
programa
Fundamentos de la IA
10 h
¿Has oído alguna vez que, según datos recogidos en EE.UU., el consumo de helado está relacionado con los ataques de tiburones?
Por disparatado que parezca, este tipo de correlación se produce cuando dos variables parecen estar relacionadas, pero en realidad ambas están influidas por una tercera variable. En este caso, el factor probable es la temperatura. Durante el verano, el consumo de helados aumenta debido al calor. Al mismo tiempo, los ataques de tiburones también aumentan porque hay más gente nadando en el océano.
Aunque este patrón muestra una correlación en los datos, no implica que uno cause el otro. Aquí es donde entra en juego Causal AI. ayuda a identificar las verdaderas relaciones causa-efecto en los datos, permitiéndonos evitar correlaciones espurias.
En este artículo exploraremos el concepto de IA Causal, su significado y cómo aplicarlo en la práctica.
La IA causal es una rama de la Inteligencia Artificial (IA) que se centra en comprender y modelar las relaciones causa-efectoen lugar de limitarse a identificar patrones o correlaciones, como hacen otros sistemas tradicionales de Aprendizaje Automático.
La IA causal ayuda a mejorar la fiabilidad, explicabilidad y solidez de los sistemas de IA, sobre todo en escenarios del mundo real como la sanidad y la economía, que son más complejos por naturaleza.
Llegados a este punto, puede que te estés preguntando:
¿Por qué los métodos tradicionales de IA no tienen en cuenta la causalidad?
Los sistemas tradicionales de IA se centran en identificar patrones, correlaciones y hacer predicciones basadas en datos. Para ello, se basan en técnicas estadísticas y de Aprendizaje Automático (AM) para encontrar asociaciones en los datos.
De hecho, durante el entrenamiento, se diseñan para optimizar la precisión en la predicción utilizando grandes conjuntos de datos. Esos conjuntos de datos son los que contienen correlaciones y los algoritmos se darán cuenta de esas correlaciones, pero puede que no haya información causal explícita.
Además, los sistemas tradicionales de IA suelen ser criticados por su escasa explicabilidad y con frecuencia se les califica de "caja negra". En este contexto, Causal AI ayuda a construir modelos más transparentes e interpretables razonando explícitamente sobre causas y efectos.
Por último, aunque los métodos tradicionales (no causales) de la IA tienen muchas aplicaciones, la conclusión clave de esta sección es: La correlación no implica causalidad.
Volviendo al ejemplo del helado frente a los ataques de tiburón de la introducción, podemos ver que las ventas de helado y los incidentes de ataques de tiburón están correlacionados (ambos aumentan en verano), pero el helado no causa los ataques de tiburón.
Como hemos visto, en el núcleo de la IA Causal está el objetivo de establecer relaciones de causa-efecto entre variables. Sin embargo, también hay dos conceptos fundamentales esenciales para comprender y manipular estas relaciones dentro de un sistema:
El razonamiento contrafáctico implica considerar escenarios hipotéticos para comprender cómo los cambios en determinadas variables pueden alterar los resultados.
Me gusta ver el Razonamiento Contrafáctico como la formulación de preguntas del tipo "¿Qué habría pasado si la variable X hubiera tomado un valor diferente?". Eso es un "pregunta pregunta.
En nuestro ejemplo del helado frente a los ataques de tiburón, podríamos preguntarnos:"¿Y si las ventas de helado hubieran sido menores? ¿Habría habido menos ataques de tiburones?".
En este escenario contrafactual, imaginamos una versión alternativa de la realidad en la que las ventas de helados disminuyen mientras todo lo demás permanece igual. Dado que tanto las ventas de helados como los ataques de tiburones aumentan en verano debido al clima más cálido (una causa común), reducir las ventas de helados no afectaría a los ataques de tiburones. Esto demuestra correlación, no causalidad.
Las intervenciones se refieren a la manipulación deliberada de variables dentro de un sistema para observar cambios en otras variables. En este caso, las intervenciones consisten en cambiar activamente una variable a un valor determinado, lo que nos permite estudiar sus efectos directos sobre el sistema.
En nuestro ejemplo, una intervención podría ser
"Prohibamos la venta de helados en días calurosos (fijando la venta de helados en 0). ¿Reducirá esto los ataques de tiburones?"
En este caso, alteramos deliberadamente el sistema eliminando las ventas de helados. El resultado más probable es que no cambien los ataques de tiburones, ya que prohibir los helados no impide que la gente nade. Este sencillo ejemplo ilustra que intervenir en la venta de helados no tiene ningún efecto causal sobre los ataques de tiburones.
Antes de seguir adelante, si estás interesado en aspectos más fundamentales de la IA, el itinerario de habilidades Fundamentos de la IA es para ti¡!
En esta sección, exploraremos tres modelos causales de IA que nos ayudarán a comprender cómo trabajar con la causalidad.
Empecemos por el modelo más sencillo y avancemos hacia otros más complejos.
Los grafos acíclicos dirigidos (DAG) codifican las relaciones direccionales entre variables sin ciclos, lo que significa que no hay bucles en los que una variable pueda causarse indirectamente a sí misma. Se utilizan para representar relaciones causales de forma binaria: O bien existe una relación causa-efecto entre dos variables, en cuyo caso hay una arista dirigida de la causa al efecto en el grafo, o no la hay, y por tanto tampoco hay arista.
Por ejemplo, el DAG de nuestro ejemplo original del consumo de helado y los ataques de tiburón muestra las siguientes vías causales:
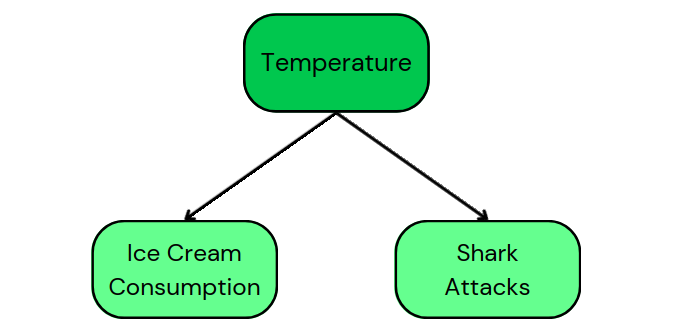
Este DAG nos dice que la temperatura es una causa común tanto del consumo de helados como de los ataques de tiburones. Además, demuestra que no existe causalidad entre el consumo de helado y los ataques de tiburón.
Los DAG son representaciones sencillas, pero pueden hacerse más complejas añadiendo más información a las vías, como veremos en los siguientes apartados.
Los Modelos Causales Estructurales (MCE) incluyen ecuaciones que modelan cómo influyen unas variables en otras. Para pasar de un DAG a un MEC, necesitamos especificar un sistema de ecuaciones estructurales que describan cuantitativamente cómo se genera cada variable.
Concretamente, una ecuación estructural en este contexto es una ecuación matemática que expresa una variable (resultado) en función de otra u otras variables (causas) más un término de perturbación que representa todas las demás influencias sobre ese resultado. En nuestro ejemplo:
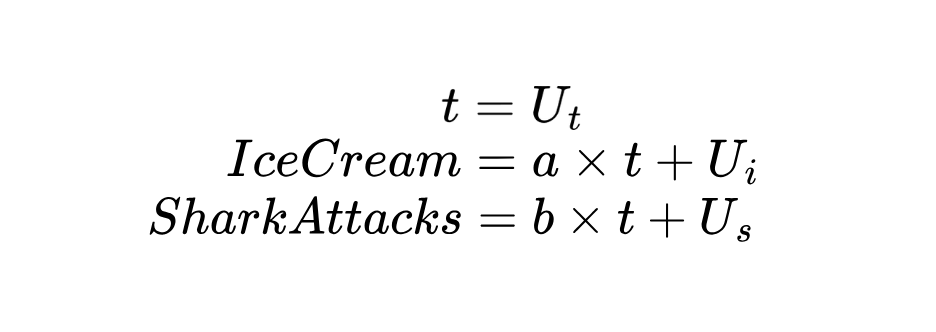
Como la temperatura (t) es una variable exógena, es decir, que no está causada por las otras dos, suponemos que está determinada por factores externos.
En las ecuaciones anteriores, tanto el consumo de helado como los ataques de tiburón siguen un modelo lineal sobre la temperatura, mostrando cómo un cambio de temperatura se propaga a ambos resultados.
Podemos ir incluso un paso más allá y ¡añadir probabilidades al juego!
Las Redes Bayesianas (BN) pueden considerarse como una instanciación particular de las MCE en las que las ecuaciones estructurales se expresan de forma probabilística.
Una BN utiliza la misma estructura de causa y efecto, pero en lugar de escribir fórmulas exactas (como un modelo lineal), describe las probabilidades o posibilidades de diferentes resultados. En otras palabras, en lugar de tener una ecuación, expresamos la probabilidad de que ocurra Y dado que X tiene un valor determinado: P(Y | X). Esta probabilidad condicional sustituye una ecuación fija en un MCE por una descripción de la incertidumbre.
En el contexto de la IA causal , la inferencia causal se refiere a las técnicas para averiguar las relaciones causa-efecto a partir de los datos. En este caso, en lugar de centrarnos en los modelos para comprender las relaciones, partimos ya de un conjunto de datos y aplicamos distintos métodos para discernir esas relaciones. Los revisaremos aplicando cada método a nuestro ejemplo original:
Los Ensayos Controlados Aleatorios (ECA) ayudan a determinar las relaciones causales asignando aleatoriamente a los participantes a diferentes grupos y comparando los resultados.
Por ejemplo, al responder a nuestra pregunta "¿Comer helado provoca más ataques de tiburón?" asignaríamos aleatoriamente a las personas en dos grupos:
Luego, compararíamos las tasas de ataques de tiburón entre los grupos. Idealmente, no deberíamos encontrar ninguna diferencia significativa en las tasas de ataques de tiburón porque el consumo de helado no causa ataques de tiburón. La causa real en este caso es probablemente la temperatura, que no se manipuló en el experimento.
Más formalmente, diríamos que la aleatorización aísla el efecto del consumo de heladoy como no se encuentra ninguna relación causal, esto sugiere que comer helado no causa directamente los ataques de tiburón.
En los casos en los que no es posible la aleatorización, podemos basarnos en datos observacionales y aplicar el emparejamiento por puntuación de propensión (PSM).
De hecho, en situaciones del mundo real, no podemos aplicar ECA y aleatorizar el consumo de helado, porque la gente decide comerlo o no. Sin embargo, podemos utilizar datos observacionales para inferir relaciones causales siguiendo los pasos del PSM:
Idealmente, las tasas de ataques de tiburón deberían ser similares para ambos grupos, lo que sugeriría que el consumo de helado no es la causa de los ataques de tiburón. Cualquier diferencia observada se debería probablemente a otros factores, como la temperatura.
Digamos que sospechamos que la temperatura es una variable oculta (un factor de confusión) que afecta tanto al consumo de helado como a los ataques de tiburón. La técnica de las Variables Instrumentales (IV) ayuda a resolver este problema utilizando una variable adicional (un instrumento) -como el horario del camión de helados- que influye en el consumo de helados pero no está relacionada con los ataques de tiburones.
Si el horario del camión sólo afecta a las ventas de helado y no al comportamiento de natación de la gente, entonces podemos utilizarlo como instrumento para aislar el efecto causal del consumo de helado sobre los ataques de tiburón. Al aplicar la IV, probablemente descubriríamos que, tras tener en cuenta este instrumento, el consumo de helado no causa ataques de tiburón, y que la correlación observada se debía al factor de confusión oculto: la temperatura.
Si tienes curiosidad sobre otros tipos de inferencias, considera la posibilidad de consultar el artículo "¿Qué es la inferencia del aprendizaje automático? Una Introducción a los Enfoques de la Inferencia".
En esta sección, exploraremos dos marcos diferentes para trabajar con la IA Causal en la práctica utilizando Python.
DoWhy es una herramienta muy interesante porque proporciona un marco integral para el razonamiento causal, haciendo hincapié en la transparencia y la interpretabilidad.
Es muy completo y ofrece una gran variedad de algoritmos para la estimación de efectos, el análisis de causas raíz, las intervenciones y los contrafactuales. Es especialmente útil para los flujos de trabajo de inferencia causal basados en grafos. No entraré en demasiados detalles sobre esta herramienta, pues ya existe un tutorial completo en DataCamp: Introducción a la IA causal utilizando la biblioteca DoWhy.
Pyro es un marco de programación probabilística centrado en el modelado estructural y bayesiano. Una de las principales ventajas de Pyro es que se integra perfectamente con PyTorch para la aceleración en la GPU y las aplicaciones de aprendizaje profundo.
Si te interesa, Pyro tiene una amplia documentación con muchos ejemplos disponibles.
Si tienes ganas de empezar a utilizar marcos de IA como los que se comentan en esta sección, te recomiendo el curso de DataCamp sobre Desarrollo de aplicaciones de IA.
Hasta ahora, hemos revisado los fundamentos de la IA Causal, los modelos que la sustentan, diferentes enfoques para la Inferencia Causal y dos marcos de trabajo en Python para trabajar con ella. Sin embargo, todos sabemos que sumergirse en una nueva disciplina puede ser duro. Por lo tanto, en esta sección repasaremos los cinco pasos clave para implantar la IA Causal:
La calidad de los datos de que disponemos es crucial, ya que la inferencia causal depende en gran medida de datos que representen con precisión el sistema estudiado. Es importante tener en cuenta que cualquier tipo de error, valor omitido o sesgo puede distorsionar las relaciones causales.
La inferencia causal también requiere datos ricos, como asegurarse de que todos los factores de confusión relevantes se observan y se incluyen en los datos, que las intervenciones están bien definidas y son coherentes en todas las observaciones y que los grupos son comparables cuando se aplican técnicas que requieren esta división.
Como consejo final, si puedes elegir tus datos, los datos temporales (series temporales o datos longitudinales) suelen ser muy útiles para establecer la causalidad, ya que ayudan a determinar el orden de los acontecimientos.
Este paso consiste en crear un modelo conceptual que represente las relaciones entre las variables. A menudo se utilizan en este punto herramientas como los DAG o los MEC para formalizar los supuestos sobre la causalidad.
Hemos visto que los factores de confusión son posibles variables ocultas que podrían estar influyendo en nuestras variables observadas. También hay otros dos tipos de variables:
Es interesante identificar estos tres tipos de variables y sus posibles interacciones durante la modelización y definir claramente la dirección de la causalidad.
El objetivo de la identificación es determinar si el efecto causal de interés puede estimarse a partir de los datos observados, dado el modelo. Por lo tanto, este paso implica comprobar si el efecto causal es identificable utilizando métodos de Inferencia Causal como la Identificación de Variables.
Una vez identificado el efecto causal, este paso se centra en cuantificar el efecto causal utilizando métodos estadísticos. Es un buen momento para aplicar, por ejemplo, el Propensity Score Matching.
Esta fase pone a prueba si tus conclusiones causales se sostienen desafiando los supuestos y explorando explicaciones alternativas. Los métodos de este paso incluyen el razonamiento contrafáctico y las intervenciones. Mientras que los contrafácticos examinan si el resultado cambiaría en condiciones diferentes, las intervenciones prueban la solidez de las relaciones causales alterando activamente las variables y observando los efectos.
Ahora que sabemos cómo funciona la IA causal, veamos algunos ejemplos de ámbitos en los que podemos aplicarla.
Un buen ejemplo de un sistema de IA causal del mundo real en funcionamiento se encuentra en el ámbito sanitario, donde se utiliza para determinar la eficacia de los tratamientos estimando, por ejemplo, el impacto causal de las intervenciones médicas. Además, las relaciones causales se utilizan para adaptar los tratamientos a cada paciente en función de su situación específica.
El marketing es otra área que se beneficia de la IA causal. Por ejemplo, la IA Causal ayuda a medir el verdadero impacto de las campañas de marketing distinguiendo entre correlación y causalidad. Proporciona una visión más profunda de lo que impulsa las decisiones de los clientes, permitiendo estrategias de marketing más específicas y eficaces. Del mismo modo, campos como la economía los negociosy la gestión de la cadena de suministro también se basan en la comprensión de la causalidad.
En este artículo, hemos explorado cómo la IA causal nos ayuda a ir más allá de las simples correlaciones en los datos para descubrir verdaderas relaciones de causa y efecto. Hemos examinado cómo los Grafos Acíclicos Dirigidos, los Modelos Causales Estructurales y las Redes Bayesianas sirven como herramientas de modelado causal para representar y razonar sobre sistemas complejos.
Además, hemos discutido cómo aplicar la IA causal a los datos, donde los Ensayos Controlados Aleatorios y el Emparejamiento por Puntuación de Propensión ayudan en la estimación del efecto causal. Cuando se sospecha que hay factores de confusión no medidos, las Variables Instrumentales ayudan a identificar las influencias ocultas.
Por último, hemos esbozado los pasos para aplicar la IA causal en la práctica, haciendo especial hincapié en el razonamiento contrafáctico y las intervenciones como herramientas clave en la fase de refutación del análisis causal.
A medida que la IA causal siga evolucionando, desempeñará un papel cada vez más vital no sólo en distinguir entre simple correlación y causalidad, sino también en aprovechar la causalidad para tomar mejores decisiones.
Si quieres saber más sobre la IA causal y cómo ayuda a las empresas a tomar mejores decisiones, consulta nuestro episodio de episodio de DataFramed sobre la IA causal en la empresa. También puedes leer nuestra guía práctica sobre IA causal utilizando la Biblioteca DoWhy para obtener un ejemplo práctico.
Los mejores cursos de DataCamp
programa
Curso
Curso