Programa
Fundamentos da IA
10 h
O aprendizado por reforço é uma técnica amplamente usada para treinar agentes inteligentes a tomar decisões eficazes em seu ambiente. No âmbito dos modelos de linguagem de grande porte (LLMs), isso geralmente envolve orientar o processo de aprendizagem por meio de feedback humano.
No entanto, depender de humanos para fornecer feedback pode ser caro, demorado e, às vezes, inconsistente. O aprendizado por reforço a partir do feedback da IA (RLAIF) apresenta uma solução alternativa que aproveita o poder dos modelos de IA existentes.
Neste artigo, detalharemos os principais conceitos do RLAIF, exploraremos como ele funciona na prática e discutiremos suas implicações para o futuro do desenvolvimento de IA.
Se você quiser saber mais sobre o aprendizado por reforço com feedback humano (RLHF), confira este artigo sobre O que é aprendizado por reforço com feedback humano.
O aprendizado por reforço com feedback de IA (RLAIF) é uma técnica de machine learning na qual os modelos de IA fornecem feedback a outros modelos de IA durante o processo de aprendizado por reforço.
Em vez de depender exclusivamente de informações humanas, o RLAIF aproveita os recursos dos sistemas de IA existentes, como grandes modelos de linguagem, para avaliar ações e orientar o aprendizado de outros agentes.
Esse feedback de IA pode assumir várias formas, incluindo a geração de recompensas, a classificação de respostas ou a sugestão direta de melhorias. Ao automatizar o ciclo de feedback, o RLAIF tem o potencial de simplificar o treinamento, reduzir os custos e aprimorar o desempenho de vários sistemas de IA, incluindo modelos de linguagem grandes.
Para que você entenda como o RLAIF se compara ao RLHF, vamos começar considerando esta tabela:
|
Recurso |
RLHF (Reinforcement Learning from Human Feedback) |
RLAIF (Reinforcement Learning from AI Feedback) |
|
Fonte de feedback |
Anotadores humanos |
Modelos de IA existentes (por exemplo, LLMs) |
|
Escalabilidade |
Limitado pela disponibilidade e pelo custo da mão de obra humana |
Altamente escalável devido à automação |
|
Qualidade do feedback |
Alto potencial para capturar preferências humanas diferenciadas |
Depende dos recursos do modelo de IA que fornece feedback |
|
Custo |
Pode ser caro devido à necessidade de mão de obra humana |
Potencialmente mais econômico devido à automação |
|
Velocidade |
Mais lento devido ao tempo necessário para a anotação humana |
Mais rápido devido à geração automatizada de feedback |
|
Bias |
Pode estar sujeito a preconceitos humanos |
Pode herdar vieses do modelo de IA que fornece feedback |
Para que você entenda melhor as diferenças entre RLHF e RLAIF, vamos considerar também este diagrama do documento RLAIF: Dimensionamento do aprendizado por reforço a partir de feedback humano com feedback de IA (Lee et al., 2023):
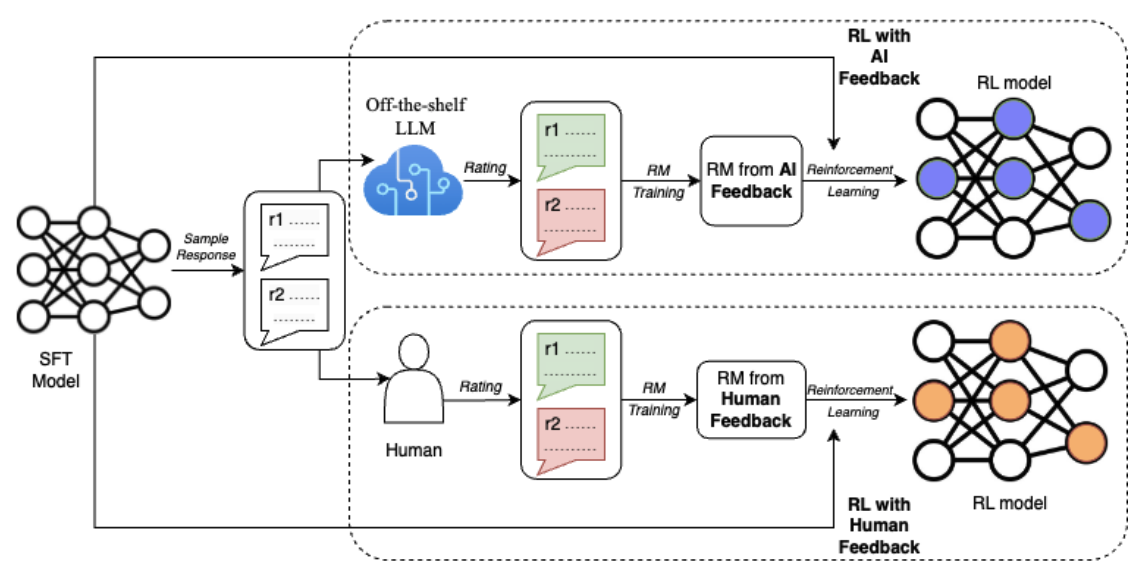
Fonte: Lee et al., 2023
O diagrama ilustra a principal diferença entre RLHF e RLAIF no processo de aprendizado por reforço. Ambas as abordagens começam com um modelo inicial (modelo SFT) que gera respostas de amostra. No entanto, no RLHF, os avaliadores humanos fornecem classificações para essas respostas, enquanto no RLAIF, um LLM pronto para uso atua como juiz.
Essas classificações são então usadas para treinar um modelo de recompensa (RM). Por fim, no loop de aprendizagem por reforço, o modelo de RL recebe recompensas do RM, que é treinado com base em feedback humano (RLHF) ou feedback de IA (RLAIF). Esse loop de feedback permite que o modelo de RL aprenda e melhore continuamente seu desempenho com base no tipo específico de feedback que recebe.
Agora que já estabelecemos os conceitos centrais do RLAIF e sua diferenciação do RLHF, vamos nos aprofundar nas etapas práticas envolvidas na implementação dessa abordagem. O processo RLAIF geralmente consiste em quatro estágios principais, cada um deles desempenhando uma função crucial para permitir que os modelos de IA aprendam com o feedback gerado pela IA.
No artigo original do RLAIF (Lee et.al., 2023), um LLM "pronto para uso" foi usado como modelo de feedback para rotulagem de preferências. Isso serve como um bom ponto de partida, mas em determinados cenários, especialmente aqueles que envolvem conhecimento ou terminologia específicos do domínio, pode ser vantajoso ajustar o LLM ainda mais com base em dados relevantes.
Por exemplo, se o objetivo for desenvolver um assistente de IA adaptado para as áreas financeira ou médica, o ajuste fino do LLM em um corpus de textos financeiros ou médicos pode melhorar significativamente a compreensão de conceitos e jargões específicos do domínio.
Essa etapa adicional garante que o modelo possa fornecer julgamentos de preferência mais precisos e relevantes, melhorando, em última análise, a qualidade geral e a confiabilidade do sistema de IA em aplicativos especializados.
Quando tivermos nosso modelo de feedback LLM - seja uma versão pronta para uso ou uma variante ajustada -, poderemos usá-lo para gerar rótulos de preferência.
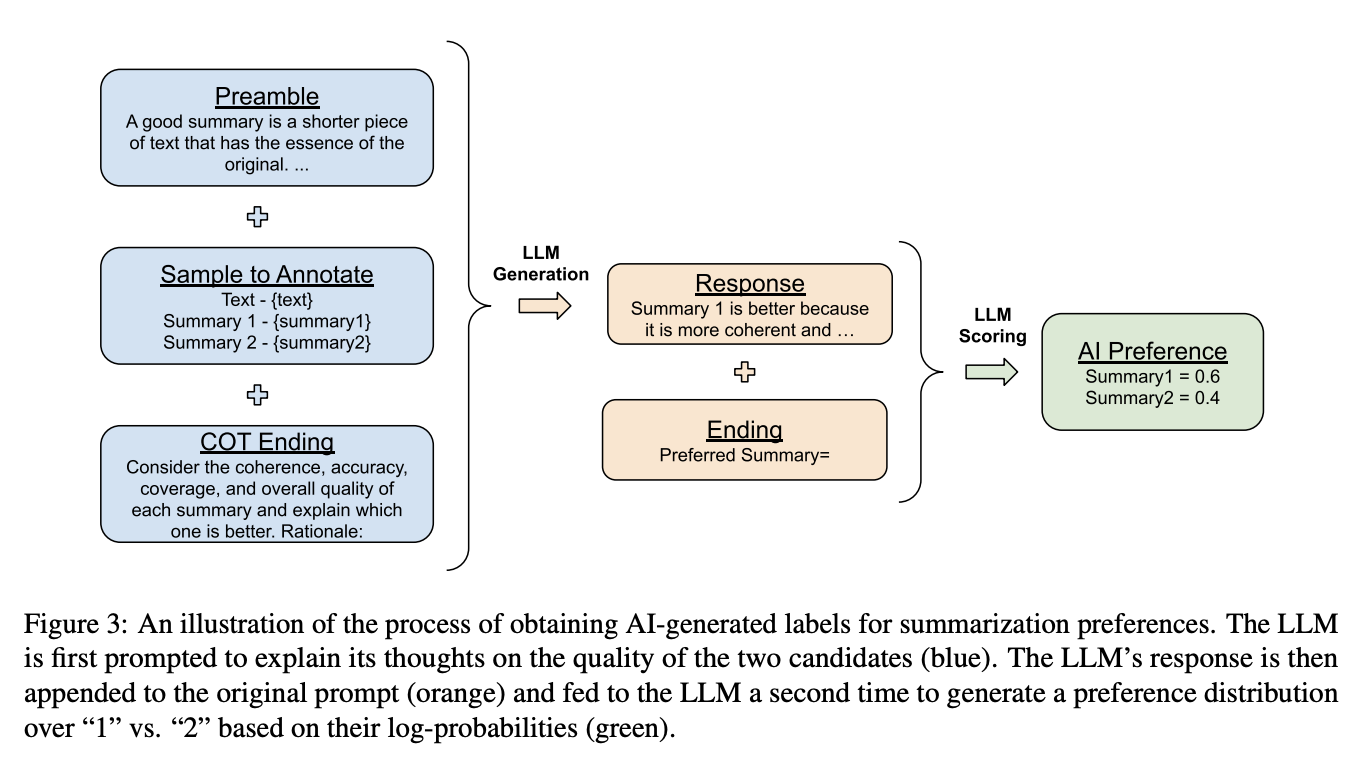
Para gerar feedback de IA, o modelo de feedback é apresentado com o contexto e duas respostas candidatas. O modelo é então solicitado a determinar qual resposta é a preferida. No documento RLAIF, o prompt de entrada para o modelo de feedback segue um formato estruturado:
Para entender melhor essa estrutura, considere a imagem abaixo:

Fonte: Lee et al., 2023
Essa abordagem estruturada garante que o modelo de feedback possa avaliar efetivamente a qualidade das respostas e fornecer rótulos de preferência precisos. Ao incluir exemplos de poucos disparos, podemos aprimorar ainda mais o desempenho do modelo, mostrando exemplos concretos de como avaliar as respostas e tornando o feedback mais consistente e confiável.
Dado o prompt de entrada, o modelo de feedback LLM gera as probabilidades de log para os tokens "1" e "2", representando a preferência do modelo pela primeira ou segunda resposta. Essas probabilidades logarítmicas são então passadas por uma função softmax para obter uma distribuição de preferências.
No artigo do RLAIF, foram experimentados dois estilos de preâmbulos: "Base" e "Detalhado". Um preâmbulo básico solicita que o modelo de feedback julgue qual resposta é melhor, enquanto um preâmbulo detalhado fornece instruções abrangentes, normalmente dadas a anotadores humanos. Para entender melhor isso, vamos considerar este exemplo:

Fonte: Lee et al., 2023
Por fim, foram exploradas duas considerações importantes para aumentar a eficácia da metodologia RLAIF:
Para entender melhor essa técnica de CoT, considere este diagrama do documento:
Fonte: Lee et al., 2023
Depois de obter rótulos de preferência do modelo de feedback do LLM, a próxima etapa é usar esses rótulos para treinar um modelo de preferência.
O modelo de preferências aprende a mapear o contexto e as respostas dos candidatos a um sinal de recompensa escalar, que serve como um substituto para as preferências humanas. Esse modelo de preferência treinado é então integrado ao ciclo de aprendizagem por reforço.
O artigo do RLAIF explora uma abordagem alternativa em que o feedback do LLM é usado diretamente como sinal de recompensa, eliminando a necessidade de um modelo de preferência separado. No entanto, esse método RLAIF "direto" é computacionalmente caro, principalmente quando o tamanho do rotulador LLM aumenta.
Com o modelo de preferência implementado, o aprendizado por reforço pode ser realizado usando o feedback da IA como sinal de recompensa. O agente (LLM básico) interage com o ambiente, e seus resultados são avaliados pelo modelo de preferência, que atribui uma recompensa com base no grau de alinhamento da ação com as preferências desejadas codificadas no modelo de feedback.
O RLAIF oferece várias vantagens atraentes em relação ao RLHF tradicional, o que o torna uma alternativa atraente para o treinamento e o refinamento de grandes modelos de linguagem. Vamos nos aprofundar em alguns dos principais benefícios que a RLAIF traz para você.
Ao automatizar o processo de geração de feedback, o RLAIF elimina a necessidade de anotadores humanos, tornando a coleta de feedback em escala mais eficiente e econômica.
Essa abordagem reduz significativamente os gargalos associados à coleta de feedback humano, como tempo, mão de obra e despesas. À medida que os LLMs se tornam mais capazes, aproveitar os sistemas de IA para supervisionar outras IAs torna-se cada vez mais vantajoso, especialmente quando a supervisão humana pode ser insuficiente para modelos altamente avançados.
O RLAIF é altamente flexível e adaptável a várias tarefas e domínios. Por não depender de conjuntos de dados fixos de feedback humano, podemos ajustar facilmente a constituição ou os dados de treinamento usados para ajustar o modelo de feedback. Isso nos permite adaptar o comportamento do LLM para melhor atender a diferentes tarefas e domínios, fornecendo uma solução mais personalizada e eficaz.
Além disso, os princípios que orientam o modelo de feedback desejado são explicitamente codificados em instruções de linguagem natural, formando uma "constituição". Essa abordagem aumenta a transparência, pois os critérios de avaliação são claramente articulados, ao contrário dos métodos tradicionais, em que os princípios de feedback podem estar espalhados por milhares de rótulos humanos individuais.
Os resultados experimentais do artigo original do RLAIF indicam que o RLAIF corresponde ao desempenho do RLHF e, em alguns casos, até o supera. Isso demonstra o potencial do RLAIF não apenas para simplificar o processo de feedback, mas também para aprimorar o desempenho geral dos modelos que ele treina.
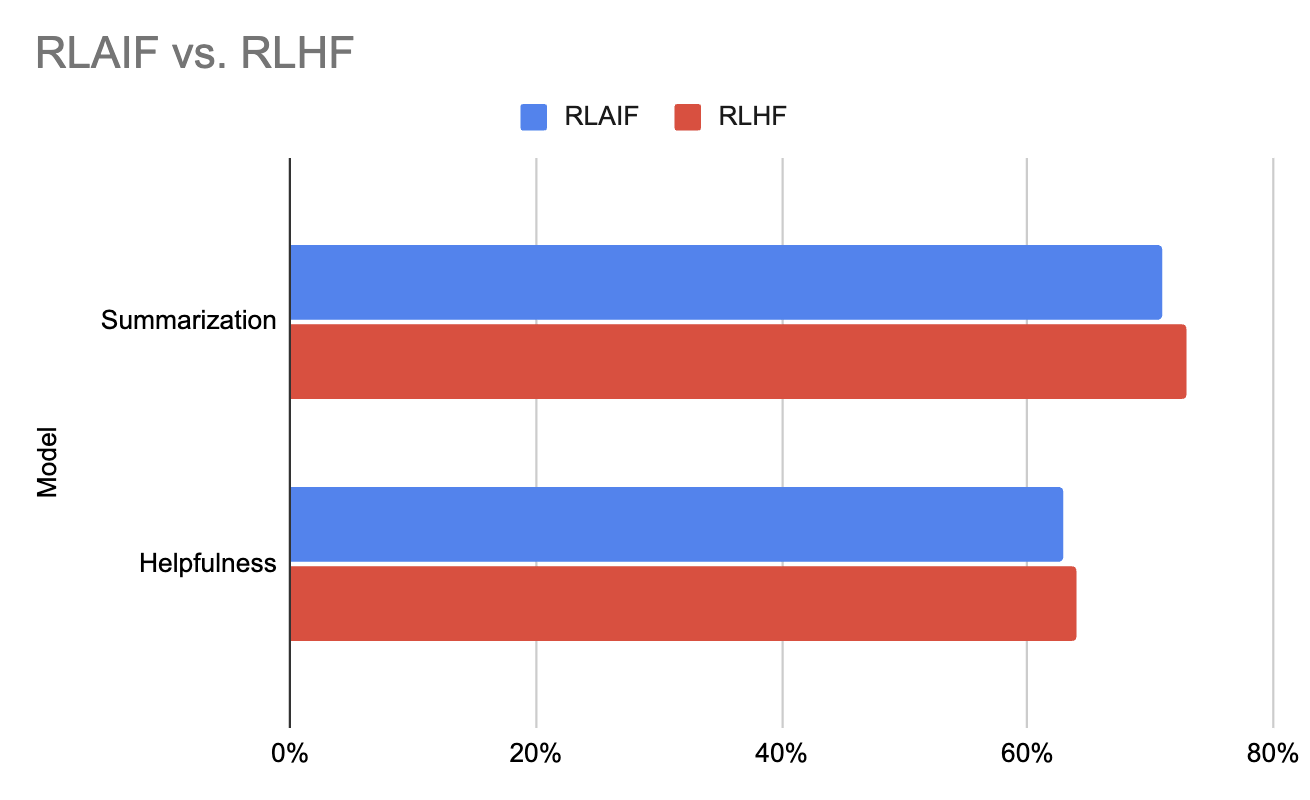
Gráfico gerado usando os dados deste documento (Lee et al., 2023)
Vamos considerar também este gráfico, que mostra que o RLAIF produz a maior porcentagem de diálogos inofensivos em comparação com o RLHF e o SFT.
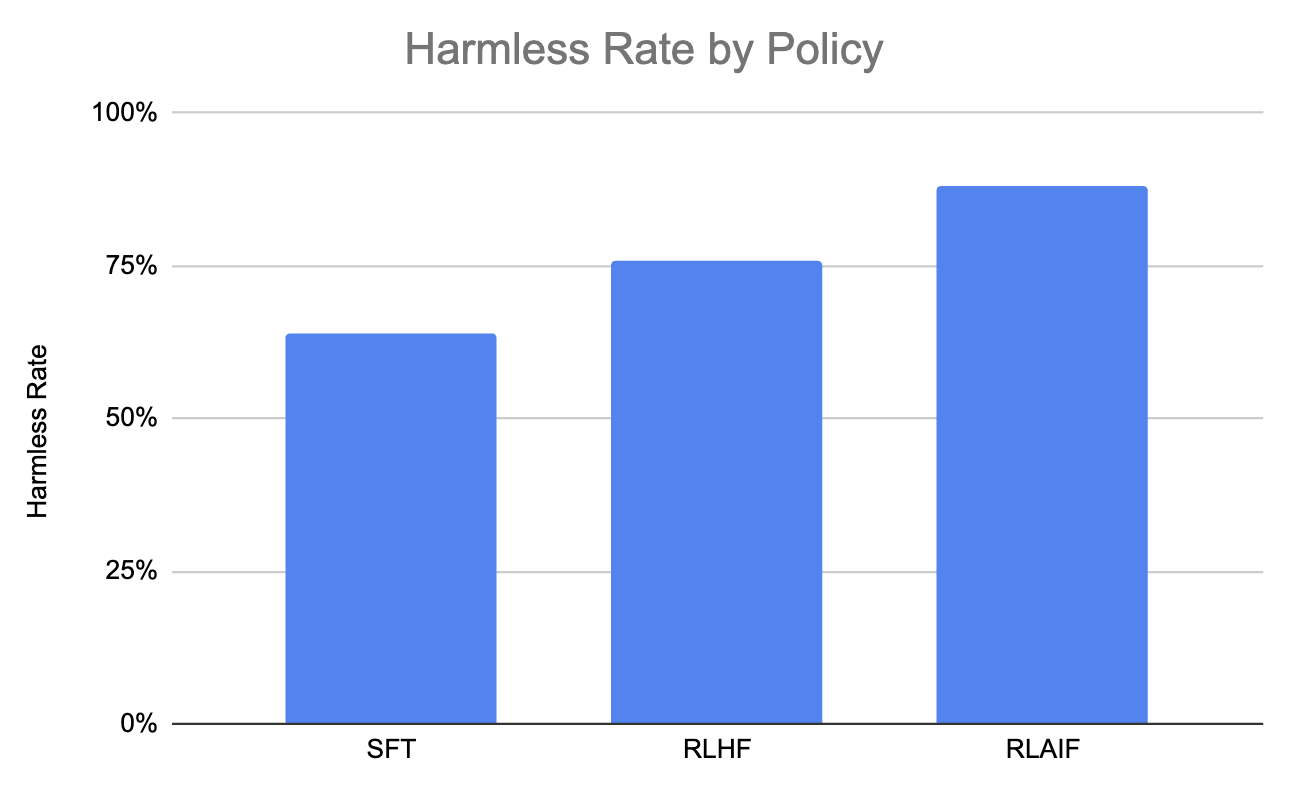
Gráfico gerado usando os dados deste documento (Lee et al., 2023)
Embora o RLAIF tenha demonstrado resultados impressionantes, ele também apresenta novos desafios que precisam ser enfrentados:
Embora a "constituição" da linguagem natural ofereça mais transparência do que rótulos humanos individuais, o pré-treinamento do LLM continua sendo uma "caixa preta". Dessa forma, garantir que o modelo de feedback esteja alinhado com os valores e as preferências humanas é um desafio fundamental, pois desalinhamentos ou vieses no modelo de feedback podem levar a consequências não intencionais ou a um comportamento abaixo do ideal por parte do agente.
Portanto, para atenuar esse risco, o feedback da IA poderia complementar a supervisão humana em vez de substituí-la totalmente. Essa abordagem dupla pode ajudar a garantir que os modelos não se afastem do comportamento preferido pelos humanos ao longo do tempo, mantendo o alinhamento com os valores humanos.
Embora o dimensionamento da supervisão humana para modelos muito grandes seja um desafio, a capacidade dos sistemas de IA atuais de supervisionar e manter de forma confiável um comportamento robusto em assistentes de IA mais capazes ainda é uma questão em aberto. Dessa forma, métricas de avaliação rigorosas são essenciais para avaliar a qualidade e o alinhamento do feedback de IA gerado pelo modelo de feedback, garantindo sua confiabilidade e eficácia.
Como qualquer modelo de machine learning, os modelos de feedback podem apresentar vieses decorrentes dos dados de treinamento ou do próprio processo de aprendizagem. As estratégias para atenuar os vieses no feedback de IA, como o uso de dados de treinamento diversos e representativos, o emprego de métodos de avaliação robustos e a incorporação de técnicas como o raciocínio em cadeia, são fundamentais.
Ao enfrentar esses desafios, o RLAIF pode ser desenvolvido como uma ferramenta robusta e confiável para treinar sistemas avançados de IA, garantindo que eles estejam alinhados com os valores humanos e sejam capazes de manter um alto desempenho em várias tarefas e domínios.
Podemos aplicar o RLAIF a muitas tarefas de processamento de linguagem natural, inclusive:
Em geral, o documento RLAIF (Lee et al. 2023) apresenta uma abordagem escalonável para treinar LLMs sem depender de rótulos de feedback humano. Ao aproveitar uma "constituição" de princípios codificados em linguagem natural e as habilidades de autocrítica de um modelo útil inicial, os autores demonstram resultados promissores na orientação do comportamento do modelo de linguagem, melhorando a transparência e a flexibilidade.
Uma conclusão importante é que a RLAIF mostra potencial para ampliar a supervisão à medida que os modelos se tornam mais capazes, complementando e automatizando parcialmente a supervisão humana. Ele também atenua problemas como a especificação incorreta da recompensa e o comportamento evasivo observados em abordagens anteriores de feedback humano. No entanto, manter um alinhamento humano robusto, gerenciar a mudança distributiva e garantir uma supervisão confiável para sistemas avançados de IA continuam sendo desafios em aberto.
No futuro, trabalhos futuros poderão explorar a integração de demonstrações de raciocínio humano de alta qualidade para focar e aprimorar ainda mais os modelos RLAIF. Estender a abordagem para orientar o comportamento do LLM em outros eixos, como personalidade e estilo de redação, também é uma direção intrigante.
Para saber mais sobre o aprendizado por reforço, confira este tutorial introdutório em Reinforcement Learning: Uma introdução com exemplos em Python.
Saiba mais sobre aprendizado por reforço e IA!
Programa
Curso
Curso