
Track
Associate Data Engineer in SQL
30 hr
A couple of years ago, during my first week in a new software engineering role, I was asked to investigate time series databases (TSDBs) to replace our Postgres solution.
I knew absolutely nothing about the topic and had so many questions. What even is a time series database? How does it work? How is it different from a traditional database? Why should we use one? Do I need specific skills for that?
Since then, I’ve learned a lot about TSDBs and have applied this knowledge in various companies to solve a wide range of problems.
In this article, I’ll sum up what I learned over the past few years to give you a good idea of what TSDBs are, how they work, and what use cases they best work for. I’ll also walk you through some of the TSDBs currently on the market and give you tips so you can choose the one that best suits your needs.
Imagine a smart thermostat sold by company X that records temperature readings every 30 seconds. In a single day, this one device generates thousands of data points. Now, multiply that by hundreds or thousands of devices across a city, and the volume of time-stamped data gathered by company X becomes staggering.
To store this data efficiently and analyze trends (like temperature changes over time or sudden spikes), company X needs a database that can handle massive write speeds and perform time-based queries efficiently.
Traditional databases tend to struggle with this kind of workload because they aren't designed to handle high-frequency data writes or query data efficiently over specific time ranges. That’s where time series databases come in.
Time series databases are specialized databases designed to manage data that is organized and indexed by time. Unlike traditional databases, which are optimized for general-purpose data storage, TSDBs focus on efficiently storing, querying, and analyzing sequences of time-stamped data points.
TSDBs are particularly suited for applications that deal with continuous data streams, such as IoT, DevOps monitoring, and financial analytics.
There are a few things that TSDBs do differently than traditional databases.
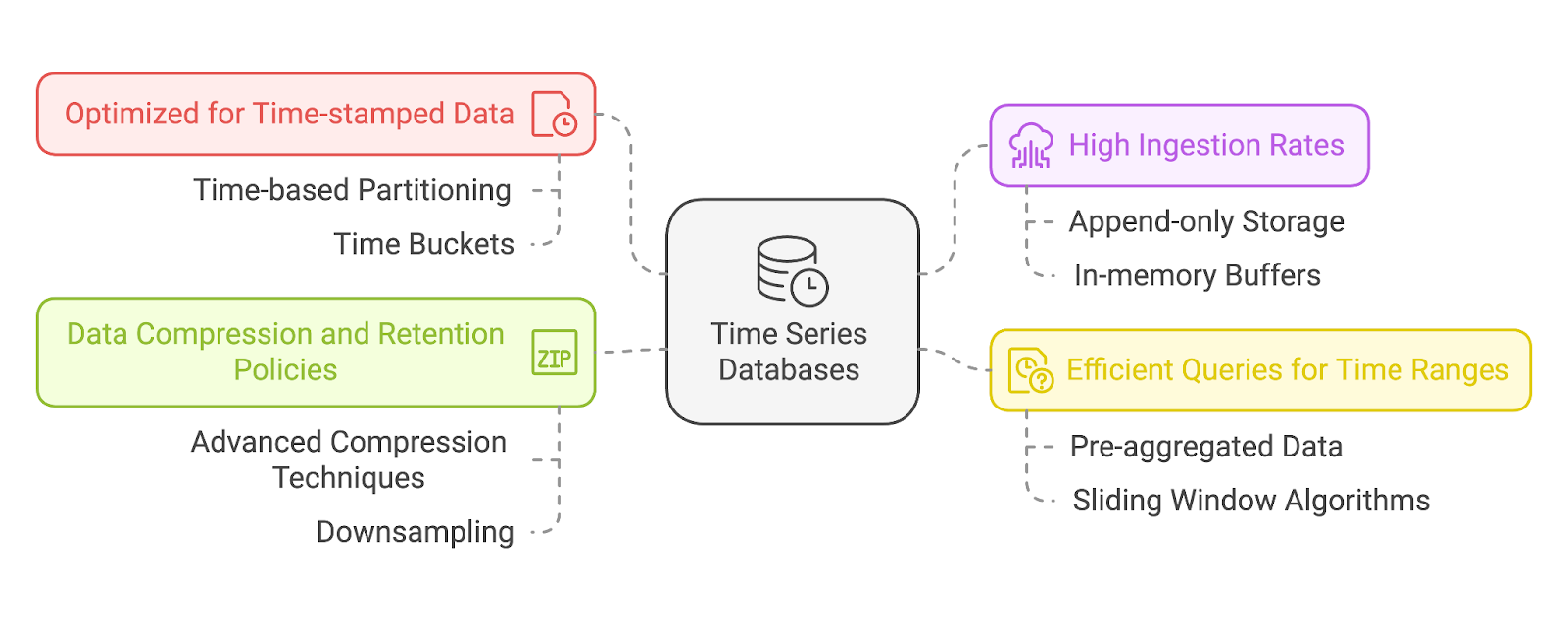
At their core, TSDBs are built to handle data with timestamps as a fundamental attribute. Every data point in a TSDB includes a timestamp, which serves as its primary index. This allows these databases to efficiently store and retrieve time-ordered sequences and provide quick access to historical trends or recent events.
Most TSDBs use time-based partitioning, meaning the data is stored in partitions based on time intervals (e.g., hourly, daily). This enables efficient pruning, where queries ignore irrelevant partitions altogether.
They can also implement time buckets, grouping data into predefined time windows (e.g., 1 minute, 1 hour) for faster aggregations.
Time series data is often generated at a rapid pace—think of IoT devices sending thousands of data points per second or a server monitoring tool capturing system metrics in real time. TSDBs are optimized for these high write rates and can ingest vast amounts of data without slowing down or losing information.
This is usually achieved using append-only data storage models and in-memory buffers to prevent locks or transactional bottlenecks.
Analyzing time series data often involves querying specific time intervals or windows, such as “last 24 hours” or “this year compared to last year.” TSDBs are built with this in mind, offering specialized query capabilities that allow users to quickly retrieve data over defined time ranges. They also support aggregations like averages, sums, or trends to offer valuable analytics without complex query logic.
The query optimization techniques include:
To manage the vast amount of time series data generated over time, TSDBs use advanced data compression techniques. These methods reduce storage requirements while preserving query performance.
TSDBs usually include retention policies so the users can define how long data should be kept. For example, a system might retain detailed data for the past month while downsampling for older data. Downsampling is the process of reducing the granularity of data over time. For example:
Examples of advanced compression techniques include:
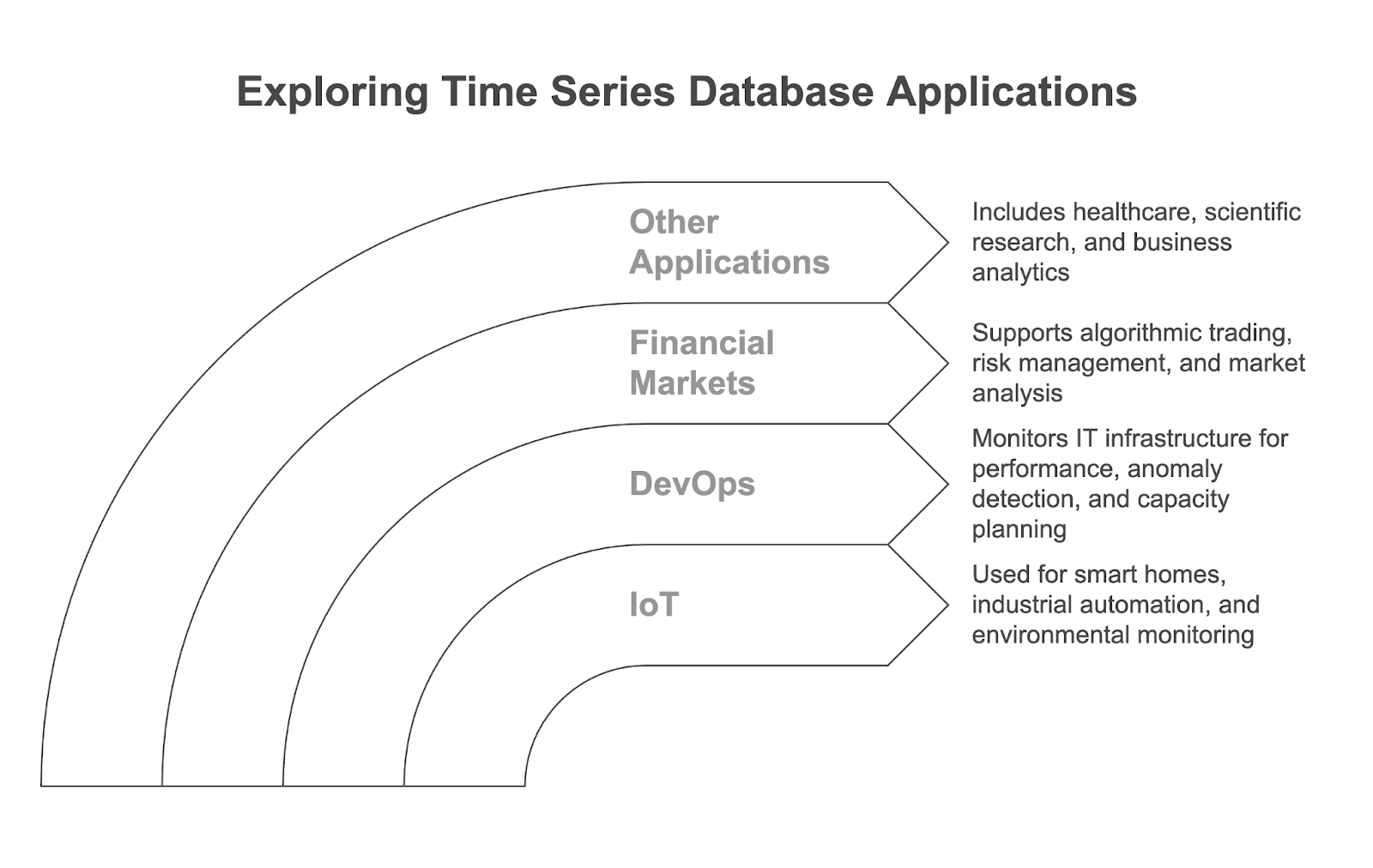
Time series databases are used in many modern data-driven applications and across diverse industries. Let’s explore the main use cases.
IoT devices, like smart thermostats, industrial sensors, and environmental monitors, generate continuous streams of time-stamped data. TSDBs are used to store and analyze this data, and power applications like:
In DevOps, TSDBs are widely used to monitor IT infrastructure and applications by collecting metrics like CPU usage, memory consumption, and network throughput. They enable:
Tools like Prometheus and Grafana often integrate with TSDBs to provide visualization and alerting capabilities for DevOps teams.
TSDBs are critical for processing and analyzing the vast amounts of high-frequency data generated in financial markets. They are used for:
While the three use cases above are very common, time series databases can also find applications in a variety of other fields:
Time series databases come in various shapes and forms, each tailored for specific use cases.
InfluxDB is a popular open-source time series database developed by InfluxData. It was designed specifically for high ingestion rates and efficient querying of time-stamped data, making it a common solution for IoT monitoring, DevOps metrics, and real-time analytics.
|
Pros |
Cons |
|
High ingestion rates for massive volumes of data. |
Requires manual management of retention policies for optimal storage. |
|
SQL-like InfluxQL simplifies querying for analysts familiar with relational databases. |
Scalability challenges for very large datasets without enterprise features. |
|
Integrates easily with tools like Grafana for visualization. |
Limited advanced query capabilities compared to SQL-based databases. |
TimescaleDB is an open-source extension for PostgreSQL, designed to combine the power of relational databases with time-series functionality. It allows you to leverage SQL while efficiently handling time-stamped data. This makes it particularly well-suited for use cases that require integrating time-series data with relational data, such as business analytics or IoT telemetry.
|
Pros |
Cons |
|
Full SQL support enables easy integration with existing PostgreSQL tools and workflows. |
Requires PostgreSQL knowledge for setup and maintenance. |
|
Hypertables: Automatically partition time-series data for efficient storage and queries. |
May not yet match the ingestion speed of dedicated TSDBs like InfluxDB. |
|
Combines relational and time-series data in a single database. |
Prometheus is a monitoring and alerting system with a built-in TSDB, widely adopted in DevOps for real-time system metrics, performance tracking, and alert management.
|
Pros |
Cons |
|
Lightweight and easy to deploy, especially with Kubernetes. |
Limited long-term storage without external solutions. |
|
Pull-based metric scraping ensures only relevant data is collected. |
Scalability relies on additional tools like Thanos or Cortex. |
|
PromQL provides powerful query capabilities. |
Focuses on metrics and may not suit all general-purpose TSDB needs. |
ClickHouse is an open-source columnar database designed for high-performance analytical queries. While it is not a traditional TSDB, its architecture makes it exceptionally suited for time-series data, especially when fast query performance is critical.
|
Pros |
Cons |
|
High query performance for analytical workloads. |
Complex to set up and maintain for beginners. |
|
Columnar storage reduces query latency. |
Not specifically designed as a TSDB (may require workarounds). |
Apache Cassandra is a distributed NoSQL database built for horizontal scalability and high availability. While not exclusively a TSDB, it can be used effectively for time-series workloads, particularly when durability and fault tolerance are critical.
|
Pros |
Cons |
|
Excellent horizontal scalability. |
Querying time-series data can be cumbersome without additional optimizations, as the database lacks native time-series query and aggregation features. |
|
Fault-tolerant and highly available. |
Amazon Timestream is a fully managed time series database service offered by AWS. Built for scalability and simplicity, it is ideal for organizations already leveraging AWS infrastructure for IoT and application monitoring.
|
Pros |
Cons |
|
Serverless architecture simplifies management. |
Limited functionality outside the AWS ecosystem. |
|
Scales automatically to handle large data volumes. |
Costs can escalate with high data ingestion rates. |
Let's do a quick recap with this table:
Learn data engineering with these courses!
Track
Course
Course
blog
Allan Ouko
6 min
blog
Kurtis Pykes
11 min
blog
Kurtis Pykes
9 min
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
code-along
Mehdi Ouazza
