programa
Ingeniero de Datos Asociado en SQL
30 h
Hace un par de años, durante mi primera semana en un nuevo puesto de ingeniería de software, me pidieron que investigara bases de datos de series temporales (TSDB) para sustituir a nuestra solución Postgres.
No sabía absolutamente nada del tema y tenía muchas preguntas. ¿Qué es una base de datos de series temporales? ¿Cómo funciona? ¿En qué se diferencia de una base de datos tradicional? ¿Por qué debemos utilizar uno? ¿Necesito habilidades específicas para ello?
Desde entonces, he aprendido mucho sobre las TSDB y he aplicado estos conocimientos en diversas empresas para resolver una amplia gama de problemas.
En este artículo, resumiré lo que he aprendido en los últimos años para darte una buena idea de lo que son las TSDB, cómo funcionan y para qué casos de uso son las mejores. También te guiaré por algunas de las TSDB que existen actualmente en el mercado y te daré consejos para que puedas elegir la que mejor se adapte a tus necesidades.
Imagina un termostato inteligente vendido por la empresa X que registra las lecturas de temperatura cada 30 segundos. En un solo día, este dispositivo genera miles de puntos de datos. Ahora, multiplícalo por cientos o miles de dispositivos en toda una ciudad, y el volumen de datos con fecha y hora recogidos por la empresa X se vuelve asombroso.
Para almacenar estos datos de forma eficiente y analizar tendencias (como cambios de temperatura a lo largo del tiempo o picos repentinos), la empresa X necesita una base de datos que pueda manejar velocidades de escritura masivas y realizar consultas basadas en el tiempo de forma eficiente.
Las bases de datos tradicionales suelen tener problemas con este tipo de carga de trabajo, porque no están diseñadas para gestionar escrituras de datos de alta frecuencia ni para consultar datos de forma eficiente en intervalos de tiempo específicos. Ahí es donde entran en juego las bases de datos de series temporales.
Las bases de datos de series temporales son bases de datos especializadas diseñadas para gestionar datos organizados e indexados por tiempo. A diferencia de las bases de datos tradicionales, que están optimizadas para el almacenamiento de datos de uso general, las TSDB se centran en el almacenamiento, la consulta y el análisis eficientes de secuencias de puntos de datos con marca temporal.
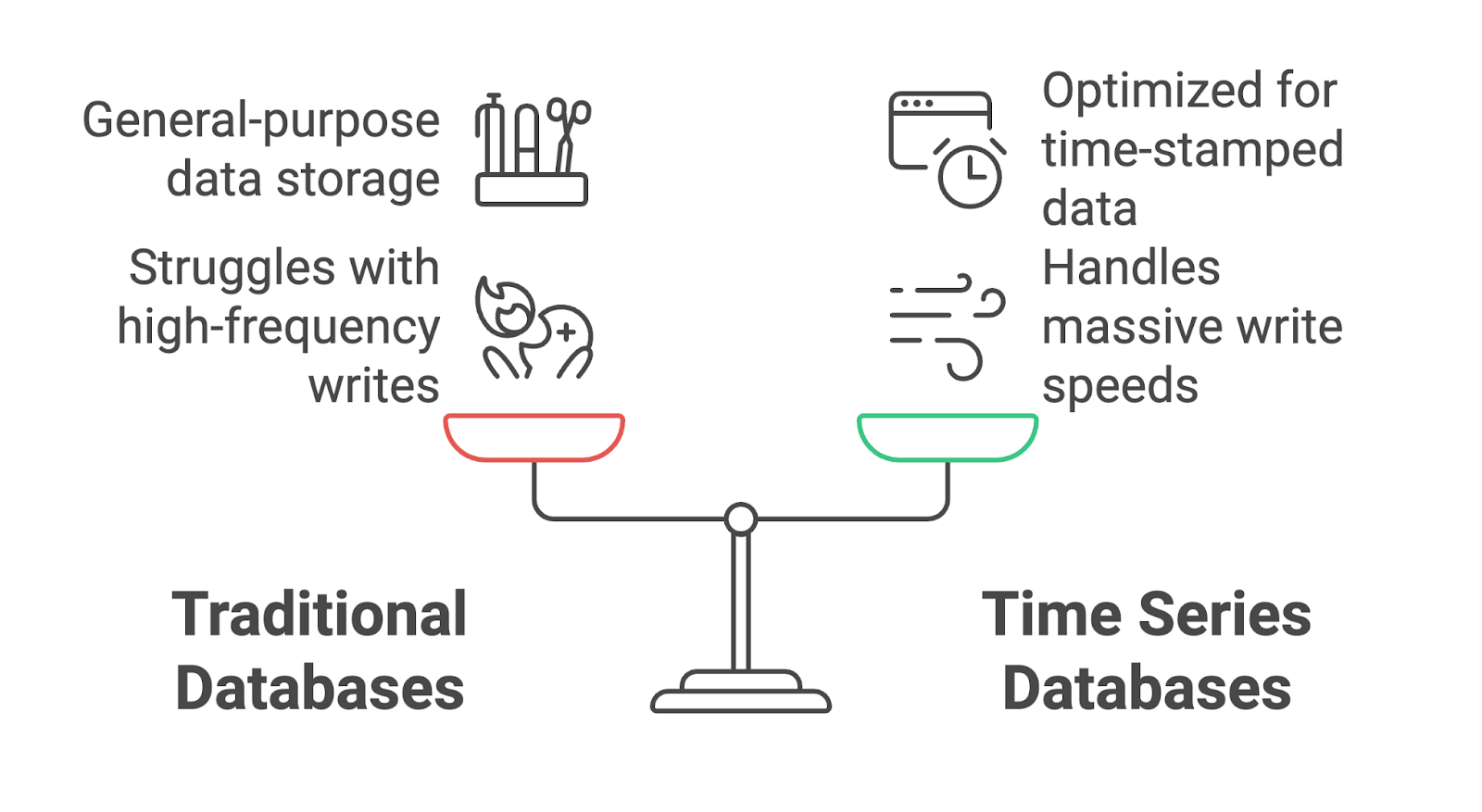
Las TSDB son especialmente adecuadas para aplicaciones que manejan flujos de datos continuos, como IoT, monitorización DevOps y análisis financiero.
Hay algunas cosas que las TSDB hacen de forma diferente a las bases de datos tradicionales.
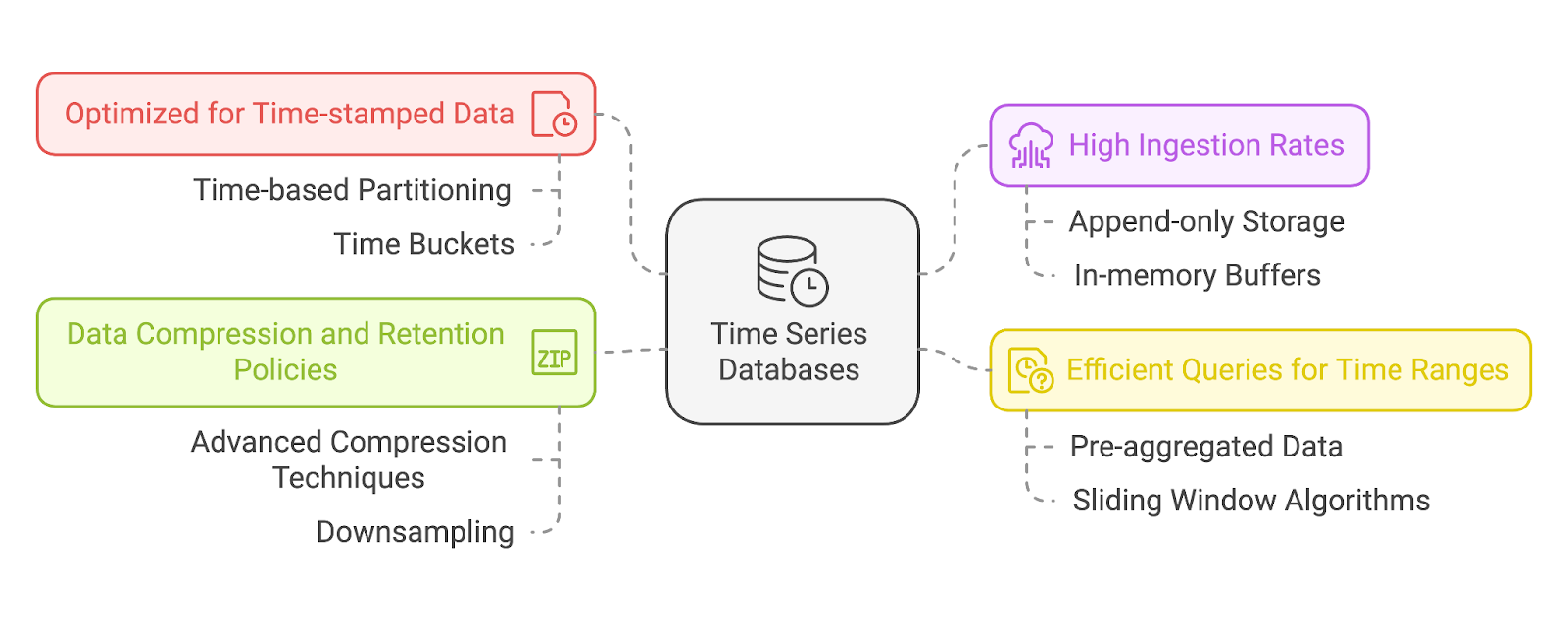
En esencia, las TSDB están construidas para manejar datos con marcas de tiempo como atributo fundamental. Cada punto de datos de una TSDB incluye una marca de tiempo, que sirve como índice primario. Esto permite a estas bases de datos almacenar y recuperar eficazmente secuencias ordenadas en el tiempo y proporcionar un acceso rápido a tendencias históricas o acontecimientos recientes.
La mayoría de las TSDB utilizan particiones basadas en el tiempo, lo que significa que los datos se almacenan en particiones basadas en intervalos de tiempo (por ejemplo, cada hora, cada día). Esto permite una poda eficaz, en la que las consultas ignoran por completo las particiones irrelevantes.
También pueden aplicar cubos de tiempoagrupando los datos en ventanas temporales predefinidas (por ejemplo, 1 minuto, 1 hora) para agregaciones más rápidas.
Los datos de series temporales suelen generarse a un ritmo rápido: piensa en dispositivos IoT que envían miles de puntos de datos por segundo o en una herramienta de supervisión de servidores que captura métricas del sistema en tiempo real. Las TSDB están optimizadas para estas altas tasas de escritura y pueden ingerir grandes cantidades de datos sin ralentizarse ni perder información.
Esto suele conseguirse utilizando modelos de almacenamiento de datos de sólo apéndice y búferes en memoria para evitar bloqueos o cuellos de botella transaccionales.
El análisis de datos de series temporales suele implicar la consulta de intervalos o ventanas temporales concretos, como "las últimas 24 horas" o "este año comparado con el año pasado". Las TSDB se construyen teniendo esto en cuenta, ofreciendo capacidades de consulta especializadas que permiten a los usuarios recuperar rápidamente datos sobre intervalos de tiempo definidos. También admiten agregaciones como medias, sumas o tendencias para ofrecer valiosos análisis sin una lógica de consulta compleja.
Las técnicas de optimización de consultas incluyen
Para gestionar la enorme cantidad de datos de series temporales que se generan a lo largo del tiempo, las TSDB utilizan técnicas avanzadas de compresión de datos. Estos métodos reducen los requisitos de almacenamiento al tiempo que preservan el rendimiento de la consulta.
Las TSDB suelen incluir políticas de retención para que los usuarios puedan definir cuánto tiempo deben conservarse los datos. Por ejemplo, un sistema puede conservar los datos detallados del último mes, mientras que reduce el muestreo para los datos más antiguos. El muestreo descendente es el proceso de reducir la granularidad de los datos a lo largo del tiempo. Por ejemplo:
Algunos ejemplos de técnicas avanzadas de compresión son
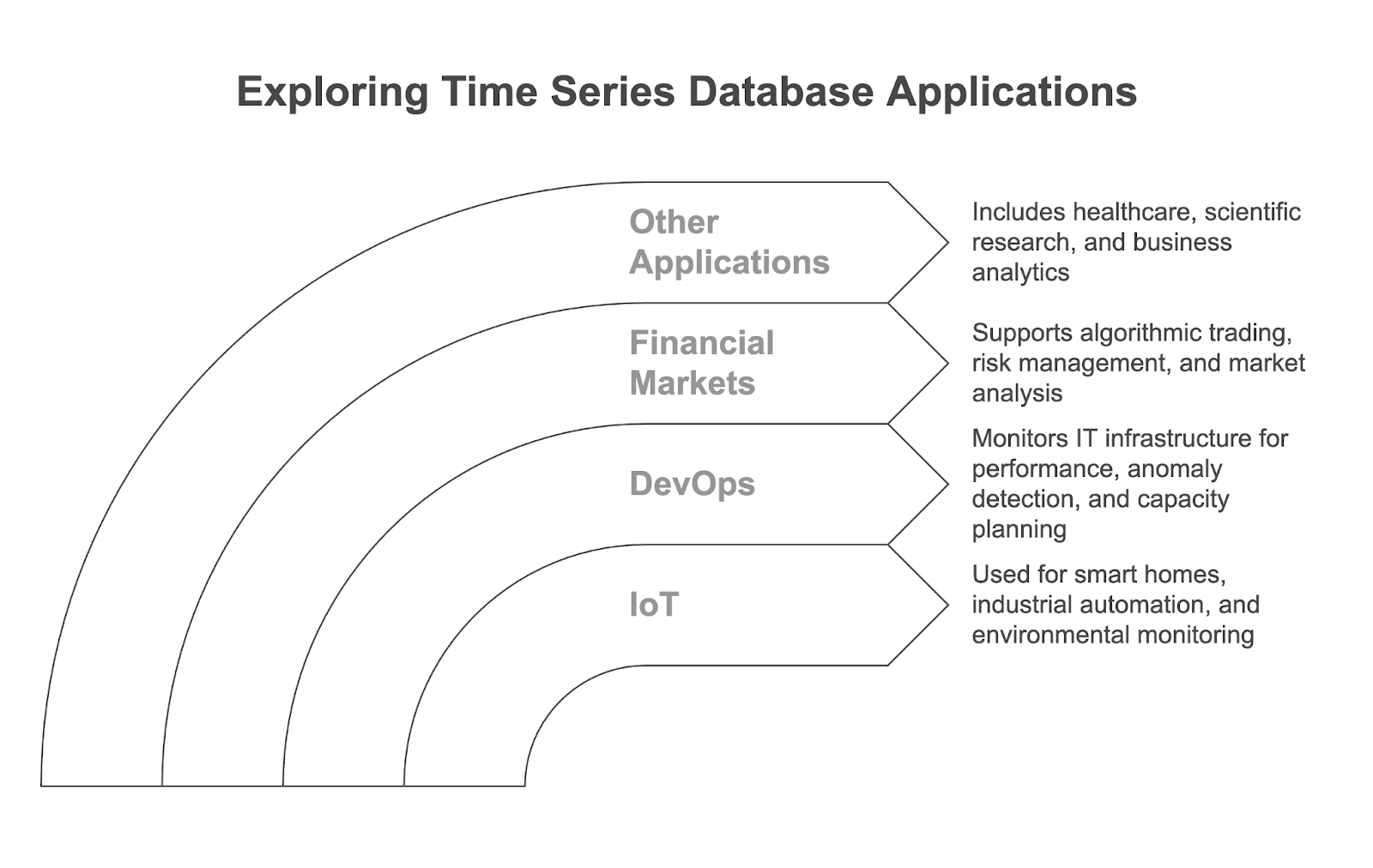
Las bases de datos de series temporales se utilizan en muchas aplicaciones modernas basadas en datos y en diversos sectores. Exploremos los principales casos de uso.
Los dispositivos IoT, como los termostatos inteligentes, los sensores industriales y los monitores medioambientales, generan flujos continuos de datos con fecha y hora. Las TSDB se utilizan para almacenar y analizar estos datos, y potencian aplicaciones como:
En DevOps, las TSDB se utilizan ampliamente para supervisar la infraestructura informática y las aplicaciones, recopilando métricas como el uso de la CPU, el consumo de memoria y el rendimiento de la red. Permiten:
Herramientas como Prometheus y Grafana suelen integrarse con las TSDB para proporcionar capacidades de visualización y alerta a los equipos de DevOps.
Las TSDB son fundamentales para procesar y analizar las enormes cantidades de datos de alta frecuencia que se generan en los mercados financieros. Se utilizan para:
Aunque los tres casos de uso anteriores son muy comunes, las bases de datos de series temporales también pueden encontrar aplicaciones en otros muchos campos:
Las bases de datos de series temporales tienen varias formas, cada una adaptada a casos de uso específicos.
InfluxDB es una popular base de datos de series temporales de código abierto desarrollada por InfluxData. Se diseñó específicamente para altas tasas de ingestión y consultas eficientes de datos con marca de tiempo, lo que la convierte en una solución habitual para la supervisión del IoT, las métricas DevOps y los análisis en tiempo real.
|
Pros |
Contras |
|
Altas tasas de ingestión para volúmenes masivos de datos. |
Requiere una gestión manual de las políticas de retención para un almacenamiento óptimo. |
|
InfluxQL, similar a SQL, simplifica las consultas para los analistas familiarizados con las bases de datos relacionales. |
Retos de escalabilidad para conjuntos de datos muy grandes sin funciones empresariales. |
|
Se integra fácilmente con herramientas como Grafana para su visualización. |
Capacidades de consulta avanzada limitadas en comparación con las bases de datos basadas en SQL. |
TimescaleDB es una extensión de código abierto para PostgreSQLdiseñada para combinar la potencia de bases de datos relacionales con la funcionalidad de las series temporales. Te permite aprovechar SQL a la vez que manejas eficazmente los datos con fecha y hora. Esto lo hace especialmente adecuado para casos de uso que requieren integrar datos de series temporales con datos relacionales, como la analítica empresarial o la telemetría IoT.
|
Pros |
Contras |
|
La compatibilidad total con SQL permite una fácil integración con las herramientas y flujos de trabajo PostgreSQL existentes. |
Requiere conocimientos de PostgreSQL para su configuración y mantenimiento. |
|
Hipertablas: Particiona automáticamente los datos de series temporales para un almacenamiento y unas consultas eficientes. |
Puede que aún no alcance la velocidad de ingestión de TSDB dedicadas como InfluxDB. |
|
Combina datos relacionales y de series temporales en una sola base de datos. |
Prometheus es un sistema de supervisión y alerta con una TSDB incorporada, ampliamente adoptado en DevOps para métricas del sistema en tiempo real, seguimiento del rendimiento y gestión de alertas.
|
Pros |
Contras |
|
Ligero y fácil de desplegar, especialmente con Kubernetes. |
Almacenamiento limitado a largo plazo sin soluciones externas. |
|
El scraping métrico basado en pull garantiza que sólo se recojan los datos relevantes. |
La escalabilidad depende de herramientas adicionales como Thanos o Cortex. |
|
PromQL proporciona potentes funciones de consulta. |
Se centra en las métricas y puede que no se adapte a todas las necesidades generales de la TSDB. |
ClickHouse es una base de datos columnar de código abierto diseñada para consultas analíticas de alto rendimiento. Aunque no es una TSDB tradicional, su arquitectura la hace excepcionalmente adecuada para datos de series temporales, especialmente cuando es fundamental un rendimiento rápido de las consultas.
|
Pros |
Contras |
|
Alto rendimiento de consulta para cargas de trabajo analíticas. |
Complejo de configurar y mantener para los principiantes. |
|
El almacenamiento en columnas reduce la latencia de las consultas. |
No está diseñada específicamente como TSDB (puede requerir soluciones). |
Apache Cassandra es una base de datos distribuida NoSQL construida para ofrecer escalabilidad horizontal y alta disponibilidad. Aunque no es exclusivamente una TSDB, puede utilizarse eficazmente para cargas de trabajo de series temporales, sobre todo cuando la durabilidad y la tolerancia a fallos son fundamentales.
|
Pros |
Contras |
|
Excelente escalabilidad horizontal. |
La consulta de datos de series temporales puede ser engorrosa sin optimizaciones adicionales, ya que la base de datos carece de funciones nativas de consulta y agregación de series temporales. |
|
Tolerante a fallos y de alta disponibilidad. |
Amazon Timestream es un servicio de base de datos de series temporales totalmente gestionado ofrecido por AWS. Construido para la escalabilidad y la simplicidad, es ideal para las organizaciones que ya aprovechan la infraestructura de AWS para el IoT y la monitorización de aplicaciones.
|
Pros |
Contras |
|
La arquitectura sin servidor simplifica la gestión. |
Funcionalidad limitada fuera del ecosistema AWS. |
|
Escala automáticamente para manejar grandes volúmenes de datos. |
Los costes pueden dispararse con altas tasas de ingestión de datos. |
Hagamos un resumen rápido con esta tabla:
¡Aprende ingeniería de datos con estos cursos!
programa
Curso
Curso