Programa
Engenheiro de dados associado em SQL
30 h
Há alguns anos, durante minha primeira semana em uma nova função de engenharia de software, pediram-me para investigar bancos de dados de séries temporais (TSDBs) para substituir nossa solução Postgres.
Eu não sabia absolutamente nada sobre o assunto e tinha muitas perguntas. O que é um banco de dados de séries temporais? Como isso funciona? Qual é a diferença entre ele e um banco de dados tradicional? Por que deveríamos usar um? Preciso de habilidades específicas para isso?
Desde então, aprendi muito sobre TSDBs e apliquei esse conhecimento em várias empresas para resolver uma ampla gama de problemas.
Neste artigo, resumirei o que aprendi nos últimos anos para que você tenha uma boa ideia do que são TSDBs, como eles funcionam e para quais casos de uso eles são mais adequados. Também apresentarei alguns dos TSDBs atualmente no mercado e darei dicas para que você possa escolher o que melhor atenda às suas necessidades.
Imagine um termostato inteligente vendido pela empresa X que registra as leituras de temperatura a cada 30 segundos. Em um único dia, esse único dispositivo gera milhares de pontos de dados. Agora, multiplique isso por centenas ou milhares de dispositivos em uma cidade, e o volume de dados com registro de data e hora coletados pela empresa X se torna impressionante.
Para armazenar esses dados de forma eficiente e analisar tendências (como mudanças de temperatura ao longo do tempo ou picos repentinos), a empresa X precisa de um banco de dados que possa lidar com grandes velocidades de gravação e realizar consultas baseadas em tempo de forma eficiente.
Os bancos de dados tradicionais tendem a ter dificuldades com esse tipo de carga de trabalho porque não foram projetados para lidar com gravações de dados de alta frequência ou consultar dados de forma eficiente em intervalos de tempo específicos. É aí que entram os bancos de dados de séries temporais.
Os bancos de dados de séries temporais são bancos de dados especializados projetados para gerenciar dados organizados e indexados por tempo. Diferentemente dos bancos de dados tradicionais, que são otimizados para o armazenamento de dados de uso geral, os TSDBs se concentram no armazenamento, na consulta e na análise eficientes de sequências de pontos de dados com registro de data e hora.
Os TSDBs são especialmente adequados para aplicativos que lidam com fluxos de dados contínuos, como IoT, monitoramento de DevOps e análise financeira.
Há algumas coisas que os TSDBs fazem de forma diferente dos bancos de dados tradicionais.
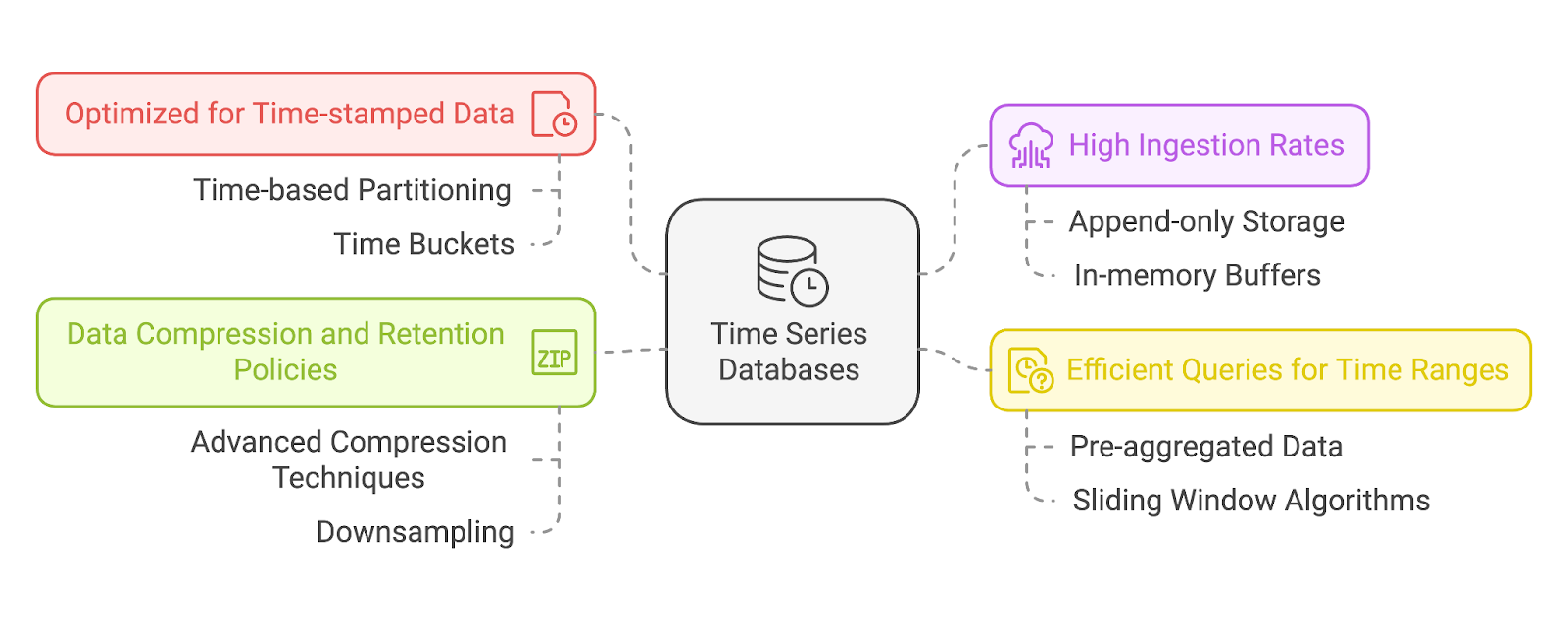
Em sua essência, os TSDBs são criados para lidar com dados com registros de data e hora como um atributo fundamental. Cada ponto de dados em um TSDB inclui um registro de data e hora, que serve como índice primário. Isso permite que esses bancos de dados armazenem e recuperem com eficiência sequências ordenadas no tempo e forneçam acesso rápido a tendências históricas ou eventos recentes.
A maioria dos TSDBs usa particionamento baseado em tempo, o que significa que os dados são armazenados em partições com base em intervalos de tempo (por exemplo, por hora, diariamente). Isso permite uma poda eficiente, em que as consultas ignoram completamente as partições irrelevantes.
Eles também podem implementar intervalos de tempoagrupando dados em janelas de tempo predefinidas (por exemplo, 1 minuto, 1 hora) para agregações mais rápidas.
Os dados de séries temporais geralmente são gerados em um ritmo rápido - pense nos dispositivos de IoT que enviam milhares de pontos de dados por segundo ou em uma ferramenta de monitoramento de servidor que captura métricas do sistema em tempo real. Os TSDBs são otimizados para essas altas taxas de gravação e podem ingerir grandes quantidades de dados sem diminuir a velocidade ou perder informações.
Em geral, isso é obtido com o uso de modelos de armazenamento de dados somente de acréscimo e buffers na memória para evitar bloqueios ou gargalos transacionais.
A análise de dados de séries temporais geralmente envolve a consulta de intervalos ou janelas de tempo específicos, como "últimas 24 horas" ou "este ano em comparação com o ano passado". Os TSDBs são criados com isso em mente, oferecendo recursos de consulta especializados que permitem que os usuários recuperem rapidamente dados em intervalos de tempo definidos. Eles também suportam agregações como médias, somas ou tendências para oferecer análises valiosas sem lógica de consulta complexa.
As técnicas de otimização de consulta incluem:
Para gerenciar a grande quantidade de dados de séries temporais gerados ao longo do tempo, os TSDBs usam técnicas avançadas de compactação de dados. Esses métodos reduzem os requisitos de armazenamento e, ao mesmo tempo, preservam o desempenho da consulta.
Os TSDBs geralmente incluem políticas de retenção para que os usuários possam definir por quanto tempo os dados devem ser mantidos. Por exemplo, um sistema pode reter dados detalhados do último mês enquanto faz downsampling para dados mais antigos. A redução da amostragem é o processo de reduzir a granularidade dos dados ao longo do tempo. Por exemplo:
Exemplos de técnicas avançadas de compactação incluem:
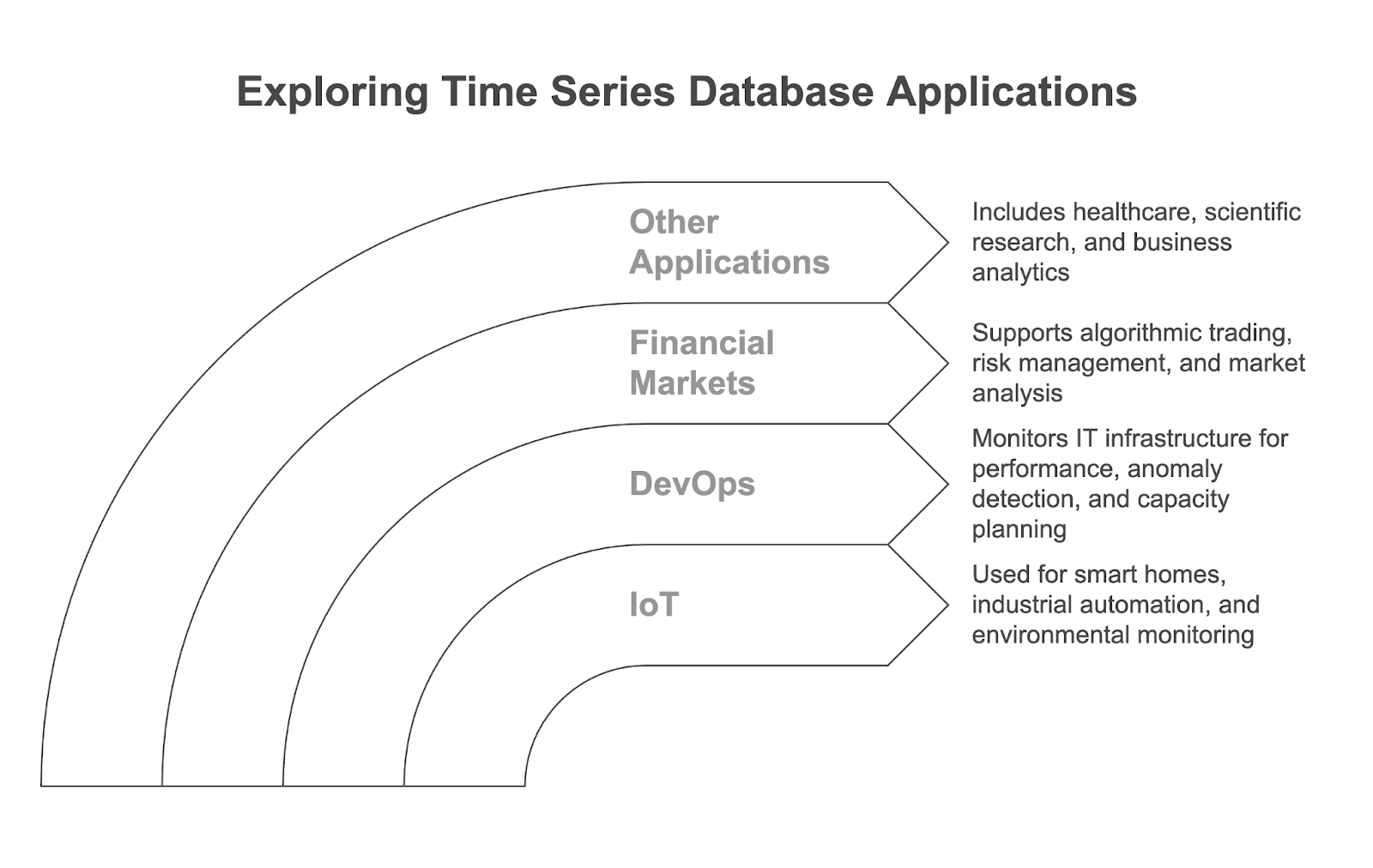
Os bancos de dados de séries temporais são usados em muitos aplicativos modernos orientados por dados e em diversos setores. Vamos explorar os principais casos de uso.
Os dispositivos de IoT, como termostatos inteligentes, sensores industriais e monitores ambientais, geram fluxos contínuos de dados com registro de data e hora. Os TSDBs são usados para armazenar e analisar esses dados e alimentar aplicativos como:
No DevOps, os TSDBs são amplamente usados para monitorar a infraestrutura e os aplicativos de TI, coletando métricas como uso da CPU, consumo de memória e taxa de transferência da rede. Eles permitem:
Ferramentas como Prometheus e Grafana geralmente se integram aos TSDBs para fornecer recursos de visualização e alerta para as equipes de DevOps.
Os TSDBs são essenciais para processar e analisar as grandes quantidades de dados de alta frequência gerados nos mercados financeiros. Eles são usados para:
Embora os três casos de uso acima sejam muito comuns, os bancos de dados de séries temporais também podem encontrar aplicações em vários outros campos:
Os bancos de dados de séries temporais têm vários formatos e formas, cada um adaptado a casos de uso específicos.
O InfluxDB é um popular banco de dados de séries temporais de código aberto desenvolvido pela InfluxData. Ele foi projetado especificamente para altas taxas de ingestão e consulta eficiente de dados com registro de data e hora, tornando-o uma solução comum para monitoramento de IoT, métricas de DevOps e análise em tempo real.
|
Prós |
Contras |
|
Altas taxas de ingestão para grandes volumes de dados. |
Requer gerenciamento manual das políticas de retenção para otimizar o armazenamento. |
|
O InfluxQL, semelhante ao SQL, simplifica a consulta para analistas familiarizados com bancos de dados relacionais. |
Desafios de escalabilidade para conjuntos de dados muito grandes sem recursos empresariais. |
|
Integra-se facilmente com ferramentas como o Grafana para visualização. |
Recursos limitados de consulta avançada em comparação com bancos de dados baseados em SQL. |
O TimescaleDB é uma extensão de código aberto para o PostgreSQLprojetada para combinar o poder dos bancos de dados relacionais com a funcionalidade de séries temporais. Ele permite que você utilize o SQL e, ao mesmo tempo, manipule com eficiência os dados com registro de data e hora. Isso o torna particularmente adequado para casos de uso que exigem a integração de dados de séries temporais com dados relacionais, como análise de negócios ou telemetria de IoT.
|
Prós |
Contras |
|
O suporte total a SQL permite a fácil integração com as ferramentas e os fluxos de trabalho existentes do PostgreSQL. |
Requer conhecimento de PostgreSQL para configuração e manutenção. |
|
Hipertabelas: Particionar automaticamente dados de séries temporais para armazenamento e consultas eficientes. |
Pode ainda não corresponder à velocidade de ingestão de TSDBs dedicados, como o InfluxDB. |
|
Combina dados relacionais e de séries temporais em um único banco de dados. |
O Prometheus é um sistema de monitoramento e alerta com um TSDB integrado, amplamente adotado em DevOps para métricas de sistema em tempo real, rastreamento de desempenho e gerenciamento de alertas.
|
Prós |
Contras |
|
Leve e fácil de implantar, especialmente com o Kubernetes. |
Armazenamento limitado de longo prazo sem soluções externas. |
|
A raspagem de métricas baseada em pull garante que somente os dados relevantes sejam coletados. |
A escalabilidade depende de ferramentas adicionais, como Thanos ou Cortex. |
|
O PromQL oferece recursos avançados de consulta. |
Concentra-se em métricas e pode não atender a todas as necessidades de uso geral do TSDB. |
O ClickHouse é um banco de dados colunar de código aberto projetado para consultas analíticas de alto desempenho. Embora não seja um TSDB tradicional, sua arquitetura o torna excepcionalmente adequado para dados de séries temporais, especialmente quando o desempenho de consultas rápidas é fundamental.
|
Prós |
Contras |
|
Alto desempenho de consulta para cargas de trabalho analíticas. |
Complexidade de configuração e manutenção para iniciantes. |
|
O armazenamento em colunas reduz a latência das consultas. |
Não foi projetado especificamente como um TSDB (pode exigir soluções alternativas). |
O Apache Cassandra é um banco de dados NoSQL distribuído criado para escalabilidade horizontal e alta disponibilidade. Embora não seja exclusivamente um TSDB, ele pode ser usado com eficiência para cargas de trabalho de séries temporais, especialmente quando a durabilidade e a tolerância a falhas são essenciais.
|
Prós |
Contras |
|
Excelente escalabilidade horizontal. |
A consulta de dados de séries temporais pode ser complicada sem otimizações adicionais, pois o banco de dados não possui recursos nativos de consulta e agregação de séries temporais. |
|
Tolerante a falhas e altamente disponível. |
O Amazon Timestream é um serviço de banco de dados de séries temporais totalmente gerenciado oferecido pela AWS. Criado para ser escalável e simples, ele é ideal para organizações que já utilizam a infraestrutura da AWS para IoT e monitoramento de aplicativos.
|
Prós |
Contras |
|
A arquitetura sem servidor simplifica o gerenciamento. |
Funcionalidade limitada fora do ecossistema da AWS. |
|
Escala automaticamente para lidar com grandes volumes de dados. |
Os custos podem aumentar com altas taxas de ingestão de dados. |
Aprenda engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Kurtis Pykes
11 min
blog
Zoumana Keita
12 min
blog
Kurtis Pykes
7 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna


