Cursus
Ingénieur de données associé en SQL
30 h
Il y a quelques années, au cours de ma première semaine dans une nouvelle fonction d'ingénieur logiciel, on m'a demandé d'étudier les aspects suivants bases de données de séries temporelles (TSDB) pour remplacer notre solution Postgres.
Je ne connaissais absolument rien au sujet et je me posais beaucoup de questions. Qu'est-ce qu'une base de données de séries chronologiques ? Comment cela fonctionne-t-il ? Quelle est la différence avec une base de données traditionnelle ? Pourquoi devrions-nous en utiliser un ? Ai-je besoin de compétences spécifiques pour cela ?
Depuis, j'ai beaucoup appris sur les TSDB et j'ai appliqué ces connaissances dans diverses entreprises pour résoudre un large éventail de problèmes.
Dans cet article, je résumerai ce que j'ai appris au cours des dernières années pour vous donner une bonne idée de ce que sont les TSDB, de leur fonctionnement et des cas d'utilisation pour lesquels elles conviennent le mieux. Je vous présenterai également quelques-unes des TSDB actuellement disponibles sur le marché et vous donnerai des conseils pour que vous puissiez choisir celle qui répond le mieux à vos besoins.
Imaginez un thermostat intelligent vendu par l'entreprise X qui enregistre la température toutes les 30 secondes. En une seule journée, cet appareil génère des milliers de points de données. Maintenant, multipliez cela par des centaines ou des milliers d'appareils dans une ville, et le volume de données horodatées recueillies par l'entreprise X devient stupéfiant.
Pour stocker efficacement ces données et analyser les tendances (comme les changements de température au fil du temps ou les pics soudains), l'entreprise X a besoin d'une base de données capable de gérer des vitesses d'écriture massives et d'exécuter efficacement des requêtes basées sur le temps.
Les bases de données traditionnelles ont tendance à se heurter à ce type de charge de travail parce qu'elles ne sont pas conçues pour gérer les écritures de données à haute fréquence ou pour interroger efficacement des données sur des périodes spécifiques. C'est là qu'interviennent les bases de données de séries chronologiques.
Les bases de données de séries temporelles sont des bases de données spécialisées conçues pour gérer des données organisées et indexées en fonction du temps. Contrairement aux bases de données traditionnelles, qui sont optimisées pour le stockage de données à usage général, les TSDB se concentrent sur le stockage, l'interrogation et l'analyse efficaces de séquences de points de données horodatés.
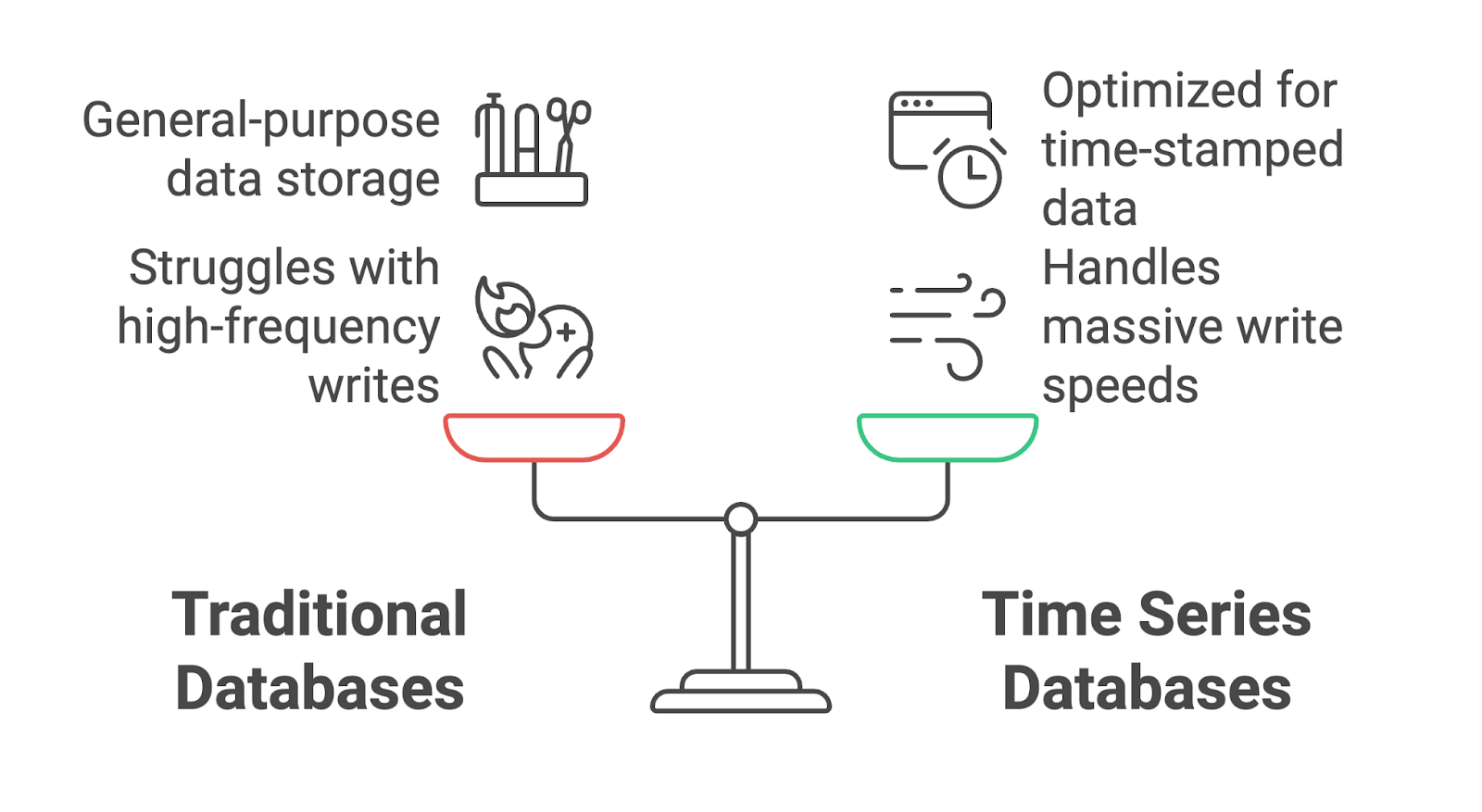
Les TSDB sont particulièrement adaptées aux applications qui traitent des flux de données continus, comme l'IoT, la surveillance DevOps et l'analyse financière.
Il y a quelques différences entre les TSDB et les bases de données traditionnelles.
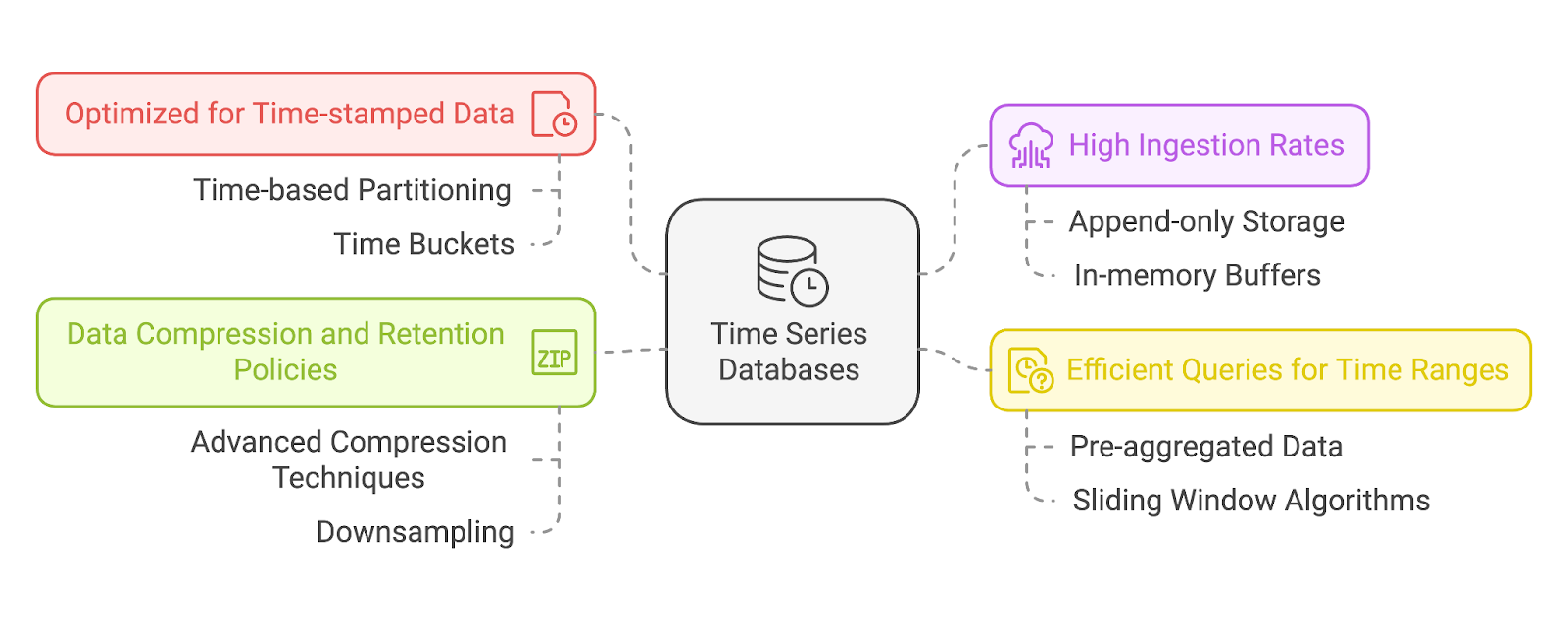
À la base, les TSDB sont conçues pour traiter des données dont l'un des attributs fondamentaux est l'horodatage. Chaque point de données dans une TSDB comprend un horodatage, qui sert d'index primaire. Cela permet à ces bases de données de stocker et d'extraire efficacement des séquences ordonnées dans le temps et d'offrir un accès rapide aux tendances historiques ou aux événements récents.
La plupart des BDST utilisent un partitionnement basé sur le temps, ce qui signifie que les données sont stockées dans des partitions basées sur des intervalles de temps (par exemple, toutes les heures, tous les jours). Cela permet un élagage efficace, où les requêtes ignorent complètement les partitions non pertinentes.
Ils peuvent également mettre en place des groupes de tempsqui regroupent les données dans des fenêtres temporelles prédéfinies (par exemple, 1 minute, 1 heure) pour des agrégations plus rapides.
Les données de séries temporelles sont souvent générées à un rythme rapide - pensez aux appareils IoT qui envoient des milliers de points de données par seconde ou à un outil de surveillance de serveur qui capture les métriques du système en temps réel. Les TSDB sont optimisées pour ces taux d'écriture élevés et peuvent ingérer de grandes quantités de données sans ralentissement ni perte d'informations.
Pour ce faire, on utilise généralement des modèles de stockage de données "append-only" et des tampons en mémoire afin d'éviter les blocages ou les goulets d'étranglement transactionnels.
L'analyse de données de séries chronologiques implique souvent l'interrogation d'intervalles de temps ou de fenêtres spécifiques, tels que "les dernières 24 heures" ou "cette année comparée à l'année dernière". Les BDST sont conçues dans cette optique et offrent des capacités d'interrogation spécialisées qui permettent aux utilisateurs d'extraire rapidement des données sur des périodes définies. Ils prennent également en charge les agrégations telles que les moyennes, les sommes ou les tendances afin d'offrir des analyses précieuses sans logique d'interrogation complexe.
Les techniques d'optimisation des requêtes comprennent
Pour gérer la grande quantité de données de séries temporelles générées au fil du temps, les TSDB utilisent des techniques avancées de compression des données. Ces méthodes réduisent les besoins en stockage tout en préservant les performances des requêtes.
Les BDST comprennent généralement des politiques de conservation permettant aux utilisateurs de définir la durée de conservation des données. Par exemple, un système peut conserver des données détaillées pour le mois écoulé tout enprocédant à un sous-échantillonnage ( ) pour les données plus anciennes ( ). Le déséchantillonnage est le processus de réduction de la granularité des données dans le temps. Par exemple :
Voici quelques exemples de techniques de compression avancées :
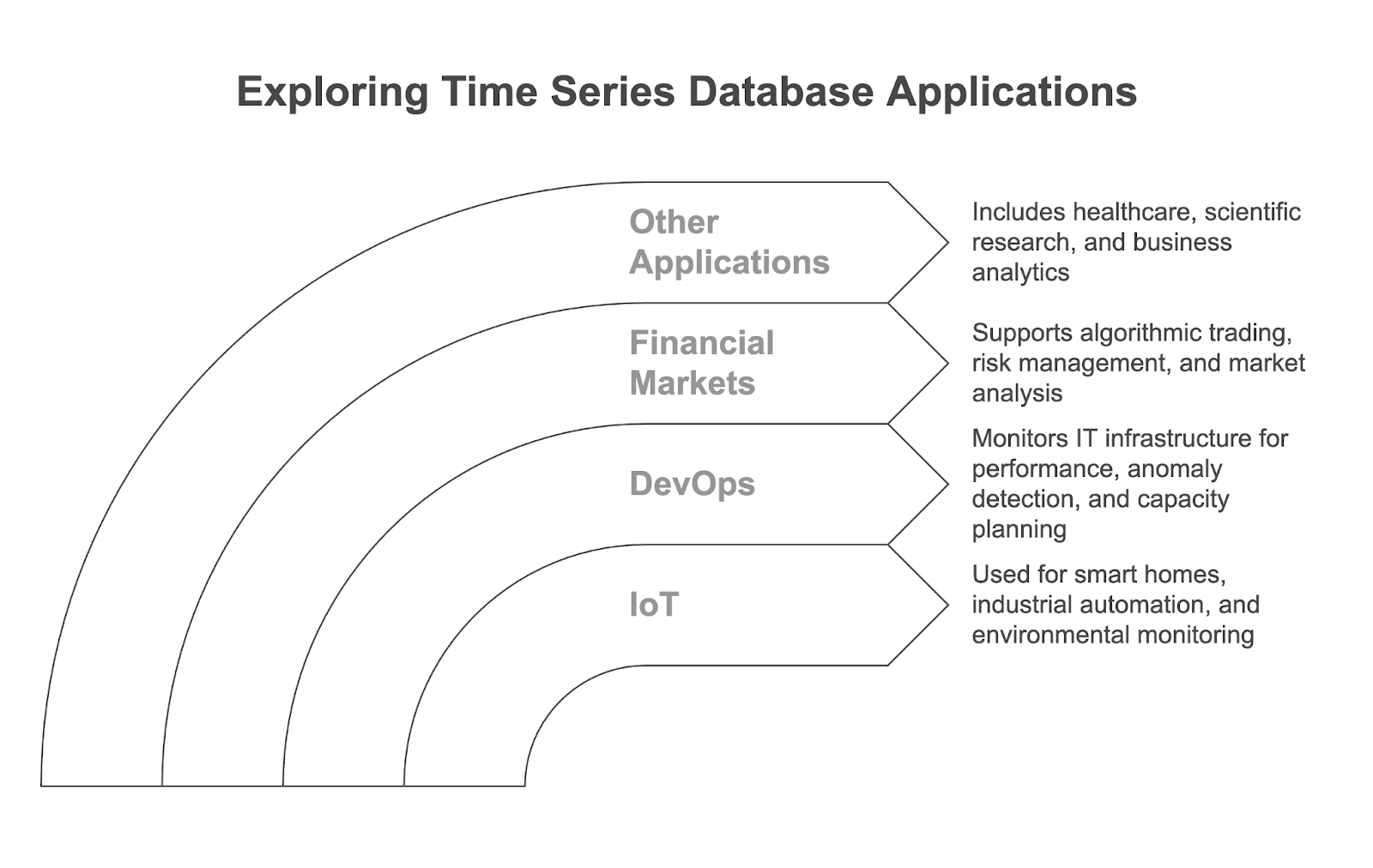
Les bases de données de séries temporelles sont utilisées dans de nombreuses applications modernes basées sur les données et dans divers secteurs d'activité. Examinons les principaux cas d'utilisation.
Les appareils IoT, tels que les thermostats intelligents, les capteurs industriels et les moniteurs environnementaux, génèrent des flux continus de données horodatées. Les TSDB sont utilisées pour stocker et analyser ces données, et alimentent des applications telles que :
Dans le cadre de DevOps, les TSDB sont largement utilisées pour surveiller l'infrastructure et les applications informatiques en collectant des données telles que l'utilisation du processeur, la consommation de mémoire et le débit du réseau. Ils permettent :
Des outils comme Prometheus et Grafana s'intègrent souvent aux TSDB pour fournir des capacités de visualisation et d'alerte aux équipes DevOps.
Les TSDB sont essentielles pour le traitement et l'analyse des grandes quantités de données à haute fréquence générées par les marchés financiers. Ils sont utilisés pour :
Si les trois cas d'utilisation ci-dessus sont très courants, les bases de données de séries temporelles peuvent également trouver des applications dans toute une série d'autres domaines :
Les bases de données de séries temporelles se présentent sous différentes formes, chacune étant adaptée à des cas d'utilisation spécifiques.
InfluxDB est une base de données de séries temporelles open-source développée par InfluxData. Il a été conçu spécifiquement pour des taux d'ingestion élevés et une interrogation efficace des données horodatées, ce qui en fait une solution courante pour la surveillance de l'IoT, les métriques DevOps et les analyses en temps réel.
|
Pour |
Cons |
|
Taux d'ingestion élevés pour des volumes massifs de données. |
Nécessite une gestion manuelle des politiques de conservation pour un stockage optimal. |
|
InfluxQL, de type SQL, simplifie les requêtes pour les analystes familiers des bases de données relationnelles. |
Défis en matière d'évolutivité pour les très grands ensembles de données sans caractéristiques d'entreprise. |
|
S'intègre facilement avec des outils comme Grafana pour la visualisation. |
Capacités d'interrogation avancées limitées par rapport aux bases de données basées sur SQL. |
TimescaleDB est une extension open-source pour PostgreSQLconçue pour combiner la puissance des bases de données relationnelles avec les fonctionnalités des séries temporelles. Il vous permet d'exploiter SQL tout en traitant efficacement les données horodatées. Il est donc particulièrement bien adapté aux cas d'utilisation qui nécessitent l'intégration de données temporelles avec des données relationnelles, telles que l'analyse commerciale ou la télémétrie IoT.
|
Pour |
Cons |
|
Le support SQL complet permet une intégration facile avec les outils et les flux de travail PostgreSQL existants. |
Des connaissances en PostgreSQL sont nécessaires pour l'installation et la maintenance. |
|
Hypertables : Partitionner automatiquement les données de séries temporelles pour un stockage et des requêtes efficaces. |
La vitesse d'ingestion n'est peut-être pas encore comparable à celle des bases de données spécialisées comme InfluxDB. |
|
Combine les données relationnelles et les séries temporelles dans une seule base de données. |
Prometheus est un système de surveillance et d'alerte avec une TSDB intégrée, largement adopté dans DevOps pour les métriques système en temps réel, le suivi des performances et la gestion des alertes.
|
Pour |
Cons |
|
Léger et facile à déployer, notamment avec Kubernetes. |
Stockage à long terme limité sans solutions externes. |
|
Le scraping métrique basé sur l'extraction garantit que seules les données pertinentes sont collectées. |
L'évolutivité repose sur des outils supplémentaires tels que Thanos ou Cortex. |
|
PromQL offre de puissantes capacités d'interrogation. |
Il se concentre sur les mesures et peut ne pas répondre à tous les besoins généraux en matière de bases de données statistiques. |
ClickHouse est une base de données en colonnes open-source conçue pour des requêtes analytiques de haute performance. Bien qu'il ne s'agisse pas d'une base de données traditionnelle, son architecture la rend exceptionnellement adaptée aux données chronologiques, en particulier lorsque la rapidité d'exécution des requêtes est essentielle.
|
Pour |
Cons |
|
Performances élevées en matière d'interrogation pour les charges de travail analytiques. |
Complexe à mettre en place et à entretenir pour les débutants. |
|
Le stockage en colonnes réduit la latence des requêtes. |
N'est pas spécifiquement conçu comme une TSDB (peut nécessiter des solutions de contournement). |
Apache Cassandra est une base de données NoSQL distribuée construite pour l'évolutivité horizontale et la haute disponibilité. Bien qu'il ne s'agisse pas exclusivement d'une TSDB, elle peut être utilisée efficacement pour les charges de travail liées aux séries temporelles, en particulier lorsque la durabilité et la tolérance aux pannes sont essentielles.
|
Pour |
Cons |
|
Excellente évolutivité horizontale. |
L'interrogation des données chronologiques peut être fastidieuse sans optimisations supplémentaires, car la base de données ne dispose pas de fonctions natives d'interrogation et d'agrégation des données chronologiques. |
|
Tolérance aux pannes et haute disponibilité. |
Amazon Timestream est un service de base de données de séries temporelles entièrement géré proposé par AWS. Conçu pour l'évolutivité et la simplicité, il est idéal pour les organisations qui exploitent déjà l'infrastructure AWS pour l'IoT et la surveillance des applications.
|
Pour |
Cons |
|
L'architecture sans serveur simplifie la gestion. |
Fonctionnalité limitée en dehors de l'écosystème AWS. |
|
S'adapte automatiquement pour gérer de grands volumes de données. |
Les coûts peuvent augmenter avec des taux d'ingestion de données élevés. |
Apprenez l'ingénierie des données avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach