
Cursus
Principes fondamentaux de l'IA
10 h
Avez-vous déjà entendu dire que, selon des données recueillies aux États-Unis, la consommation de crème glacée est liée aux attaques de requins ?
Aussi fou que cela puisse paraître, ce type de corrélation se produit lorsque deux variables semblent liées mais sont en fait toutes deux influencées par une troisième variable. Dans ce cas, la température est le facteur le plus probable. En été, la consommation de glaces augmente en raison de la chaleur. Dans le même temps, les attaques de requins augmentent également parce que de plus en plus de gens nagent dans l'océan.
Bien que ce schéma montre une corrélation dans les données, il n'implique pas que l'un soit à l'origine de l'autre. C'est là qu'intervient Causal AI. Le site permet d'identifier les véritables relations de cause à effet dans les données, ce qui permet d'éviter les corrélations fallacieuses.
Dans cet article, nous allons explorer le concept d'IA causale, son importance et la manière de l'appliquer dans la pratique.
L'IA causale est une branche de l'intelligence artificielle (IA) qui s'attache à la compréhension et la modélisation des relations de cause à effetplutôt que d'identifier des modèles ou des corrélations comme le font les autres systèmes traditionnels d'apprentissage automatique.
L'IA causale permet d'améliorer la fiabilité, l'explicabilité et la robustesse des systèmes d'IA, en particulier dans des scénarios réels tels que les soins de santé et l'économie, qui sont plus complexes par nature.
À ce stade, vous vous posez peut-être la question :
Pourquoi les méthodes traditionnelles d'IA ne tiennent-elles pas compte de la causalité ?
Les systèmes d'IA traditionnels se concentrent sur l'identification de modèles, de corrélations et de prédictions basées sur des données. Pour ce faire, ils s'appuient sur des techniques statistiques et d'apprentissage automatique pour trouver des associations dans les données.
En effet, lors de la formation, ils sont conçus pour optimiser la précision de la prédiction en utilisant de grands ensembles de données. Ces ensembles de données sont ceux qui contiennent des corrélations et les algorithmes remarqueront ces corrélations, mais des informations causales explicites peuvent ne pas être présentes.
En outre, les systèmes d'IA traditionnels sont souvent critiqués pour leur caractère peu explicable et sont fréquemment qualifiés de "boîte noire". Dans ce contexte, Causal AI aide à construire des modèles plus transparents et interprétables en raisonnant explicitement sur les causes et les effets.
Enfin, bien que les méthodes d'IA traditionnelles (non causales) aient de nombreuses applications, le principal enseignement à tirer de cette section est le suivant : La corrélation n'implique pas la causalité.
Si l'on reprend l'exemple des glaces et des attaques de requins de l'introduction, on constate qu'il existe une corrélation entre les ventes de glaces et les attaques de requins (les deux augmentent en été), mais les glaces ne sont pas à l'origine des attaques de requins.
Comme nous l'avons vu, l'objectif de l'IA causale est d'établir des relations de cause à effet entre les variables. Cependant, il existe également deux concepts fondamentaux essentiels pour comprendre et manipuler ces relations au sein d'un système :
Le raisonnement contrefactuel consiste à envisager des scénarios hypothétiques pour comprendre comment les changements de certaines variables peuvent modifier les résultats.
J'aime considérer que le raisonnement contrefactuel pose des questions telles que : "Que se serait-il passé si la variable X avait pris une valeur différente ? Il s'agit d'un question "Et si". question.
Dans notre exemple de la crème glacée contre les attaques de requins, nous pourrions nous demander :"Que se passerait-il si les ventes de crème glacée avaient été plus faibles ? Y aurait-il eu moins d'attaques de requins ?".
Dans ce scénario contrefactuel, nous imaginons une version alternative de la réalité où les ventes de glaces diminuent alors que tout le reste reste reste inchangé. Étant donné que les ventes de glaces et les attaques de requins augmentent toutes deux en été en raison du temps plus chaud (une cause commune), la réduction des ventes de glaces n'aurait pas d'incidence sur les attaques de requins. Il s'agit d'une corrélation et non d'un lien de cause à effet.
Les interventions font référence à la manipulation délibérée de variables au sein d'un système afin d'observer des changements dans d'autres variables. Dans ce cas, les interventions consistent à modifier activement une variable pour lui donner une valeur spécifique, ce qui nous permet d'étudier ses effets directs sur le système.
Dans notre exemple, une intervention pourrait être :
"Interdisons la vente de glaces les jours de canicule (en fixant les ventes de glaces à 0). Cela réduira-t-il le nombre d'attaques de requins ?
Ici, nous modifions délibérément le système en supprimant les ventes de glaces. Le résultat le plus probable est que les attaques de requins restent inchangées, puisque l'interdiction des glaces n'empêche pas les gens de nager. Cet exemple simple montre que l'intervention sur les ventes de glaces n'a pas d'effet causal sur les attaques de requins.
Avant de poursuivre, si vous êtes intéressé par des aspects plus fondamentaux de l'IA, le cursus de compétences Fondamentaux de l'IA est fait pour vous!
Dans cette section, nous allons explorer trois modèles d'IA causale qui nous aideront à comprendre comment travailler avec la causalité.
Commençons par le modèle le plus simple et progressons vers des modèles plus complexes.
Les graphes acycliques dirigés (DAG) encodent les relations directionnelles entre les variables sans cycles, signifiant qu'il n'y a pas de boucles où une variable peut indirectement s'engendrer elle-même. Ils sont utilisés pour représenter les relations causales de manière binaire : Soit il existe une relation de cause à effet entre deux variables, auquel cas le graphe comporte une arête dirigée de la cause à l'effet, soit il n'y en a pas, et il n'y a donc pas non plus d'arête.
Par exemple, le DAG de notre exemple original de consommation de crème glacée et d'attaques de requins présente les chemins de causalité suivants :
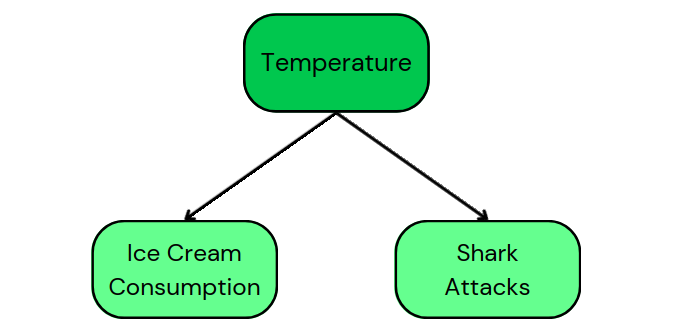
Ce DAG nous apprend que la température est une cause commune à la consommation de crème glacée et aux attaques de requins. En outre, elle montre qu'il n'y a pas de causalité entre la consommation de glaces et les attaques de requins.
Les DAG sont des représentations simples, mais elles peuvent devenir plus complexes en ajoutant des informations aux voies, comme nous le verrons dans les sections suivantes.
Les modèles structurels de causalité (SCM) comprennent des équations qui modélisent la façon dont les variables sont influencées par d'autres. Pour passer d'un DAG à un SCM, nous devons spécifier un système d'équations structurelles qui décrivent quantitativement comment chaque variable est générée.
Concrètement, une équation structurelle dans ce contexte est une équation mathématique qui exprime une variable (résultat) en tant que fonction d'une ou plusieurs autres variables (causes) plus un terme de perturbation représentant toutes les autres influences sur ce résultat. Dans notre exemple :
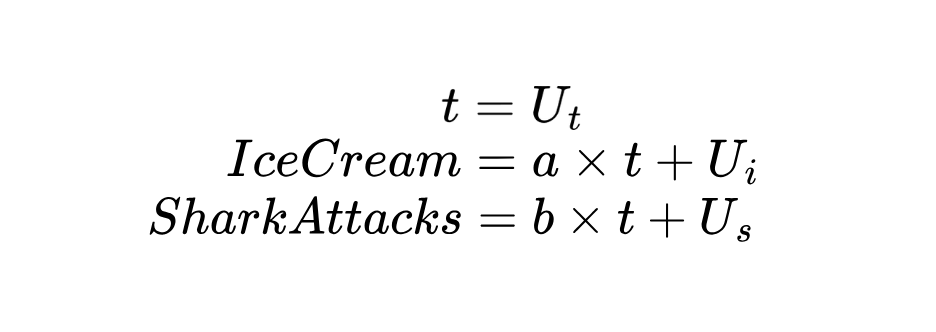
La température (t) étant une variable exogène, c'est-à-dire qu'elle n'est pas causée par les deux autres, nous supposons qu'elle est déterminée par des facteurs externes.
Dans les équations ci-dessus, la consommation de glaces et les attaques de requins suivent un modèle linéaire sur la température, montrant comment un changement de température se propage aux deux résultats.
Nous pouvons même aller plus loin et ajouter des probabilités au jeu !
Les réseaux bayésiens (RB) peuvent être considérés comme une instanciation particulière des MCS dans laquelle les équations structurelles sont exprimées de manière probabiliste. les équations structurelles sont exprimées de manière probabiliste.
Un BN utilise la même structure de cause à effet, mais au lieu d'écrire des formules exactes (comme dans le cas d'un modèle linéaire), il décrit les probabilités ou les chances des différents résultats. En d'autres termes, plutôt que d'avoir une équation, nous exprimons la probabilité que Y se produise si X a une certaine valeur : P(Y | X). Cette probabilité conditionnelle remplace une équation fixe dans un MCS par une description de l'incertitude.
Dans le contexte de l'IA causale, l'inférence causale fait référence aux techniques permettant d'établir des relations de cause à effet à partir de données. Dans ce cas, au lieu de se concentrer sur les modèles pour comprendre les relations, nous partons déjà d'un ensemble de données et appliquons différentes méthodes pour discerner ces relations. Nous allons les passer en revue en appliquant chaque méthode à notre exemple initial :
Les essais contrôlés randomisés (ECR) permettent de déterminer les relations de cause à effet en répartissant les participants de manière aléatoire dans différents groupes et en comparant les résultats.
Par exemple, en répondant à notre question, "Manger de la glace provoque-t-il plus d'attaques de requins ?" nous répartissons au hasard les personnes en deux groupes :
Ensuite, nous comparerons les taux d'attaques de requins entre les deux groupes. Idéalement, nous ne devrions pas trouver de différence significative dans les taux d'attaques de requins, car la consommation de crème glacée n'est pas à l'origine des attaques de requins. La cause réelle dans ce cas est probablement la température, qui n'a pas été manipulée dans l'expérience.
Plus formellement, nous dirions que la randomisation isole l'effet de la consommation de glaceet comme aucun lien de causalité n'est trouvé, cela suggère que la consommation de crème glacée n'est pas directement à l'origine des attaques de requins.
Dans les cas où la randomisation n'est pas possible, nous pouvons nous appuyer sur des données d'observation et appliquer la méthode de l'appariement des scores de propension (Propensity Score Matching - PSM).
En fait, dans le monde réel, il n'est pas possible d'appliquer des ECR et de randomiser la consommation de crème glacée, car les gens décident d'en manger ou non. Cependant, , nous pouvons utiliser des données d'observation pour déduire des relations de cause à effet en suivant les étapes du PSM :
Idéalement, les taux d'attaques de requins devraient être similaires pour les deux groupes, ce qui suggérerait que la consommation de crème glacée n'est pas la cause des attaques de requins. Toute différence observée serait probablement due à d'autres facteurs, tels que la température.
Supposons que nous soupçonnions que la température est une variable cachée (un facteur de confusion) qui influe à la fois sur la consommation de crème glacée et sur les attaques de requins. La technique des variables instrumentales (IV) permet de résoudre ce problème enutilisant une variable supplémentaire (un instrument) - telle que l'horaire du camion de glaces - qui influence la consommation de glaces mais n'est pas liée aux attaques de requins.
Si l'horaire du camion n'affecte que les ventes de glaces et non le comportement des gens en matière de natation, alors nous pouvons l'utiliser comme instrument pour isoler l'effet causal de la consommation de glaces sur les attaques de requins. En appliquant la méthode IV, nous constaterions probablement qu'après avoir pris en compte cet instrument, la consommation de crème glacée n'est pas à l'origine des attaques de requins, et que la corrélation observée est due à un facteur de confusion caché : la température.
Si vous êtes curieux de connaître d'autres types d'inférences, vous pouvez consulter l'article "Qu'est-ce que l'inférence en apprentissage automatique ? Une introduction aux approches d'inférence".
Dans cette section, nous allons explorer deux cadres différents pour travailler avec l'IA causale en pratique à l'aide de Python.
DoWhy est un outil très intéressant car il fournit un cadre de bout en bout pour le raisonnement causal, en mettant l'accent sur la transparence et l'interprétabilité.
Il est très complet et offre une grande variété d'algorithmes pour l'estimation des effets, l'analyse des causes profondes, les interventions et les contrefactuels. Il est particulièrement utile pour les processus d'inférence causale basés sur les graphes. Je ne rentrerai pas trop dans les détails de cet outil, car un tutoriel complet est déjà disponible sur DataCamp : Introduction à l'IA causale à l'aide de la bibliothèque DoWhy.
Pyro est un cadre de programmation probabiliste dont l'objectif principal est la modélisation structurelle et bayésienne. L'un des principaux avantages de Pyro est qu'il s'intègre parfaitement à PyTorch pour l'accélération GPU et les applications d'apprentissage en profondeur.
Si vous êtes intéressé, Pyro dispose d'une documentation complète avec de nombreux exemples disponibles.
Si vous êtes impatient de commencer à utiliser des frameworks d'IA tels que ceux abordés dans cette section, je vous recommande la formation DataCamp sur les thèmes suivants . Développer des applications d'IA.
Jusqu'à présent, nous avons passé en revue les principes fondamentaux de l'IA causale, les modèles qui la sous-tendent, les différentes approches pour l'inférence causale, et deux frameworks Python pour travailler avec. Néanmoins, nous savons tous qu'il peut être difficile de se lancer dans une nouvelle discipline. C'est pourquoi, dans cette section, nous passerons en revue les cinq étapes clés de la mise en œuvre de l'IA causale :
La qualité des données dont nous disposons est cruciale, car l'inférence causale repose fortement sur des données qui représentent avec précision le système étudié. Il est important de garder à l'esprit que tout type d'erreur, de valeur manquante ou de biais peut fausser les relations de cause à effet.
L'inférence causale nécessite également des données riches, par exemple en s'assurant que tous les facteurs de confusion pertinents sont observés et inclus dans les données, que les interventions sont bien définies et cohérentes entre les observations et que les groupes sont comparables lors de l'application de techniques qui nécessitent cette division.
Enfin, si vous pouvez choisir vos données, les données temporelles (séries chronologiques ou données longitudinales) sont souvent très utiles pour établir la causalité, car elles permettent de déterminer l'ordre des événements.
Cette étape consiste à créer un modèle conceptuel qui représente les relations entre les variables. Des outils tels que les DAG ou les SCM sont souvent utilisés à ce stade pour formaliser les hypothèses de causalité.
Nous avons vu que les facteurs de confusion sont des variables cachées qui peuvent influencer les variables observées. Il existe également deux autres types de variables :
Il est intéressant d'identifier ces trois types de variables et leurs interactions potentielles lors de la modélisation et de définir clairement le sens de la causalité.
L'objectif de l'identification est de déterminer si l'effet causal recherché peut être estimé à partir des données observées, compte tenu du modèle. Par conséquent, cette étape consiste à vérifier si l'effet causal est identifiable à l'aide de méthodes d'inférence causale telles que l'identification des variables.
Une fois l'effet causal identifié, cette étape se concentre sur la quantification de l'effet causal à l'aide de méthodes statistiques. C'est le moment idéal pour appliquer l'appariement par score de propension, par exemple.
Cette phase permet de vérifier si vos conclusions causales tiennent la route en remettant en question les hypothèses et en explorant d'autres explications. Les méthodes de cette étape comprennent le raisonnement contrefactuel et les interventions. Alors que les contrefactuels examinent si le résultat changerait dans des conditions différentes, les interventions testent la robustesse des relations causales en modifiant activement les variables et en observant les effets.
Maintenant que nous savons comment fonctionne l'IA causale, examinons quelques exemples de domaines dans lesquels nous pouvons l'appliquer.
Un bon exemple de système d'IA causale à l'œuvre dans le monde réel se trouve dans le domaine des soins de santé, où il est utilisé pour déterminer l'efficacité des traitements en estimant, par exemple, l'impact causal des interventions médicales. En outre, les relations de cause à effet sont utilisées pour adapter les traitements aux patients individuels en fonction de leur situation spécifique.
Le marketing est un autre domaine qui bénéficie de l'IA causale. Par exemple, Causal AI aide à mesurer l'impact réel des campagnes de marketing en faisant la distinction entre la corrélation et la causalité. Elle permet de mieux comprendre ce qui motive les décisions des clients, ce qui permet de mettre en place des stratégies de marketing plus ciblées et plus efficaces. De même, des domaines tels que l'économie, les affaireset la gestion de la chaîne d'approvisionnement s'appuient également sur la compréhension de la causalité.
Dans cet article, nous avons exploré comment l'IA causale nous aide à aller au-delà des simples corrélations dans les données pour découvrir de véritables relations de cause à effet. Nous avons examiné comment les graphes acycliques dirigés, les modèles causaux structurels et les réseaux bayésiens servent d'outils de modélisation causale pour représenter et raisonner sur des systèmes complexes.
En outre, nous avons discuté de la manière d'appliquer l'IA causale aux données, où les essais contrôlés randomisés et l'appariement des scores de propension aident à l'estimation de l'effet causal. Lorsque l'on soupçonne une confusion non mesurée, les variables instrumentales permettent d'identifier les influences cachées.
Enfin, nous avons décrit les étapes de la mise en œuvre de l'IA causale dans la pratique, en mettant particulièrement l'accent sur le raisonnement contrefactuel et les interventions en tant qu'outils clés dans la phase de réfutation de l'analyse causale.
Au fur et à mesure de son évolution, l'IA causale jouera un rôle de plus en plus vital non seulement dans la distinction entre la simple corrélation et la causalité, mais aussi dans l'exploitation de la causalité pour une meilleure prise de décision.
Si vous souhaitez en savoir plus sur l'IA causale et la manière dont elle aide les entreprises à prendre de meilleures décisions, consultez notre épisode de DataFrame sur l'IA causale dans les entreprises.. Vous pouvez également lire notre guide pratique sur L'IA causale à l'aide de la bibliothèque DoWhy pour obtenir un exemple pratique.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours