.
These ratings are then used to train a reward model (RM). Finally, in the reinforcement learning loop, the RL model receives rewards from the RM, which is trained on either human feedback (RLHF) or AI feedback (RLAIF). This feedback loop enables the RL model to continuously learn and improve its performance based on the specific type of feedback it receives.
Now that we've established the core concepts of RLAIF and its differentiation from RLHF, let's dive into the practical steps involved in implementing this approach. The RLAIF process typically consists of four key stages, each playing a crucial role in enabling AI models to learn from AI-generated feedback.
In the original RLAIF paper (Lee et.al., 2023), an "off-the-shelf" LLM was used as the feedback model for preference labeling. This serves as a good starting point, but in certain scenarios, particularly those involving domain-specific knowledge or terminology, it may be advantageous to fine-tune the LLM further on relevant data.
For example, if the goal is to develop an AI assistant tailored for the finance or medical fields, fine-tuning the LLM on a corpus of finance or medical texts can significantly enhance its comprehension of domain-specific concepts and jargon.
This additional step ensures that the model can provide more accurate and relevant preference judgments, ultimately improving the overall quality and reliability of the AI system in specialized applications.
Once we have our LLM feedback model—either an off-the-shelf version or a fine-tuned variant—we can use it to generate preference labels.
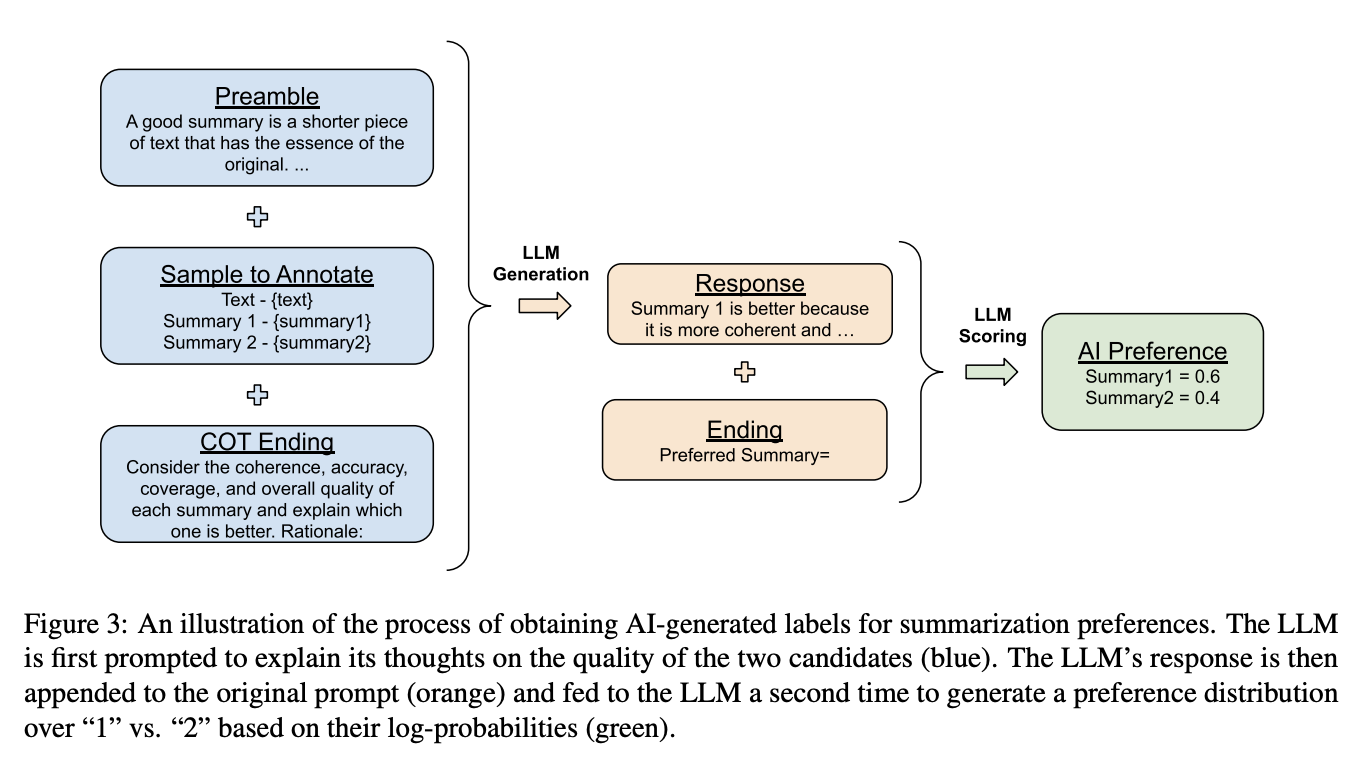
To generate AI feedback, the feedback model is presented with the context and two candidate responses. The model is then prompted to determine which response is preferred. In the RLAIF paper, the input prompt to the feedback model follows a structured format:
To better understand this structure, consider the image below:

Source: Lee et al., 2023
This structured approach ensures that the feedback model can effectively assess the quality of the responses and provide accurate preference labels. By including few-shot exemplars, we can further enhance the model's performance, showing concrete examples of how to evaluate responses, and making the feedback more consistent and reliable.
Given the input prompt, the LLM feedback model generates the log-probabilities for the tokens "1" and "2"—representing the model's preference for either the first or second response. These log-probabilities are then passed through a softmax function to obtain a preference distribution.
In the RLAIF paper, two styles of preambles were experimented with: “Base” and “Detailed”. A Base preamble asks the feedback model to judge which response is better, while a Detailed preamble provides comprehensive instructions typically given to human annotators. To better understand this, let’s consider this example:

Source: Lee et al., 2023
Lastly, two important considerations were explored to enhance the effectiveness of the RLAIF methodology:
To better understand this CoT technique, consider this diagram from the paper:
Source: Lee et al., 2023
Once we’ve obtained preference labels from the LLM feedback model, the next step is using these labels to train a preference model.
The preference model learns to map the context and candidate responses to a scalar reward signal, which serves as a proxy for human preferences. This trained preference model is then integrated into the reinforcement learning cycle.
The RLAIF paper explores an alternative approach where the LLM feedback is directly used as the reward signal, eliminating the need for a separate preference model. However, this "direct" RLAIF method is computationally expensive, particularly as the size of the LLM labeler increases.
With the preference model in place, reinforcement learning can be performed using the AI feedback as the reward signal. The agent (base LLM) interacts with the environment, and its outputs are evaluated by the preference model, which assigns a reward based on how well the action aligns with the desired preferences encoded in the feedback model.
RLAIF offers several compelling advantages over traditional RLHF, making it an attractive alternative for training and refining large language models. Let's delve into some of the key benefits that RLAIF brings to the table.
By automating the feedback generation process, RLAIF eliminates the need for human annotators, making collecting feedback at scale more efficient and cost-effective.
This approach significantly reduces the bottlenecks associated with human feedback collection, such as time, labor, and expense. As LLMs become more capable, leveraging AI systems to supervise other AIs becomes increasingly beneficial, especially when human supervision may be insufficient for highly advanced models.
RLAIF is highly flexible and adaptable to various tasks and domains. By not relying on fixed human feedback datasets, we can easily adjust the constitution or training data used to fine-tune the feedback model. This allows us to tailor the LLM behavior to best suit different tasks and domains, providing a more customized and effective solution.
Moreover, the principles guiding the desired feedback model are explicitly encoded in natural language instructions, forming a "constitution." This approach enhances transparency, as the evaluation criteria are clearly articulated, unlike in traditional methods, where feedback principles may be scattered across thousands of individual human labels.
The experimental results from the original RLAIF paper indicate that RLAIF matches the performance of RLHF and, in some cases, even surpasses it. This demonstrates the potential for RLAIF to not only streamline the feedback process but also enhance the overall performance of the models it trains.
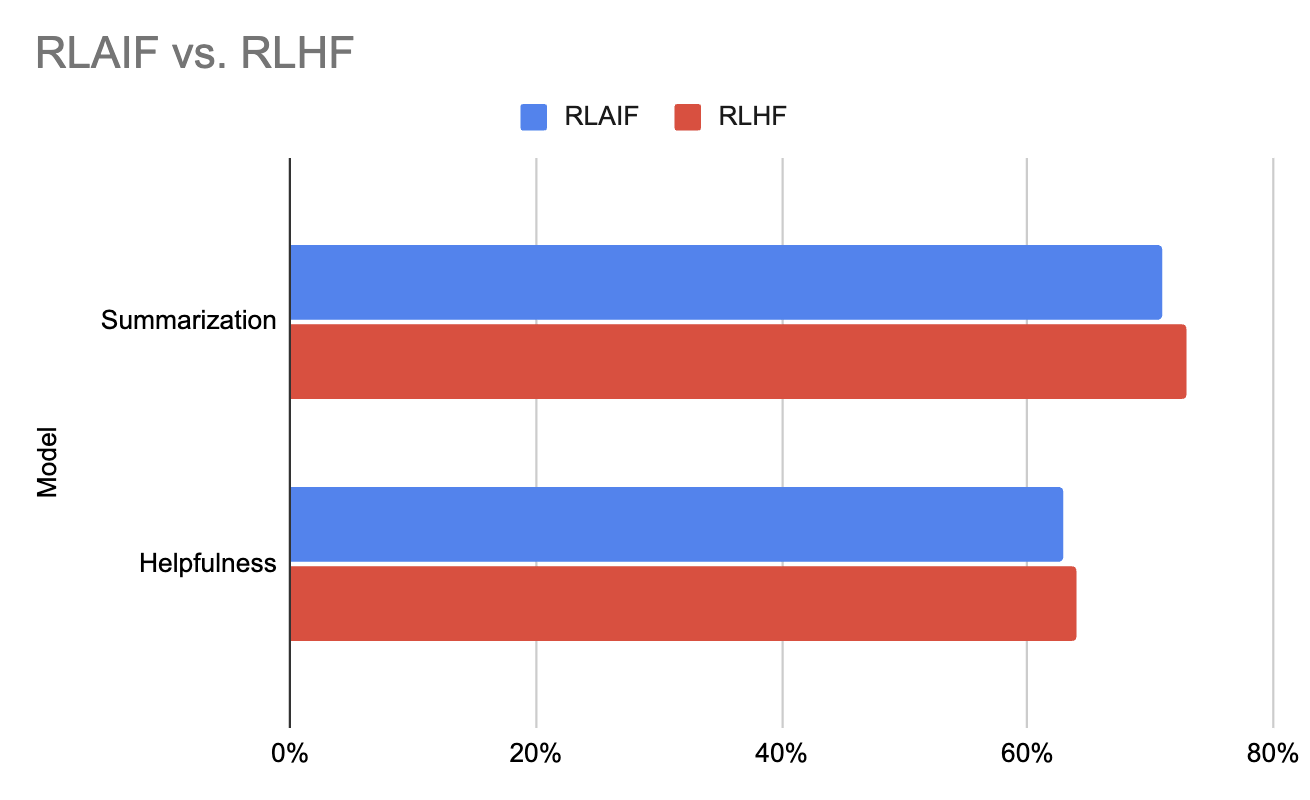
Graph generated using the data in this paper (Lee et al., 2023)
Let's also consider this graph, which shows that RLAIF produces the highest percentage of harmless dialogue compared to RLHF and SFT.
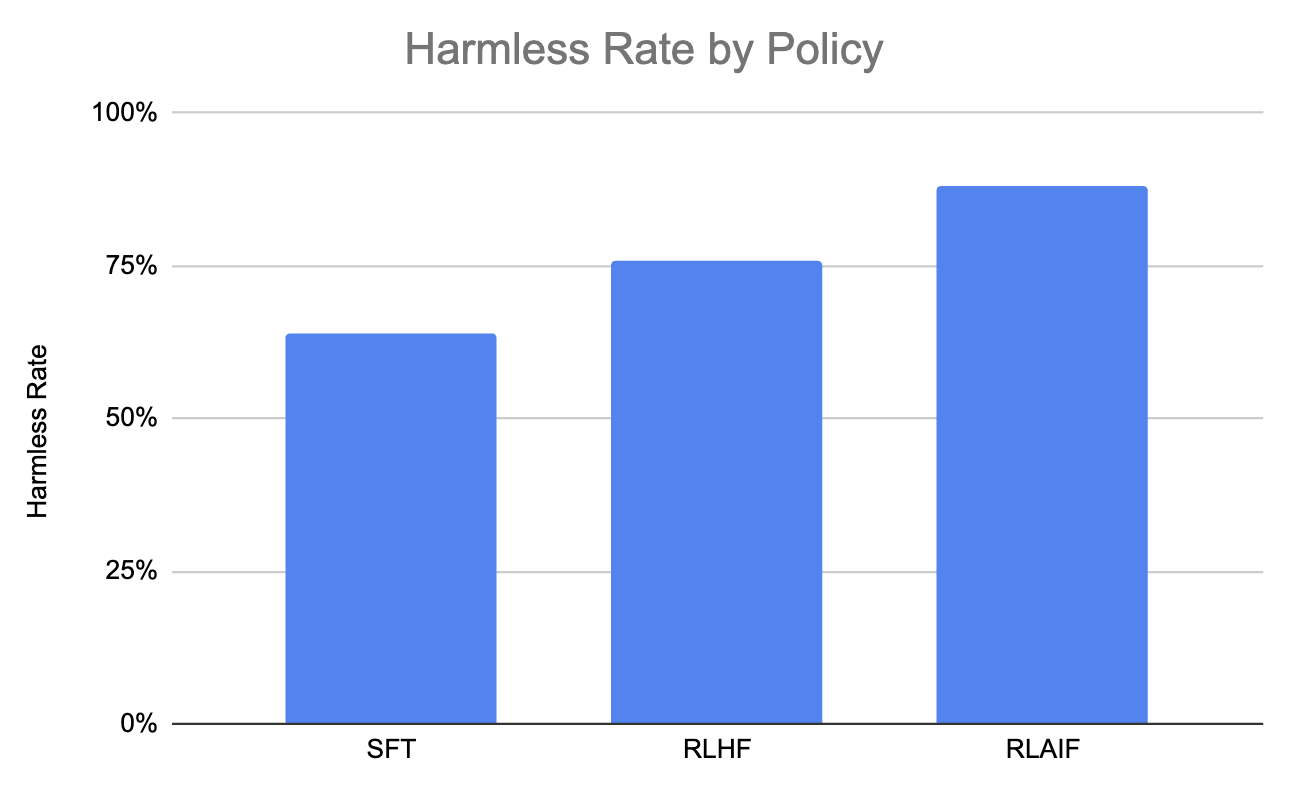
Graph generated using the data in this paper (Lee et al., 2023)
While RLAIF demonstrated impressive results, it also introduces new challenges that must be addressed:
Although the natural language "constitution" provides more transparency than individual human labels, LLM pretraining remains a “black box.” As such, ensuring that the feedback model aligns with human values and preferences is a critical challenge as misalignments or biases in the feedback model can lead to unintended consequences or suboptimal behavior from the agent.
Therefore, to mitigate this risk, AI feedback could complement human oversight rather than replace it entirely. This dual approach could help ensure models don’t drift away from human-preferred behavior over time, maintaining alignment with human values.
While scaling human supervision for very large models is challenging, the ability of current AI systems to reliably supervise and maintain robust behavior in more capable AI assistants is still an open question. As such, rigorous evaluation metrics are essential to assess the quality and alignment of AI feedback generated by the feedback model, ensuring its reliability and effectiveness.
Like any machine learning model, feedback models can exhibit biases stemming from the training data or the learning process itself. Strategies for mitigating biases in AI feedback, such as using diverse and representative training data, employing robust evaluation methods, and incorporating techniques like chain-of-thought reasoning, are crucial.
By addressing these challenges, RLAIF can be developed into a robust and reliable tool for training advanced AI systems, ensuring they are aligned with human values and capable of maintaining high performance across various tasks and domains.
We can apply RLAIF to many natural language processing tasks, including:
Overall, the RLAIF paper (Lee et al. 2023) introduces a scalable approach for training LLMs without relying on human feedback labels. By leveraging a "constitution" of principles encoded in natural language and an initial helpful model's self-critiquing abilities, the authors demonstrate promising results in steering language model behavior while improving transparency and flexibility.
A key takeaway is that RLAIF shows potential for scaling supervision as models become more capable, complementing and partially automating human oversight. It also mitigates issues like reward misspecification and evasive behavior seen in prior human feedback approaches. However, maintaining robust human alignment, managing distributional shift, and ensuring reliable supervision for advanced AI systems remain open challenges.
Looking ahead, future work could explore integrating high-quality human reasoning demonstrations to further focus and improve RLAIF models. Extending the approach to steer LLM behavior across other axes like personality and writing style is also an intriguing direction.
To learn more about reinforcement learning, check out this introductory tutorial on Reinforcement Learning: An Introduction With Python Examples.
Learn more about reinforcement learning and AI!
Track
Course
Course
blog
Javier Canales Luna
8 min
blog
Abid Ali Awan
5 min
blog
Abid Ali Awan
9 min
Tutorial
Bex Tuychiev
Tutorial
Iván Palomares Carrascosa
Tutorial
Zoumana Keita


